
Linux 文件系统(一)基本概念

声明:本文转载自 文件系统的原理 和 Linux 中的 VFS 实现 [一]
没有文件系统,访问磁盘上的数据就需要直接读写磁盘的 sector(繁琐),而文件系统存在的意义,就是能更有效的组织、管理和使用磁盘上的 raw data。
文件系统的组成
因为磁盘上的数据要和内存交互,而内存通常是以 4KB
为单位管理的,所以把磁盘按照 4KB 划分比较方便(称为一个
block)。现在假设由一个文件系统管理 64 个 blocks 的一个磁盘区域: 
文件
文件系统的基础要素自然是文件,而文件作为一个数据容器的逻辑概念,本质上是字节构成的集合,这些字节就是文件的
user data(对应下图的"D")。 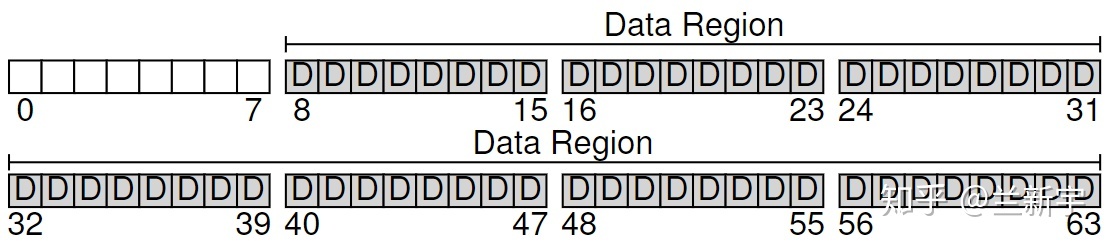
除了文件本身包含的数据,还有文件的访问权限、大小和创建时间等控制信息,这些信息被称为文件的 meta data。这些 meta data 的数据结构就是 inode(对应下图的"I",有些文件系统称之为 dnode 或 fnode)。
假设一个 inode 占据 256 字节,那么一个 4KB 的 block 可以存放 16 个
inodes,使用 5 个 blocks 可以存放 80 个 inodes,也就是最多支持 80
个文件。 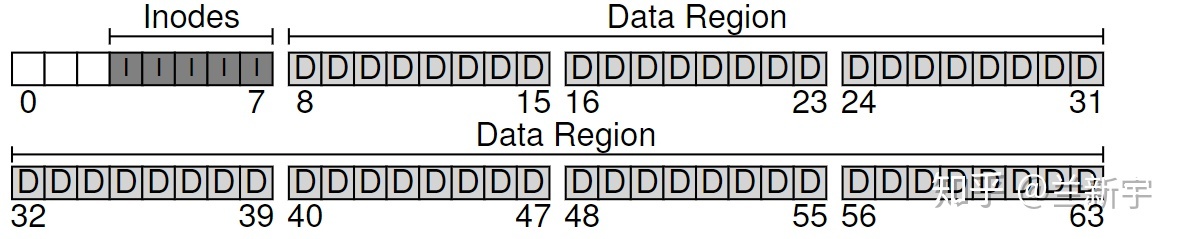
bitmap
需要追踪这些 inodes 和 data blocks
的分配和释放情况,判断哪些是已用的,哪些是空闲的。最简单的办法就是使用
bitmap,包括记录 inode 使用情况的 bitmap(对应下图的"i"),和记录 data
block 使用情况的 bitmap(对应下图的"d")。空闲就标记为
0,正在使用就标记为 1。 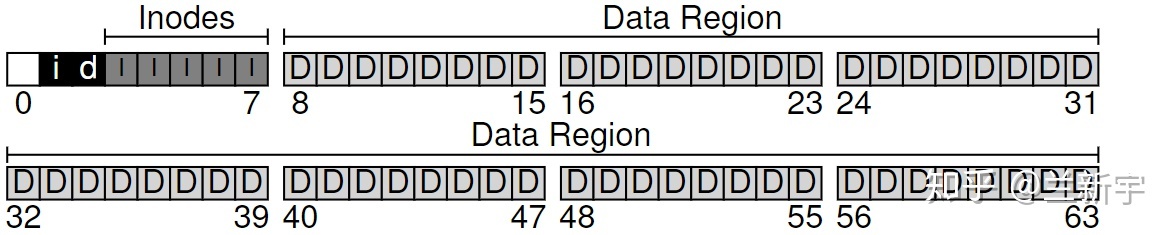
superblock
superblock 包含了一个文件系统所有的控制信息,比如文件系统中有多少个
inodes 和 data blocks,inode 的信息起始于哪个 block(这里是第 3
个),可能还有一个区别不同文件系统类型的 magic number。因此,superblock
可理解为是文件系统的 meta data。 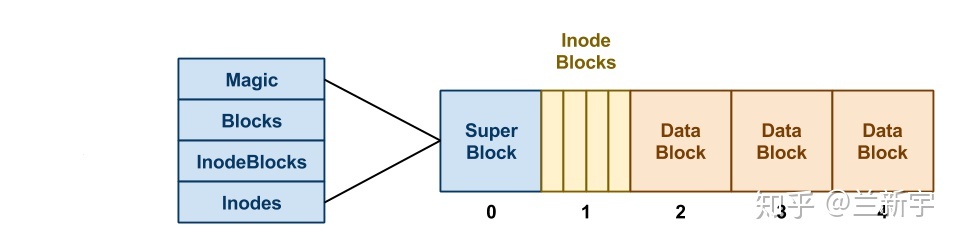
文件寻址
寻址过程
这 5 个 blocks 中的 80 个 inodes 构成了一个 inode table。假设一个
inode 的大小是 256 字节,现在我们要访问第 32 个文件,也就是第 32 个
inode 所在的磁盘位置。它应该在相对 inode table 起始地址的 8KB
处(32*256=8192),而 inode table 的起始地址是 12KB,所以实际位置是
20KB。 
磁盘同内存不同,它在物理上不是按字节寻址的,而是按 sector。一个 sector 的大小通常是 512 字节,因此换算一下就是第 40 个 sector(20*1024/512)。找到 inode 后,inode 里就有指针指向保持文件数据的 data block 就查找到了文件。
对于 ext2/3/4 文件系统,以上介绍的这些 inode bitmap, data block
bitmap 和 inode
table,都可以通过一个名为"dumpe2fs"的工具来查看其在磁盘上的具体位置:
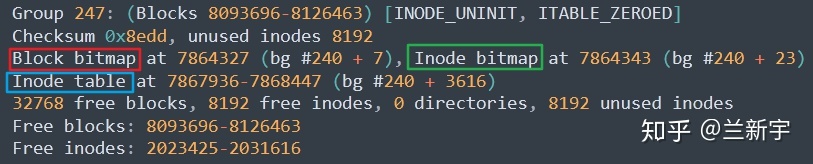
如果只需要查看 inode 的使用情况,那么直接使用"df -i"命令即可: 
寻址方式
两种寻址方式:
- inode 里通过指针指向一个 block,假设一个 inode 最多能包含 12
个指针,那么文件的大小不能超过 48KB。那如果超过了怎么办?可由 inode
先指向一个中间 block,这个 block 再指向分散的 data block,这种方法称为
multi-level index。假设一个指针占据 4 个字节,那么一个中间 block 可存储
1024 个指针,二级 index 的寻址范围就可超过 4MB,三级 index 则可超过
4GB。
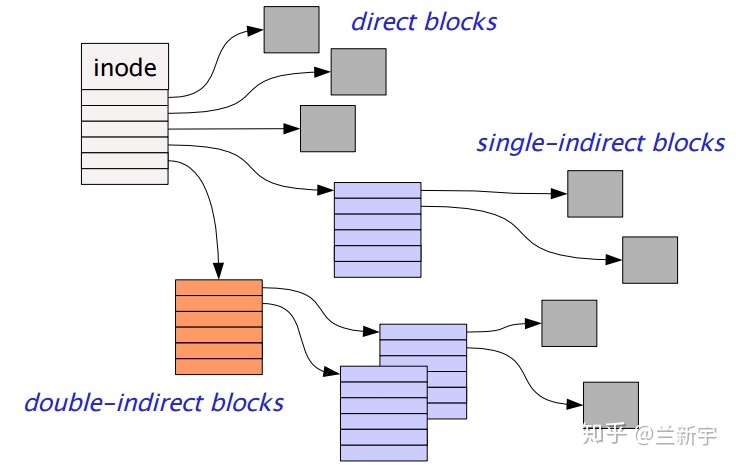
这种只使用 block 指针的方式(可被称为"pointer-based")被 ext2 和 ext3 文件系统所采用,但它存在一个问题,对于占据多个 data block 的文件,需要较多的 meta data。
- 另一种实现是使用一个 block 指针加上一个 length 来表示一组物理上连续的 blocks(称为一个 extent,其中 length 以 block 为单位计),一个文件则由若干个 extents 构成。这种"extent-based"的方式被后来的 ext4 文件系统所采用。
1 | struct ext4_extent { |
相比"pointer-based"而言,"extent-based"由于需要磁盘上连续的 free space,灵活性稍差,适用于磁盘空闲空间比较充足的场景。
目录和路径
各级目录构成了访问文件的路径,从抽象的角度,目录也可视作一种文件,只是这种文件比较特殊,它的
user data 存储的是该路径下的普通文件的 inode 编号。 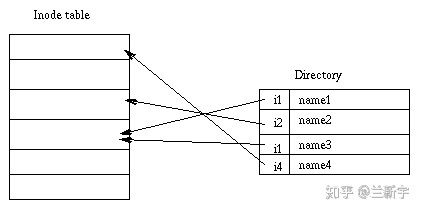
所以,如下图所示的这样一个路径结构,假设要在"/foo"目录下创建一个文件"bar.txt",那么需要从
inode bitmap 中分配一个空闲的 inode,并在"/foo"这个目录中分配一个
entry,以关联这个 inode 号。 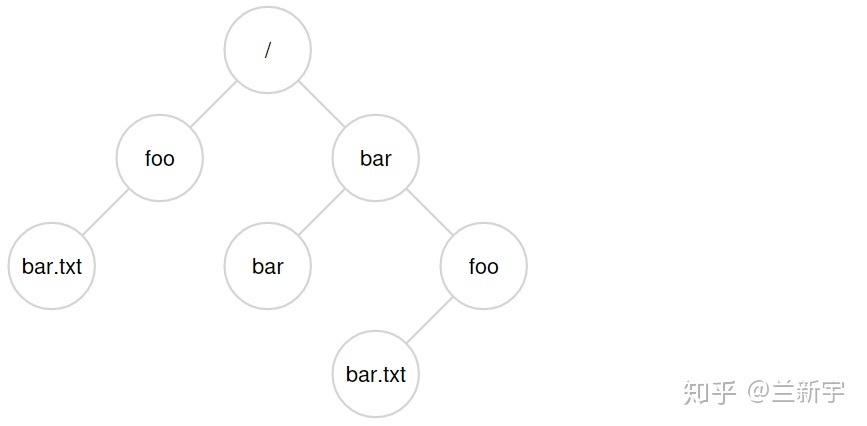
接下来,我们要读取刚才创建的这个"/foo/bar.txt"文件,那么先得找到"/"这个目录文件的 inode 号(这必须是事先知道的,假设是 2)。然后访问这个 inode 指向的 data block,从中找到一个名为"foo"的 entry,得到目录文件"foo"的 inode 号(假设是 44)。重复此过程,按图索骥,直到找到文本文件"bar.txt"的 inode 号。
用户看到的文件
访问权限控制
每个文件有三种与之关联的权限,分别是读、写和执行。试图访问文件的用户也划分为三类,分别是文件的所有者(user)、与所有者在同一用户组的用户(group),以及其他用户(others)。
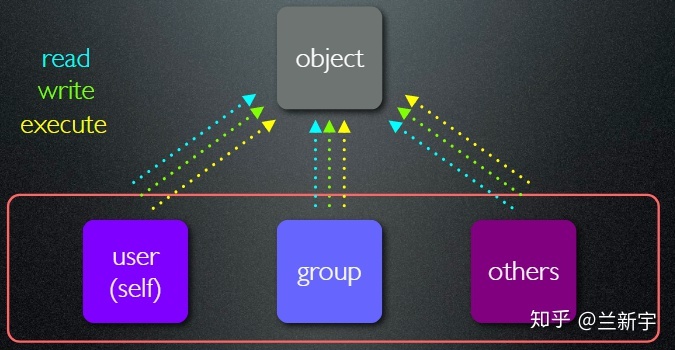
可通过"chmod"命令修改文件的权限,通过"chown"命令修改文件的 UID 和 GID。
1 | struct inode { |
每个文件都有三种 timestamp:文件上次被访问的时间(access time,简称 atime)、文件上次被修改的时间(modification time,简称 mtime)和文件属性上次被修改的时间(change time,简称 ctime)
1 | struct timespec64 i_atime; |
mtime 针对的是文件的内容(即 user data),而 ctime 针对的是 inode
结构自身(即 meta data)。 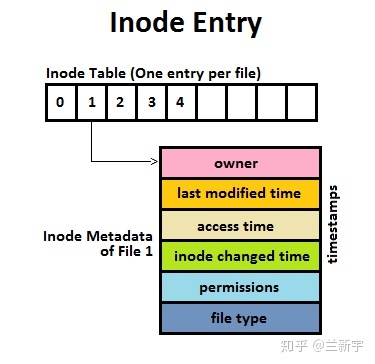
特殊文件
上面示例的这个文件是 regular file,此外,设备在 Linux 中也被视作文件,一个设备可以是 block device(即"i_bdev"),也可以是 character device(即"i_cdev"),而且设备还具有主设备号和从设备号(即"i_rdev")。
1 | dev_t i_rdev; |
如上文所说,目录(directory)也被视作一种特殊的文件,因而它没有独立的数据结构,且基于文件的大部分操作也可用于
directory。 
inode 编号和 superblock
一个文件必然处于一个文件系统中,因而一个 inode 也必然被一个 superblock 所管理(由"i_sb"指向)。同一 superblock 的所有 inodes 以双向链表的形式连接(即"i_sb_list"),每个 inode 在其所属的 superblock 中有唯一的编号(即"i_ino",对应上面 stat 命令输出的"Inode"项)。
1 | struct super_block *i_sb; |
两种 link
一个文件可以有两种 link:hard link 和 symbolic/soft
link,可分别通过"ln"和"ln -s"命令创建。 
它们的 inode 编号却不相同(通过"ls -i"查看),hard link 与原文件的
inode 号相同,soft link 则有单独的 inode 号。 
再来查看文件的详细信息: 
现在用"rm"命令删除原文件,并通过 strace
工具追踪这期间发生的系统调用。 
可以看到,它调用了"unlink",为什么不是叫"remove"或者"delete"呢?先来试试删除原文件之后,还能否继续使用
hard link 和 soft link。 
hard link 还可以正常访问原来的内容,而 soft link 的访问则会失败。这一切的原因还得从 hard link 和 soft link 的属性说起。
当创建一个文件时,我们需要选择一个路径(pathname),并为文件设置一个字符串形式的名称(symbol)。这其实做了两件事,一是生成一个 inode 结构体,用于记录这个文件的所有相关信息,包括大小、在磁盘上占据的 blocks 数目等,二是将生成的 inode 关联(link)了这个路径和名称。
一个文件的 hard link 增加的是对这个 inode
结构体的关联/指向,并不是一个新的文件。而 soft link
本身就是一个文件,就像 directory
这种特殊文件里存放的是该目录下包含哪些文件,soft link
这种文件里存放的则是指向原 inode 的路径,路径越长,soft link
的大小就越大。这就是为什么 hard link 和原文件的 inode 号相同,而 soft
link 不同。 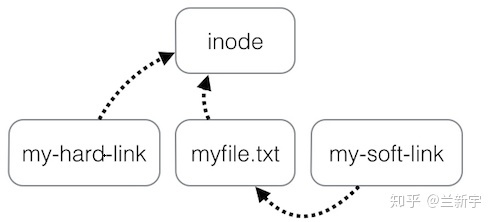
因此,当我们用"rm"命令“删除”原文件时,删除的只是原文件的路径和 inode 之间的关联,而不是这个 inode 本身,文件的内容依然存在于磁盘中,因而只能算是"unlink"。所以直接关联 inode 的 hard link 不受影响,而关联原文件路径的 soft link 此时相当于是一个 dangling reference。
一个 inode 被 link 的数目由"i_nlink"表示(这就是前面"ls -l"命令输出中第二列数值的含义):
1 | unsigned int i_nlink; |
相比起 soft link,hard link 在使用的时候有个限制,就是必须和原文件位于相同的文件系统,原因还是和 inode 编号有关。因为一个 inode 编号只在文件所属的 superblock 中是唯一的,而 hard link 使用和原文件相同的 inode 编号,如果 hard link 跑到其他文件系统,就可能和这些文件系统中既有的文件 inode 编号冲突。
参考文献
https://zhuanlan.zhihu.com/p/106459445
https://zhuanlan.zhihu.com/p/100329177





