
Linux 文件系统(二)块 I/O
系统中能够随机访问固定大小数据片的硬件设备称作块设备,这些固定大小的数据片就称作块。另一种基本的设备类型是字符设备,字符设备按照子节流的方式被有序访问,像串口和键盘就属于字符设备。对于这两种类型的设备,它们的区别在于是否可以随机访问数据。
剖析一个块设备
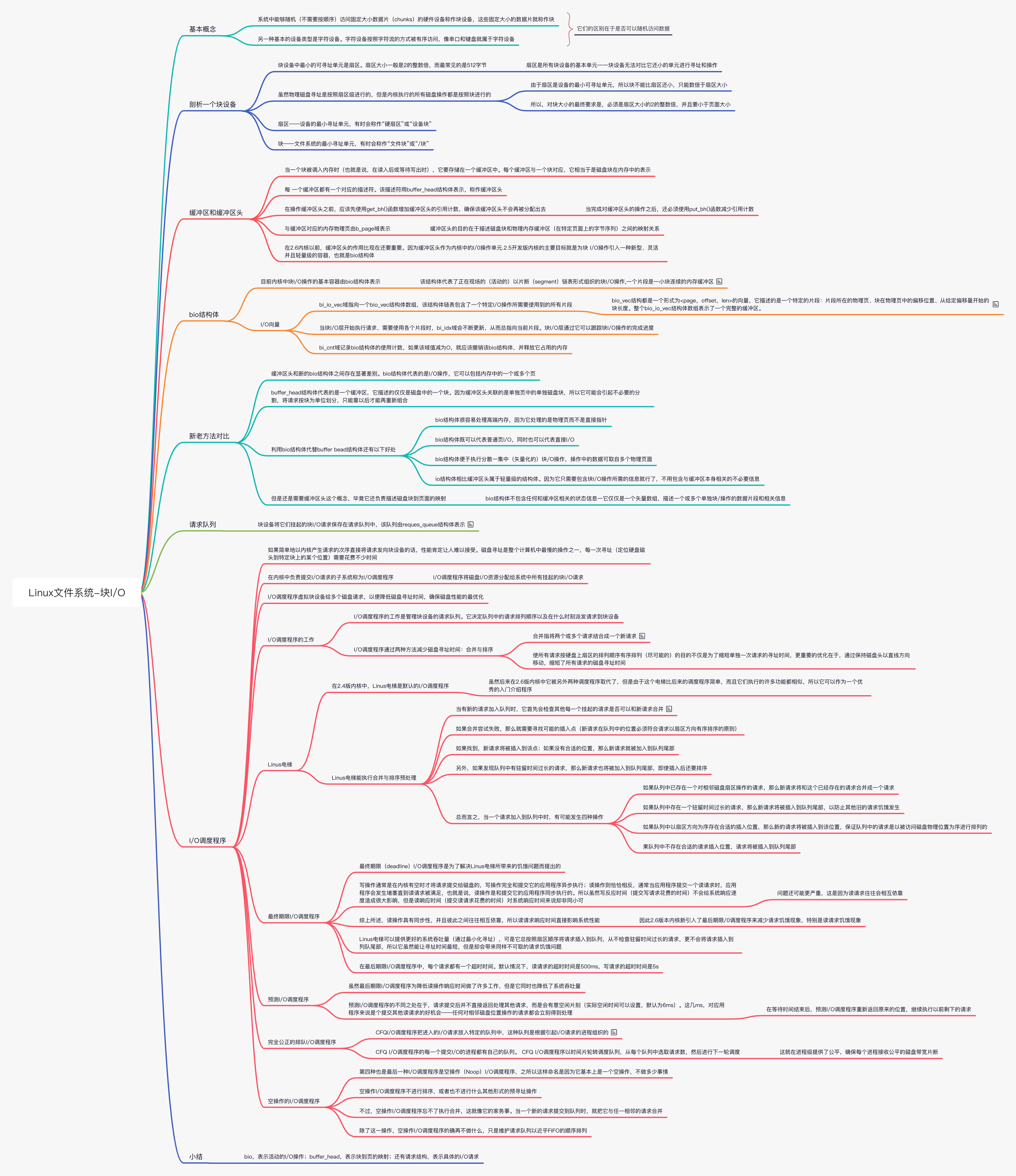
块设备中最小的可寻址单元是扇区(sector)。扇区大小一般是 2 的整数倍,而最常见的是 512 字节。扇区的大小是设备的物理属性,扇区是所有块设备的基本单元—-块设备无法对比它还小的单元进行寻址和操作。
因为各种软件的用途不同,所以它们都会用到自己的最小逻辑可寻址单元--块(block)。块是文件系统的一种抽象,只能基于块来访问文件系统。虽然物理磁盘寻址是按照扇区级进行的,但是内核执行的所有磁盘操作都是按照块进行的。由于扇区是设备的最小可寻址单元,所以块不能比扇区还小,只能数倍于扇区大小。另外,内核(对有扇区的硬件设备)还要求块大小是 2 的整数倍,而且不能超过一个页(page)的长度。所以,对块大小的最终要求是,必须是扇区大小的 2 的整数倍,并且要小于页面大小。所以通常块大小是 512 字节、1KB 或 4KB。
扇区——设备的最小寻址单元;同样的,块——文件系统的最小寻址单元。
缓冲区和缓冲区头
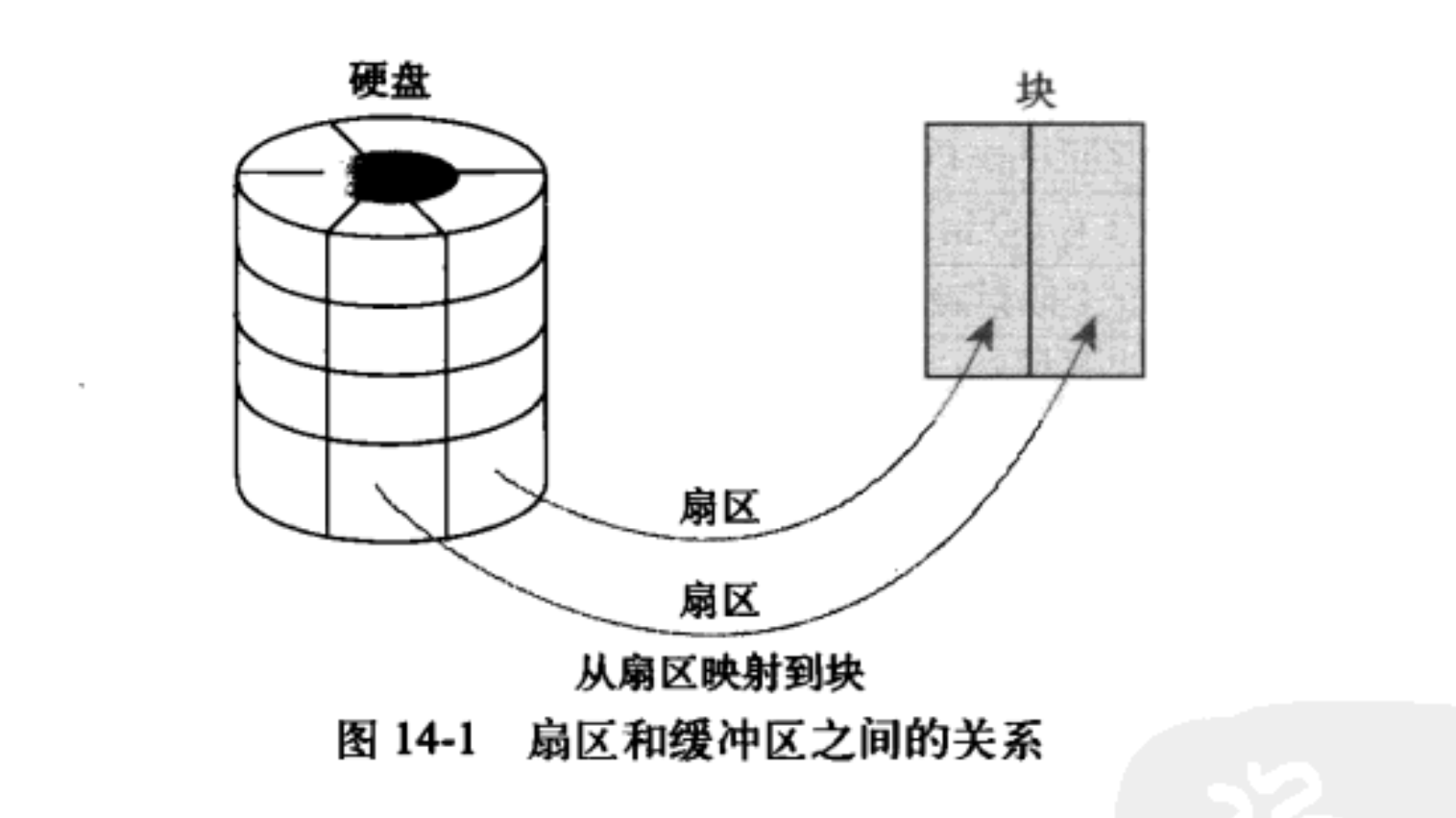
缓冲区头的目的在于描述磁盘块和物理内存缓冲区之间的映射关系。这个结构体在内核中只扮演一个描述符的角色,说明从缓冲区到块的映射关系。
当一个块被调入内存时,它要存储在一个缓冲区中,每个缓冲区与一个块对应,它相当于是磁盘块在内存中的表示。前面提到过,块包含一个或多个扇区,但大小不能超过一个页面,所以一个页可以容纳一个或多个内存中的块。由于内核在处理数据时需要一些相关的控制信息、(比如块属于哪一个块设备,块对应于哪个缓冲区等),所以每一个缓冲区都有一个对应的描述符。该描述符用 buffer head 结构体表示,称作缓冲区头,在文件《linux/buffer_head.h》中定义,它包含了内核操作缓冲区所需要的全部信息。
1 | struct buffer_head { |
在 2.6 内核以前,缓冲区头的作用比现在还要重要。因为缓冲区头作为内核中的 I/O 操作单元,不仅仅描述了从磁盘块到物理内存的映射,而且还是所有块 I/O 操作的容器。可是,将缓冲区头作为 I/O 操作单元带来了两个弊端。
- 首先,缓冲区头是一个很大且不易控制的数据结构体(现在是缩减过了的),而且缓冲区头对数据的操作既不方便也不清晰。
- 缓冲区头带来的第二个弊端是:它仅能描述单个缓冲区,当作为所有 I/O 的容器使用时,缓冲区头会促使内核把对大块数据的 I/O 操作(比如写操作)分解为对多个 buffer_head 结构体进行操作,这样做必然会造成不必要的负担和空间浪费。所以 2.5 开发版内核的主要目标就是为块 I/O 操作引入一种新型、灵活并且轻量级的容器,也就是 bio 结构体。
bio 结构体
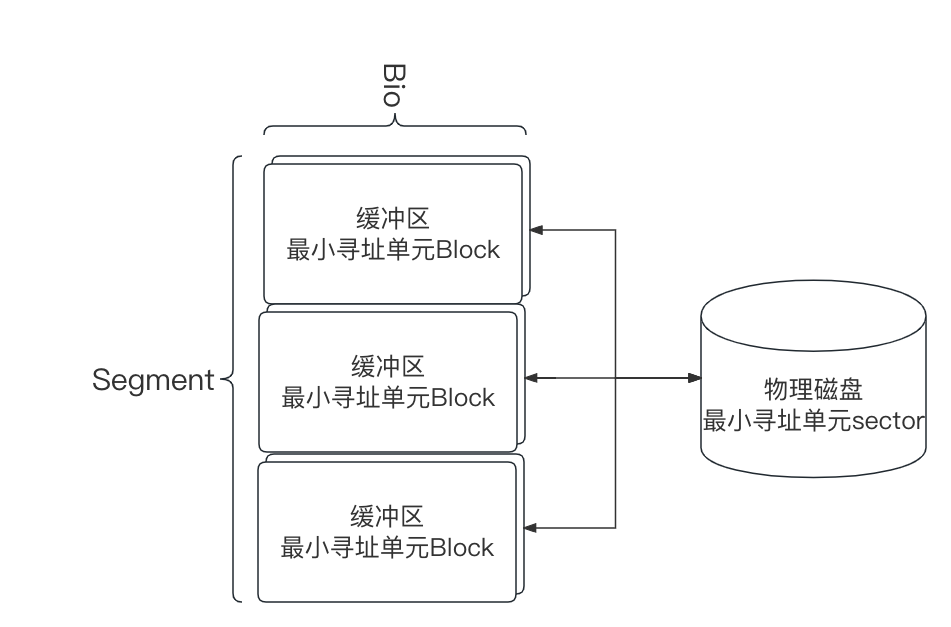
目前内核中块 I/O 操作的基本容器由 bio 结构体表示,该结构体代表了正在现场的(活动的)以片断(segment)链表形式组织的块 I/O 操作。一个片段是一小块连续的内存缓冲区。这样的话,就不需要保证单个缓冲区一定要连续。所以通过用片段来描述缓冲区,即使一个缓冲区分散在内存的多个位置上,bio 结构体也能对内核保证 I/O 操作的执行。像这样的向量 I/O 就是所谓的聚散 I/O。bio 结构体定义于《linux/bio.h》中,下面给出 bio 结构体和各个域的描述。
1 | struct bio { |
使用 bio 结构体的目的主要是代表正在现场执行的 I/O
操作,所以该结构体中的主要域都是用来管理相关信息的,其中最重要的几个域是
bi_io_vecs、bi_vcnt 和 bi_idx。下图显示了 bio
结构体及其他结构体之间的关系。 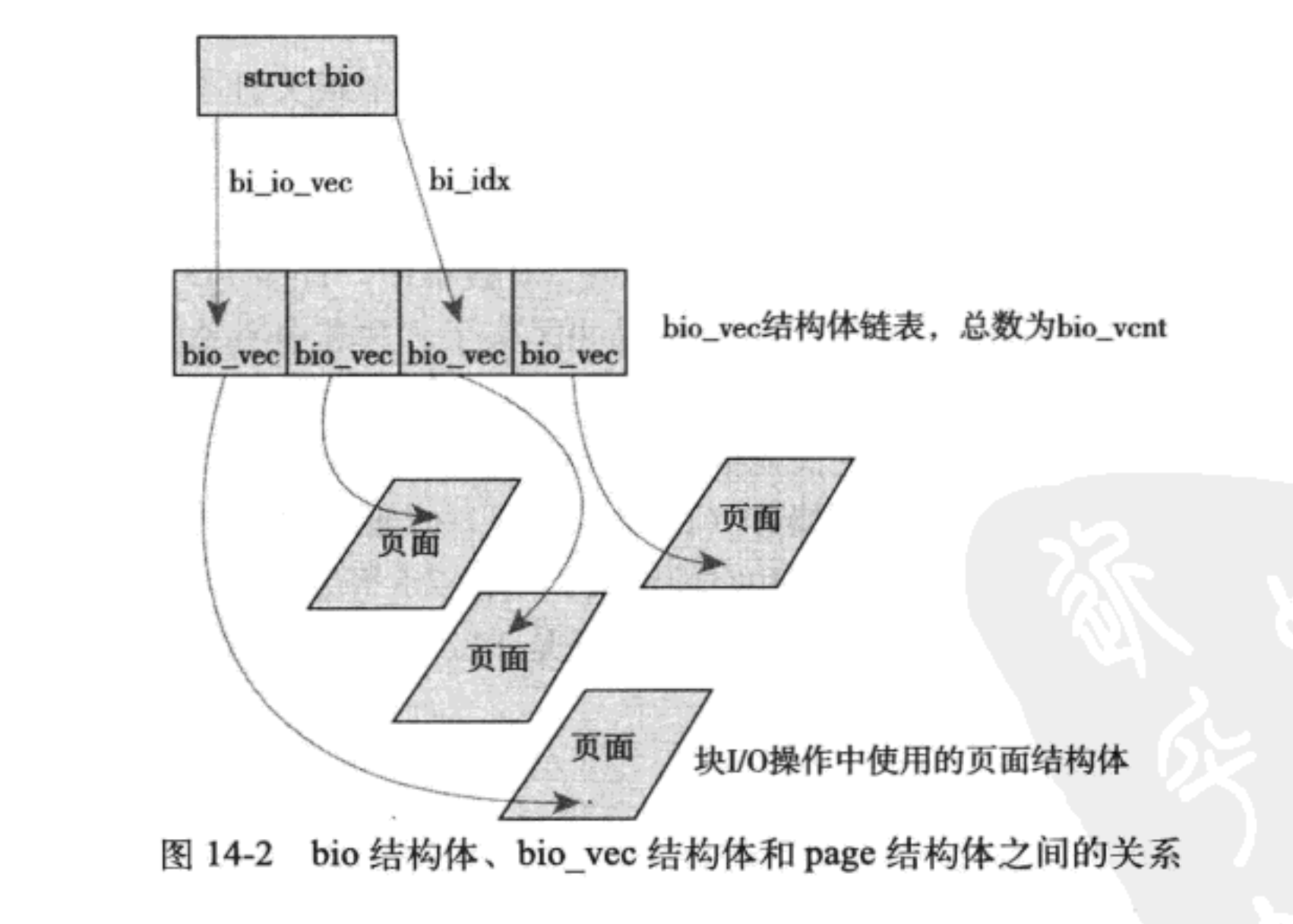
Sector、Block、Segment 之间的关系:
I/O 向量
bi_io_vec 域指向一个 bio_vec 结构体数组,该结构体链表包含了一个特定 I/O 操作所需要使用到的所有片段。每个 bio_vec 结构都是一个形式为<page,offset,len>的向量,它描述的是一个特定的片段:片段所在的物理页、块在物理页中的偏移位置、从给定偏移量开始的块长度。整个 bio_io_vec 结构体数组表示了一个完整的缓冲区。bio_vec 结构定义在《linux/bio.h》文件中:
1 | struct bio_vec { |
在每个给定的块 I/O 操作中,bi_vcnt 域用来描述 bi_io_vec 所指向的 bio_vec 数组中的向量数目。当块 I/O 操作执行完毕后,bi_idx 域指向数组的当前索引。
bi_vcnt 域记录 bio 结构体的使用计数,如果该域值减为 O,就应该撤销该 bio 结构体,并释放它占用的内存。通过下面两个函数管理使用计数。
1 | static inline void bio_get(struct bio *bio) |
前者增加使用计数,后者减少使用计数(如果计数减到 0,则撤销 bio 结构体)。在操作正在活动的 bio 结构体时,一定要首先增加它的使用计数,以免在操作过程中该 bio 结构体被释放;相反,在操作完毕后,要减少使用计数。
新老方法对比
利用 bio 结构体代替 buffer bead 结构体还有以下好处:
- bio 结构体很容易处理高端内存,因为它处理的是物理页而不是直接指针
- bio 结构体既可以代表普通页 I/O,同时也可以代表直接 I/O(指那些不通过页高速缓存的 I/0 操作)
- bio 结构体便于执行分散一集中(矢量化的)块 I/O 操作,操作中的数据可取自多个物理页面
- bio 结构体相比缓冲区头属于轻量级的结构体。因为它只需要包含块 I/O 操作所需的信息就行了,不用包含与缓冲区本身相关的不必要信息
但是还是需要缓冲区头这个概念,毕竟它还负责描述磁盘块到页面的映射。bio 结构体不包含任何和缓冲区相关的状态信息一它仅仅是一个矢量数组,描述一个或多个单独块 I/O 操作的数据片段和相关信息。在当前设置中,当 bio 结构体描述当前正在使用的 I/O 操作时,bufferhead 结构体仍然需要包含缓冲区信息。内核通过这两种结构分别保存各自的信息,可以保证每种结构所含的信息量尽可能地少。
请求队列
块设备将它们挂起的块 I/O 请求保存在请求队列中,该队列由 reques_queue 结构体表示,定义在文件《linux/blkdev.h》中,包含一个双向请求链表以及相关控制信息。通过内核中像文件系统这样高层的代码将请求加入到队列中。请求队列只要不为空,队列对应的块设备驱动程序就会从队列头获取请求,然后将其送入对应的块设备上去。请求队列表中的每一项都是一个单独的请求,由 reques 结构体表示。 队列中的请求由结构体 request 表示,它定义在文件《linux/blkdev.h》中。因为一个请求可能要操作多个连续的磁盘块,所以每个请求可以由多个 bio 结构体组成。注意,虽然磁盘上的块必须连续,但是在内存中这些块并不一定要连续——每个 bio 结构体都可以描述多个片段,而每个请求也可以包含多个 bio 结构体。
I/O 调度程序
为了优化寻址操作,内核既不会简单地按请求接收次序,也不会立即将其提交给磁盘。相反,它会在提交前,先执行名为合并与排序的预操作,这种预操作可以极大地提高系统的整体性能。在内核中负责提交 I/O 请求的子系统称为 I/O 调度程序。
I/O 调度程序的工作
I/O 调度程序通过两种方法减少磁盘寻址时间:合并与排序。
合并指将两个或多个请求结合成一个新请求。请求合并后只需要传递给磁盘一条寻址命令,因此合并请求显然能减少系统开销和磁盘寻址次数。
整个请求队列将按扇区增长方向有序排列。使所有请求按硬盘上扇区的排列顺序有序排列(尽可能的)的目的不仅是为了缩短单独一次请求的寻址时间,更重要的优化在于,通过保持磁盘头以直线方向移动,缩短了所有请求的磁盘寻址时间。该排序算法类似于电梯调度,所以 I/O 调度程序称作电梯调度。
Linus 电梯
当一个请求加入到队列中时,有可能发生四种操作,它们依次是:
- 如果队列中已存在一个对相邻磁盘扇区操作的请求,那么新请求将和这个已经存在的请求合并成一个请求
- 如果队列中存在一个驻留时间过长的请求,那么新请求将被插入到队列尾部,以防止其他旧的请求饥饿发生
- 如果队列中以扇区方向为序存在合适的插入位置,那么新的请求将被插入到该位置,保证队列中的请求是以被访问磁盘物理位置为序进行排列的
- 如果队列中不存在合适的请求插入位置,请求将被插入到队列尾部
最终期限 I/O 调度程序
最终期限(deadline)I/O 调度程序是为了解决 Linus 电梯所带来的饥饿问题而提出的。
普通的请求饥饿还会带来名为写一饥饿一读(writes-starving-reads)这种特殊问题。写操作完全和提交它的应用程序异步执行;读操作则恰恰相反是同步的,所以读操作响应时间对系统的性能非常重要。
问题还可能更严重,这是因为读请求往往会相互依靠。当读操作阻塞后,后面的读请求操作也会跟着阻塞。因此 2.6 版本内核新引入了最后期限 I/0 调度程序来减少请求饥饿现象,特别是读请求饥饿现象。
在最后期限 I/O 调度程序中,每个请求都有一个超时时间。
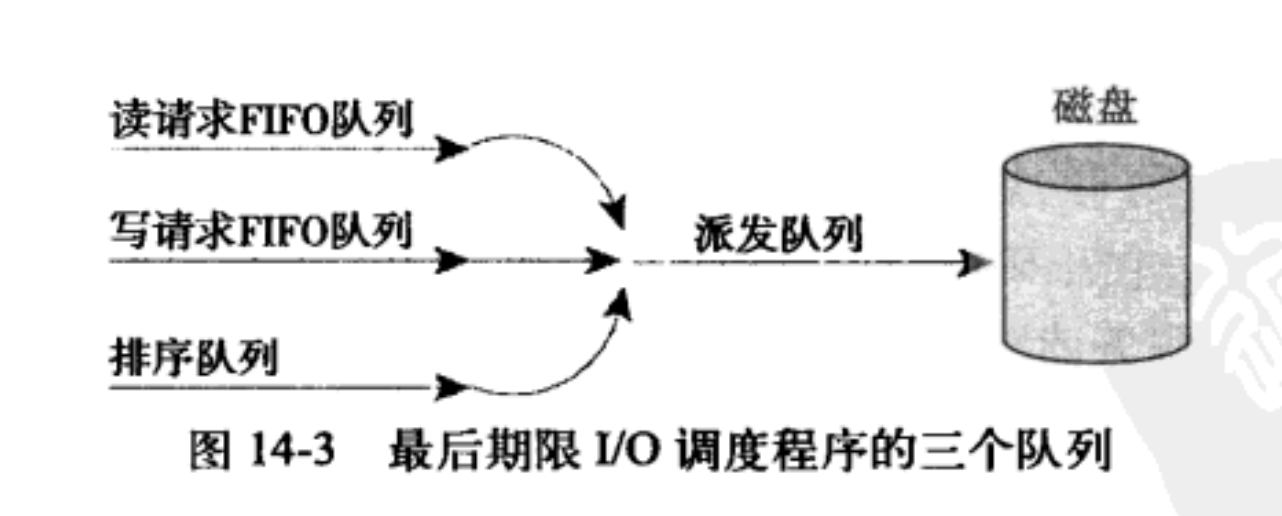
默认情况下,读请求的超时时间是 500ms,写请求的超时时间是 5s。最后期限 I/O 调度请求类似于 Linus 电梯,也以磁盘物理位置为次序维护请求队列,这个队列称为排序队列。当一个新请求递交给排序队列时,
- 最后期限 I/O 调度程序在执行合并和插入请求时类似于 Linus 电梯执行合并排序到排队序列
- 同时也会以请求类型为依据将它们插入到额外队列中。读请求按次序被插入到特定的读 FIFO 队列中
- 写请求被插入到特定的写 FIFO 队列中
虽然普通队列以磁盘扇区为序进行排列,但是这些队列是以 FIFO(很有效,以时间为基准排序)形式组织的,结果新队列总是被加人到队列尾部。对于普通操作来说,最后期限 I/O 调度程序将请求从排序队列的头部取下,再推入到派发队列中,派发队列然后将请求提交给磁盘驱动,从而保证了最小化的请求寻址。
注意,最后期限 I/O 调度算法并不能严格保证请求的响应时间,但是通常情况下,可以在请求超时或超时前提交和执行,以防止请求饥饿现象的发生。最后期限 I/O 调度程序的实现在文件 block/deadline-iosched.c 中。
预测 I/O 调度程序
虽然最后期限 I/O 调度程序为降低读操作响应时间做了许多工作,但是它同时也降低了系统吞吐量。预测(Anticipatory)I/O 调度程序的目标就是在保持良好的读响应的同时也能提供良好的全局吞吐量。 预测 I/O 调度程序最主要的改进是它增加了预测启发(anticipation-heuristic)能力。请求提交后并不直接返回处理其他请求,而是会有意空闲片刻(实际空闲时间可以设置,默认为 6ms)。这几 ms,对应用程序来说是个提交其他读请求的好机会——任何对相邻磁盘位置操作的请求都会立刻得到处理。在等待时间结束后,预测 I/O 调度程序重新返回原来的位置,继续执行以前剩下的请求。
预测 I/O 调度程序的实现在文件内核源代码树的 block/as-iosched.c 中,它是 Linux 内核中缺省的 I/O 调度程序。
完全公正的排队 I/O 调度程序
完全公正的排队 I/O 调度程序(Complete Fair Queuing,CFQ)是为专有工作负荷设计的,CFQ I/O 调度程序把进入的 I/O 请求放入特定的队列中,这种队列是根据引起 I/O 请求的进程组织的。例如,来自 foo 进程的 I/O 请求进入 foo 队列,而来自 bar 进程的 I/O 请求进入 bar 队列。在每个队列中,刚进入的请求与相邻请求合并在一起,并进行插入分类。队列由此按扇区方式分类,这与其他 I/O 调度程序队列类似。CFQ I/O 调度程序的差异在于每一个提交 I/O 的进程都有自己的队列。
CFQ I/O 调度程序以时间片轮转调度队列,从每个队列中选取请求数(默认值为,可以进行配置),然后进行下一轮调度。这就在进程级提供了公平,确保每个进程接收公平的磁盘带宽片断。
空操作的 I/O 调度程序
空操作(Noop)I/O 调度程序不进行排序,或者也不进行什么其他形式的预寻址操作。不过,空操作 I/O 调度程序忘不了执行合并。除了这一操作,空操作 I/O 调度程序的确再不做什么,只是维护请求队列以近乎 FIFO 的顺序排列,块设备驱动程序便可以从这种队列中摘取请求。
空操作 I/O 调度程序位于 block/noop-iosched.c,它是专为随机访问设备而设计的。
参考文献
《linux 内核设计与实现》





