
Linux 并发与同步(四)RCU

RCU 概述
RCU 的全称 Read-Copy-Update,它是 Linux 内核中一种重要的同步机制。Linux 内核中已有了原子操作、自旋锁、读写自旋锁、读写信号量、互斥锁等锁机制,为什么要单独设计一个比它们复杂得多的新机制呢?回忆自旋锁、读写信号量和互斥锁的实现,它们都使用了原子操作指令,即原子地访问内存,多 CPU 争用共享的变量会让高速缓存一致性变得很糟,使得性能下降。
以读写信号量为例,除了上述缺点外,读写信号量还有一个致命弱点,它允许多个读者同时存在,但是读者和写者不能同时存在。因此 RCU 机制要实现的目标是,读者线程没有同步开销,或者说同步开销变得很小,甚至可以忽略不计,不需要额外的锁,不需要使用原子操作指令和内存屏障指令,即可畅通无阻地访问;而把需要同步的任务交给写者线程,写者线程等待所有读者线程完成后才会把旧数据销毁。
在 RCU 中,如果有多个写者同时存在,那么需要额外的保护机制。RCU 机制的原理可以概括为 RCU 记录了所有指向共享数据的指针的使用者,当要修改共享数据时,首先创建一个副本,在副本中修改。所有读者线程离开读者临界区之后,指针指向修改后的副本,并且删除旧数据。
RCU 的一个重要的应用场景是链表,链表可以有效地提高遍历读取数据的效率。读取链表成员数据时通常只需要 rcu_read_lock() 函数,允许多个线程同时读取该链表,并且允许一个线程同时修改链表。那为什么这个过程能保证链表访问的正确性呢? 在读者遍历链表时,假设另外一个线程删除了一个节点。删除线程会把这个节点从链表中移出,但不会直接销毁它。RCU 会等到所有读线程读取完成后,才销毁这个节点。 RCU 提供的接口如下。
- rcu_read_lock()/ rcu_read_unlock():组成一个 RCU 读者临界区
- rcu_dereference():用于获取被 RCU 保护的指针,读者线程要访问 RCU 保护的共享数据,需要使用该函数创建一个新指针,并且指向被 RCU 保护的指针
- rcu_assign_pointer():通常用于写者线程。在写者线程完成新数据的修改后,调用该接口可以让被 RCU 保护的指针指向新创建的数据,用 RCU 的术语是发布了更新后的数据
- synchronize_rcu():同步等待所有现存的读访问完成
- call_rcu():注册一个回调函数,当所有现存的读访问完成后,调用这个回调函数销毁旧数据
关于 RCU 的一个简单例子
下面通过关于 RCU 的一个简单例子来理解上述接口的含义,该例子来源于内核源代码中的 Documents/RCU/whatisrcu.rst,并且省略了一些异常处理情况。
1 | 《关于 RCU 的一个简单例子》 |
该例子的目的是通过 RCU 机制保护 my_test_init() 函数分配的共享数据结构 g_ptr,并创建一个读者线程和一个写者线程来模拟同步场景。对于 myrcu_reader_thread,注意以下几点。
- 通过 rcu_read_lock() 函数和 rcu_read_unlock() 函数来构建一个读者临界区
- 调用 rcu_dereference() 函数获取被保护数据的副本,即指针 p,这时 p 和 g_ptr 都指向旧的被保护数据
- 读者线程每隔 200ms 读取一次被保护数据
对于 myrcu_writer_thread,注意以下几点。
- 分配新的保护数据,并修改相应数据
- rcu_assign_pointer() 函数让 g_ptr 指向新数据
- call_rcu() 函数注册一个回调函数,确保所有对旧数据的引用都执行完成之后,才调用回调函数来删除旧数据
- 写者线程每隔 400ms 修改被保护数据
上述过程如图所示: 
在所有访问结束之后,内核可以释放旧数据,关于何时释放旧数据,内核提供了两个接口函数--synchronize_rcu() 和 call_rcu()。
经典 RCU 和 Tree RCU
本节重点介绍经典 RCU 和 Tree RCU 的实现,可睡眠 RCU 和可抢占 RCU 留给读者学习。RCU 里有两个很重要的概念,分别是宽限期( Grace Period,GP)和静止状态(Quiescent State, QS)。
- 宽限期:GP 有生命周期,有开始和结束之分。从 GP 开始算起,如果所有处于读者临界区的 CPU 都离开了临界区,也就是都至少经历了一次 QS,那么认为一个 GP 可以结束了。GP 结束后,RCU 会调用注册的回调函数,如销毁旧数据等。
- 静止状态:在 RCU 设计中,如果一个 CPU 处于 RCU 读者临界区中,说明它的状态是活跃的:如果在时钟滴答中检测到该 CPU 处于用户模式或空闲状态,说明该 CPU 已经离开了读者临界区,那么它是 QS。在不支持抢占的 RCU 实现中,只要检测到 CPU 有上下文切换,就可以知道离开了读者临界区。
RCU 在开发 Linux2.5 内核时已经被添加到 Linux 内核中,但是在 Linux2.6.29 内核之前的 RCU 通常称为经典 RCU( Classic RCU)。经典 RCU 在大型系统中遇到了性能问题,后来在 Linux2.6.29 内核中 IBM 的内核专家 Paul E. Mckenney 提出了 Tree RCU 的实现, Tree RCU 也称为 Hierarchical RCU。
经典 RCU 的实现在超级大系统中遇到了问题,特别是有些系统的 CPU
内核超过了 1024 个,甚至达到 4096 个。经典 RCU 在判断是否完成一次 GP
时采用全局的 cpumask 图。如果每位表示一个 CPU,那么在 1024 个 CPU
内核的系统中, cpumask 位图就有 1024 位。每个 CPU 在 GP
开始时要设置位图中对应的位,GP 结束时要清除相应的位。全局的 cpumask
位图会导致很多 CPU
竞争使用,因此需要自旋锁来保护位图。这样导致锁争用变得很激烈,激烈程度随着
CPU 的个数线性递增。以 4 核 CPU 为例,经典 RCU 的实現如图所示。 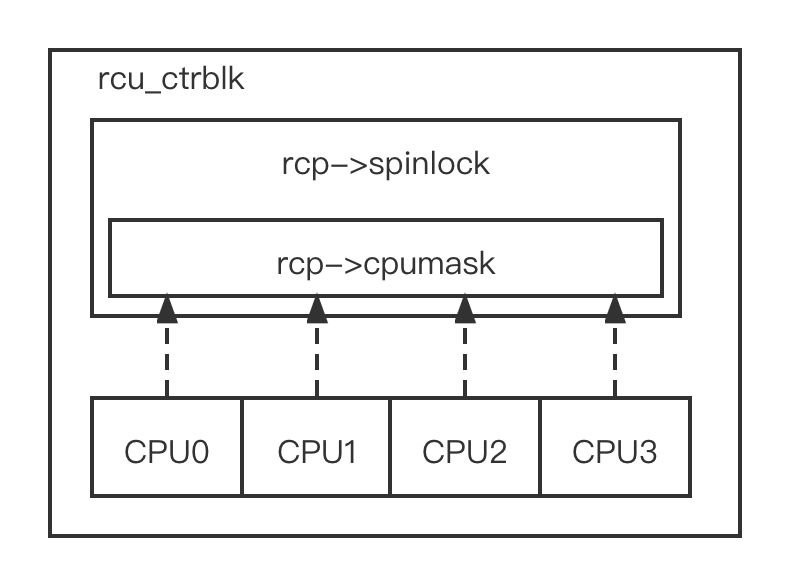
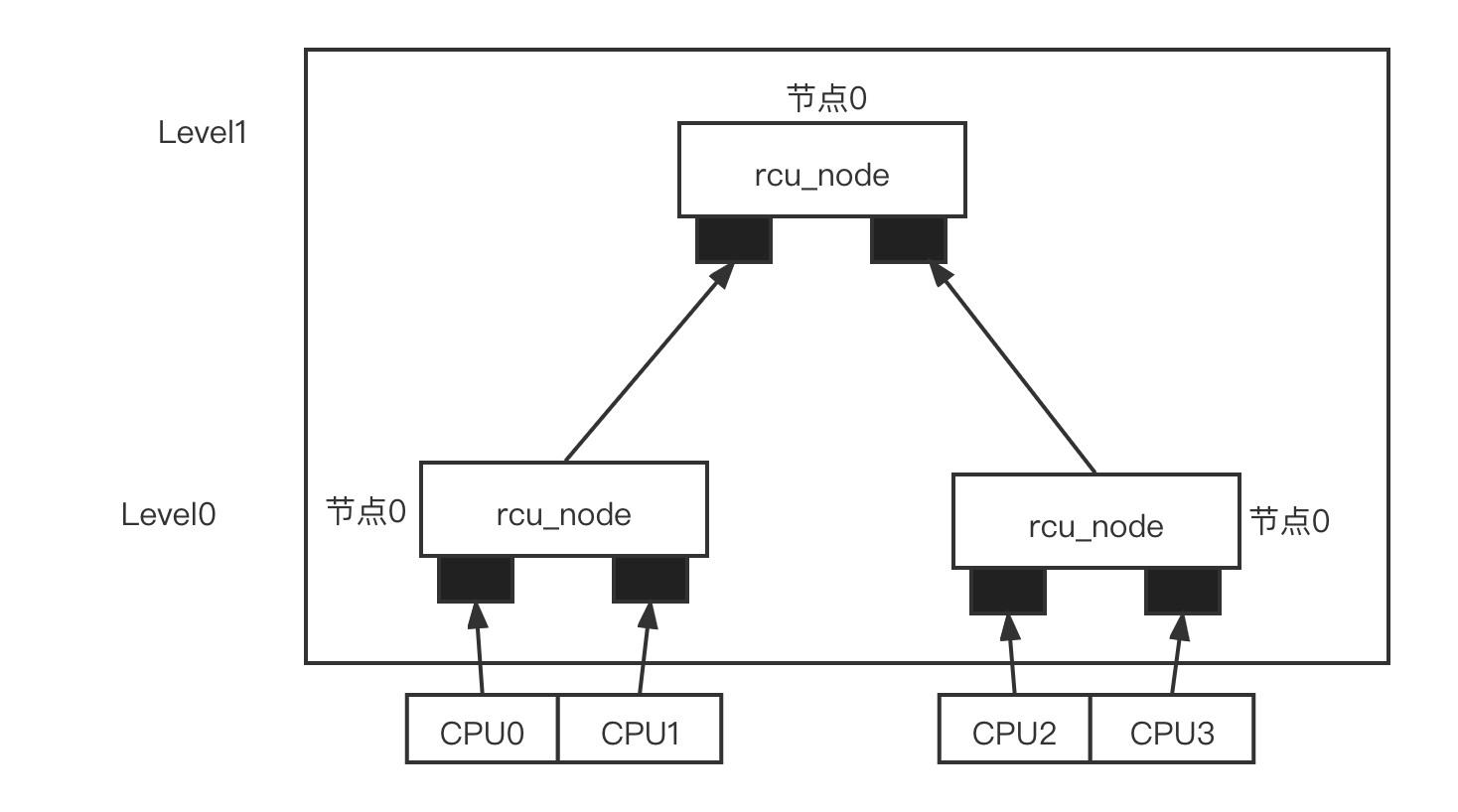
而 Tree RCU 的实现巧妙地解决了 cpumask 位图竞争锁的问题,以上述 4 核 CPU 为例,假设 Tree RCU 以两个 CPU 为一个 rcu_node, 这样 4 个 CPU 被分配到两个 rcu_node,使用另外一个 rcu_node 来管理这两个 rcu_node。节点 1 管理 pu0 和 cpu1,节点 2 管理 pu2 和 cpu3。而节点 0 是根节点,管理节点 1 和节点 2。每个节点只需要两位的位图就可以管理各自的 CPU 或者节点,每个节点都通过各自的自旋锁来保护相应的位图。
假设 4 个 CPU 都经历过一个 QS,那么 4 个 CPU 首先在 Leve0 的节点 1
和节点 2 上修改位图。对于节点 1 或者节点 2 来说,只有两个 CPU
竞争锁,这比经典 RCU 上的锁争用要减少一半。当节点 1 和节点 2
上的位图都被清除干浄后,才会清除上一级节点的位图,并且只有最后清除节点的
CPU 才有机会尝试清除上一级节点的位图。因此对于节点 0 来说,还是两个 CPU
争用锁。整个过程中只有两个 CPU 争用一个锁。这类似于足球比赛,进入四强的
4
支球队被分成上下半区,每个半区有两支球队,只有半决赛获胜的球队才能进入决赛。
参考文献
《奔跑吧 Linux 内核》





