
Linux 内存管理(十)KSM
概述
KSM 指 Kernel SamePage Merging,即内核同页合并,用于合并内容相同的页面。KSM 的出现是为了优化虚拟化中产生的冗余页面。 KSM 允许合并同一个进程或不同进程之间内容相同的匿名页面,这对应用程序来说是不可见的。把这些相同的页面合并成一个只读的页面,从而释放出多余的物理页面,当应用程序需要改变页面内容时,会发生写时复制。
使能 KSM
KSM 只会处理通过 madvise 系统调用显式指定的用户进程地址空间,因此用户程序想使用这个功能就必须在分配地址空间时显式地调用 madvise(addr,length,MADV_MERGEA BLE)。如果用户想在 KSM 中取消某一个用户进程地址空间的合并功能,也需要显式地调用 madvise(addr,length,MADV_UNMERGEABLE)。 下面是测试 KSM 的 test.c 程序的代码片段,使用 mmap():来创建一个文件的私有映射,并且调用 memset() 写入这些私有映射的内容缓存页面中。
1 | 《测试 KSM 的 test.c 程序的代码片段》 |
编译上述 test.c 程序。
1 | gcc test.c -o test |
使用 dd 命令创建一个 ksm.dat 文件,即创建 100MB 大小的文件。
1 | dd if=/dev/zero of=ksm.dat bs=1M count=100 |
使能 KSM。
1 | echo 1 >/sys/kernel/mm/ksm/run |
运行 test.c 程序。
1 | #./test ksm.dat |
过一段时间之后,查看系统有多少页面合并了。
1 | root@benshushu#cat /sys/kernel/mm/ksm/pages_sharing |
可以看到 pages_shared 为 100 说明系统有 100 个共享的页面。若有 100 个页面的内同,它们可以合并成一个页面,这时 pages_shared 为 1。 pages_sharing 为 25500 说明有 25500 个页面合并了。 100MB 的内存可存放 25600 个页面。因此,我们可以看到,KSM 把这 25600 个页面分别合并成 1 共享的页面,每一个共享页面里共享了其他的 255 个页面,为什么会这样?我们稍后详细解析。 pages_unshared 表示当前未合并页面的数量。
1 | rootebenshushut cat /sys/kernel/mn/ksm/stable_node_chains |
stable_node_chains 表示包含了链式的稳定节点的个数,当前系统中为 1,说明只有一个链式的稳定节点,但是这个稳定的节点里包含了链表。 stable_node_dups 表示稳定的节点所在的链表包含的元素总数。 KSM 的 sysfs 节点在/sys/kernel/mm/ksm/目录下,其主要节点的描述如下所示。
- run:可以设置为 0~2。若设置 0,暂停 ksmd 内核线程;若设置 1,启动 ksmd 内核线程;若设置 2,取消所有已经合并好的页面
- full_scans: 完整扫描和合并区域的次数
- pages_volatile: 表示还没扫描和合并的页面数量。若由于页面内容更改过快导致两次计算的校验值不相等,那么这些页面是无法添加到红黑树里的
- sleep_millisecs: ksmd 内核线程扫描一次的时间间隔
- pages_to_scan: 单次扫描页面的数量
- pages_shared: 合并后的页面数。如果 100 个页面的内容相同,那么可以把它们合并成一个页面,这时 pages_shared 的值为 1
- pages_sharing: 共享的页面数。如果两个页面的内容相同,它们可以合并成一个页面,那么有一个页面要作为稳定的节点,这时 pages_shared 的值为 1,pages_sharing 也为 1。第 3 个页面也合并进来后,pages_sharing 的值为 2,表示两个页面共享同一个稳定的节点
- pages_unshared: 当前未合并页面数量
- max_page_sharing: 这是在 Linux4.3 内核中新增的参数,表示一个稳定的节点最多可以合并的页面数量。这个值默认是 256
- stable_node_chains: 链表类型的稳定节点的个数。每个链式的稳定节点代表页面内容相同的 KM 页面。这个链式的稳定节点可以包含多个 dup 成员,每个 dup 成员最多包含 256 个共享的页面
- stable_node_dups: 链表中 dup 成员的个数。这些 dup 成员会连接到链式的稳定节点的 hlist 链表中
KSM 在初始化时会创建一个名为 ksmd 的内核线程。
1 | <mm/ksm.c> |
在 tes.c 程序中创建私有映射(MAP_PRIVATE)之后,显式地调用 madvise 系统调用把用户进程地址空间添加到 Linux 内核的 KSM 系统中。
1 | <madvise()->ksm_madvise()-> ksm_enter()> |
ksm_enter() 函数会把当前的 mm_struct 数据结构添加到 mm_slots_hash 哈希表中。另外把 mm_slot 添加到 ksm_scan.mm_slot->mm_list 链表中。最后,设置 mm->flags 中的 MMF_VM_MERGEABLE 标志位,表示这个进程已经被添加到 KSM 系统中。
1 | <ksm 内核线程> |
ksm_scan_thread() 是 ksmd 内核线程的主干,它运行 ksm_do_scan() 函数,扫描和合并 100 个页面,见 ksm_thread_pages_to_scan 参数,然后等待 20ms,见 ksm_thread_sleep_millisecs 参数,这两个参数可以在/sys/kernel/mm/ksm 目录下设置和修改。
1 | <ksmd 内核线程> |
ksm_do_scan() 函数在 while 循环中尝试合并 scan_npages 个页面, scan_get_next_rmap_item() 获取一个合适的匿名页面。 cmp_and_merge_page() 函数会让页面在 KSM 中稳定和不稳定的两棵红黑树中查找是否有可以合并的对象,并且尝试合并他们。
KSM 基本实现
为了让读者先有一个初步的认识,本节先介绍 Lnux4.13 内核之前的 KSM 实现,后文会介绍 Linux5.0 内核中的实现。
KSM
机制下采用两棵红黑树来管理扫描的页面和己经合并的页面。第一棵红黑树称为不稳定红黑树,里面存放了还没有合并的页面;第二棵红黑树称为稳定红黑树,已经合并的页面会生成一个节点,这个节点为稳定节点。如两个页面的内容是一样的,KSM
扫描并发现了它们,因此这两个页面就可以合并成一个页面。对于这个合并后的页面,会设置只读属性,其中一个页面会作为稳定的节点挂载到稳定的红黑树中之后,另外一个页面就会被释放了。但是这两个页面的
rmap_item 数据结构会被添如到稳定节点中的 hist 链表中,如下图所示。 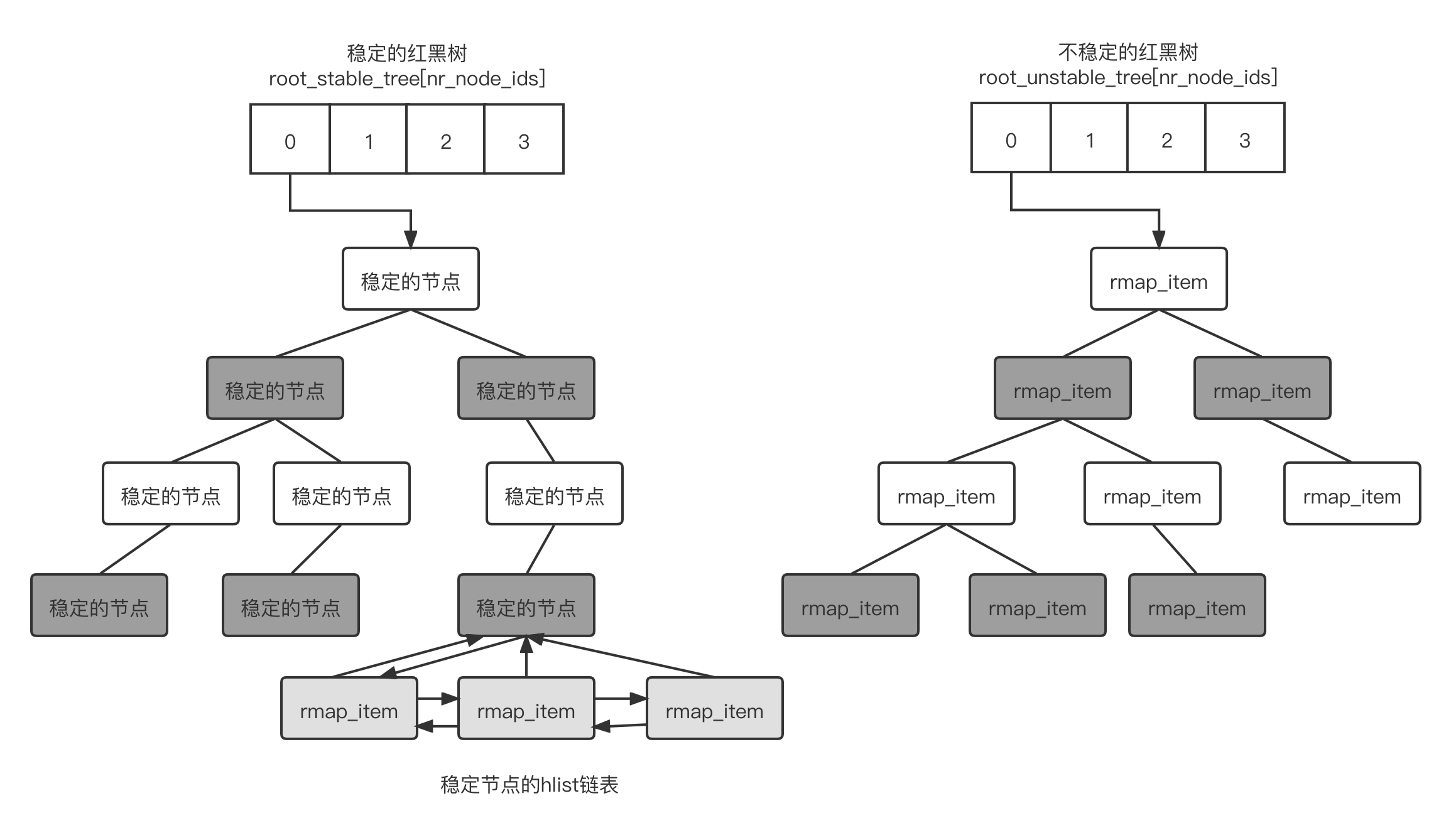
我们假设有 3 个 VMA(表示进程地址空间,VMA 的大小正好是一个页面的大小,分别有 3 个页面映射这 3 个 VMA。这 3 个页面准备通过 KSM 来扫描和合并,这 3 个页面的内容是相同的。具体步骤如下。
- 3 个页面会被添加到 KSM 中,第一轮扫描中分别给这 3 个页面分配 rmap_item 数据结构来描述它们,并且分别给它计算校验和,如图(a)所示
- 第二轮扫描中,先扫描 page0,若当前稳定的红黑树没有成员,那么不能比较和加入稳定的红黑树。接着,第二次计算校验值,如果 page0 的校验值没有发生变化,那么把 page0 的 rmap_item() 添加到不稳定的红黑树中,如图(b)所示。如果此时校验值发生了变化,说明页面内容发生变化,这种页面不适合添加到不稳定的红黑树中
- 扫描 page1,当前稳定的红黑树中没有成员,略过稳定的红黑树的搜索。搜索不稳定的红黑树,遍历红黑树中所有成员。 page1 发现自己的内容与不稳定的红黑树中的 rmap_item() 一致,因此尝试将 page0 和 page1 合并成一个稳定的节点,合并过程就是让 WMA0 对映的虚拟地址、vaddr0 映时到 page1 上。,并且把对应的 PTE 属性修改成只读展性。另外,VMA1 映射到 page1 的 PTE 属性也设置为只读属性。新创建一个稳定的节点,这个节点包含了 page1 的页帧号等信息,把这个稳定的节点添加到稳定的红黑树中。把代表 page0 的 map _item0 和 page1 的 rmap_item1 添加到这个稳定的节点的 hlist 链表中,最后释放 page0 页面,如图(c)所示
- 扫描
page2。因为稳定的红黑树中有成员,因此,先和稳定的红黑树中的成员进行比较,检査是否可以合并。若发现
page2 的内容和稳定的节点内容一致,那么把 VMA2 中的 vaddr2
映射到稳定的节点对应的 page1 上,并且把 PTE 属性设置为只读属性。把代表
page2 的 rmap_item2 添加到稳定的节点的 hlist 链表中,最后释放 page2
页面,如图(d)所示
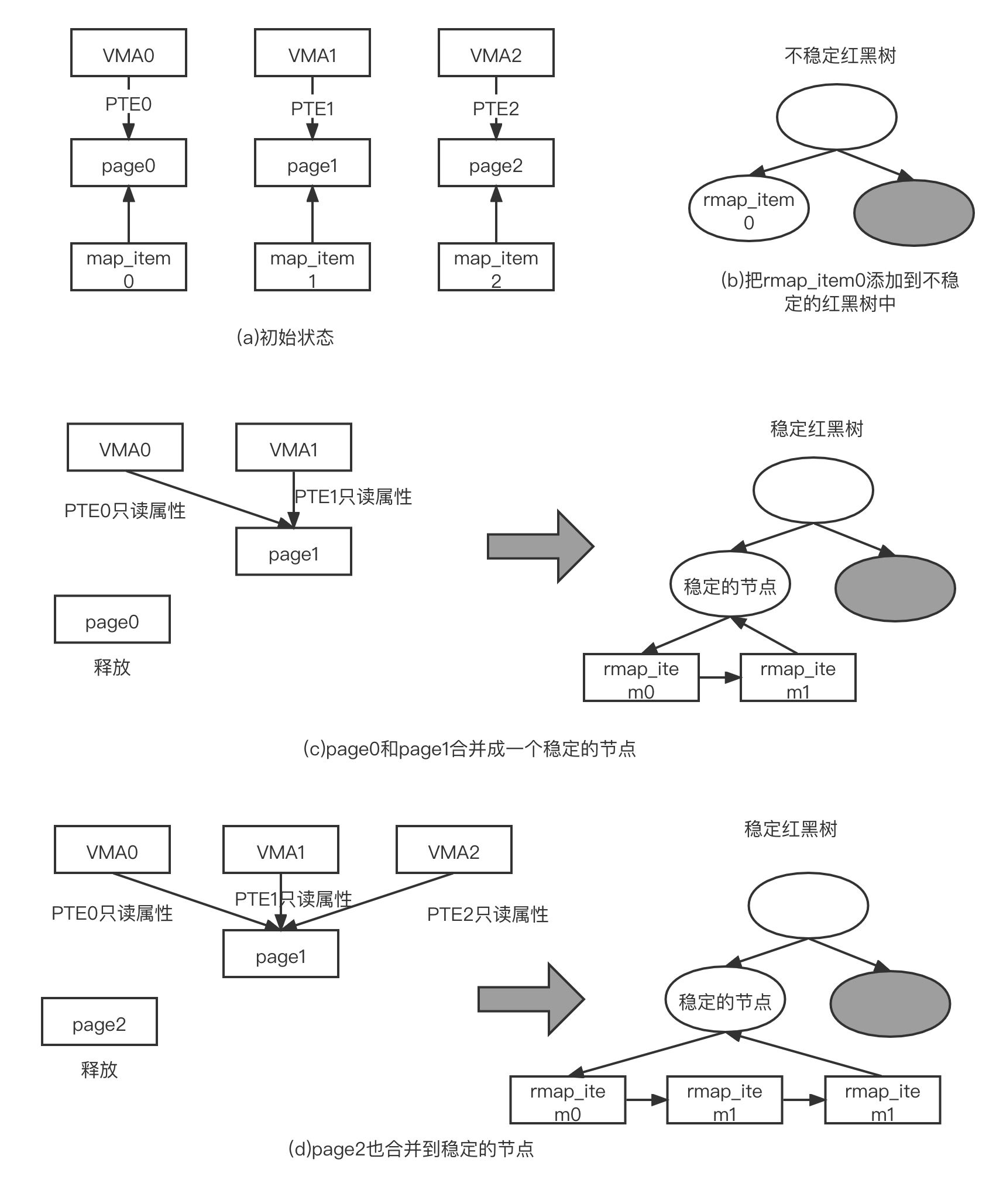
上述步骤完成之后,VMAO~VMA2 这 3 个 VMA 对应的虚拟地址(vadr)都映射到 page1 上,并且映射的 3 个 PTE 属性都是只读属性,page1 生成一个稳定的节点并被添加到了稳定的红黑树中,page0 和 page2 被释放了。
新版本 KSM 的新特性
新版本的 KSM(如 Linux5.0 内核的 KSM)比 Linux4.0 内核的 KSM 新增了两项特性。
- 对内容全是零的页面进行特殊处理
- 对稳定的节点的 hlis 链表进行改造,以防止大量的相同的页面聚集在一个稳定的节点中,导致页面迁移、内存规整等机制长时间等待这个页面
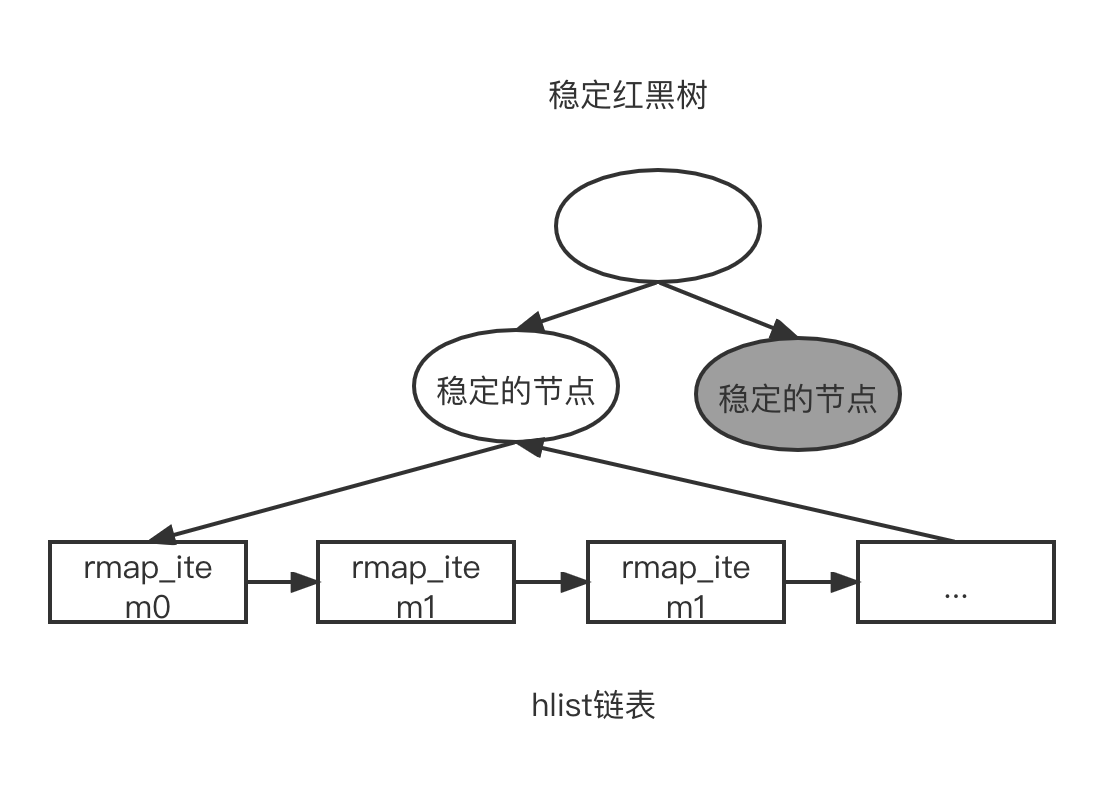
新特性中,第一项实现起来比较简单,系统中己经存在了系统零页,我们可以对这个系统零页预先计算检査和。若在扫描页面时发现页面的检査和等于系统零页的检查和,那么直接修改这个页面的映射关系,让其映射到系统零页,这样可以释放这个页面。 第二项新特性实现起来就比较复杂了。主要原因是在一些大型的服务器中,会把大量的页面(如几百万个页面)合并到一个稳定的节点中。 页面迁移机制会调用 RMAP 机制来遍历这个稳定节点中所有的 rmap_item,如图所示。在 try_to_unmap_one() 函数解除页表映射关系时,需要调用 flush_tlb_page() 函数来刷新 TLB。CPU 内部发送 IPI 广播来通知其他 CPU 做了这个 TLB 刷新动作,这个页面的 PTE 已经被解除映射关系,大概需要 10pus 的时间。若需要遍历 1 万个页表项,那么将持续 100ms;若需要遍历几十万甚至几百万个页面,那么将持续更长时间。在调用 my_to_unmap() 函数之前需要申请这个页面的锁,但是其他进程有可能在等待这个页锁,那将会是一场“灾难”,足以让服务器宕机。具体流程如下:
1 | grate_pages () |
在 Linux4.13 内核中, Red Hat 工程师 Andrea Arcangeli
对这个问题进行了修复。新办法是限制共享页面的数量在 256 以内,这样遍历
256
个页表项的时间将会限制在毫秒不会导致系统宕机。新的解决方案扩充了稳定节点的
hlist 链表结构, rmap_items 超过 256
个之后,扩展稳定的节点为链表。每个链表的成员都是一个稳定的节点,每个稳定的节点有一个链表,这个
hlist 链表中可以添加新的
rmap_items。另外,还需要把稳定的节点和链表的头在红黑树中做一个交换。
新版本的稳定的节点包含两个形态,而且它们同时存放在稳定的红黑树中,如图所示:
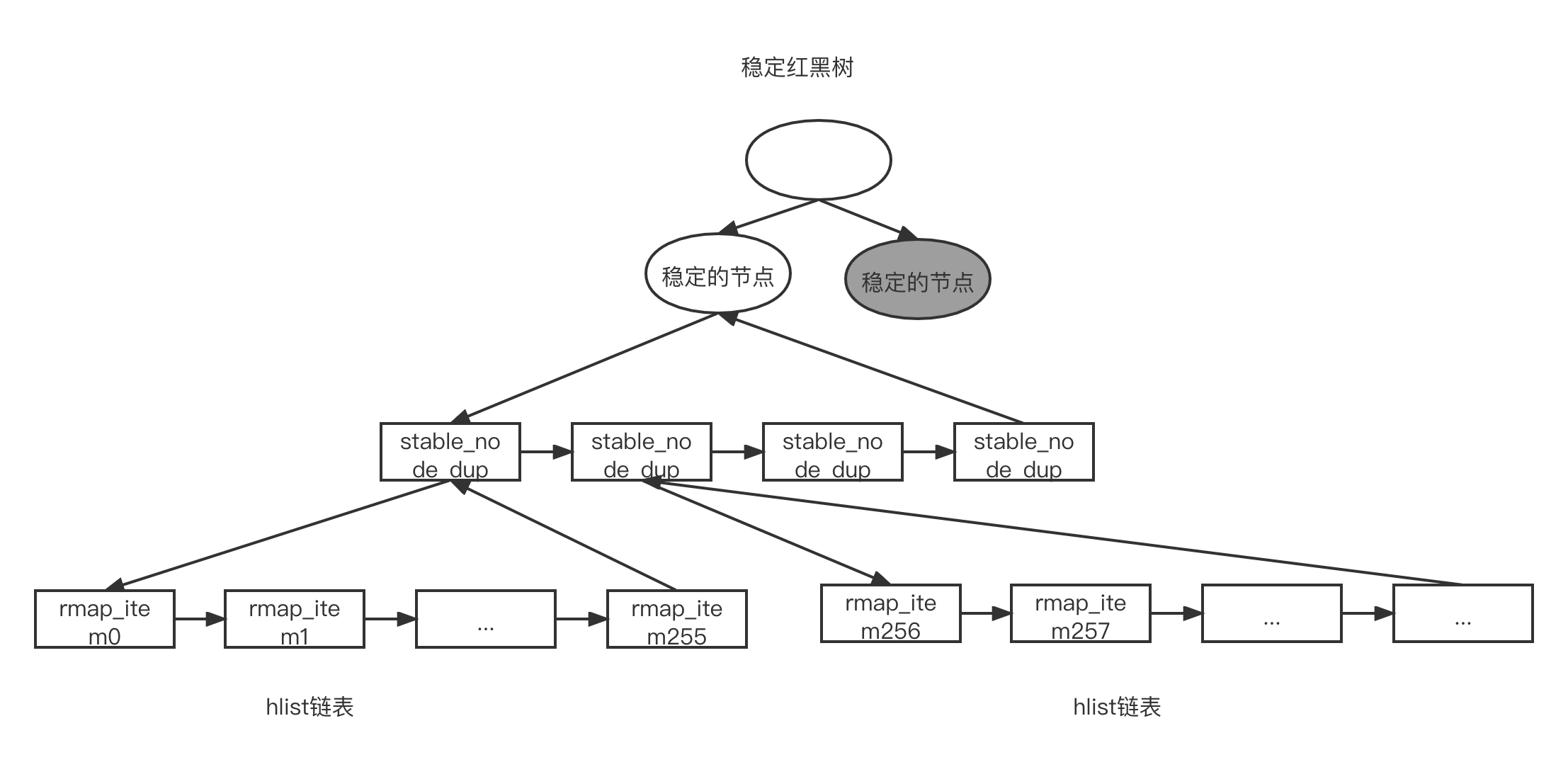
- 传统的稳定的节点:兼容旧版本的稳定的节点格式。
- 链式稳定的节点:新版本的链式节点格式。
下面以 test.c 程序为例,假设现在系统产生了 1000 个页面,并且这 1000 个页面的内容都是相同的,每个页面对应不同的 VMA,这些 VMA 的大小正好是一个页面大小。接下来观察新版本的 KSM 如何处理这些页面,如何创建新版本的链式稳定的节点。
第 1 次扫描这 1000 个页面。第 1 次扫描页面时会计算每个页面的检验和。部分代码如下:
1 | statc void cmp_and_merge_page(struct page *page, struct rmap_item *rmap_item) |
第 2 次扫描中,先看第一个页面(编号为 page0,以此类推)的情况,它首先进入 cmp_and_merge_page() 函数。具体过程如下:
- cmp_and_merge_page() 函数会遍历稳定的红黑树中每个稳定的节点,并和 page0 进行比较,判断内容是否一致。若内容一致,则将页面合并到稳定的节点中。因为这时 stable 红黑树还是空的,所以跳过 stable_tree_searche() 函数
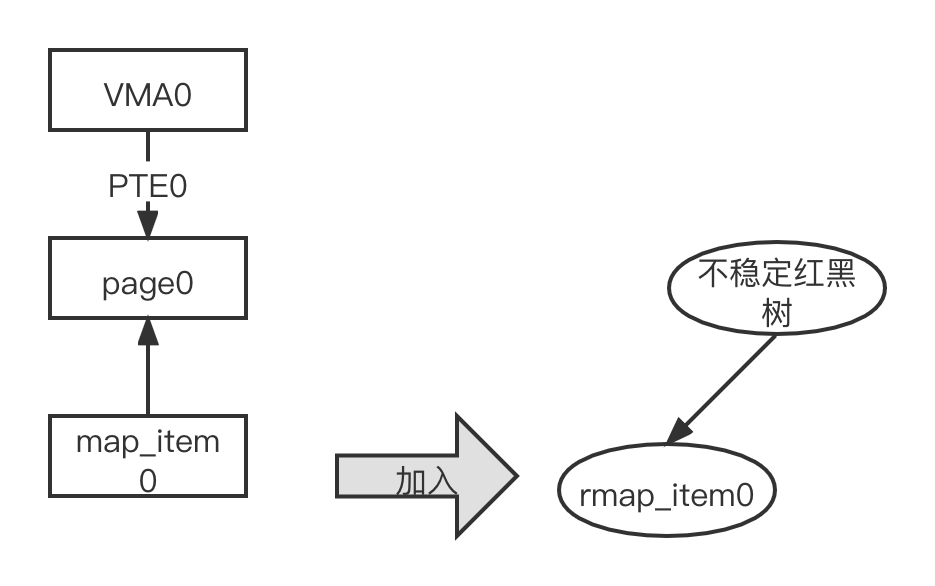
- 如果页面校验值不变,则遍历 unstable 红黑树中的每一个 rmap_item
节点。这时,不稳定的红黑树也还是空的,因此直接把 rmap_item0
添加到不稳定的红黑树中,扫描第 i 个页面,如图所示
部分代码如下。
1 | struct rmap_item * unstable_tree_search_insert() |
接下来,扫描第 2 个页面(pge)。具体过程如下
- 略过稳定的红黑树
- 遍历不稳定的红黑树,现在不稳定的红黑树中有个成员 rmap_item0, unstable_tree_search_insert() 函数取出 rmap_item0,然后和 page1 进行内容比较。 try_to_merge_two_page() 函数会比较 rmap_item0 对应的 page0 和 page1,若发现内容一致,则将其合并成一个页面。过程就是让 VMA0 对应的虚拟地址 vaddr0 映射到 page1 上,并且把对应的 PTE 属性修改成只读属性。另外,WMA1 映射到 page1 的 PTE 属性也设置为只读属性
- 在 stable_tree_inserter() 函数中,因为 stable 红黑树为空,所以会新建一个稳定的节点 (stable node 数据结构),我们称它为 stable_node_dup0 或者 node_dup0
- page1 的页帧号也会记录在 stable_node_dup0->kpfn 中,并且 rmap_list_len 值为 0. 调用 set_page_stable_node() 数把 page1 设置成 KSM 页面,详见 mm/ksm.c 文件中的代码
1 | <mm/ksm.c> |
- 由于这时不需要为稳定的节点建立链表,因此第 1884 行代码的 need_chain 为 ifalse 最后直接把 stable_node_dup0 添加到稳定的红黑树中
- 调用 stable_tree_append(),分别把 page0 对应的 rmap_item0 和 page1 对应的 rmap_item1 添加到 stable_node_dup0->hlist 链表中。增加 ksm_pages_ shared 和 ksm_pages_sharing 计数,这时 ksm_pages_sharing 为 1, ksm_pages_shared 为 1, stable_node_dup0->rmap_hlist_len 为 2
- 释放 page0。
合并过程如图所示。 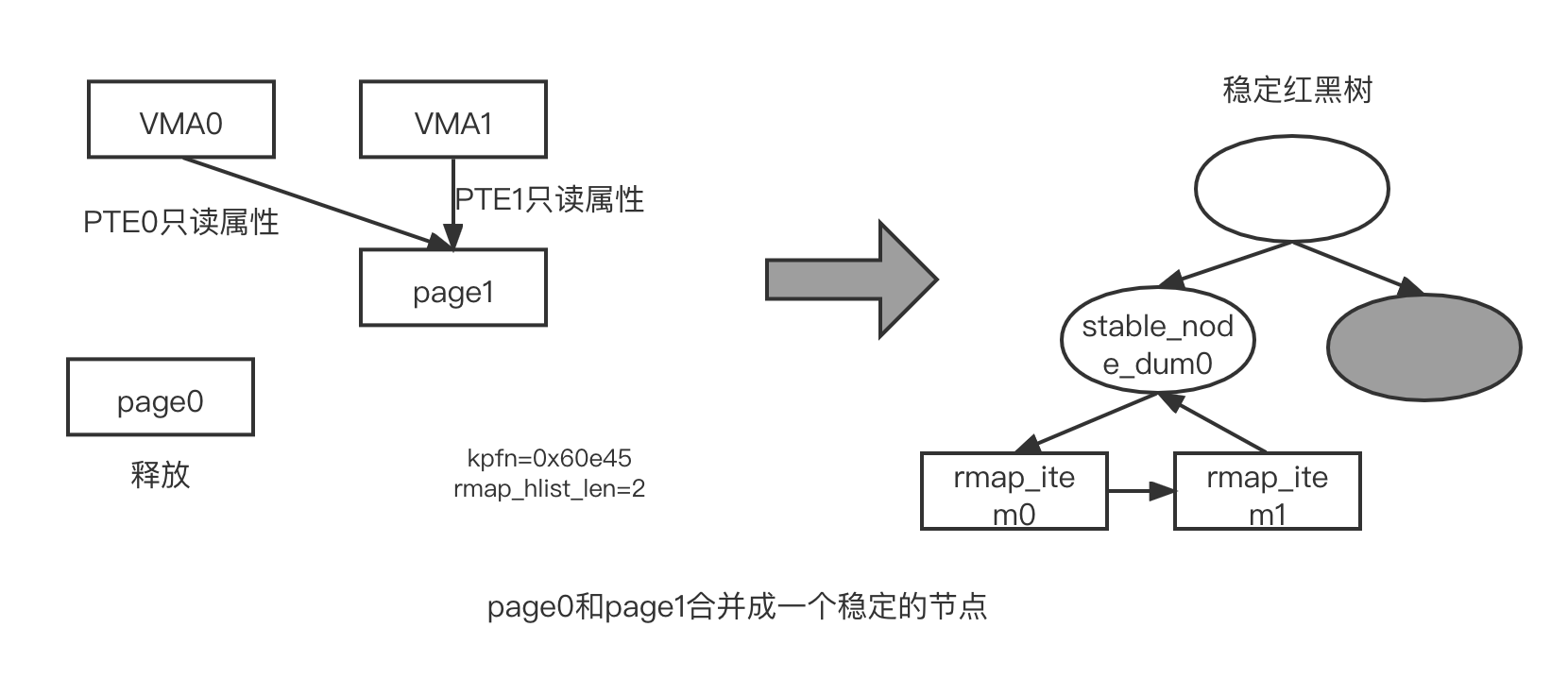
接下来,扫描第 3 个页面(page2)。具体过程如下。
- 遍历 stable 红黑树,见 stable_tree_search() 函数。通过 rb_entry() 取出稳定的红黑树节点这时,稳定的红黑树只有一个节点,那就是 stable_node_dup()
- 调用 chain_prune() 函数。在内部调用__stable_node_chain() 函数时会对稳定的点行判断
1 | <chain_prune()->__stable_node_chain()> |
- is_stable_node_chain 判断这个稳定的节点是否为链式稳定的节点。判断依据是 rmap_hlist_len 是否为 STABLE_NODE_CHAIN。链式稳定的节点所在的 hlist 链表是不存放 rmap_item 的,并且它的 rmap_hlist_len 会初始化为一个固定值, STABLE_NODE_CHAIN(默认初始值为-1024),我们由此来判断该节点是否为链式稳定的节点
1 | define STABLE_NODE_CHAIN -1024 |
- stable_node_dup0 显然不是链式的稳定的节点,它是传统的稳定的节点。 is_page_sharing_candidate() 判断这个节点中是否还能存放 rmap_item。默认情况下,我们规定每个节点的 hlist 链表最多只能存放 256 个成员
- 调用 get_ksm_page() 函数返回 stable_node_dup0 节点对应的 page 数据结构
- 比较 stable_node_dup0 对应的页面(即 tree_page)和 page2 的页面内容是否一样,若一样, stable_tree_searche() 函数会返回 tree_page
- 调用 ty_to_merge_with_ksm_page() 函数尝试合并 tree_page 和 pge2。若能合并,那么调用 stable_tree_append() 函数把 page2 对应的 rmap_item2 添加到 stable_node_dup0->hlist 链表中。增加 ksm_pages_sharing 的值,此时 ksm_pages_sharing 的值为 2。这时, stable_node_dup0->hlist_len 为 3
- 释放 page2
上述过程如图所示。 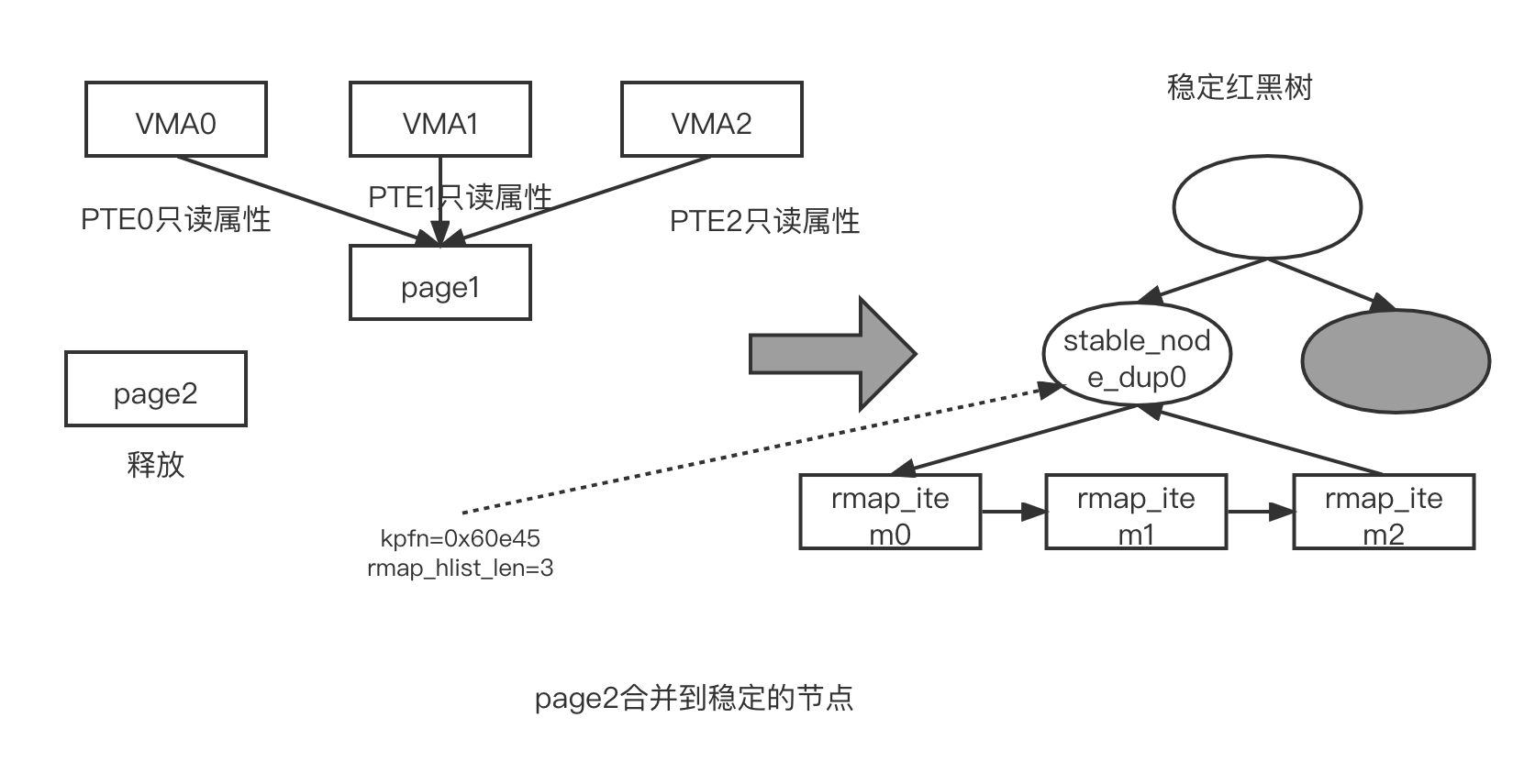
接下来,扫描第 4 个页面,一直到第 256 个页面。和扫描第 3 个页面一样,这些页面都会合并到 stable_node_dup0 对应的 tree_page 中,其对应的 rmap_item 都会被添加到 stable_node_dup0->hlist 链表中,这时 stable_node_dupO->rmap_hlist_len 的值为 256, ksm_pages_sharing 的值为 255.
接下来,扫描第 257 个页面(p2ge256)。具体过程如下:
- 遍历稳定的红黑树,见 stable_tree_search() 函数
- 如果在 chain_prune->__stable_node_chain()->is_page_sharing_candidate() 函数中发现 hlist 链表的成员个数已经到达最大值( ksm_max_page_ sharing),那么会返回 NULL,并且 stable_node_dup 参数也返回 NULL
- stable_tree_search() 函数调用 stable_node_dup_any() 来获取稳定的节点,get_ksm_page() 获取这个稳定的节点对应的 tree_page。比较 tree_page 和 page256 的内容时发现二者是一致的,但是因为 stable_node_dup 参数为 NULL,所以在第 1653~1666 行里会返回 NULL。这里在注释里对代码做了解释,当我们发现被扫描页面的内容和稳定的节点的页面内容一致时,但是因为这时稳定的节点的 hlist 链表已经满了,所以我们必须从不稳定的红黑树中找到另外一个页面、进行合并,创建一个新的 KSM 共享页面
- 因为 stable_tree_search() 函数返回 NULL,所以直接遍历不稳定的红黑树。此时,不稳定的红黑树没有成员,因此可以直接把 page256 对应的 map_item 添加到不稳定的红黑树中
接下来,扫描第 258 个页面(page257)。具体过程如下。
- 遍历稳定的红黑树,见 stable_tree_search() 函数。和步骤(6)一样,因为 stable_node_dup0->hlist 链表满了,所以直接返回 NULL
- 调用 unstable_tree_search_insert() 函数。若发现 page257 和不稳定红黑树的成员内容一致,返回 tree_rmap_item
- 调用 tyy_merge_two_pages() 函数尝试合并 pge257 和 tree_page。假如它们符合合并条件,那么尝试将其合并成一个页面
- 调用 stable_tree 把这个合并后的页面添加到稳定的红黑树中。在 stable_tree_insert() 函数中,遍历稳定的红黑树中的所有成员,当发现稳定的节点的页面内容和当前页面内容一致时,设置 need_chain 为 true 并退出遍历,说明找到一个内容相同的“小伙伴”了(见 1870 行代码)
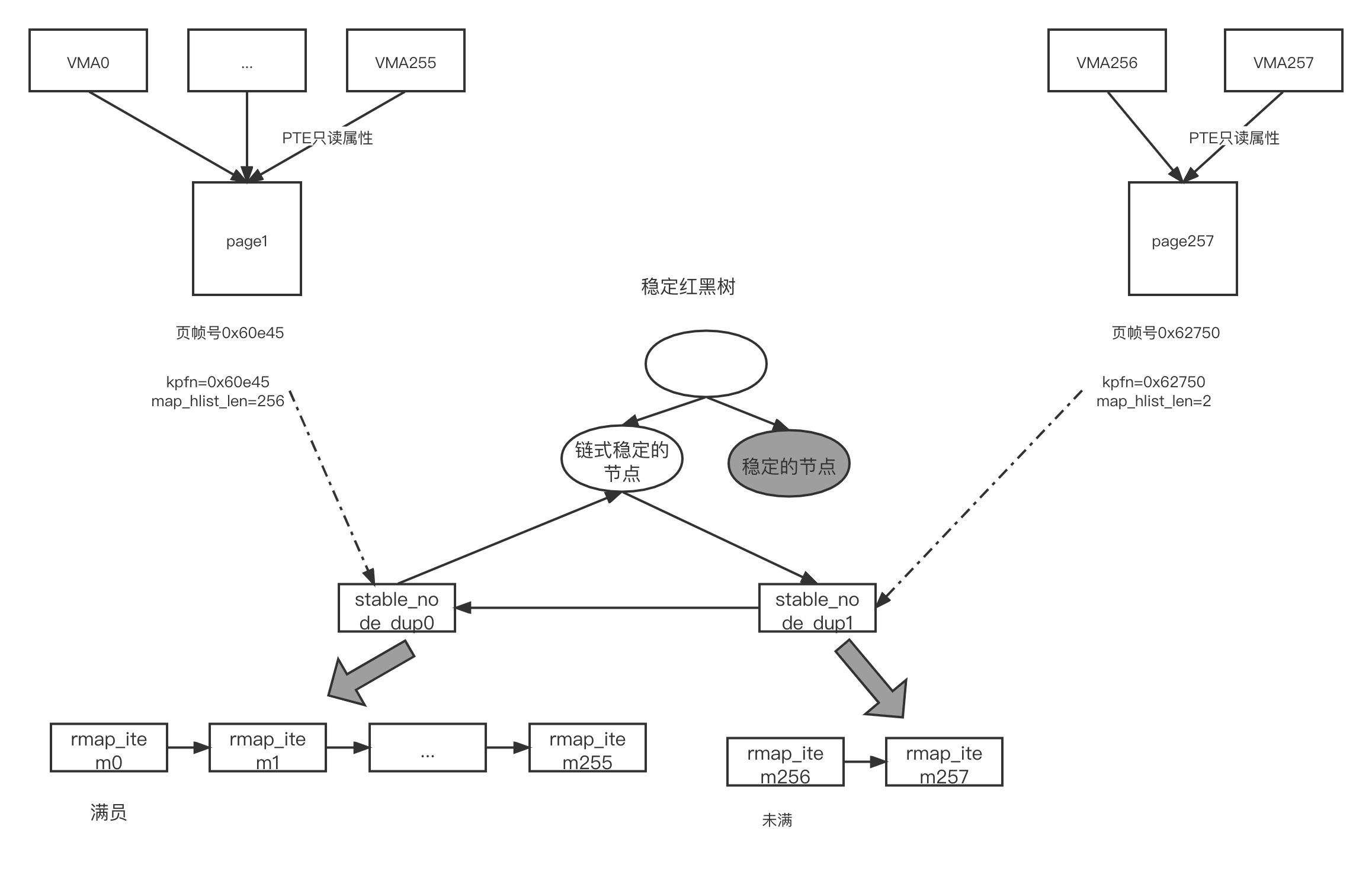
- 在第 1875 行中,新健一个稳定的节点,称为 stable_node_dup1 或者 node_dup1。设置新合并页面的页帧号到 stable_node_dup1->kpfn 中。 set_page_stable_node() 函数把这个新合并面设置为 KSM 页面。这时 stable_node_dup1->rmap_hlist_len 的值为 0
- 在第 188 行中,稳定的红黑树的节点为 stable_node_dup0,它是传统的稳定的节点在第 1891 行中,调用 alloc_stable_node_chain() 函数重新创建一个链式稳定的节点。 chain->rmap_hlist_len 的值初始化为 STABLE_NODE_CHAN,表明该节点是链式稳定的节点。増加 ksm_stable_node_chains 计数
- 把链式稳定的节点替換到稳定的红黑树上的 stable_node_dup0 节点,并且把 stable_node_dup0 节点添加到链式稳定的节点所在的 hlist 链表中,这样一个新的链式稳定的节点就创建成功了
- 在第 1897 行中,把刚才新创建的 stable_node_dup1 节点也添加到链式稳定的节点的 hlist 链表中。此时,链式稳定的节点的 hlist 链表中有两个成员,一个是 stable_node_dup0 节点,另一个是 stable_node_dup1 节点。此时, ksm_stable_node_chain 为 1 ksm_stable_node_dups 为 2
- 在第 2145~2147 行中,分别调用 stable_tree_append() 函数,把
rmap_item257 和 tree_rmap_item 添加到 table_node_dup1->hlist
链表中。此时, stable_nodde_dup1->rmap_hist_len 的值为 2,
ksm_pages_shared 为 2, ksm_pages_sharing 为 256 整个过程如图所示
接下来,扫描第 259 个页面(page258)。具休过程如下。
- 遍历 stable 红黑树,见 stable_tree_searen() 函数。
- 调用 chain_prune()->__stable_node_chain() 函数,由于当前的节点是链式稳定的节点,因此直接调用 stabie_node_dup() 函数,详见 stable_node_dup() 函数
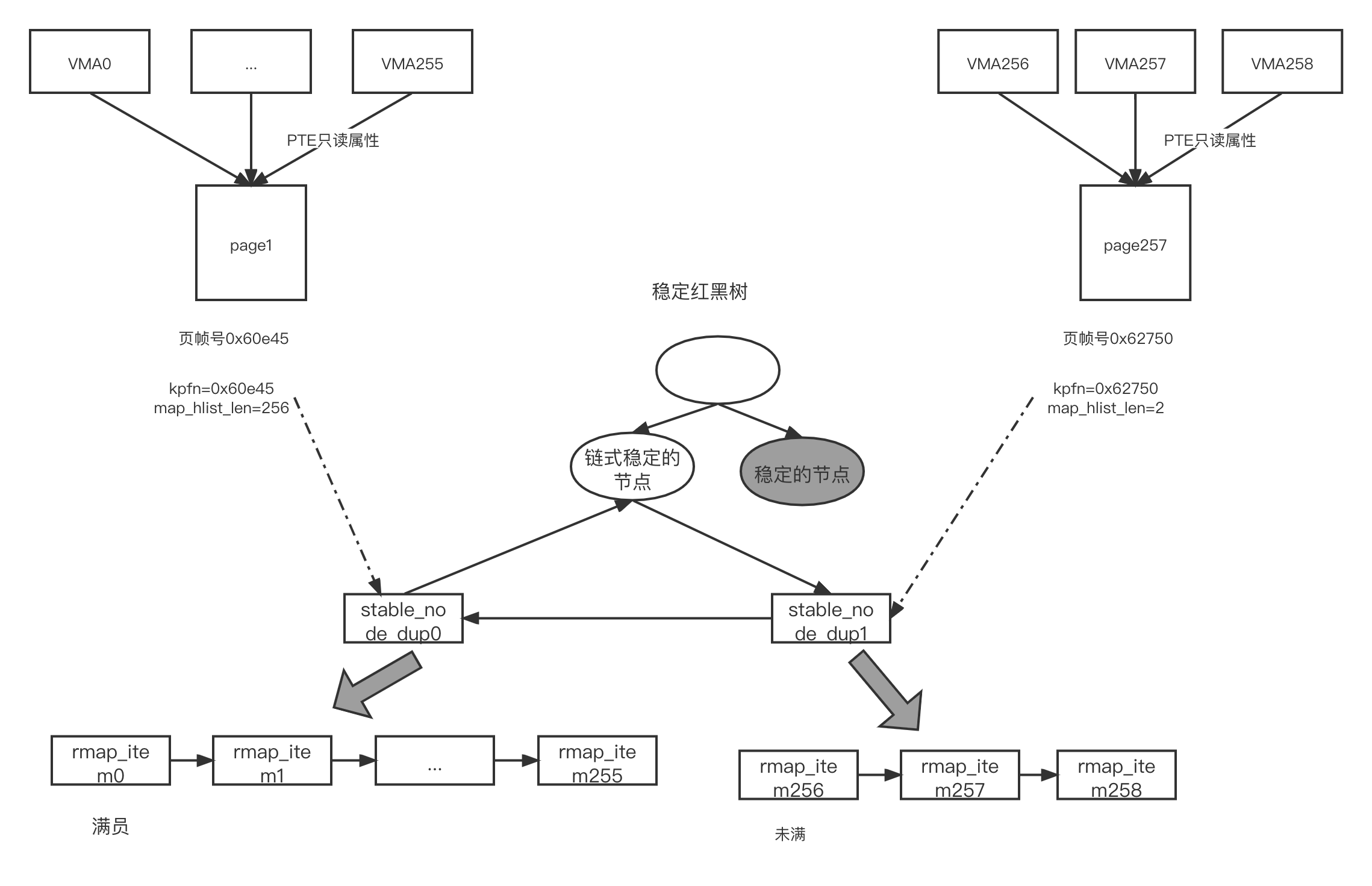
- 在 stabie_node_dup() 函数中遍历稳定的节点所在的 hlist 链表中所有的 rmap_item,查找一个 hlist 链表中还有空间的 rmap_item。然后返回这个 rmap_item 对应的页面,另外 stabie_node_dup 指向 rmap_item. 此时,链式稳定的节点有两个 stable_nale_dup() 分别是 stabie_node_dup0 和 stabie_node_dup1,只有 stable_node_dup1 还有空间容纳 rmap_item, 因此返回 stabie_node_dup1 对应的页面。
- 在 stable_tree_search() 函数中,发现第 259 个页面和 stabie_node_dup1 对应的页面内容相同,因此返回 stabie_node_dup1 对应的页面,它称为 tree_page
- 调用 try_to_merge_with_ksm_page() 尝试合并 page258 到 tree_page
中。调用 stable_tree_append() 函数把 rmap_item258 添加到
stable_node_dup1 的 hlist 链表中, rmap_hlist_len 的值变成了
3,ksages_sharing 变成了 257 整个过程如图所示:
接下来,扫描其他页面。具体过程如下。
(1)继续扫描其他页面,直到 stable_node_dup1->hlist 链表满员为止。 (2)重复扫描第 257 个和第 258 个页面,新创建一个 node_dup2 节点,添加到链式稳定的节点的 hlist 链表中,新的 rmap_item 就可以继续添加到 node_dup2->hlist 链表中了。 综上所述,我们们发现新版本的 KSM 机制有:
- 上述 1000 个相同页面会生成多个 KSM 页面,上图 9 所示的 page1 是第一个 KSM 页面,page257 是第二个 KSM 页面,以此类推。而在旧版本的 KSM 机制中,1000 个页面会生成一个 KSM 页面,另外的 999 个页面都会合并到这个 KSM 页面中。
- 每个 KSM 页面最多把 256 个页面合并在一起,其中还包括 KSM 页面自己,即最多有 255 个其他的页面被合并。
当 RMAP 机制需要遍历 KSM 页面时,它只需要遍历 256 个 rmap_items 即可。如当需要迁移 page1 时,可以通过 page1 找到 stable_node_dup0 节点,因此只需要遍历和处理 node_dup0->hlist 链表中的第 256 个 rmap_items 就可以迁移 page1.
malloc 函数分配的内存是不能被 KSM 扫描的,malloc() 函数分配的虚拟内存没办法保证一定是按照页面对齐的,但在 madvise 系统调用中,要求起始地址是按照页面对齐的。
小结
KSM 的核心设计思想基于写时复制机制,也就是内容相同的页面可以合并成一个只读页面,从而释放空闲页面。 KSM 最早是为了 KVM 虚拟机而设计的,KVM 虚拟机在宿主机上使用的页面大部分是匿名页面,并且它们在宿主机中存在大量的冗余内存。对于典型的应用程序,KSM 只考虑进程分配使用的匿名页面,暂时不考虑页面高速缓存的情况。一个典型的应用程序可以由以下 5 个内存部分组成
- 可执行文件的内存映射(页面高速缓存)
- 程序打开使用的匿名页面
- 进程打开的文件映射(包括常用的或者不常用的,甚至只用一次的页面高速缓存)
- 进程访问文件系统时产生的内容缓存
- 进程访问内核产生时的内核缓冲器(如 slab)等
设计的关键是如何寻找和比较两个相同的页面,如何让这个过程变得高效而且占用的系统资源最少,这就是一个好的设计人员应该思考的问题。首先不能用哈希算法来比较两个页面的专利问题。KSM 虽然使用了 memcmp 来比较,最糟糕的情况是两个页面最后的 4 字节不一样但是 KSM 使用红黑树来设计了两棵树,分别是稳定的红黑树和不稳定的红黑树,可以有效地避免最糟糕的情况。另外,KSM 也巧妙地利用页面的校验和来比较不稳定的红黑树的页面最近是否被修改过,从而避开了该专利的缺陷。 页面分为物理页面和虚拟页面,多个虚拟页面可以同时映射到一个物理页面,因此需要把映射到该页面的所有 PTE 都解除后,才是算真正释放(这里说的 PTE 是指用户进程地止空间的虚拟地址映射的该页面的 PTE,简称用户 PTE,因此 page->__mapcount 成员里描述的 PTE 数量不包含内核线性映射的 PTE)。目前有两种做法,一种做法是扫描每个进程中用户地址进程空间,由用户地址进程空间的虚拟地址查询 MMU 页表,找到对应的 page 数据结构,这样就找到了用户 PTE。然后对比 KSM 中的稳定树和不稳定树,如果找到页面内容相同的,就把该 PTE 设置成写时复制,映射到 KSM 页面中,从而释放出一个 PTE。注意,这里是释放出一个用户 PTE,而不是一个物理页面(如果该物理页面只有一个 PTE 映射,那就是释放该页)。另外一种做法是直接扫描系统中的物理页面,然后通过 RMAP 来解除该页面所有的用户 PTE,从而一次性地释放出物理页面。显然,目前内核的 KSM 是基于第一种做法。 KSM 的作者在他的论文中有实测数据,但作者依然覚得有一些情况下会比较糟糕。如在一个很大内存的服务器上,很多的匿名页面都同时映射了多个虚拟页面。假设每个匿名页面都映射了 1000 个虚拟页面,这些虚拟页面又同时分布在不同的子进程中,那么要释放一个物理页面,需要扫描完 1000 个虚拟页面所在的用户地址进程空间,每次都要利用 follow_page() 查询页表,然后査询稳定树,还需要多次执行 memcmp 比较,合并 10000 次 PTE 也就意味着 memcmp 要执行 10000 次,这个过程会很漫长,在实际项目中,有很多人抱怨 KSM 的效率低,在很多项目是关闭该特性的。也有很多人在思考如何提高 KSM 的效率,包括利用新的软件算法或者利用硬件机制。
参考文献
《奔跑吧 Linux 内核》





