C Tips
区别以下函数
1 2 3 4 5 6 7 int * f () ; int (*f)(); int * f[]; int (*f[])(); int *(*f[])(); int f () []; int f[]();
宏定义
1 2 3 4 5 6 7 8 9 10 11 12 #define _SYSCALL_CONCAT(arg1, arg2) __SYSCALL_CONCAT(arg1, arg2) #define __SYSCALL_CONCAT(arg1, arg2) ___SYSCALL_CONCAT(arg1, arg2) #define ___SYSCALL_CONCAT(arg1, arg2) arg1##arg2 #define _SYSCALL_NARG(...) __SYSCALL_NARG(__VA_ARGS__, __SYSCALL_RSEQ_N()) #define __SYSCALL_NARG(...) __SYSCALL_ARG_N(__VA_ARGS__) #define __SYSCALL_ARG_N(_1, _2, _3, _4, _5, _6, _7, N, ...) N #define __SYSCALL_RSEQ_N() 6, 5, 4, 3, 2, 1, 0 #define Z_SYSCALL_HANDLER(...) \\ _SYSCALL_CONCAT(__SYSCALL_HANDLER, \\ _SYSCALL_NARG(__VA_ARGS__))(__VA_ARGS__)
container_of 宏
1 2 3 4 5 #define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER) #define container_of(ptr, type, member) ({ \\ const typeof( ((type *)0)->member ) *__mptr = (ptr); \\ (type *)( (char *)__mptr - offsetof(type,member) );})
可以通过结构体中的一个成员获得该结构体首地址。精髓在于定义该结构体并将其放到
0 地址处通过已知成员获得偏移从而计算出首地址
__builtin_expect
1 2 #define likely(x) __builtin_expect((bool)!!(x), true) #define unlikely(x) __builtin_expect((bool)!!(x), false)
这个宏定义的作用是优化代码,减少指令跳转次数。
在实际使用中例如
1 2 3 4 5 if ( likely ( x ) ) { ... } else { ... }
当 x 为 true 的场景较多时可以优化代码减少跳转次数相反当 x 倾向于
false 时用 unlikely,这个主要是 cpu 预取指相关内容。
C++ Tips
conversion function
1 2 3 4 5 6 7 8 9 10 11 12 13 class Fraction {public : Fraction (int num,int den = 1 ): m_numerator (num), m_denominnator (den) {} operator double () const return (double )(m_numerator / m_denominnator); } private : int m_numerator; int m_denominnator; }
用法:
1 2 Fraction f (3 ,5 ) ;double d = 4 + f;
实际上做()运算符的重载。
explicit
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Fraction {public : Fraction (int num,int den = 1 ): m_numerator (num), m_denominnator (den) {} operator double () const return (double )(m_numerator / m_denominnator); } Fraction operator +(const Fraction& f){ return Fraction (...); } private : int m_numerator; int m_denominnator; }
用法:
1 2 3 Fraction f (3 ,5 ) ;Fraction d = f + 4 ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Fraction {public : explicit Fraction (int num,int den = 1 ) : m_numerator(num), m_denominnator(den) { } operator double () const return (double )(m_numerator / m_denominnator); } Fraction operator +(const Fraction& f){ return Fraction (...); } private : int m_numerator; int m_denominnator; }
这样 4 就没办法转化为 Fractor(4,1) 了,这个关键字只对单参数 class
起作用
share_ptr
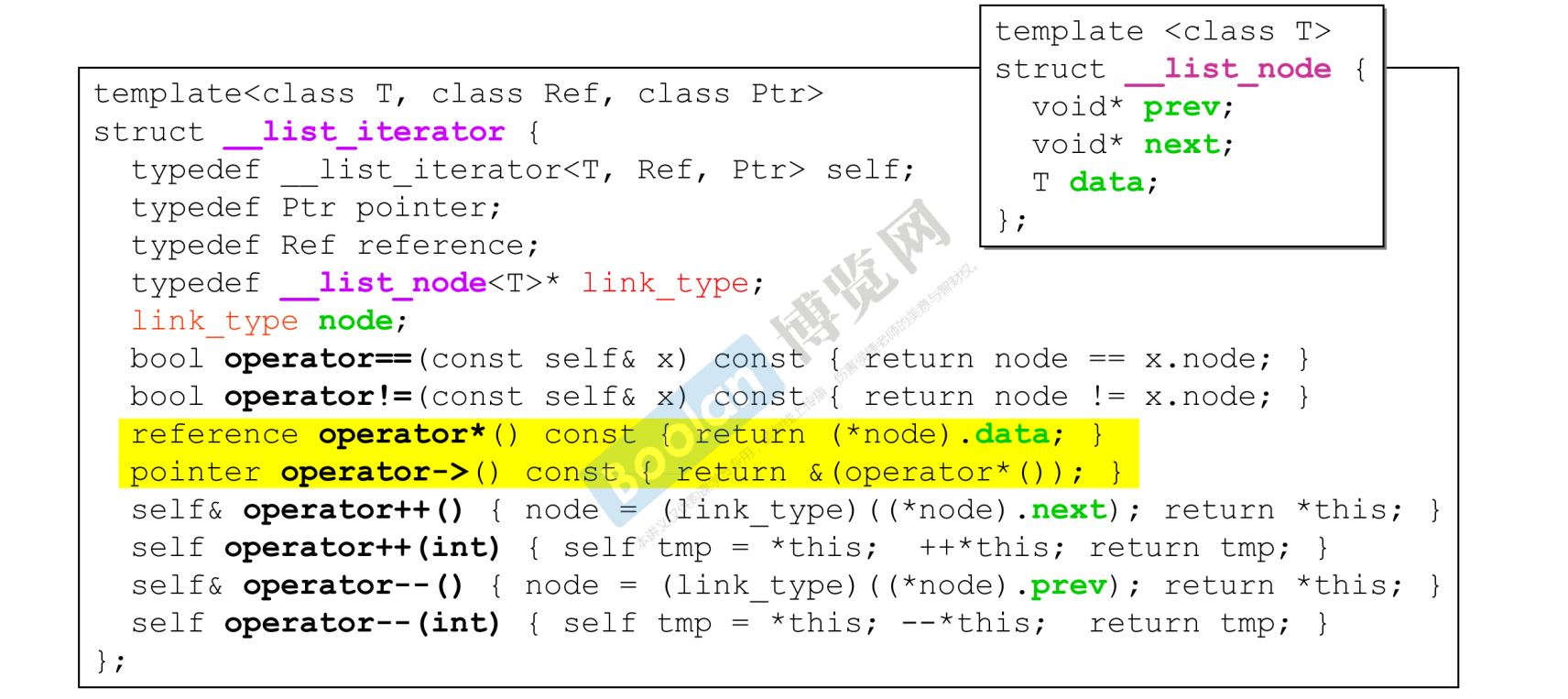
iterator
模板特化和偏特化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 template <class key >struct hash {};template <>struct hash <char > { size_t operator () (char x) const return x;} }; template <>struct hash <int > { size_t operator () (int x) const return x;} }; template <>struct hash <long > { size_t operator () (long x) const return x;} }; template <typename T,typename Alloc=...>class vector { ... }; template <typename Alloc=...>class vector<bool ,Alloc> { ... }
模板模板参数
1 2 3 4 5 6 7 8 9 10 11 12 13 template <typename T, template <typename T> class Container > class XCls { private : Container<T> c; public : XCls () { ... } };
override
派生类定义了一个函数与基类中的虚函数名字相同但是参数却不同,我们本来想
overwrite
基类中的虚函数,但是参数不同并不会报错而是两个独立的函数,这不是我们想要的,这个问题一般很难发现,因此可以通过
overridr 关键字来进行检查。
1 2 3 4 5 6 7 8 9 10 11 12 13 class A {public : virture void f1 (int ) const ; virture void f2 () ; void f3 () } class B :public A { void f1 (int ) const override void f2 (int ) override void f3 () override void f4 () override }
final
定义为 final 的函数,之后派生类的任何覆盖该函数的行为都是非法的
1 2 3 4 5 6 7 8 9 class C : public A {public : void f1 (int ) const final } class D : public C {public : void f1 (int ) const }
std::remove_cv &
std::remove_reference 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #include <iostream> #include <type_traits> int main () typedef const volatile char cvchar; std::remove_cv<cvchar>::type a; std::remove_cv<char * const >::type b; std::remove_cv<const char *>::type c; if (std::is_const<decltype (a)>::value) std::cout << "type of a is const" << std::endl; else std::cout << "type of a is not const" << std::endl; if (std::is_volatile<decltype (a)>::value) std::cout << "type of a is volatile" << std::endl; else std::cout << "type of a is not volatile" << std::endl; return 0 ; }
Output:
1 2 3 type of a is not consttype of a is not volatile
std::function 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 #include <iostream> #include <functional> int half (int x) return x/2 ;}struct third_t { int operator () (int x) return x/3 ;} }; struct MyValue { int value; int fifth () return value/5 ;} }; int main () std::function<int (int )> fn1 = half; std::function<int (int )> fn2 = ½ std::function<int (int )> fn3 = third_t (); std::function<int (int )> fn4 = [](int x){return x/4 ;}; std::function<int (int )> fn5 = std::negate <int >(); std::cout << "fn1(60): " << fn1 (60 ) << '\\n' ; std::cout << "fn2(60): " << fn2 (60 ) << '\\n' ; std::cout << "fn3(60): " << fn3 (60 ) << '\\n' ; std::cout << "fn4(60): " << fn4 (60 ) << '\\n' ; std::cout << "fn5(60): " << fn5 (60 ) << '\\n' ; std::function<int (MyValue&)> value = &MyValue::value; std::function<int (MyValue&)> fifth = &MyValue::fifth; MyValue sixty {60 }; std::cout << "value(sixty): " << value (sixty) << '\\n' ; std::cout << "fifth(sixty): " << fifth (sixty) << '\\n' ; return 0 ; }
Output:
1 2 3 4 5 6 7 8 fn1(60): 30 fn2(60): 30 fn3(60): 20 fn4(60): 15 fn5(60): -60 value(sixty): 60 fifth(sixty): 12
std::type_index 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #include <iostream> #include <typeinfo> #include <typeindex> #include <unordered_map> #include <string> struct C {};int main () std::unordered_map<std::type_index,std::string> mytypes; mytypes[typeid (int )]="Integer type" ; mytypes[typeid (double )]="Floating-point type" ; mytypes[typeid (C)]="Custom class named C" ; std::cout << "int: " << mytypes[typeid (int )] << '\\n' ; std::cout << "double: " << mytypes[typeid (double )] << '\\n' ; std::cout << "C: " << mytypes[typeid (C)] << '\\n' ; return 0 ; }
Output:
1 2 3 4 int: Integer type double: Floating-point type C: Custom class named C
std::bind
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #include <iostream> #include <functional> double my_divide (double x, double y) return x/y;}struct MyPair { double a,b; double multiply () return a*b;} }; int main () using namespace std::placeholders; auto fn_five = std::bind (my_divide,10 ,2 ); std::cout << fn_five () << '\\n' ; auto fn_half = std::bind (my_divide,_1,2 ); std::cout << fn_half (10 ) << '\\n' ; auto fn_invert = std::bind (my_divide,_2,_1); std::cout << fn_invert (10 ,2 ) << '\\n' ; auto fn_rounding = std::bind <int > (my_divide,_1,_2); std::cout << fn_rounding (10 ,3 ) << '\\n' ; MyPair ten_two {10 ,2 }; auto bound_member_fn = std::bind (&MyPair::multiply,_1); std::cout << bound_member_fn (ten_two) << '\\n' ; auto bound_member_data = std::bind (&MyPair::a,ten_two); std::cout << bound_member_data () << '\\n' ; return 0 ; }
Output:
std::lock_guard
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 #include <iostream> #include <thread> #include <mutex> #include <stdexcept> std::mutex mtx; void print_even (int x) if (x%2 ==0 ) std::cout << x << " is even\\n" ; else throw (std::logic_error ("not even" )); } void print_thread_id (int id) try { std::lock_guard<std::mutex> lck (mtx) ; print_even (id); } catch (std::logic_error&) { std::cout << "[exception caught]\\n" ; } } int main () std::thread threads[10 ]; for (int i=0 ; i<10 ; ++i) threads[i] = std::thread (print_thread_id,i+1 ); for (auto & th : threads) th.join (); return 0 ; }
Possible output:
1 2 3 4 5 6 7 8 9 10 [exception caught] 2 is even [exception caught] 4 is even [exception caught] 6 is even [exception caught] 8 is even [exception caught] 10 is even
std::promise
std::promise 和 std::future 用于线程异步
waitForSubmittedTasks
函数可以通过如下方式等待所有线程执行完成,flushedFuture.wait();
会休眠等待条件满足,flushedPromise.set_value() 会导致变量 ready,只有
ready 了线程才会被唤醒,结束函数。
1 2 3 4 5 6 7 8 9 10 11 12 void SharedExecutor::waitForSubmittedTasks() noexcept { std::unique_lock<std::mutex> lock{m_queueMutex}; if (m_threadRunning) { // wait for thread to exit . std::promise<void> flushedPromise; auto flushedFuture = flushedPromise.get_future(); m_queue.emplace_back([&flushedPromise]() { flushedPromise.set_value(); }); lock.unlock(); flushedFuture.wait (); } }
std::condition_variable 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 #include <iostream> #include <thread> #include <mutex> #include <condition_variable> std ::mutex mtx;std ::condition_variable cv;bool ready = false ;void print_id (int id) { std ::unique_lock<std ::mutex> lck (mtx) ; while (!ready) cv.wait(lck); std ::cout << "thread " << id << '\\n' ; } void go () { std ::unique_lock<std ::mutex> lck (mtx) ; ready = true ; cv.notify_all(); } int main () { std ::thread threads[10 ]; for (int i=0 ; i<10 ; ++i) threads[i] = std ::thread(print_id,i); std ::cout << "10 threads ready to race...\\n" ; go(); for (auto & th : threads) th.join(); return 0 ; }
Possible output (thread order may vary):
1 2 3 4 5 6 7 8 9 10 11 10 threads ready to race... thread 2 thread 0 thread 9 thread 4 thread 6 thread 8 thread 7 thread 5 thread 3 thread 1
type_traits 空类的作用
还有一个关于空类的疑问就是,C++语言有必要保留空类吗?空类实现空对象有什么用?
有用的,尤其是在“泛型编程”中,空类(结构)的用处非常广:
在其他的文章中提到,我们利用类型(通常是空类)来区别对待不同类对象的属性。(其实我们是可以通过使用常数来区分的,但是区别我们很容易就能知道)。
使用常数来区分需要使用 if else
的这种运行时来确定执行的线路的方法,而使用函数重载的方法,在参数中加入一个空类域作为区分不同的函数的方法,编译的时候直接选择,而不是在运行的时候选择,这是非常提高效率的。
要知道,不同的空类,是不同的。他们代表着不同的类型(虽然他们结构一样)。在
STL
中,使用空类区分不同类型的标志,从而在编译的时候来对不同的类进行有针对性的优化是非常常见的。