
Linux 驱动之 ALSA(九)虚拟声卡 Latency
测试方法
两块板子之间通过 I2S 通信,其中一块板子配置为 Slave 另一块板子为 Master
Master 板端执行 arecord | aplay 或者 gstream 命令
1
2arecord -Dhw:2,0 -r 44100 -c 8 -f S32_LE | aplay -Dhw:2,0 -c 8 -r 44100 -f S32_LE
gst-launch-1.0 alsasrc device=device_input_split ! alsasink device=device_output sync=falseSlave 通过 aplay 播放一段 wav 文件
通过示波器抓取 Master 板的 I2S 输入和输出端的波形间隔来测量虚拟声卡的 Latency
DataStream
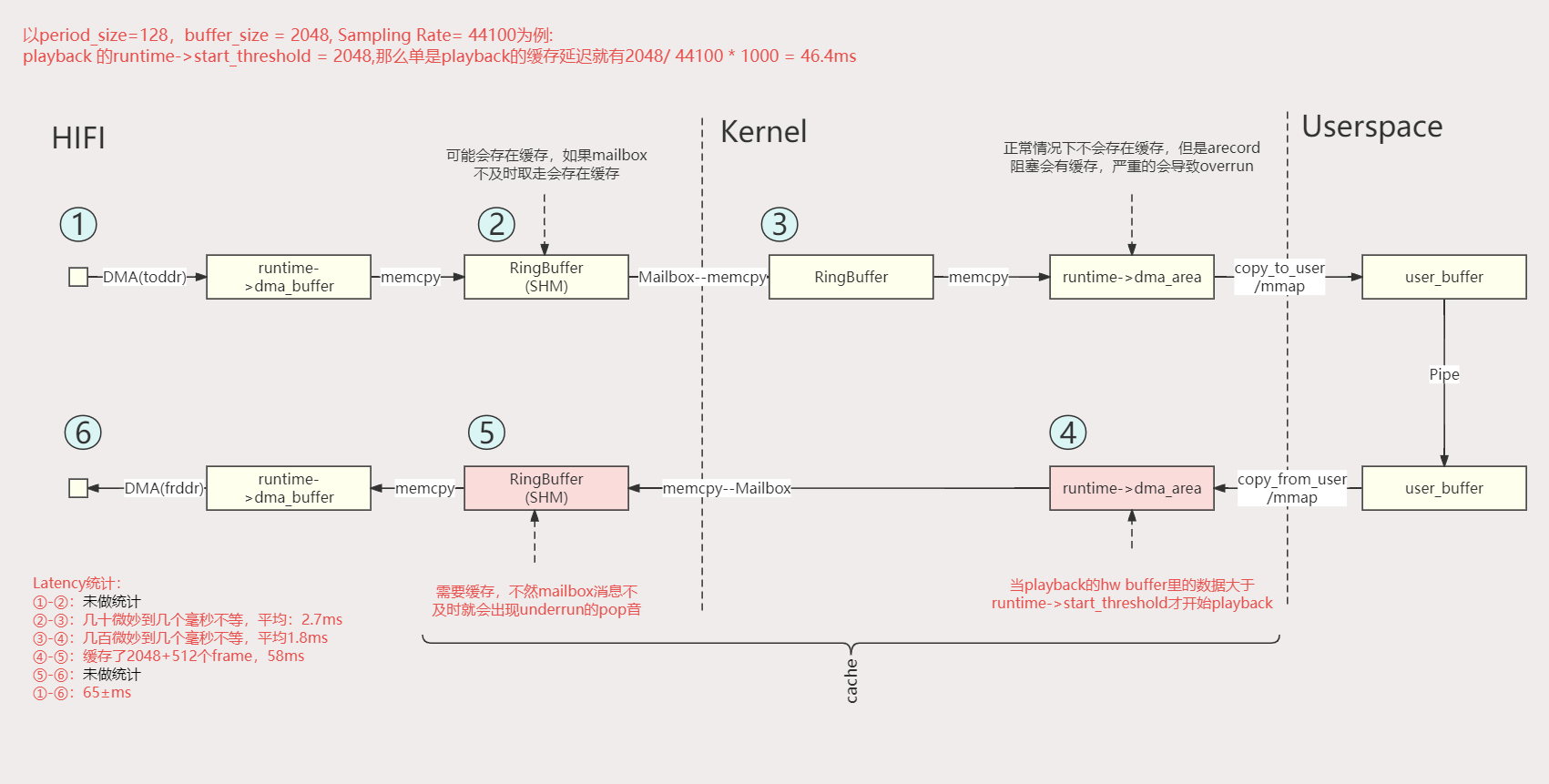
上图就是 arecord | aplay(没有使用插件) 整个虚拟声卡的数据流,其中延迟最大的部分就是红色框中的缓存。
走 USB 通路的 latency: 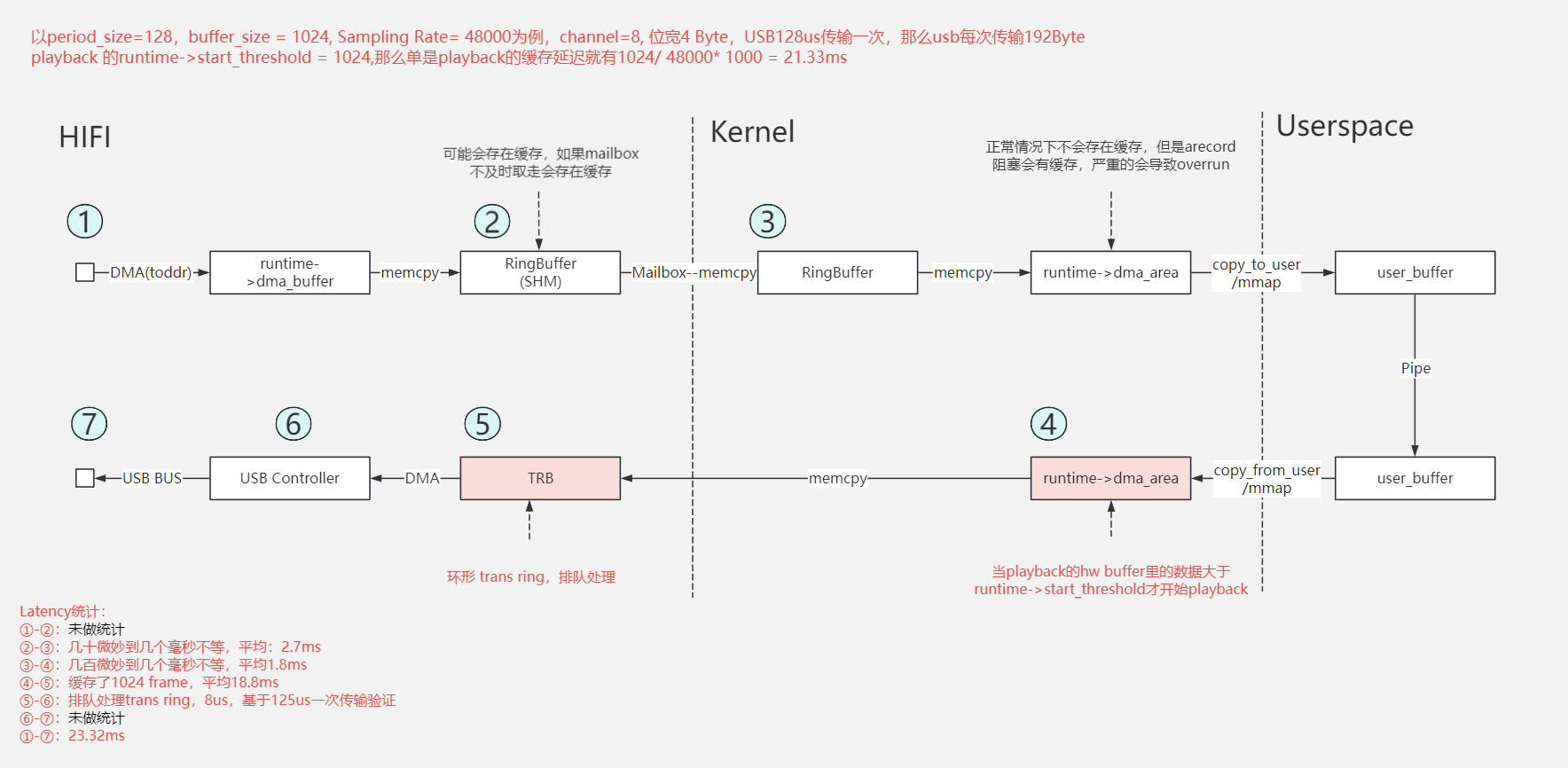
增大 Buffer Size 为什么会增大 latency?
aplay 通过调用 snd_pcm_write 写数据给驱动,alsa lib 中 snd_pcm_write 有如下调用栈:
1 | _snd_pcm_writei(pcm, buffer, size) |
alsa lib 通过 ioctl 系统调用到内核,打印 snd_pcm_write 内核调用栈:
1 | 14.513126@2] Call trace: |
整理一下:
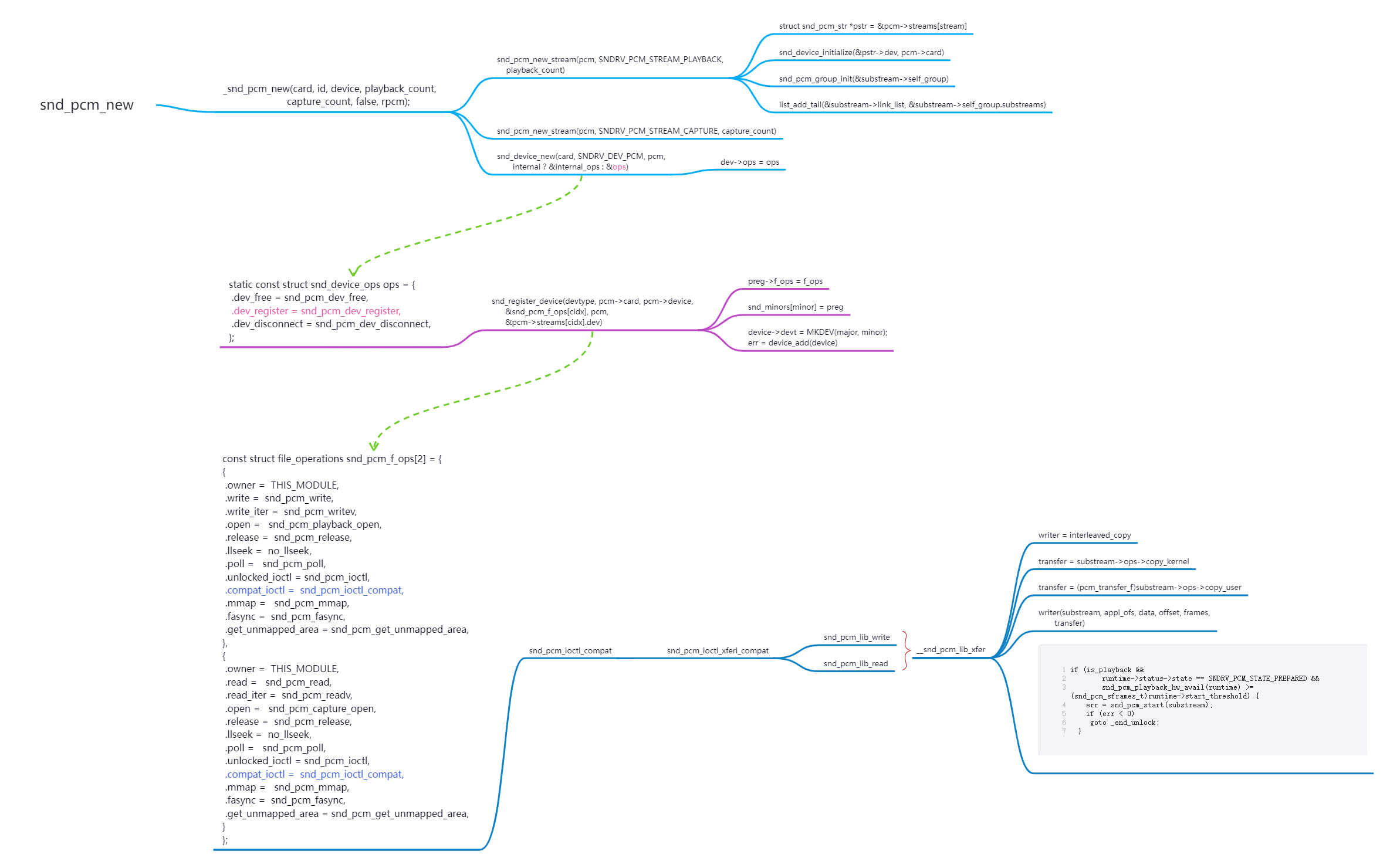
内核中通过 Ioctl 系统调用最终调用到__snd_pcm_lib_xfer 函数,然后发现该数有如下逻辑:
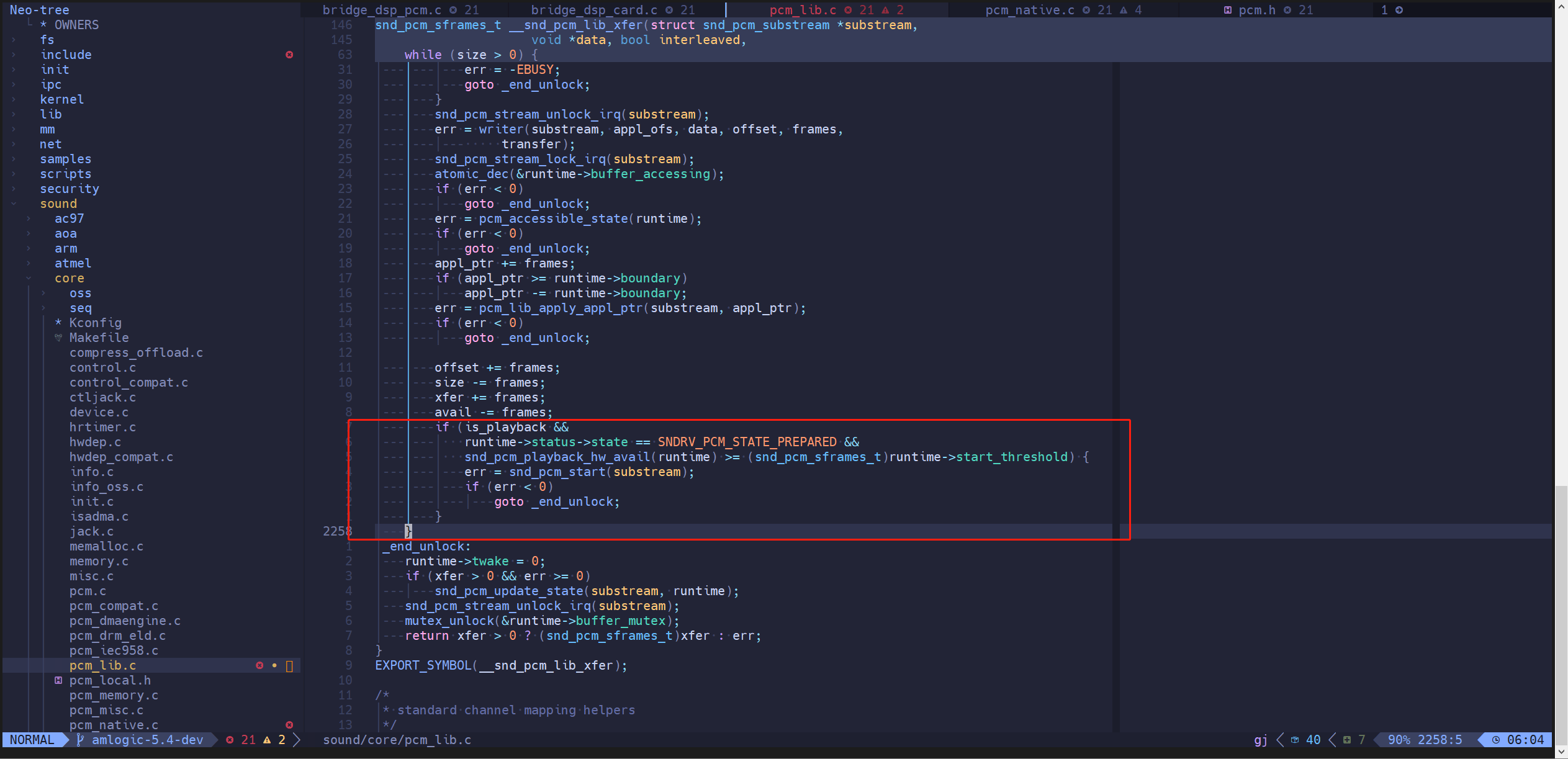
如果是 playback 流,且状态为 parpare,当 runtime→dma_area 里的数据大于等于 runtime→start_threshold,状态才会切换到 running。通过打印 log 发现:
1 | [ 14.571395@0] playback : buffer_size : 2048 dma size : 65536 start_threshold : 2048 stop_threshold : 2048 |
playback 的 runtime→start_threshold 跟 buffer_size 一样大,也就是 playback 会先缓存 buffer_size 个 frame 的数据然后再开始播放,这样会导致 latency 随着 buffer_size 的变大而变大了。
参考文献
https://www.alsa-project.org/alsa-doc/alsa-lib/pcm_plugins.html
https://alsa.opensrc.org/ALSA_plugins





