
Linux 进程管理(三)CFS 调度器
公平调度思想的引入
传统调度器时间片悖论
在 O(n)和 O(1)调度器中,时间片是固定分配的,静态优先级高的进程获取更大的 time slice。高优先级的进程会获得更多的连续执行的机会,这是 CPU-bound 进程期望的,但是实际上,CPU-bound 进程往往在后台执行,其优先级都是比较低的。
RSDL 调度器
RSDL 调度器仍然沿用了 O(1)调度的数据结构和软件结构,当然删除了那些令人毛骨悚然的评估进程交互指数的代码。我们这一小节不可能详细描述 RSDL 算法,不过只讲清楚 Rotating、Staircase 和 Deadline 这三个基本概念。
首先看 Staircase 概念,它更详细表述应该是 priority staircase,即在进程调度过程中,其优先级会像下楼梯那样一点点的降低。在传统的调度概念中,一个进程有一个和其静态优先级相匹配的时间片,在 RSDL 中,同样也存在这样的时间片,但是时间片是散布在很多优先级中。例如如果一个进程的优先级是 120,那么整个时间片散布在 120~139 的优先级中,在一个调度周期,进程开始是挂入 120 的优先级队列,并在其上运行 6ms,一旦在 120 级别的时间配额使用完毕之后,该进程会转入 121 的队列中,发生一次 Rotating,更准确的说是 Priority minor rotating。之后,该进程沿阶而下,直到 139 的优先级,在这个优先级上如果耗尽了 6ms 的时间片,这时候,该进程所有的时间片就都耗尽了,就会被挂入到 expired 队列中去等待下一个调度周期。这次 rotating 被称为 major rotating。当然,这时候该进程会挂入其静态优先级对应的 expired 队列,即一切又回到了调度的起点。
Deadline 是指在 RSDL 算法中,任何一个进程可以准确的预估其调度延迟。一个简单的例子,假设 runqueue 中有两个 task,静态优先级分别是 130 的 A 进程和 139 的 B 进程。对于 A 进程,只有在进程沿着优先级楼梯从 130 走到 139 的时候,B 进程才有机会执行,其调度延迟是 9 x 6ms = 54ms。
多么简洁的算法,只需要维持公平,没有对进程睡眠/运行时间的统计,没有对用户交互指数的计算,没有那些奇奇怪怪的常数……调度,就是这么简单。
CFS 调度器
Con Kolivas 的 RSDL 调度器始终没有能够进入 kernel mainline,取而代之的是同样基于公平调度思想的 CFS 调度器,在 CFS 调度器并入主线的同时,仍然提供了模块化的设计,为 RSDL 或者其他的调度器可以进入内核提供了方便。本章我们唯一需要描述的是 Ingo Molnar 如何把完全公平调度的理想照进现实。
模块化思想的引入
从 2.6.23
内核开始,调度器采用了模块化设计的思想,从而把进程调度的软件分成了两个层次,一个是
core scheduler layer,另外一个是 specific scheduler layer: 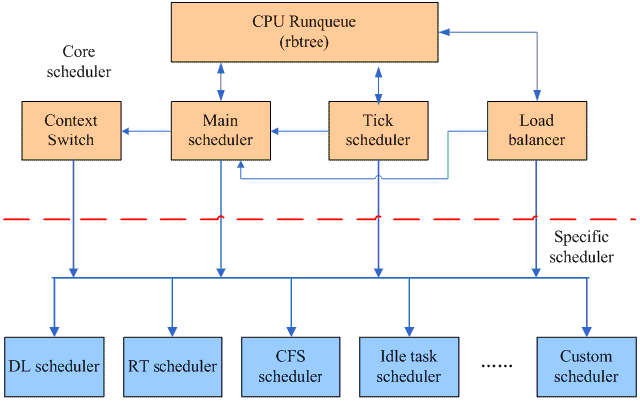
从功能层面上看,进程调度仍然分成两个部分,第一个部分是通过负载均衡模块将各个 runnable task 根据负载情况平均分配到各个 CPU runqueue 上去。第二部分的功能是在各个 CPU 的 Main scheduler 和 Tick scheduler 的驱动下进行单个 CPU 上的调度。
时间粒度
Linux 内核的 CFS 调度器已经摒弃了传统的固定时间片的概念了,O(1)调度器会为每一个进程分配一个缺省的时间片。CFS 调度器没有传统的静态时间片的概念,她的时间片是动态的,和当前 CPU 的可运行状态的进程以及它们的优先级相关,因此 CFS 调度器中,时间片是动态变化的。
CFS 调度器是有一个时间粒度的定义,我们称之调度周期。也就是说,在一个调度周期内,CFS 调度器可以保证所有的可运行状态的进程平均分配 CPU 时间。
如何保证有界的调度延迟?
传统的调度器无法保证调度延迟,为了说明这个问题我们设想这样一个场景:CPU runqueue 中有两个 nice value 等于 0 的 runnable 进程 A 和 B,传统调度器会为每一个进程分配一个固定的时间片 100ms,这时候 A 先运行,直到 100ms 的时间片耗尽,然后 B 运行。这两个进程会交替运行,调度延迟就是 100ms。随着系统负荷的加重,例如又有两个两个 nice value 等于 0 的 runnable 进程 C 和 D 挂入 runqueue,这时候,A、B、C、D 交替运行,调度延迟就是 300ms。因此,传统调度器的调度延迟是和系统负载相关的,当系统负载增加的时候,用户更容易观察到卡顿现象。
CFS 调度器设计之初就确定了调度延迟的参数,我们称之 targeted latency,这个概念类似传统调度器中的调度周期的概念,只不过在过去,一个调度周期中的时间片被固定分配给了 runnable 的进程,而在 CFS 中,调度器会不断的检查在一个 targeted latency 中,公平性是否得到了保证。下面的代码说明了 targeted latency 的计算过程:
1 | static u64 __sched_period(unsigned long nr_running) |
当 runqueue 中的 runnable 进程的数目小于 sched_nr_latency(8 个)的时候,targeted latency 就是 sysctl_sched_latency(6ms),当 runqueue 中的 runnable 进程的数目大于等于 sched_nr_latency 的时候,targeted latency 等于 runnable 进程数目乘以 sysctl_sched_min_granularity(0.75ms)。显然 sysctl_sched_min_granularity 这个参数就是一段一个进程被调度执行,它需要至少执行的时间片大小,设立这个参数是为了防止 overscheduling 而产生的性能下降。
CFS 调度器保证了在一个 targeted latency 中,所有的 runnable 进程都会至少执行一次,从而保证了有界的、可预测的调度延迟。
为何引入虚拟时间?
虽然 Con Kolivas 提出了精采绝伦的设计思想,但是在具体实现的时候相对保守。CFS 调度器则不然,它采用了相对激进的方法,把 runqueue 中管理 task 的优先级链表变成了红黑树结构。有了这样一颗 runnable 进程的红黑树,在插入操作的时候如何确定进程在红黑树中的位置?也就是说这棵树的“key”是什么?
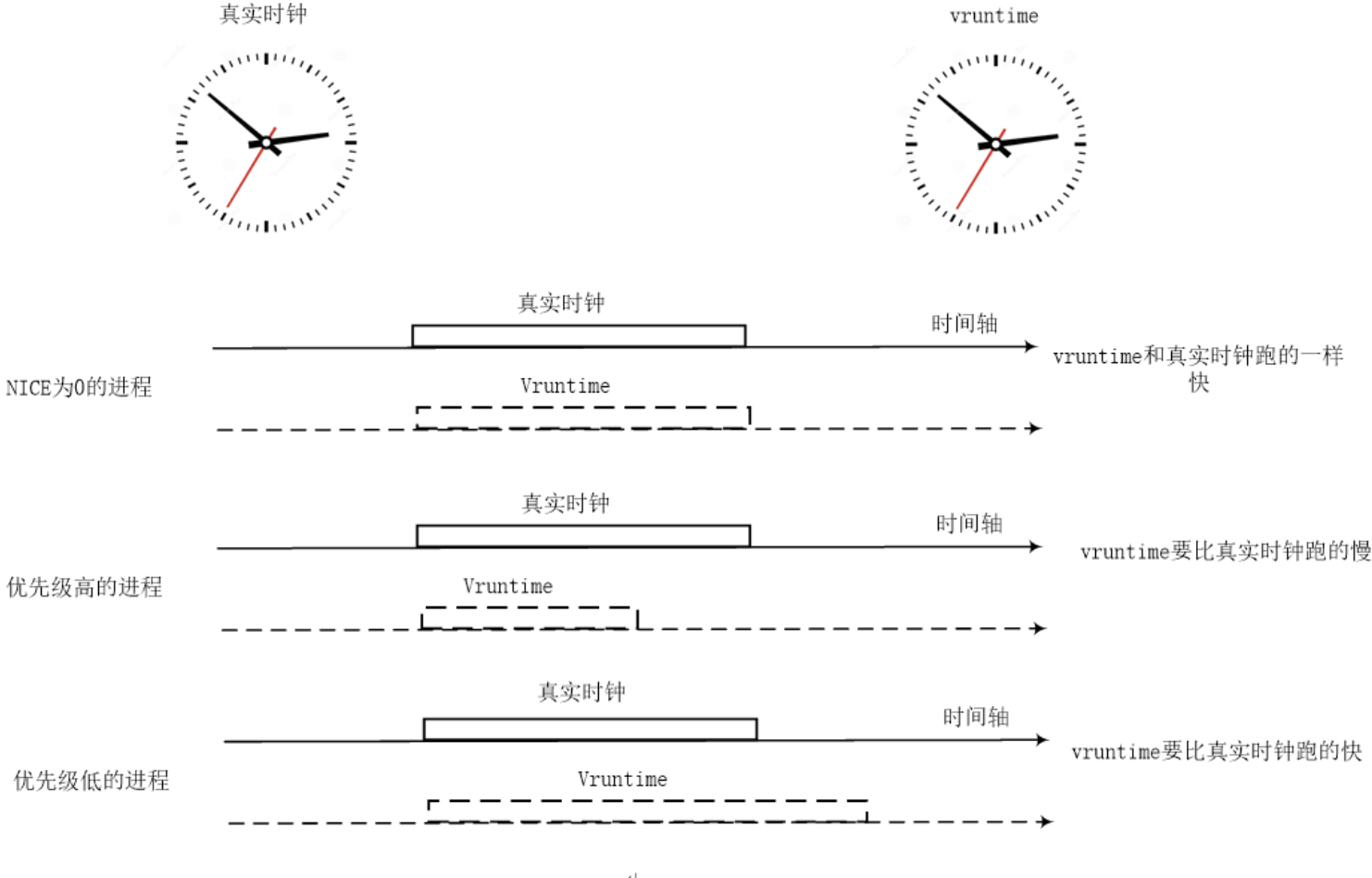
CFS 的红黑树使用 vruntime(virtual runtime)作为 key,为了理解 vruntime,这里需要引入一个虚拟时间轴的概念。在上一章中,我们已经清楚的表述了公平的含义:按照进程的静态优先级来分配 CPU 资源,当然,CPU 资源也就是 CPU 的时间片,因此在物理世界中,公平就是分配和静态优先级匹配的 CPU 时间片。但是红黑树需要一个单一数轴上的量进行比对,而这里有两个度量因素:静态优先级和物理时间片,因此我们需要把它们映射到一个虚拟的时间轴上,屏蔽掉静态优先级的影响:
如何计算 virtual runtime
具体的计算公式如下:
\[ Virtual runtime = (physical runtime) * (nice value 0 的权重)/ 当前线程的权重 \]
为了计算方便,Linux 内核约定 nice 值 0 对应的权值为 1024,其他 nice 值对应的权重值可以通过查表的方式来获取。内核预先计算好了 sched_prio_to_weight[40],表的下标对应 nice 值。CFS 调度器规定 nice 值为 0 的进程具有基准权重,并且其值每增加 1 则减少 10%的 CPU 权重,每减少 1 则增加 10%的 CPU 权重(1024-1024*20% = 820)。其中线程的权重定义如下:
1 | const int sched_prio_to_weight[40] = { |
通过上面的公式,我们构造了一个虚拟的世界。二维的(load weight,physical runtime)物理世界变成了一维的 virtual runtime 的虚拟世界。在这个虚拟的世界中,各个进程的 vruntime 可以比较大小,以便确定其在红黑树中的位置,而 CFS 调度器的公平也就是维护虚拟世界 vruntime 的公平,即各个进程的 vruntime 是相等的。
根据上面的公式,我们可以看出:实际上对于静态优先级是 120(即 nice
value 等于
0)的进程,其物理时间轴等于虚拟时间轴,而其他的静态优先级的虚拟时间都是根据其权重和
nice 0
的权重进行尺度缩放。对于更高优先级的进程,其虚拟时间轴过的比较慢,而对于优先级比较低的进程,其虚拟时间轴过的比较快。
在进行进程调度时候,调度器需要选择下一个占用 CPU 资源的那个 next thread。对于 CFS 而言,其算法就是从红黑树中找到 left most 的那个 task 并调度其运行。这时候,失去 CPU 执行权的那个 task 会被重新插入红黑树,其在红黑树中的位置是由 task 的 vruntime 值决定的。
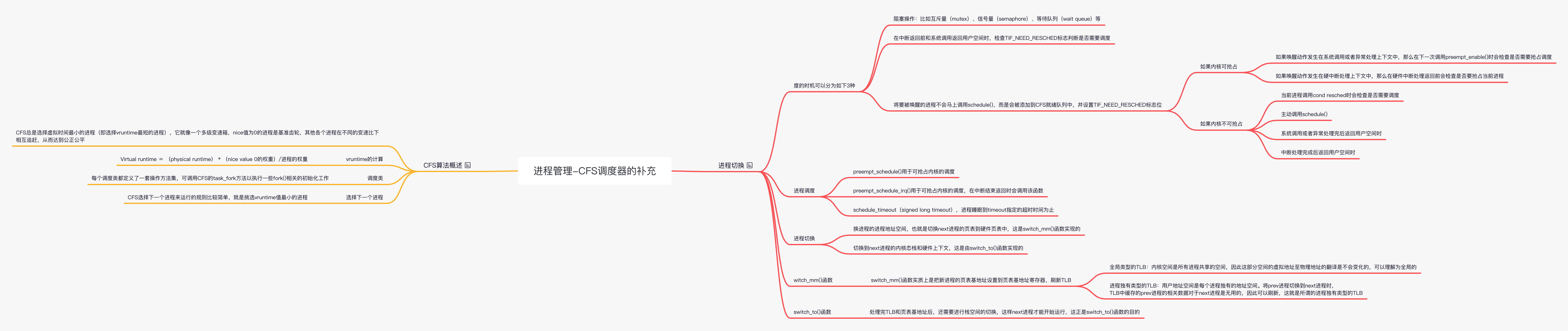
进程切换
调度时机
内核中实现调度的统一策略是:检查进程是否需要调度和实际的调度行为是分离的,比如在 tick 中断或者唤醒进程时检查到存在高优先级进程可以抢占当前执行进程,此时只是设置抢占标志 (TIF_NEED_RESCHED),在特定的时间点再执行调度行为,而不是直接执行调度。毕竟在中断中是绝对不能直接执行调度的。schedule()(调用__schedule())是调度器的核心函数,作用是让调度器选择和切换到一个合适的进程并运行。调度的时机可以分为如下 3 种。
- 阻塞操作:比如互斥量(mutex)、信号量(semaphore)、等待队列(wait queue)sleep 等。
- 在中断返回前和系统调用返回用户空间时,检查 TIF_NEED_RESCHED 标志判断是否需要调度。
- 将要被唤醒的进程不会马上调用 schedule(),而是会被添加到 CFS
就绪队列中,并且设置 TIF_NEED_RESCHED
标志位。那么被唤醒的进程什么时候被调度呢?这要根据内核是否具有可抢占功能(CONFIG_PREEMPT=y)分两种情况:
- 内核可抢占
- 如果唤醒动作发生在系统调用或者异常处理上下文中,那么在下一次调用 preempt_enable() 时会检查是否需要抢占调度
- 如果唤醒动作发生在硬中断处理上下文中,那么在硬件中断处理返回前会检查是否要抢占当前进程
- 内核不可抢占
- 当前进程调用 cond_resched 时会检查是否需要调度
- 主动调用 schedule()
- 系统调用或者异常处理完后返回用户空间时
- 中断处理完成后返回用户空间时
- 内核可抢占
前文提到的硬件中断返回前和硬件中断返回用户空间前是两个不同的概念。前者在每次硬件中断返回前都会检查是否有进程需要被抢占调度,而不管中断发生点是在内核空间还是用户空间;后者仅当中断发生点在用户空间时才会检查。
在 Linux 内核里,schedule() 是内部使用的接口函数,有不少其他函数会直接调用该函数。除此之外,schedule() 函数还有不少变种。
- preempt_schedule() 用于可抢占内核的调度。
- preempt_schedule_irq() 用于可抢占内核的调度,在中断结束返回时会调用该函数。
- schedule_timeout(signed long timeout),进程睡眠到 timeout 指定的超时时间为止。 schedule() 函数的核心代码片段如下。
1 | asmlinkage __visible void __sched schedule(void) |
进程切换
操作系统会把当前正在运行的进程挂起并且恢复以前挂起的某个进程的执行,这个过程称为进程切换或者上下文切换。Linux 内核实现进程切换的核心函数是 context_switch() 每个进程可以拥有属于自己的进程地址空间,但是所有进程都必须共享 CPU 的寄存器等资源。所以,在切换进程时必须把 next 进程在上一次挂起时保存的寄存器值重新装载到 CPU 里。在进程恢复执行前必须装入 CPU 寄存器的数据,则称为硬件上下文。进程的切执可以总结为如下两步。
- 切换进程的进程地址空间,也就是切换 next 进程的页表到硬件页表中,这是 switch_mm() 函数实现的。
- 切换到 next 进程的内核态栈和硬件上下文,这是由 switch_to() 函数实现的。硬件上下文提供了内核执行 next 进程所需要的所有硬件信息。
switch_mm() 函数
switch_mm() 函数实质上是把新进程的页表基地址设置到页表基地址寄存器。对于 ARM64 处理器,switch_mm() 函数的主要作用是完成 ARM 架构相关的硬件设置,例如刷新 TLB 以及设置硬件页表等。
在运行进程时,除了高速缓存(cache)会缓存进程的数据外,MMU 内部还有叫作 TLB(Translation Lookaside Buffer,快表)的硬件单元,TLB 会为了加快虚拟地址到物理地址的转换速度而将部分页表项内容缓存起来,避免频繁访问页表。因此刚切换完进程时会出现很严重的 TLB 未命中和高速缓存未命中,导致系统性能下降。
如何提高 TLB 的性能?这是最近几十年来芯片设计人员和操作系统设计人员共同努力的方向。从 Linux 内核角度看,地址空间可以划分为内核地址空间和用户空间;对于 TLB 来说,可以划分成全局(global)类型和进程独有(process-specific)类型。
- 全局类型的 TLB:内核空间是所有进程共享的空间,因此这部分空间的虚拟地址至物理地址的翻译是不会变化的,可以理解为全局的。
- 进程独有类型的 TLB:用户地址空间是每个进程独有的地址空间。将 prev 进程切换到 next 进程时,TLB 中缓存的 prev 进程的相关数据对于 next 进程是无用的,因此可以刷新,这就是所谓的进程独有类型的 TLB。
为了支持进程独有类型的 TLB,ARM 架构提出了一种硬件解决方案,叫 ASID(Address Space ID),这样 TLB 就可以识别哪些 TLB 项是属于某个进程的。ASID 方案使得每个 TLB 项包含一个 ASID,ASID 用于标识每个进程的地址空间。因此,有了 ASID 硬件机制的支持,进程的切换就不需要刷新整个 TLB,只需要刷新进程独有的 TLB。
switch_to() 函数
处理完 TLB 和页表基地址后,还需要进行栈空间的切换,这样 next 进程才能开始运行,这正是 switch_to() 函数的目的。
1 | <include/asm-generic/switch_to.h> |
switch_to() 函数一共有 3 个参数,第一个表示将要被调度出去的进程 prev,第二个表示将要被调度进来的进程 next,第三个参数 last 是什么意思呢?为什么 switch_to() 函数有 3 个参数?prev 和 next 就够了,为何还需要 last?
switch_to 宏由旧进程调用,在新进程结束,新进程如果想获取旧进程描述符地址,不能直接读取局部变量 prev(因为 prev 存放在该宏调用者,即旧进程的内核栈中,新进程无法访问旧进程的内核栈),所以就需要一个输出参数将旧进程描述符地址传递给新进程(实现方法就是利用 cpu 寄存器%eax,在切换过程中该寄存器的值不变,也就是说,在旧进程中,将 prev 存入%eax,在新进程恢复执行后,将%eax 的内容放入 last)。
task_struct 数据结构里的 thread_struct 用来存放和具体架构相关的一些信息。对于 ARM64 架构来说,thread_struct 数据结构定义在 arch/arm64/include/asm/processor.h 文件中。
1 | <arch/arm64/include/asm/processor.h> |
- cpu_context:保存进程上下文相关的信息到 CPU 相关的通用寄存器中
- tp_value:TLS 寄存器。
- tp2_value:TLS 寄存器。
- fpsimd_state:与 FP 和 SMID 相关的状态。
- fpsimd_cpu:FP 和 SMID 的相关信息。
- sve_state:SVE 寄存器。
- sve_vl:SVE 向量的长度。
- sve_vl_onexec:下一次执行之后 SVE 向量的长度。
- fault_address:异常地址。
- fault_code:异常错误值,从 ESREL1 中读出。
cpu_context 是一种非常重要的数据结构,它勾画了在切换进程时,CPU 需要保存哪些寄存器,我们称为进程硬件上下文。对于 ARM64 处理器来说,在切换进程时,我们需要把 prev 进程的 x19~x28 寄存器以及 fp、sp 和 pc 寄存器保存到 cpu_context 数据结构中,然后把 next 进程中上一次保存的 cpu_context 数据结构的值恢复到实际硬件的寄存器中,这样就完成了进程的上下文切换。 cpu_context 数据结构的定义如下。
1 | <arch/arm64/include/asm/processor.h> |
进程的上下文切换的流程如图所示。在进程切换过程中,进程硬件上下文中重要的寄存器已保存到
prev 进程的 cpu_context 数据结构中,进程硬件上下文包括 x19~x28
寄存器、fp 寄存器、sp 寄存器以及 pc 寄存器,如图(a)所示。然后,把 next
进程存储的上下文恢复到 CPU 中,如图(b)所示。 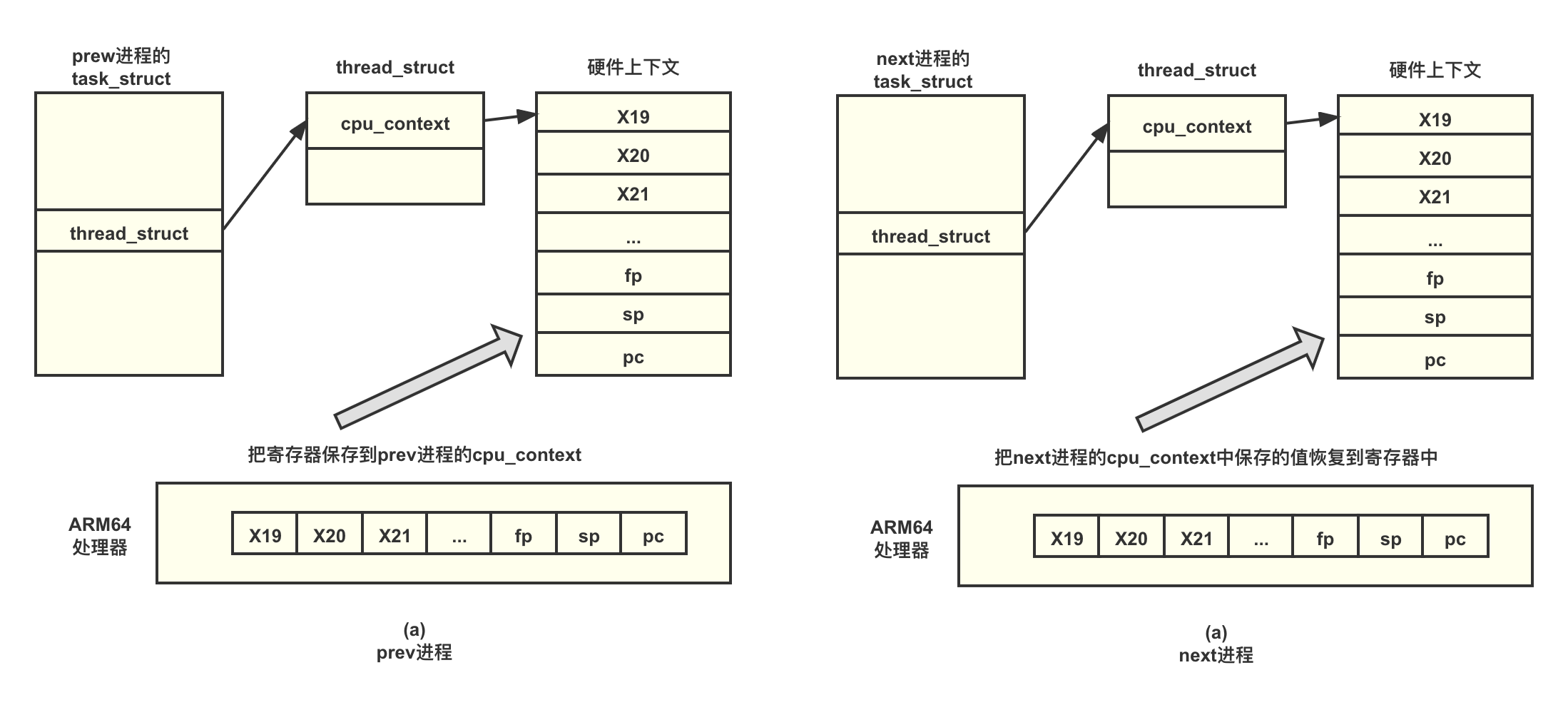
参考文献
《奔跑吧 Linux 内核》
《Linux 内核设计与实现》





