
Linux 应用编程
文件 IO
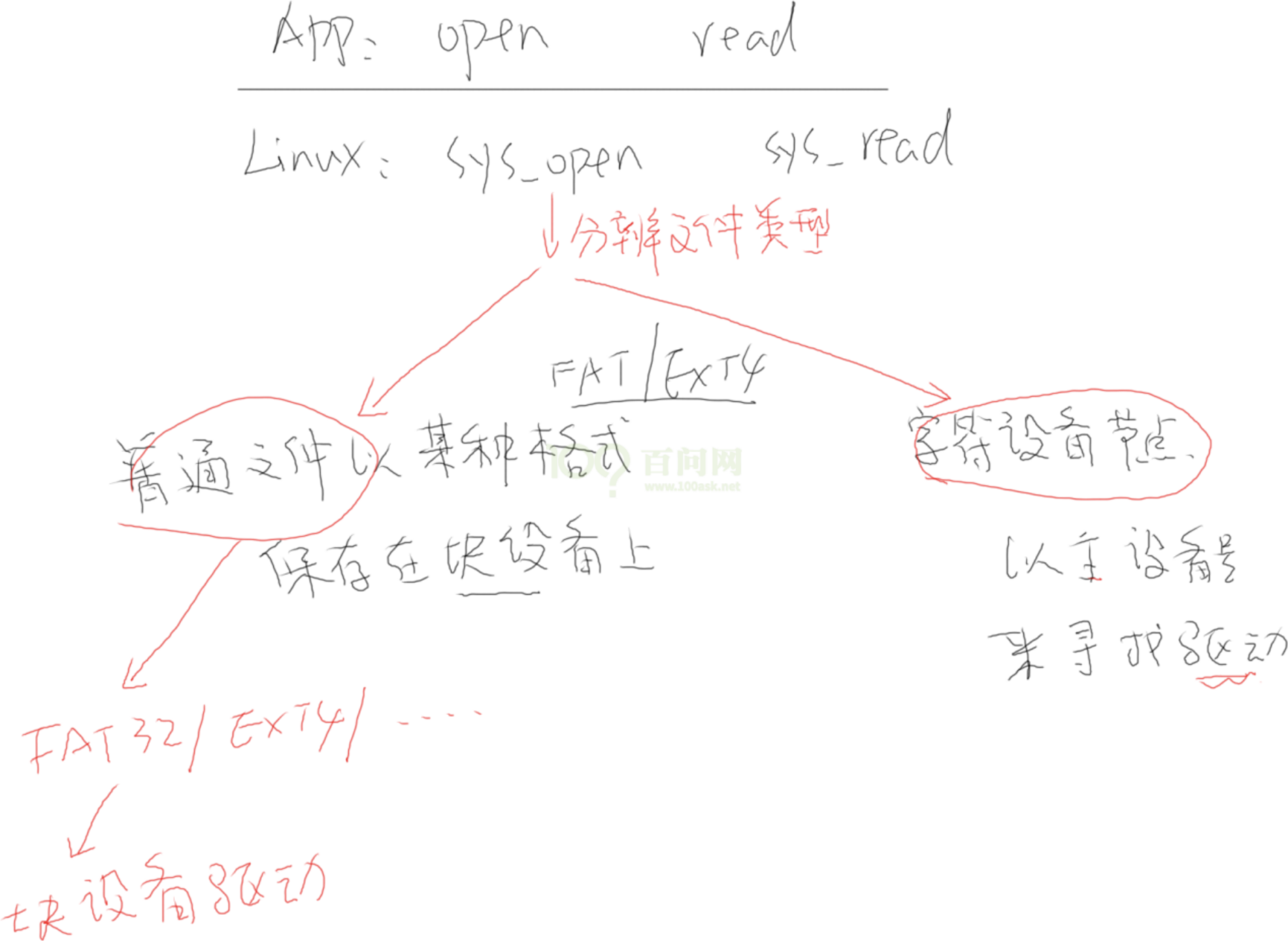
系统调用进入内核

内核的 sys_open、sys_read 做了什么:
Framebuffer 应用编程
LCD 操作原理
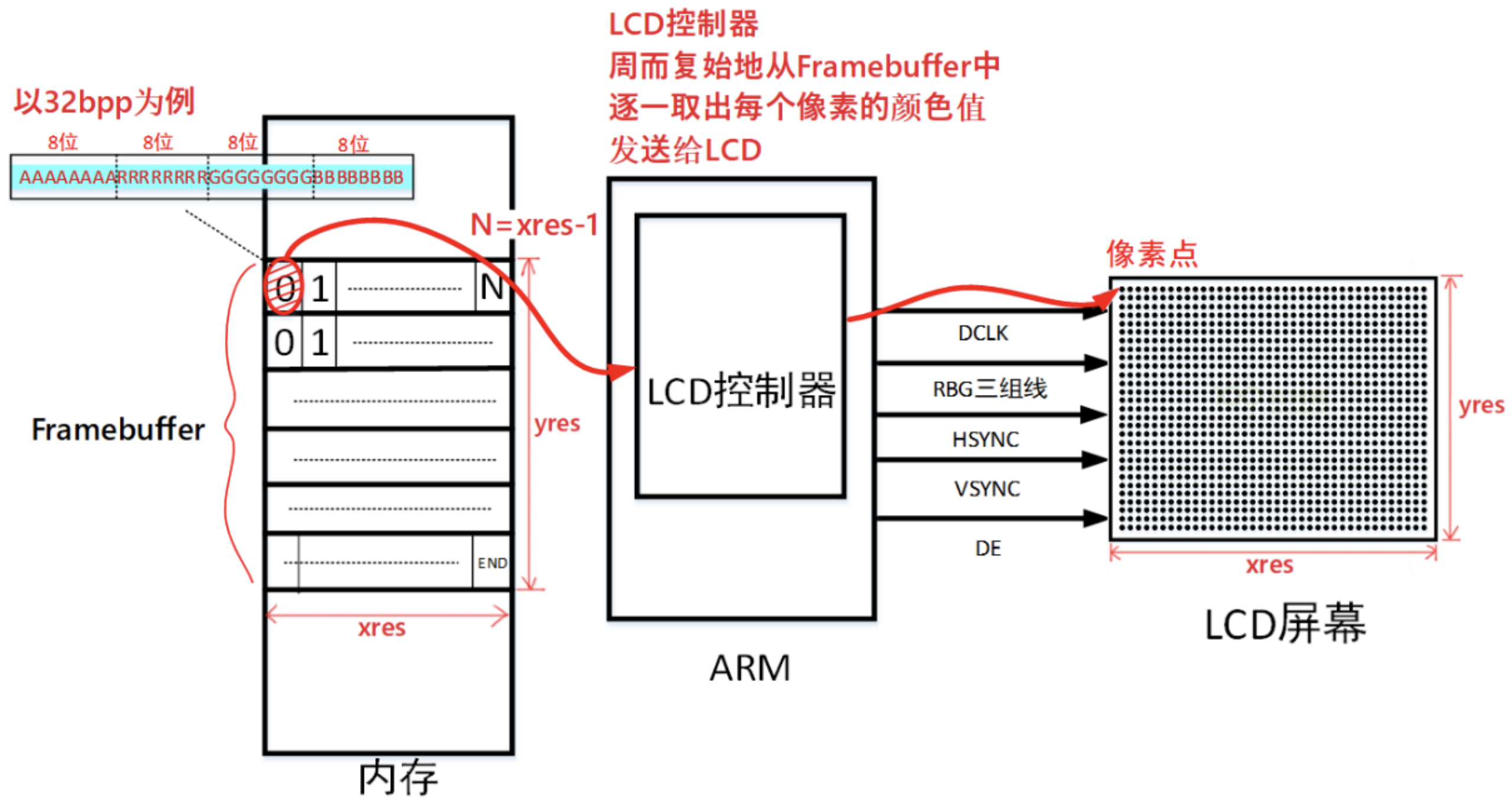
在 Linux 系统中通过 Framebuffer 驱动程序来控制 LCD。Frame 是帧的意思,buffer 是缓冲的意思,这意味着 Framebuffer 就是一块内存,里面保存着一帧图像。Framebuffer 中保存着一帧图像的每一个像素颜色值,假设 LCD 的分辨率是 1024x768,每一个像素的颜色用 32 位来表示,那么 Framebuffer 的大小就是:1024x768x32/8=3145728 字节。
简单介绍 LCD 的操作原理:
- 驱动程序设置好 LCD 控制器:根据 LCD 的参数设置 LCD 控制器的时序、信号极性;根据 LCD 分辨率、BPP 分配 Framebuffer
- APP 使用 ioctl 获得 LCD 分辨率、BPP
- APP 通过 mmap 映射 Framebuffer,在 Framebuffer 中写入数据
假设需要设置 LCD 中坐标 (x,y) 处像素的颜色,首要要找到这个像素对应的内存,然后根据它的 BPP 值设置颜色。假设 fb_base 是 APP 执行 mmap 后得到的 Framebuffer 地址,如下图所示:
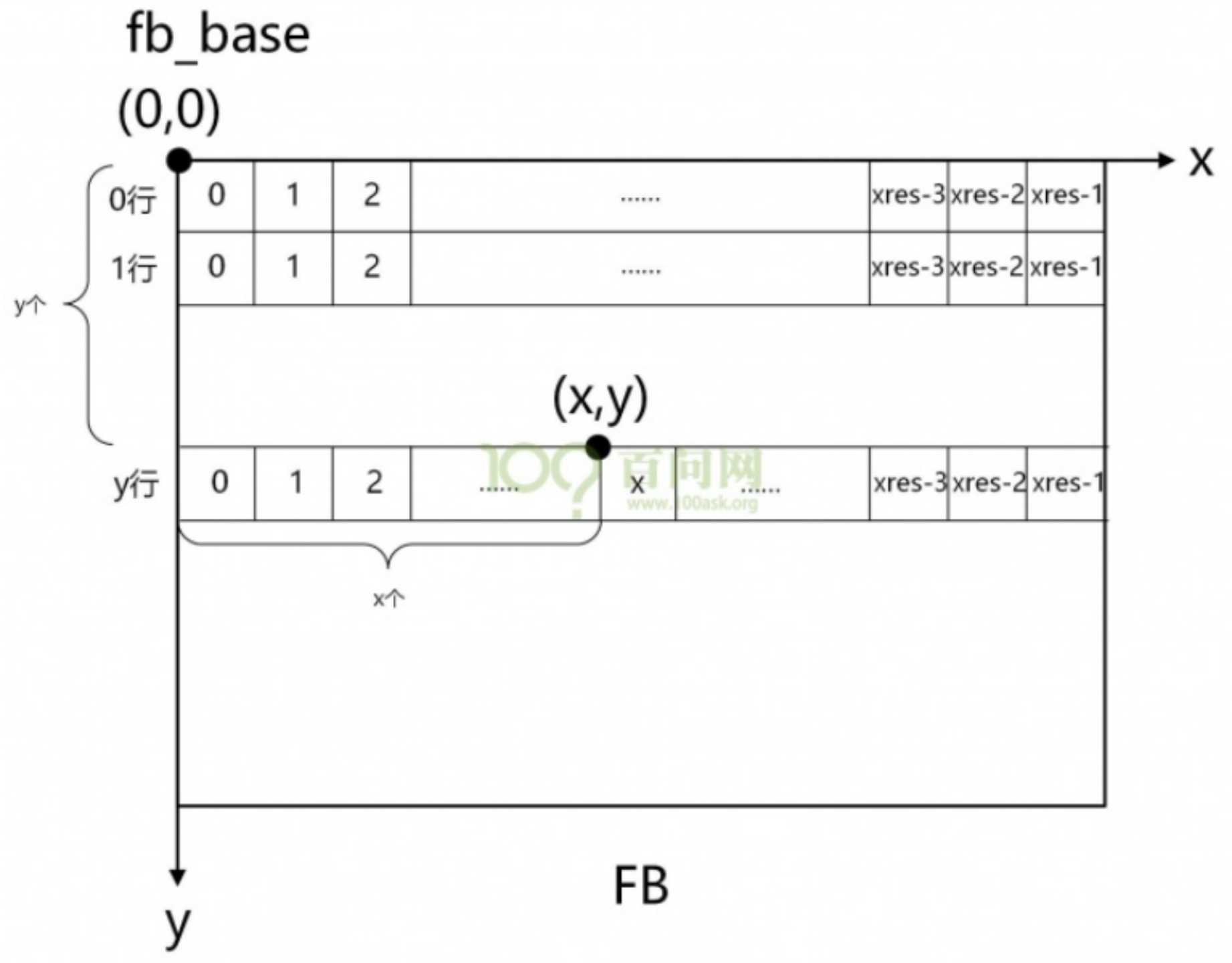
可以用以下公式算出 (x,y) 坐标处像素对应的 Framebuffer 地址:(x,y) 像素起始地址=fb_base+(xres*bpp/8)_y + x_bpp/8
最后一个要解决的问题就是像素的颜色怎么表示?它是用 RGB 三原色(红、绿、蓝)来表示的,在不同的 BPP 格式中,用不同的位来分别表示 R、G、B,如下图所示:
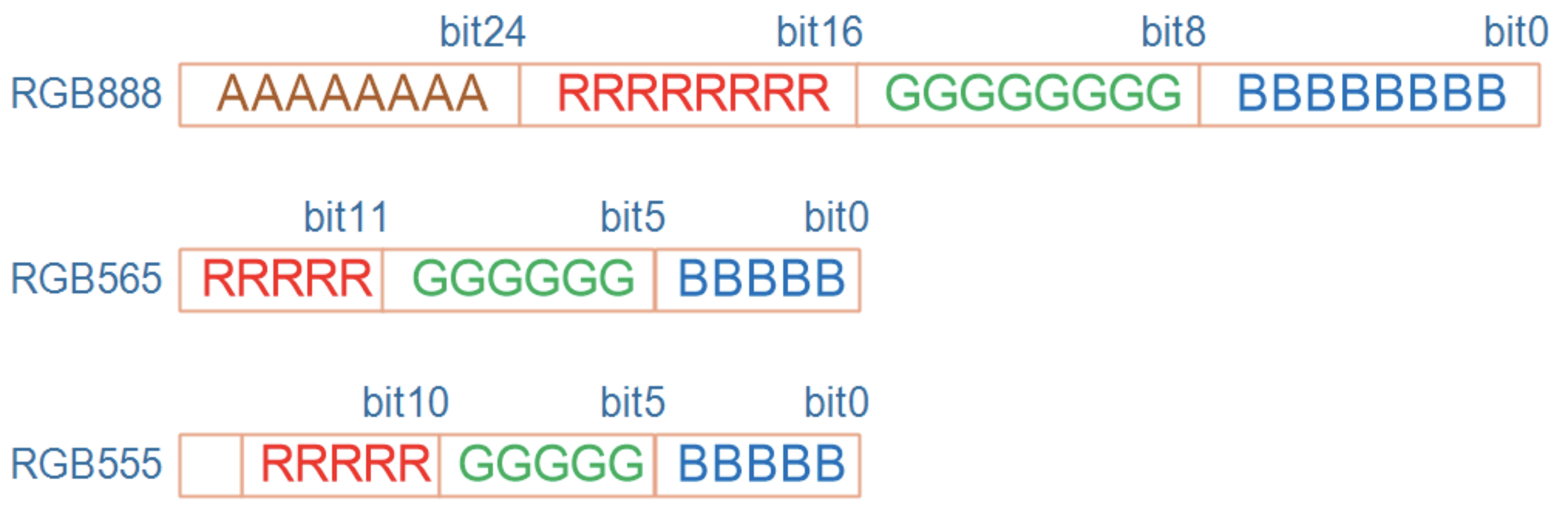
对于 32BPP,一般只设置其中的低 24 位,高 8 位表示透明度,一般的 LCD 都不支持。
对于 24BPP,硬件上为了方便处理,在 Framebuffer 中也是用 32 位来表示,效果跟 32BPP 是一样的。
对于 16BPP,常用的是 RGB565;很少的场合会用到 RGB555,这可以通过 ioctl 读取驱动程序中的 RGB 位偏移来确定使用哪一种格式。
文字显示
字符的编码方式(区分编码和字体)
在计算机上,我们看到的字符“A”可能长这样: 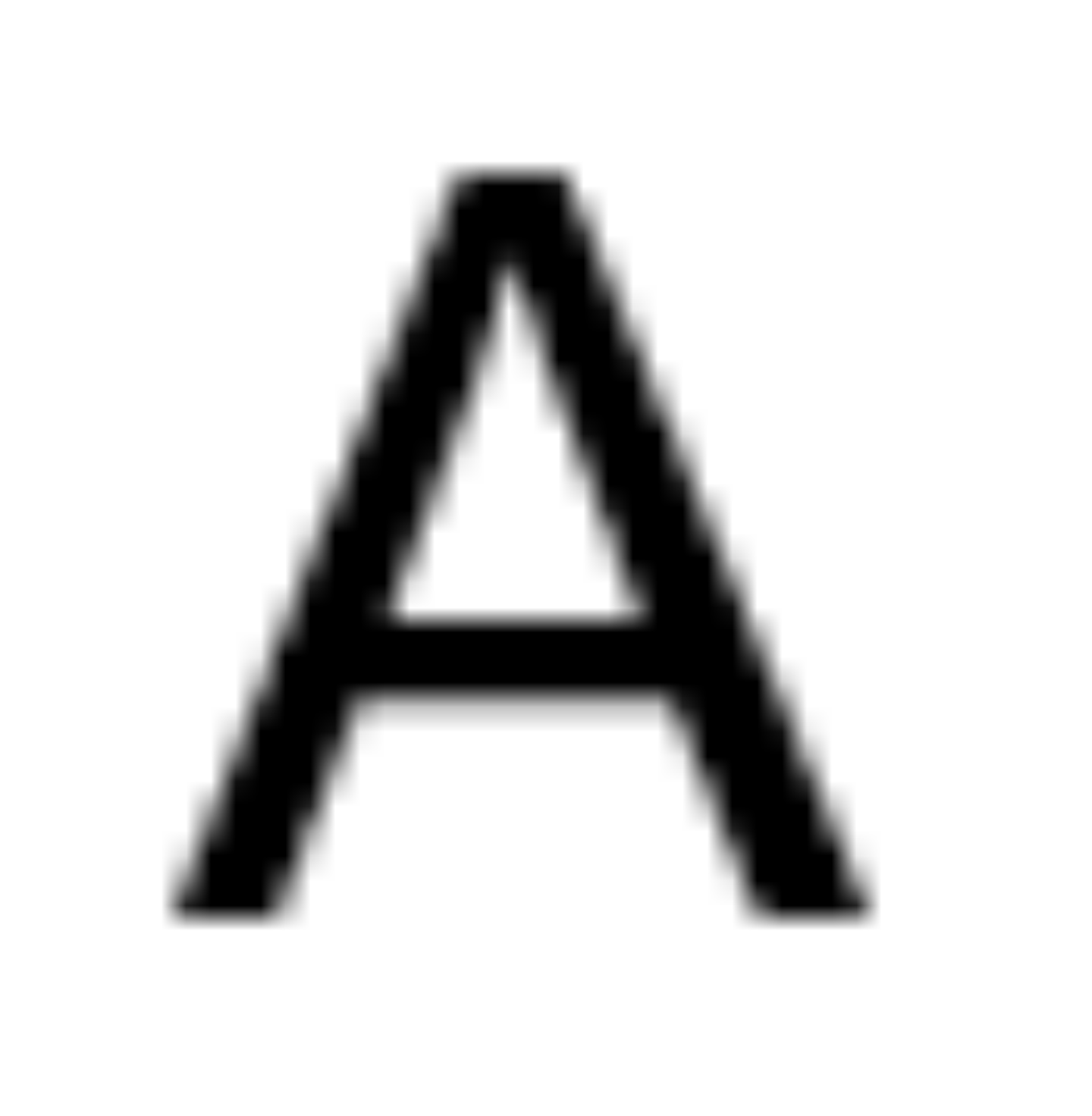
也可能长这样: 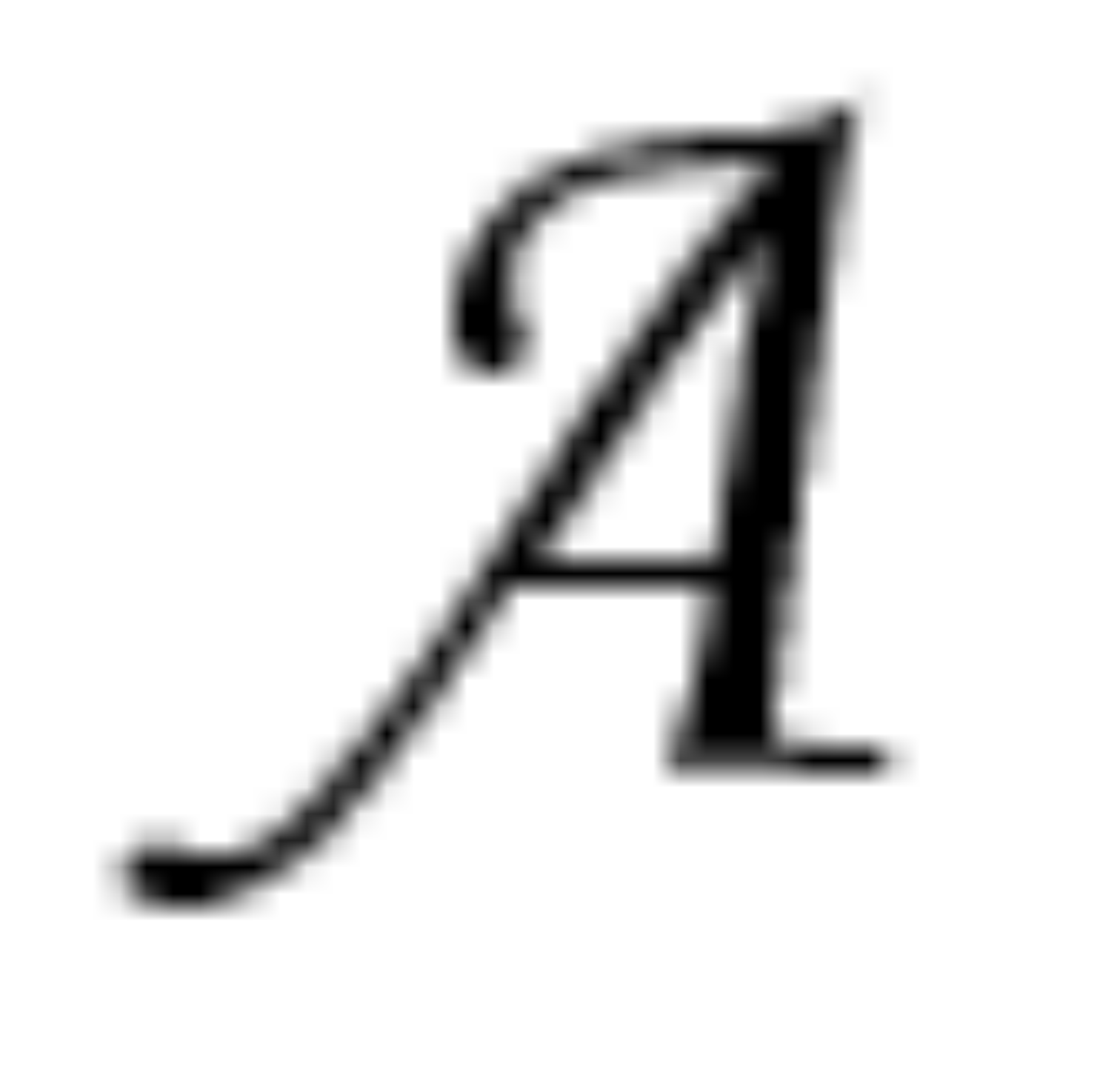
对于同一个 TXT 文件中的内容,你在 Notepad 上选择不同字体时,字符显示的形状不一样。
所以 TXT 文件中保存的是字符的核心:它的编码值。而 Notepad 上显示时,这些字符对应什么样的形状态,这是由字符文件决定的。编码值,字体是两个不一样的东西,比如 A 的编码值是 0x41,但是在屏幕上显示出来时可以使用不同的形状。
ASCII
是“American Standard Code for Information Interchange”的缩写,美国信息交换标准代码。 
ANSI
使用记事本保存文件时,可以选择“ANSI”编码,却没有“ASCII”,各下图所示。怎么回事?
ASNI 是 ASCII 的扩展,向下包含 ASCII。对于 ASCII 字符仍以一个字节来表示,对于非 ASCII 字符则使用 2 字节来表示。并没有固定的 ASNI 编码,它跟“本地化”(locale) 密切相关。比如在中国大陆地区,ANSI 的默认编码是 GB2312;在港澳台地区默认编码是 BIG5。以数值“0xd0d6”为例,对于 GB2312 编码它表示“中”;对于 BIG5 编码它表示“笢”。所以对于 ANSI 编码的 TXT 文件,如果你打开它发现乱码,那么还得再次细分它的具体编码。
这仅仅是在中国地区就出现这些不兼容的问题。对于不同国家,它们默认的 ANSI 编码各不相同,所以同一个 TXT 文件在不同国家就很有可能出现乱码。
根本的原理在于没有“统一的编码”,那解决方法自然就是使用“统一的编码”:UNICODE。
UNICODE
在 ANSI 标准中,很多种文字都有自己的编码标准,汉字简体字有 GB2312、繁体字有 BIG5,这难免同一个数值对应不同字符。比如数值“0xd0d6”,对于 GB2312 编码它表示“中”;对于 BIG5 编码它表示“笢”。这造成了使用 ANSI 编码保存的文件,不适合跨地区交流。
UNICODE 编码就是解决这类问题:对于地球上任意一个字符,都给它一个唯一的数值。
UNICODE 仍然向下兼容 ASCII,但是对于其他字符会有对应的数值,比如对于“中”、“笢”,它们的数值分别是:0x4e2d、0x7b22
UNICODE 中的数值范围是 0x0000 至 0x10FFFF,有 1,114,111 即 100 多万个数值,可以表示 100 多万个字符,足够地球人使用了。
- UNICODE 编码实现
所谓编码实现,就是对于一个数值,怎么表示它。这很奇怪,数值还能怎么表示?比如“中”的 UNICODE 值是 0x4e2d,在 TXT 文件中怎么表示 0x4e2d?直接写入 0x4e2d?不行!
比如在 TXT 文件中写入 2 字节数据“0x2d 0x4e”,它可以用来表示“中”字吗?不能!它们对应 ASCII 字符“-N”。
问题的关键在于:怎么断字。在 TXT 文件中,2 字节数据“0x2d 0x4e”是作为一个整体看待,还是拆成 2 部分看待?
所以,需要用一定的技巧来表示数值,这就对应不同的编码实现。
现在我们知道:
- ASCII 编码中使用一个字节来表示一个字符,只用到其中的 7 位,最高位恒为 0
- ANSI 编码中,对于 ASCII 字符仍使用一个字节来表示 (BIT7 是 0),对于非 ASCII 字符一般使用 2 个字节来表示,非 ASCII 字符的数值 BIT7 都是 1
- UNICODE:这就有点复杂了,下面一一讲解
先用记事本新建 3 个文件:utf-16_le.txt、utf-16_be.txt、utf-8.txt、bom_utf-8.txt,里面的内容都是“ab 中”,保存时编码分别选择“UTF-16 LE”、“UTF-16 BE”、“UTF-8”、“带有 BOM 的 UTF-8”,下图是其中一个例子: 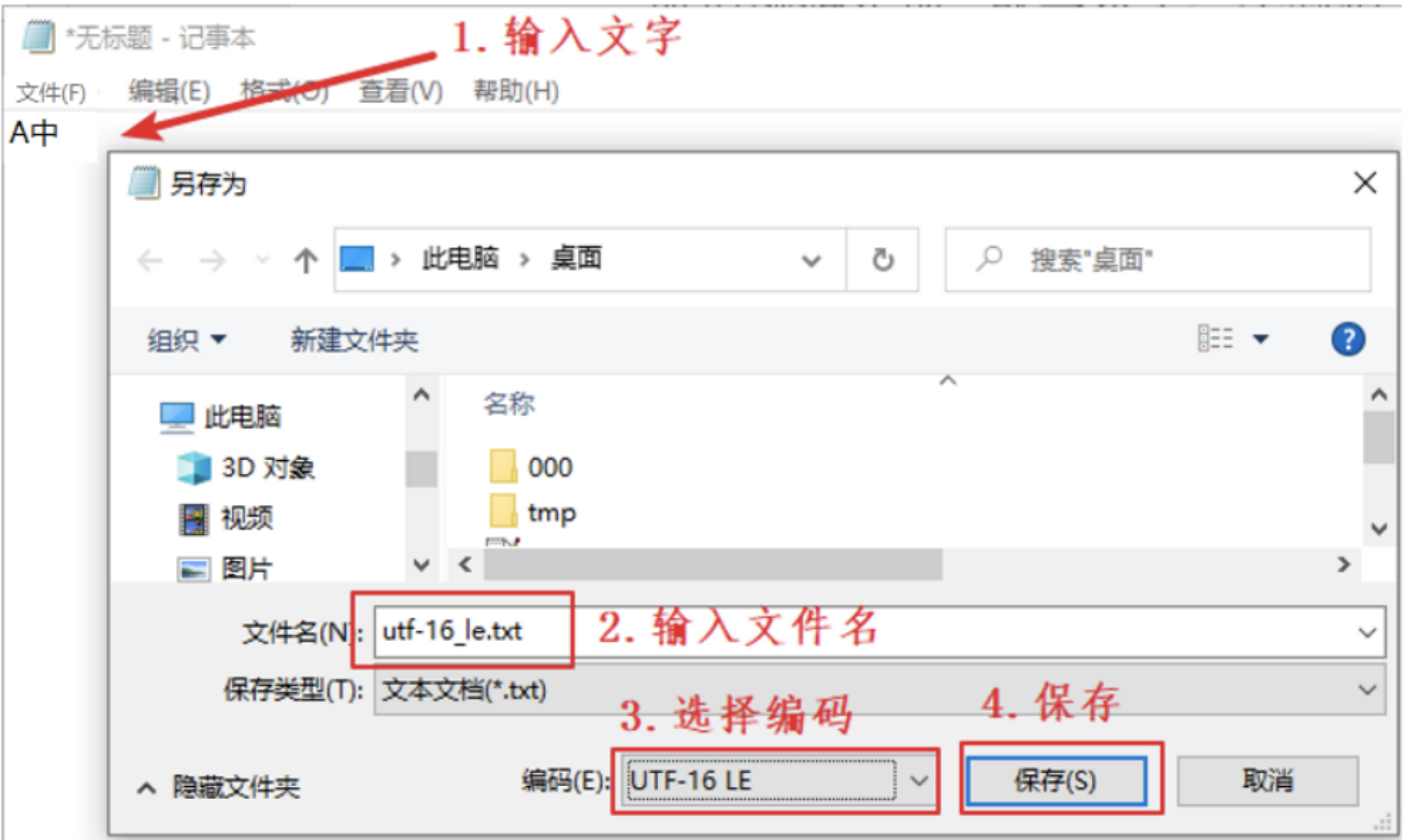 怎么表示一个 UNICODE 数值?
怎么表示一个 UNICODE 数值?
- 使用 3 个字节表示一个 UNICODE
不,太浪费。
UNICODE 的最大值是 0x10FFFF,那使用 3 个字节来表示一个 UNICODE 数值?这当然是很省事的方法,但是会造成浪费,比如字符 A 的 UNICOCDE 值是 0x41,难道也用“0x41 0x00 0x00”这 3 个字节来表示
- UCS-2 Little endian/UTF-16 LE
每个 UNICODE 值用 3 字节来表示有点浪费,那只用 2 字节呢?它可以表示 2^16=65536 个字符,全世界常用的字符都可以表示了。
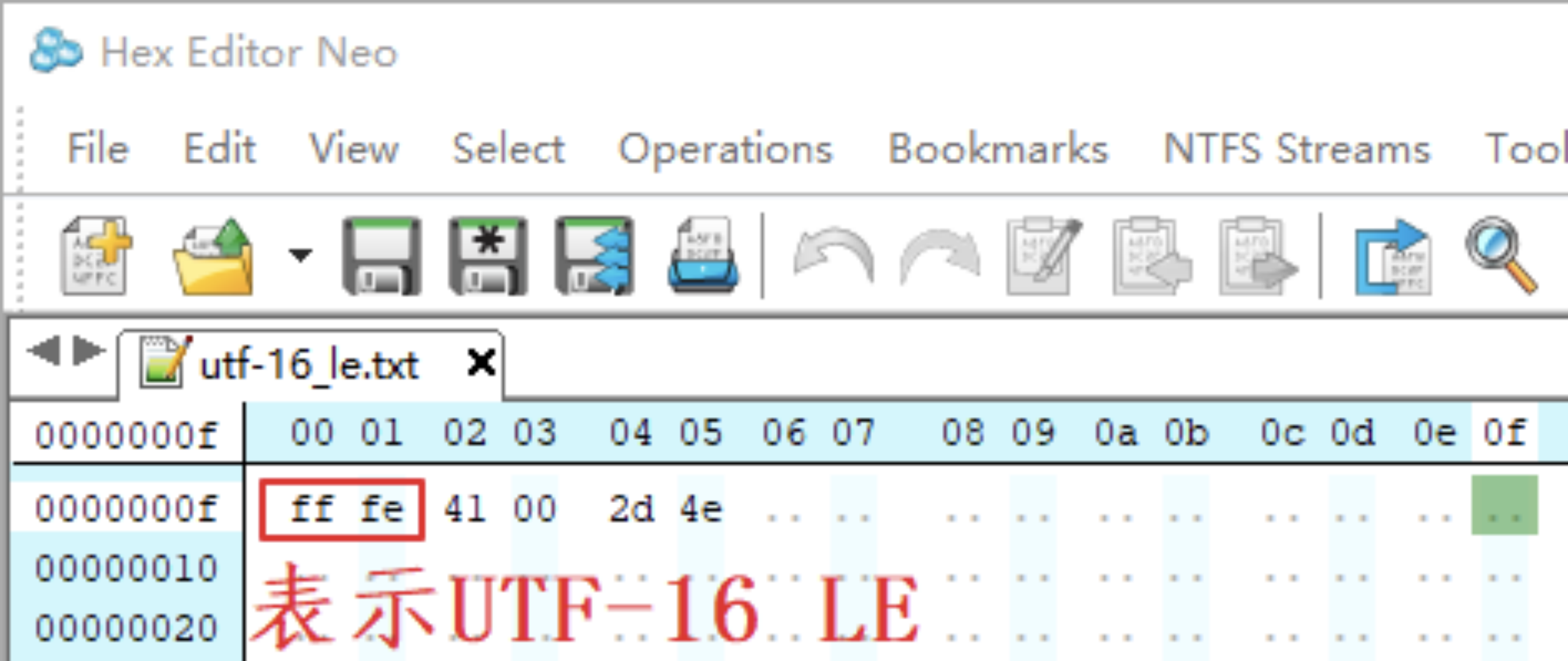
Little endian 表示小字节序,数值中权重低的字节放在前面,比如字符“A 中”在 TXT 文件中的数值如下,其中的“A”使用“0x41 0x00”两字节表示;“中”使用“0x2d 0x4e”两字节表示。文件开头的“0xff 0xfe”表示“UTF-16 LE”。
- UCS-2 Big endian/UTF-16 BE
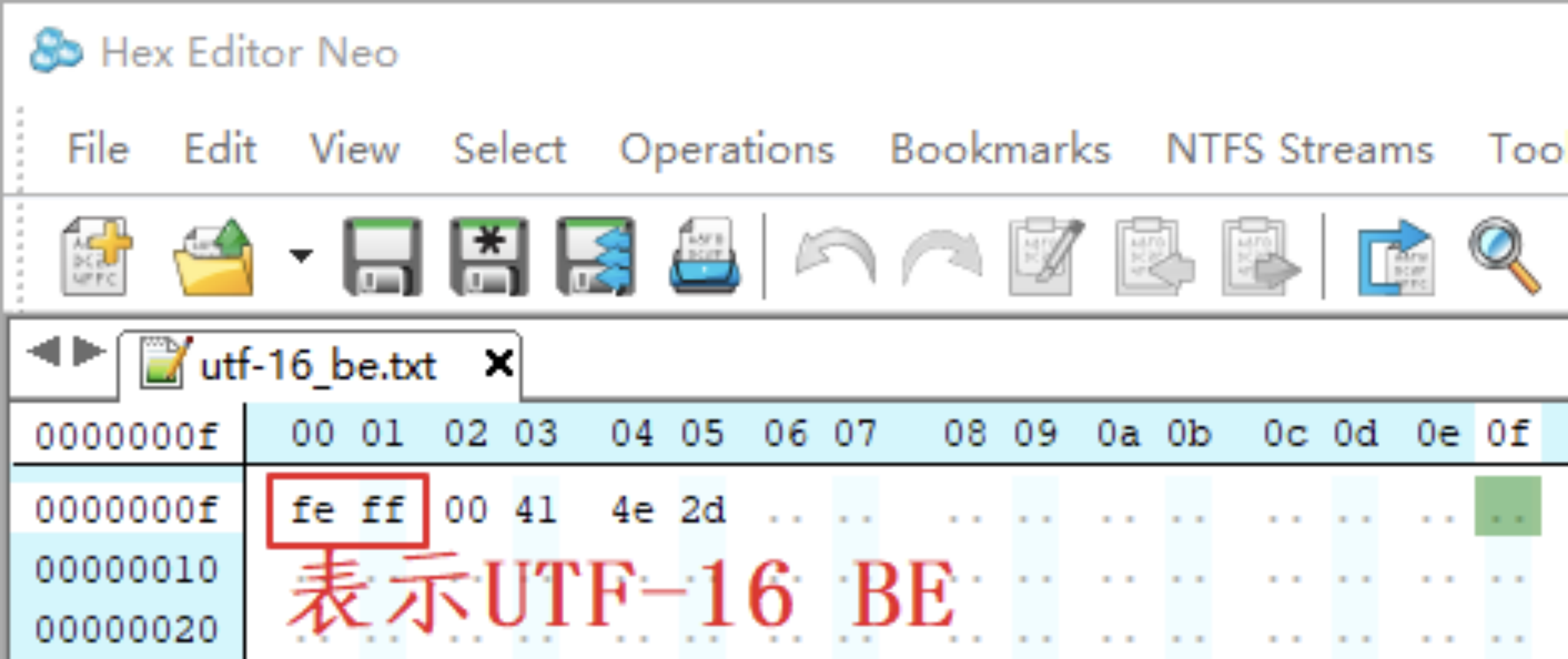
Big endian 表示大字节序,数值中权重低的字节放在后面,比如字符“ab 中”在 TXT 文件中的数值如下,其中的“A”使用“0x00 0x41”两字节表示;“中”使用“0x4e 0x2d”两字节表示。文件开头的“0xfe 0xff”表示“UTF-16 BE”。
- UTF8
在上面 2 种方法中,每一个 UNICODE 使用 2 字节来表示,这有 3 个缺点:表示的字符数量有限、对于 ASCII 字符有空间浪费、如果文件中有某个字节丢失,这会使得后面所有字符都因为错位而无法显示。
使用 UTF8 可以解决上述所有问题。UTF8 是变长的编码方法,有 2 种 UTF8 格式的文件:带有头部、不带头部。先举例,看下图: 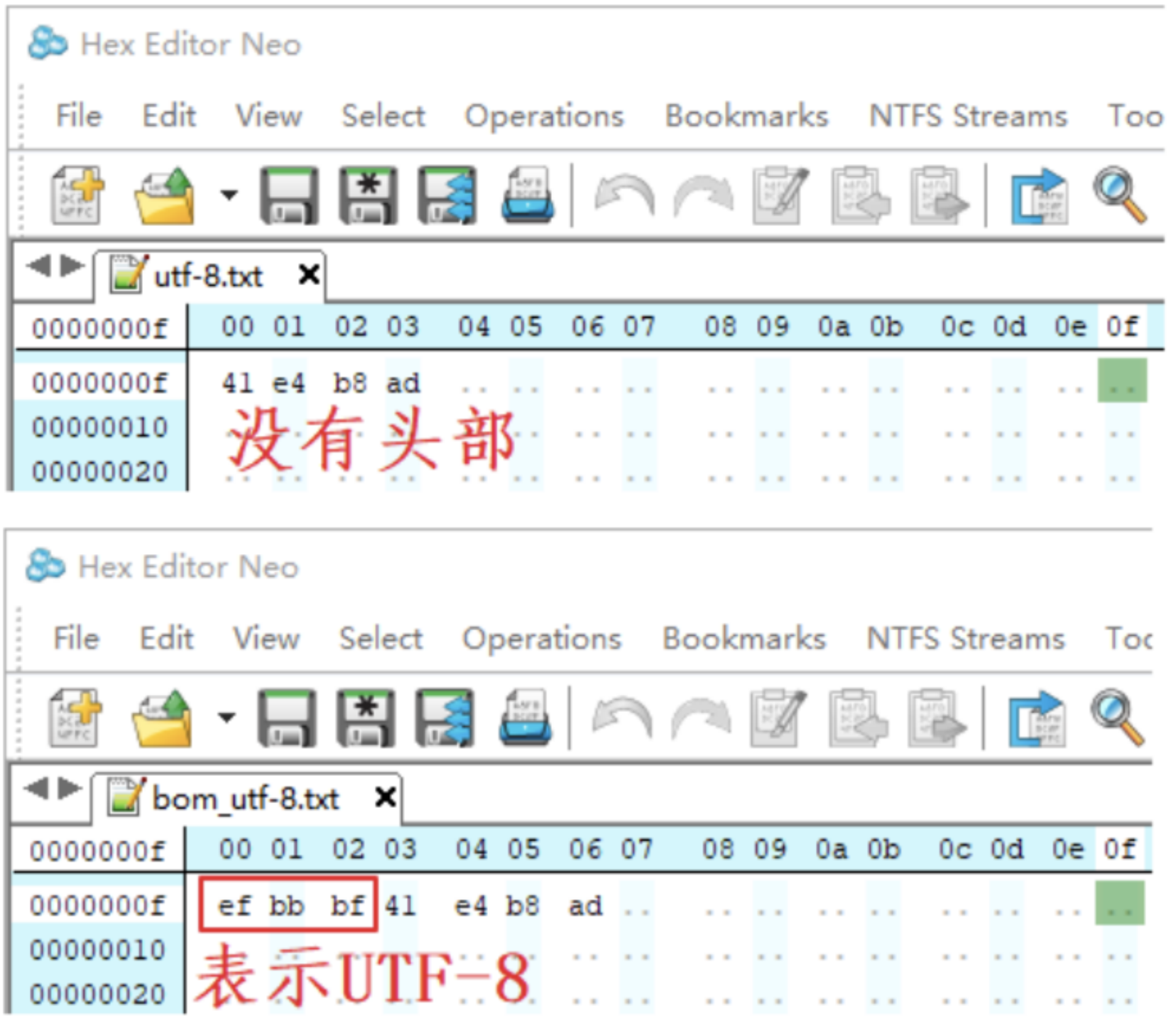
对于其中的 ASCII 字符,在 UTF8 文件中直接用其 ASCII 码来表示,比如上图中的 0x61 表示字符 a、0x62 表示字符 b。上图中的 3 个字节“0xe4 0xb8 0xad”表示的数值是 0x4e2d,对应“中”的 UNICODE 码。
对于非 ASCII 字符,使用变长的编码:每一个字节的高位都自带长度信息。请看下图
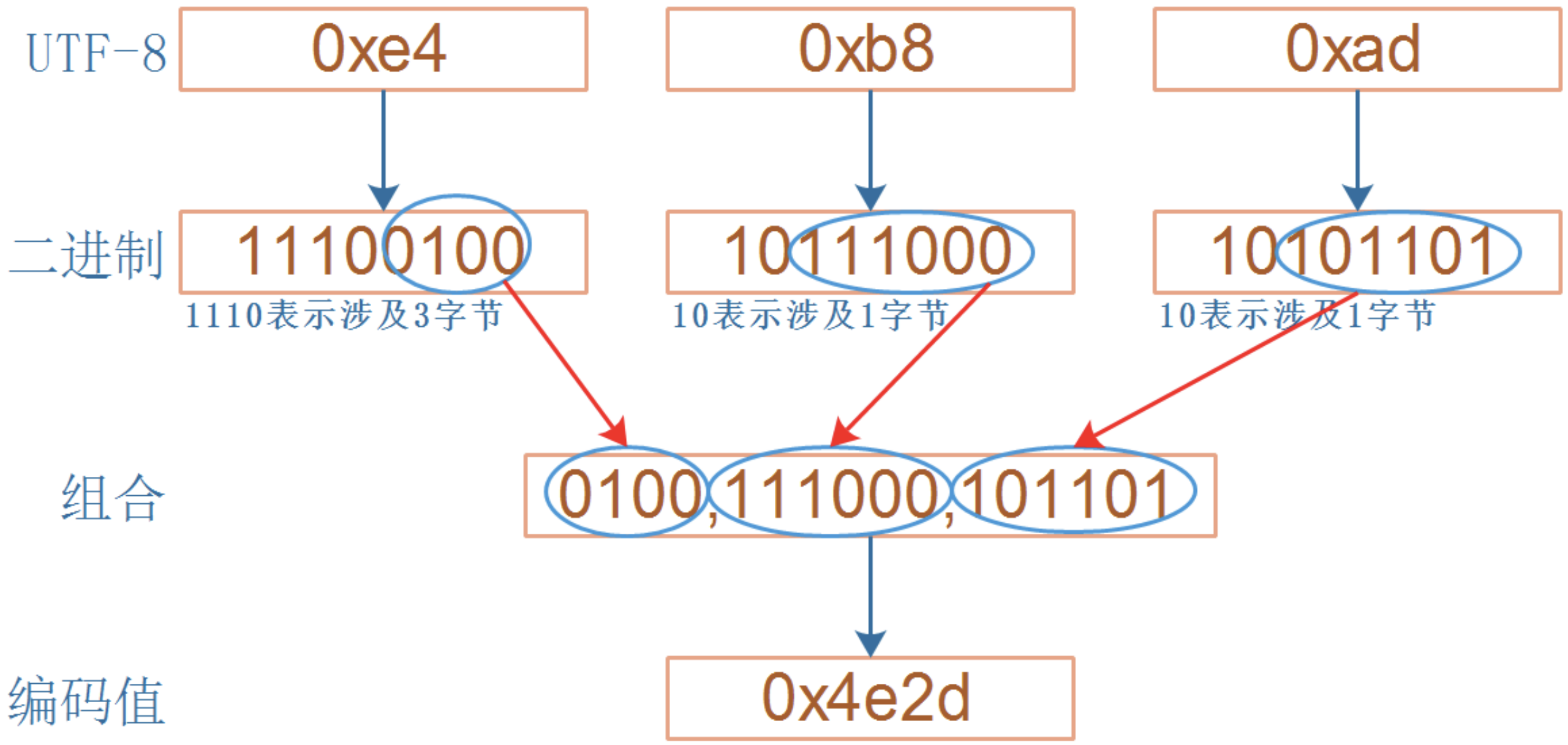
上图中,0xe4 的二进制是“11100100”,高位有 3 个 1,表示从当前字节起有 3 字节参与表示 UNICODE;
0xb8 的二进制是“10111000”,高位有 1 个 1,表示从当前字节起有 1 字节参与表示 UNICODE;
0xad 的二进制是“10101101”,高位有 1 个 1,表示从当前字节起有 1 字节参与表示 UNICODE;
除去高位的“1110”、“10”、“10”后,剩下的二进制数组合起来得到“01001110001101”,它就是 0x4e2d,即“中”的 UNICODE 值。
使用 UTF8 编码时,即使 TXT 文件中丢失了某些数据,也只会影响到当前字符的显示,后面的字符不受影响
ASCII 字符的点阵显示
要在 LCD 中显示一个 ASCII 字符,即英文字母这些字符,首先是要找到字符对应的点阵。在 Linux 内核源码中有这个文件:lib_8x16.c,里面以数组形式保存各个字符的点阵,比如:
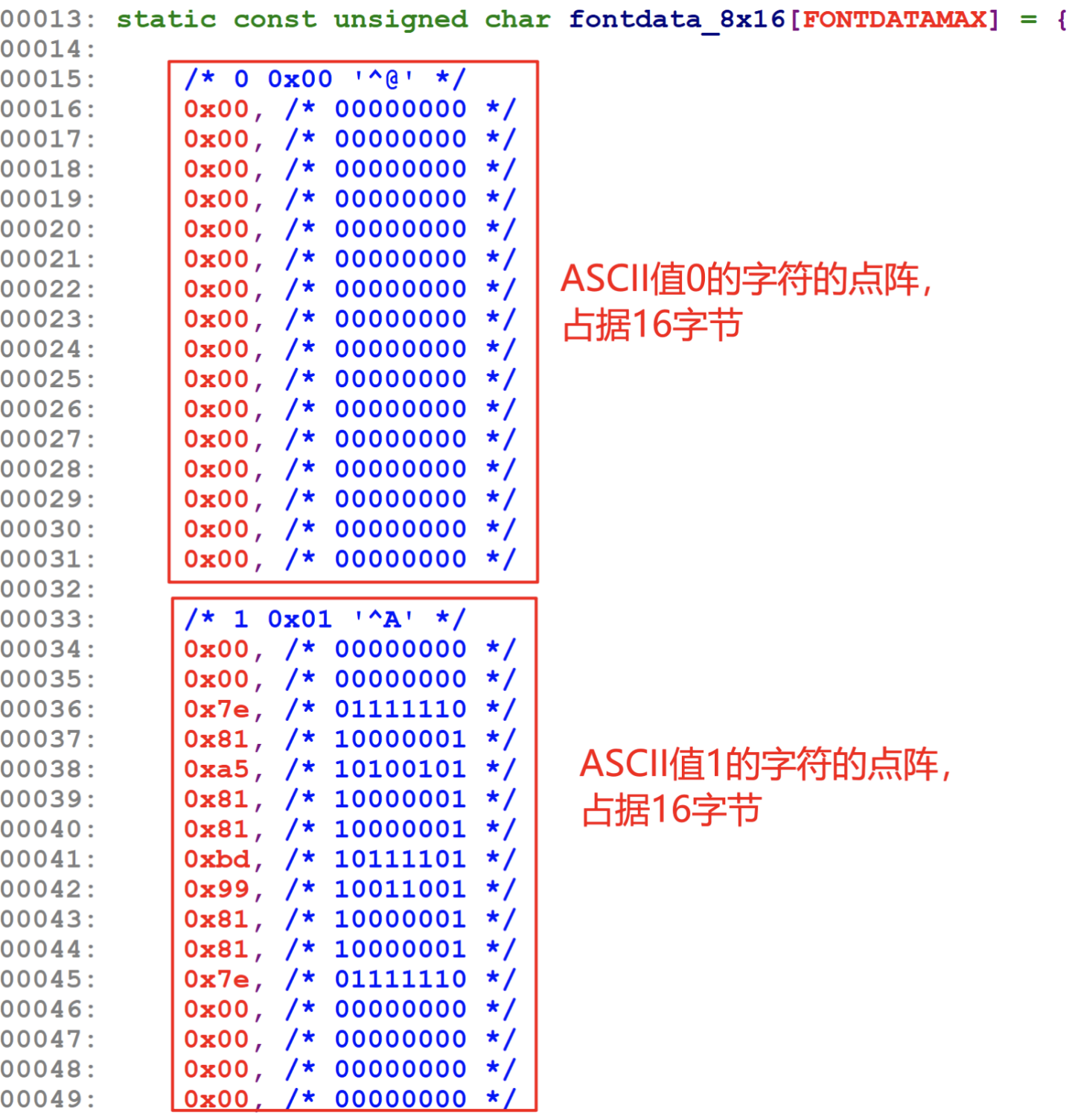
数组里的数字是如何表示点阵的?以字符 A 为例,如下图所示:

上图左侧有 16 行数值,每行 1 个字节。每一个节对应右侧一行中 8 个像素:像素从右边数起,bit0 对应第 0 个像素,bit1 对应第 1 个像素,……,bit7 对应第 7 个像素。某位的值为 1 时,表示对应的像素要被点亮;值为 0 时表示对应的像素要熄灭。
所以要显示某个字符时,根据它的 ASCII 码在 fontdata_8x16 数组中找到它的点阵,然后取出这 16 个字节去描画 16 行像素。
比如字符 A 的 ASCII 值是 0x41,那么从 fontdata_8x16[0x41*16] 开始取其点阵数据。
矢量字体引入
使用点阵字库显示英文字母、汉字时,大小固定,如果放大缩小则会模糊甚至有锯齿出现,为了解决这个问题,引用矢量字体。
矢量字体形成分三步:
- 确定关键点
- 使用数学曲线(贝塞尔曲线)连接头键点
- 填充闭合区线内部空间
什么是关键点?以字母“A”为例,它的的关键点如下图中的黄色所示。

如果需要放大或者缩小字体,关键点的相对位置是不变的,只要数学曲线平滑,字体就不会变形。
Freetype 介绍
Freetype 是开源的字体引擎库,它提供统一的接口来访问多种字体格式文件,从而实现矢量字体显示。我们只需要移植这个字体引擎,调用对应的 API 接口,提供字体文件,就可以让 freetype 库帮我们取出关键点、实现闭合曲线,填充颜色,达到显示矢量字体的目的。
关键点 (glyph) 存在字体文件中,Windows 使用的字体文件在 c:目录下,扩展名为 TTF 的都是矢量字库,本次使用实验使用的是新宋字体 simsun.ttc。
给定一个字符,怎么在字体文件中找到它的关键点?
首先要确定该字符的编码值:比如 ASCII 码、GB2312 码、UNICODE 码。如果字体文件支持某种编码格式 (charset),就可以使用这类编码值去找到该字符的关键点 (glyph)。有些字体文件支持多种编码格式 (charset),这在文件中被称为 charmaps(注意:这个单词是复数,意味着可能支持多种 charset)。
以 simsun.ttc 为值,该字体文件的格如下:头部含有 charmaps,可以使用某种编码值去 charmaps 中找到它对应的关键点。下图中的“A、B、中、国、韦”等只是 glyph 的示意图,表示关键点。
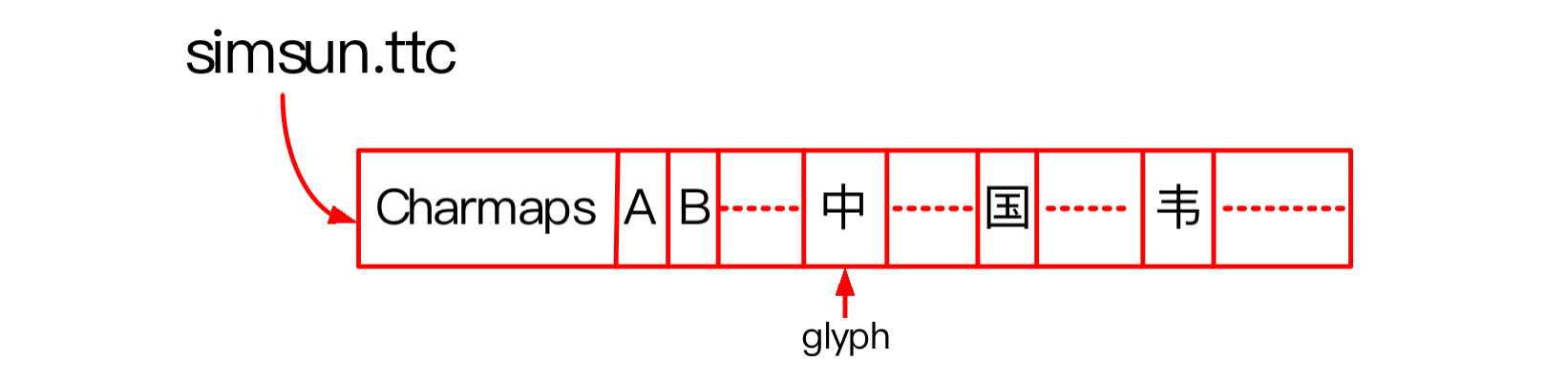
Charmaps 表示字符映射表,字体文件可能支持哪一些编码,GB2312、UNICODE、BIG5 或其他。如果字体文件支持该编码,使用编码值通过 charmap 就可以找到对应的 glyph,一般而言都支持 UNICODE 码。
有了以上基础,一个文字的显示过程可以概括如下:
- 给定一个字符可以确定它的编码值 (ASCII、UNICODE、GB2312)
- 设置字体大小
- 根据编码值,从文件头部中通过 charmap 找到对应的关键点 (glyph),它会根据字体大小调整关键点
- 把关键点转换为位图点阵
- 在 LCD 上显示出来
使用:
- 初始化:FT_InitFreetype
- 加载(打开)字体 Face:FT_New_Face
- 设置字体大小:FT_Set_Char_Sizes 或 FT_Set_Pixel_Sizes
- 选择 charmap:FT_Select_Charmap
- 根据编码值 charcode 找到 glyph_index:glyph_index = FT_Get_Char_Index(face,charcode)
- 根据 glyph_index 取出 glyph:FT_Load_Glyph(face,glyph_index)
- 转为位图:FT_Render_Glyph
- 移动或旋转:FT_Set_Transform
- 最后显示出来
上面的⑤⑥⑦可以使用一个函数代替:FT_Load_Char(face, charcode, FT_LOAD_RENDER),它就可以得到位图。
输入系统应用编程
输入系统框架及调试
框架概述
输入系统框架如下图所示:
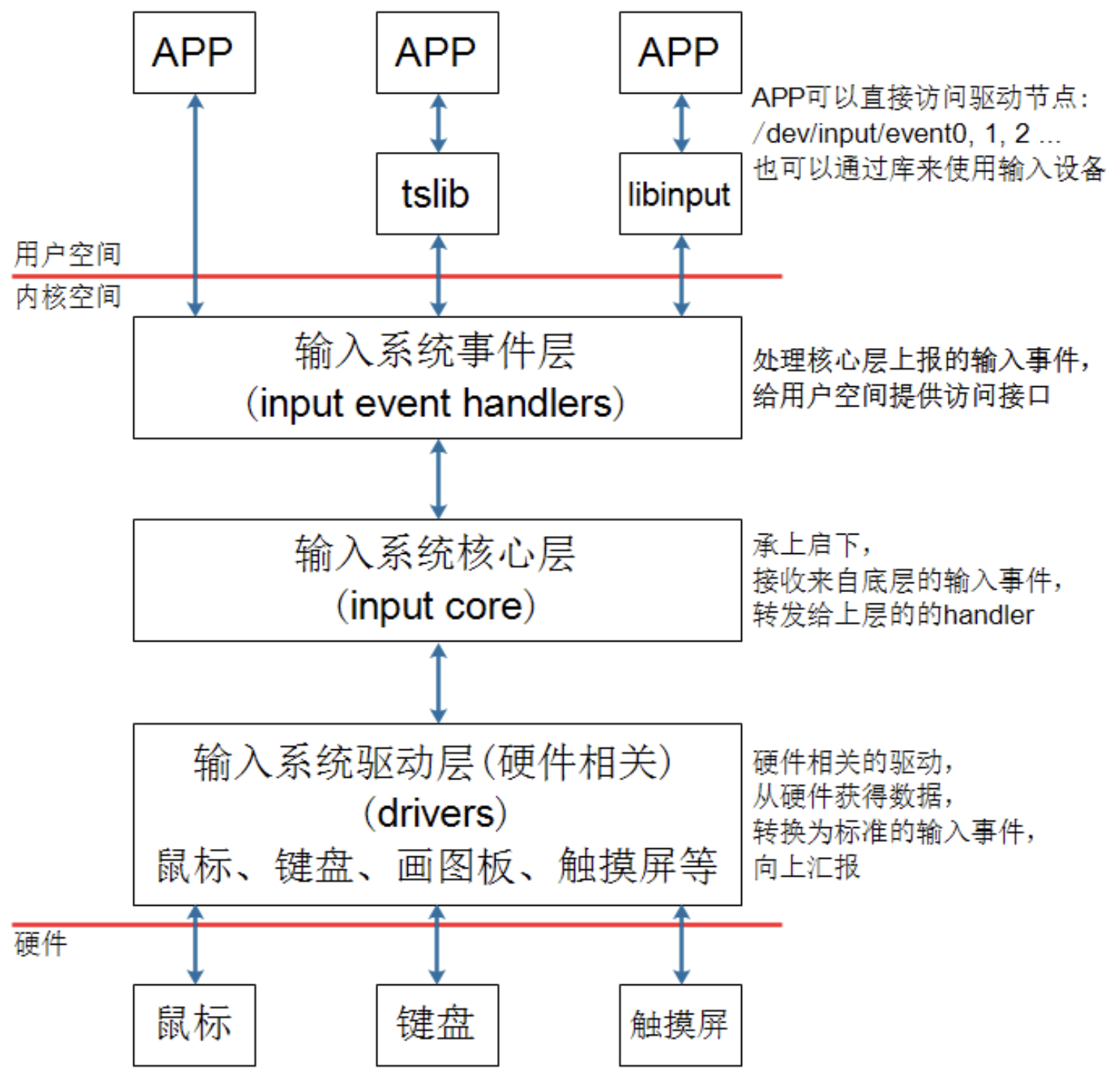
假设用户程序直接访问/dev/input/event0 设备节点,或者使用 tslib 访问设备节点,数据的流程如下:
- APP 发起读操作,若无数据则休眠;
- 用户操作设备,硬件上产生中断;
输入系统驱动层对应的驱动程序处理中断:
读取到数据,转换为标准的输入事件,向核心层汇报。 所谓输入事件就是一个“struct input_event”结构体。核心层可以决定把输入事件转发给上面哪个 handler 来处理:
从 handler 的名字来看,它就是用来处输入操作的。有多种 handler,比如:evdev_handler、kbd_handler、 joydev_handler 等等。最常用的是 evdev_handler:它只是把 input_event 结构体保存在内核 buffer 等,APP 来读取时就原原本本地返回。它 支持多个 APP 同时访问输入设备,每个 APP 都可以获得同一份输入事件。
当 APP 正在等待数据时,evdev_handler 会把它唤醒,这样 APP 就可以返回数据。
APP 对输入事件的处理:
APP 获得数据的方法有 2 种:直接访问设备节点(比如/dev/input/event0,1,2,...),或者通过 tslib、libinput 这类库来间接访问设备节点。这些库简化了对数据的处理。
编写 APP 需要掌握的知识
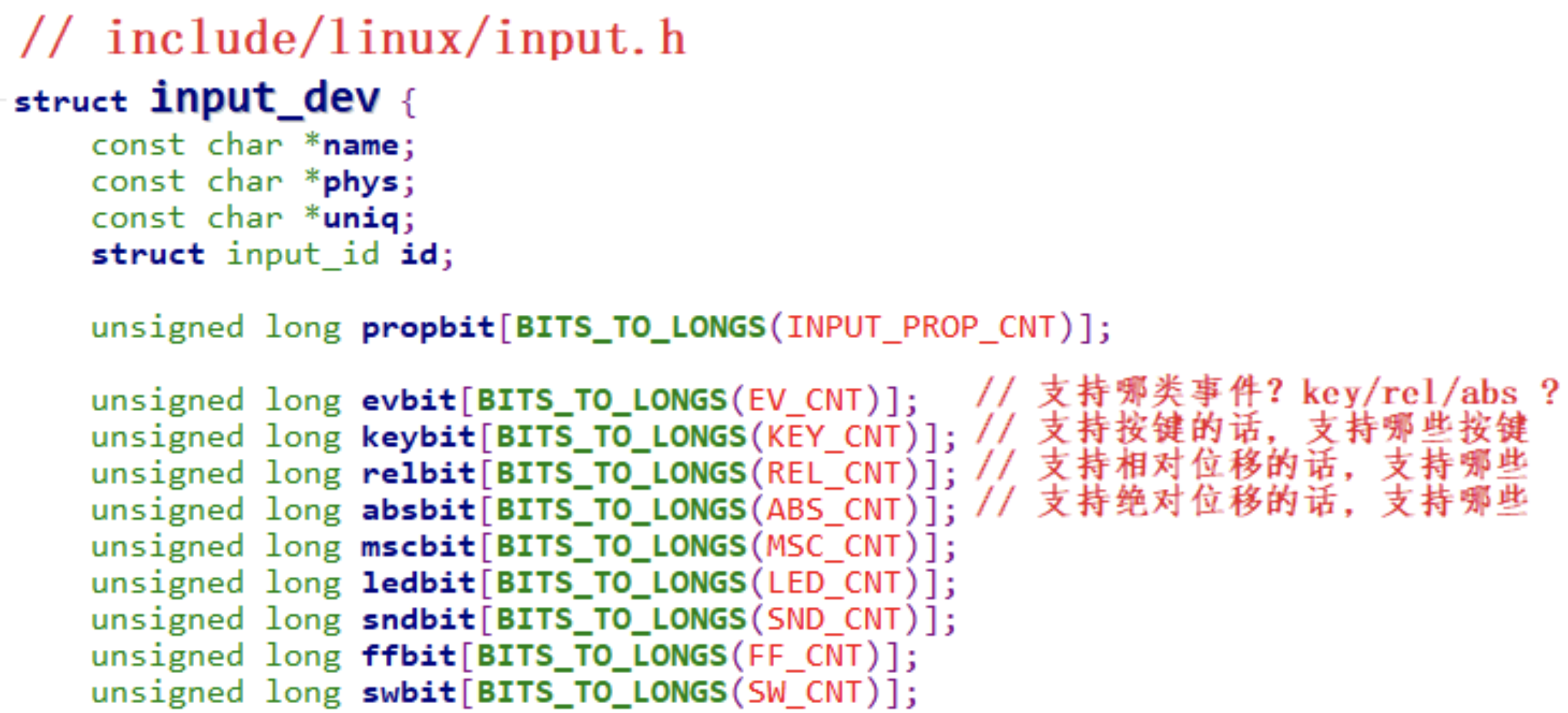
内核中怎么表示一个输入设备?
使用 input_dev 结构体来表示输入设备,它的内容如下:
APP 可以得到什么数据?
可以得到一系列的输入事件,就是一个一个“struct input_event”,它定义如下:

每个输入事件 input_event 中都含有发生时间:timeval 表示的是“自系统启动以来过了多少时间”,它是一个结构体,含有“tv_sec、tv_usec”两项(即秒、微秒)。
输入事件 input_event 中更重要的是:type(哪类事件)、code(哪个事件)、value(事件值),细讲如下:
type:表示哪类事件
比如 EV_KEY 表示按键类、EV_REL 表示相对位移(比如鼠标),EV_ABS 表示绝对位置(比如触摸屏)。有这几类事件(参考 Linux 内核头文件):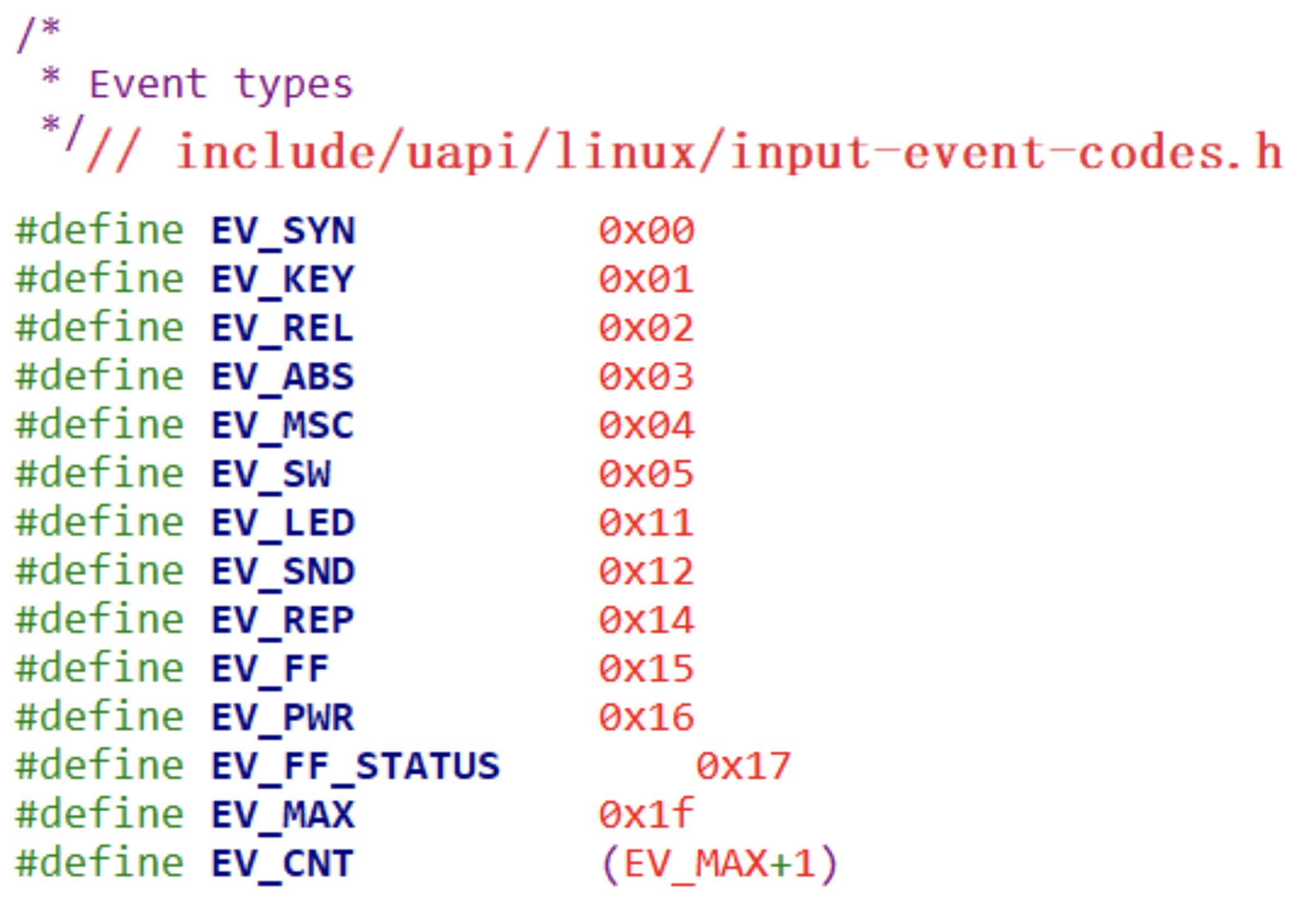
code:表示该类事件下的哪一个事件
比如对于 EV_KEY(按键)类事件,它表示键盘。键盘上有很多按键,比如数字键 1、2、3,字母键 A、B、C 里等。所以可以 有这些事件:
对于触摸屏,它提供的是绝对位置信息,有 X 方向、Y 方向,还有压力值。所以 code 值有这些:

value:表示事件值
对于按键,它的 value 可以是 0(表示按键被按下)、1(表示按键被松开)、2(表示长按); 对于触摸屏,它的 value 就是坐标值、压力值。事件之间的界线
APP 读取数据时,可以得到一个或多个数据,比如一个触摸屏的一个触点会上报 X、Y 位置信息,也可能会上报压力值。APP 怎么知道它已经读到了完整的数据?
驱动程序上报完一系列的数据后,会上报一个“同步事件”,表示数据上报完毕。APP 读到“同步事件”时,就知道已经读 完了当前的数据。
同步事件也是一个 input_event 结构体,它的 type、code、value 三项都是 0。
输入子系统支持完整的 API 操作
支持这些机制:阻塞、非阻塞、POLL/SELECT、异步通知。
调试技巧
确定设备信息
输入设备的设备节点名为/dev/input/eventX(也可能是/dev/eventX,X 表示 0、1、2 等数字)。
怎么知道这些设备节点对应什么硬件呢?可以在板子上执行以下命令:
1 | cat /proc/bus/input/devices |
这条指令的含义就是获取与 event 对应的相关设备信息,可以看到类似以下的结果:
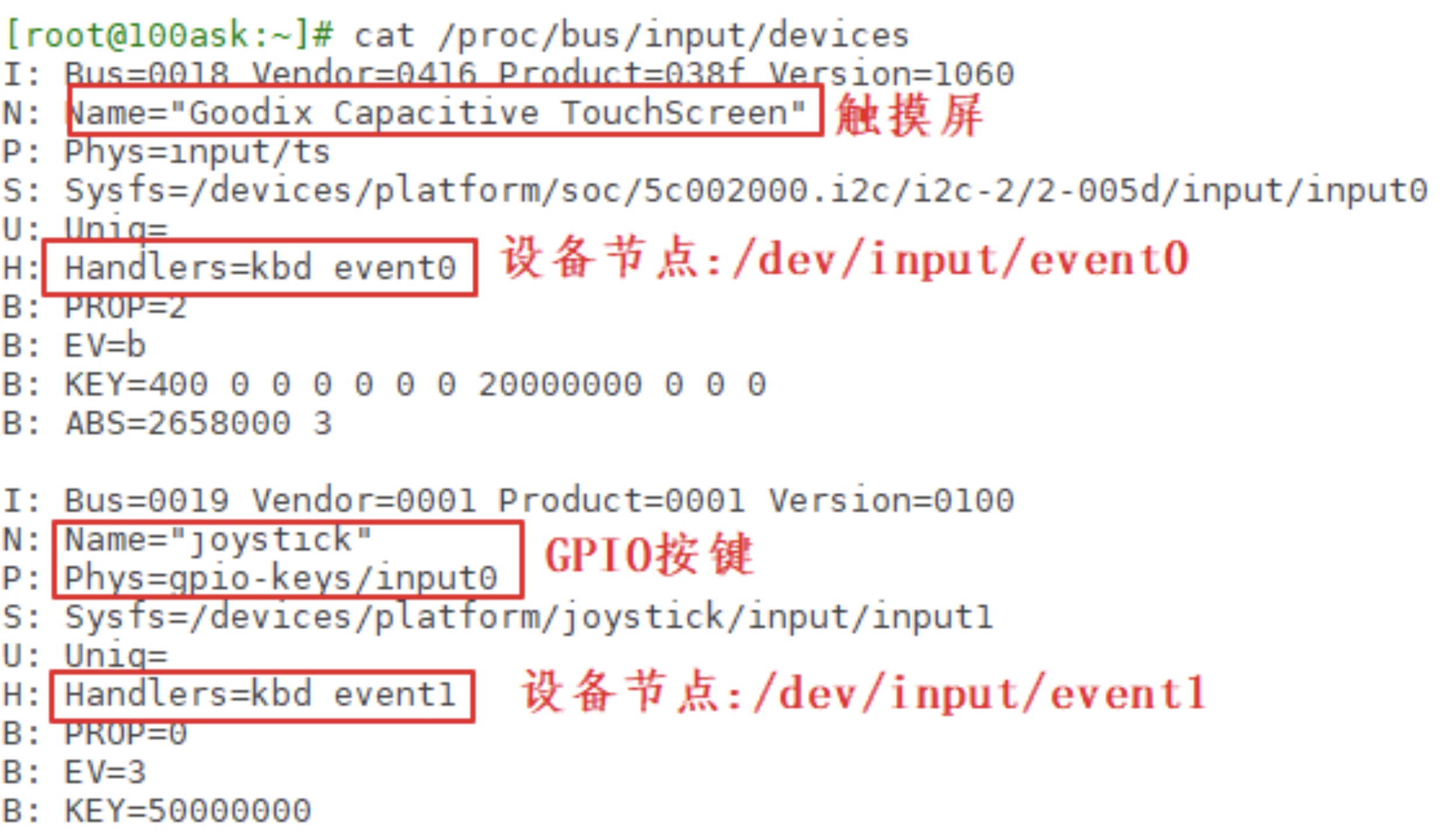
那么这里的 I、N、P、S、U、H、B 对应的每一行是什么含义呢?
I:id of the device(设备 ID)
该参数由结构体 struct input_id 来进行描述,驱动程序中会定义这样的结构体: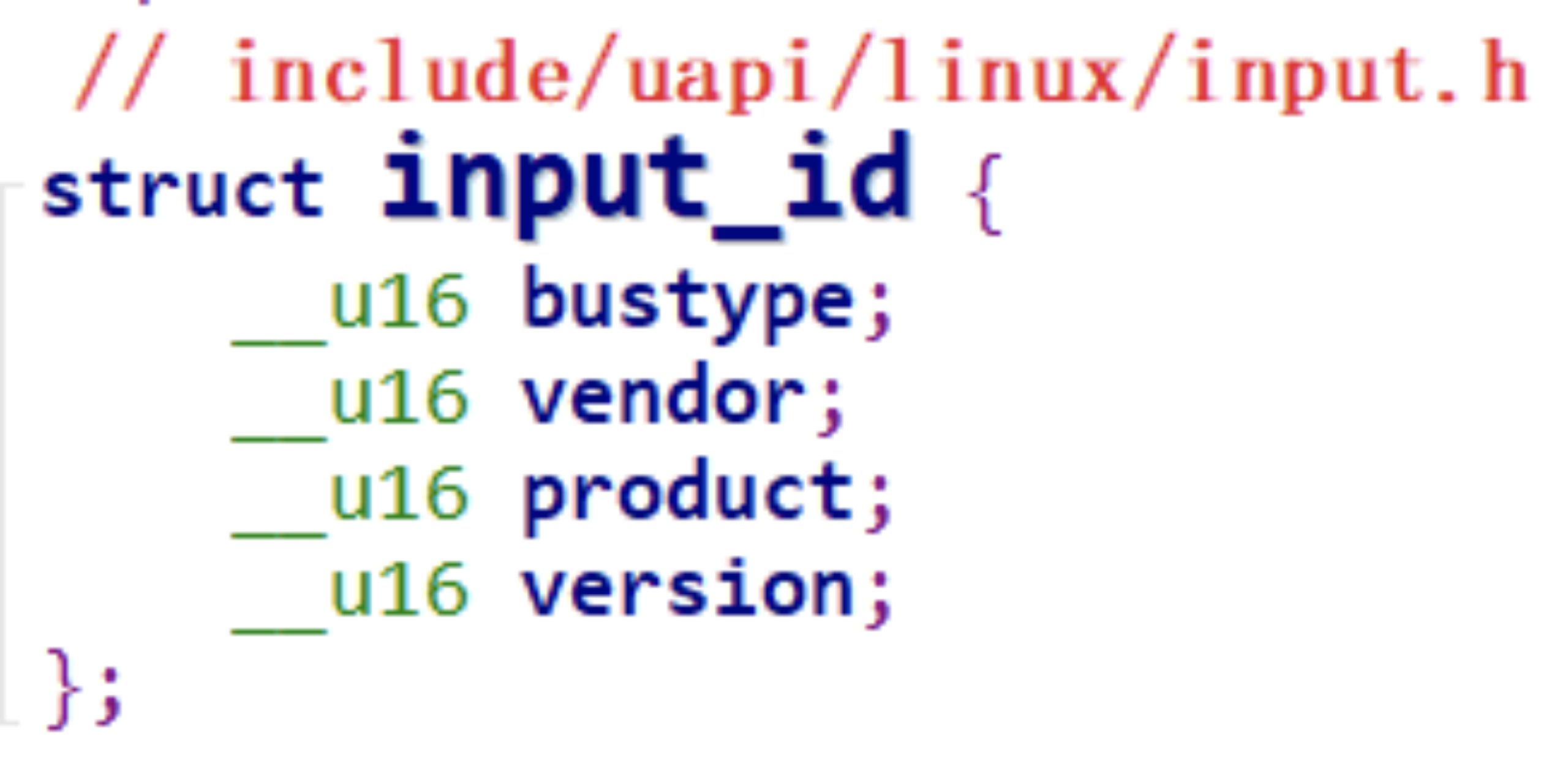
- N:name of the device 设备名称
- P:physical path to the device in the system hierarchy 系统层次结构中设备的物理路径
- S:sysfs path 位于 sys 文件系统的路径
- U:unique identification code for the device(if device has it) 设备的唯一标识码
- H:list of input handles associated with the device 与设备关联的输入句柄列表
B:bitmaps(位图)
PROP:device properties and quirks(设备属性) EV:types of events supported by the device(设备支持的事件类型) KEY:keys/buttons this device has(此设备具有的键/按钮) MSC:miscellaneous events supported by the device(设备支持的其他事件) LED:leds present on the device(设备上的指示灯)
值得注意的是 B 位图,比如上图中“B: EV=b”用来表示该设备支持哪类输入事件。b 的二进制是 1011,bit0、1、3 为 1,表示该设备支持 0、1、3 这三类事件,即 EV_SYN、EV_KEY、EV_ABS。
再举一个例子,“B: ABS=2658000 3”如何理解?
它表示该设备支持 EV_ABS 这一类事件中的哪一些事件。这是 2 个 32 位的数字:0x2658000、0x3,高位在前低位在后,组成一个 64 位的数字:“0x2658000,00000003”,数值为 1 的位有:0、1、47、48、50、53、54,即:0、1、0x2f、0x30、0x32、0x35、0x36,对应以下这些宏:

即这款输入设备支持上述的 ABS_X、ABS_Y、ABS_MT_SLOT、ABS_MT_TOUCH_MAJOR、ABS_MT_WIDTH_MAJOR、ABS_MT_POSITION_X、ABS_MT_POSITION_Y 这些绝对位置事件
使用命令读取数据
调试输入系统时,直接执行类似下面的命令,然后操作对应的输入设备即可读出数据:
1 | hexdump /dev/input/event0 |
在开发板上执行上述命令之后,点击按键或是点击触摸屏,就会打印以下信息:
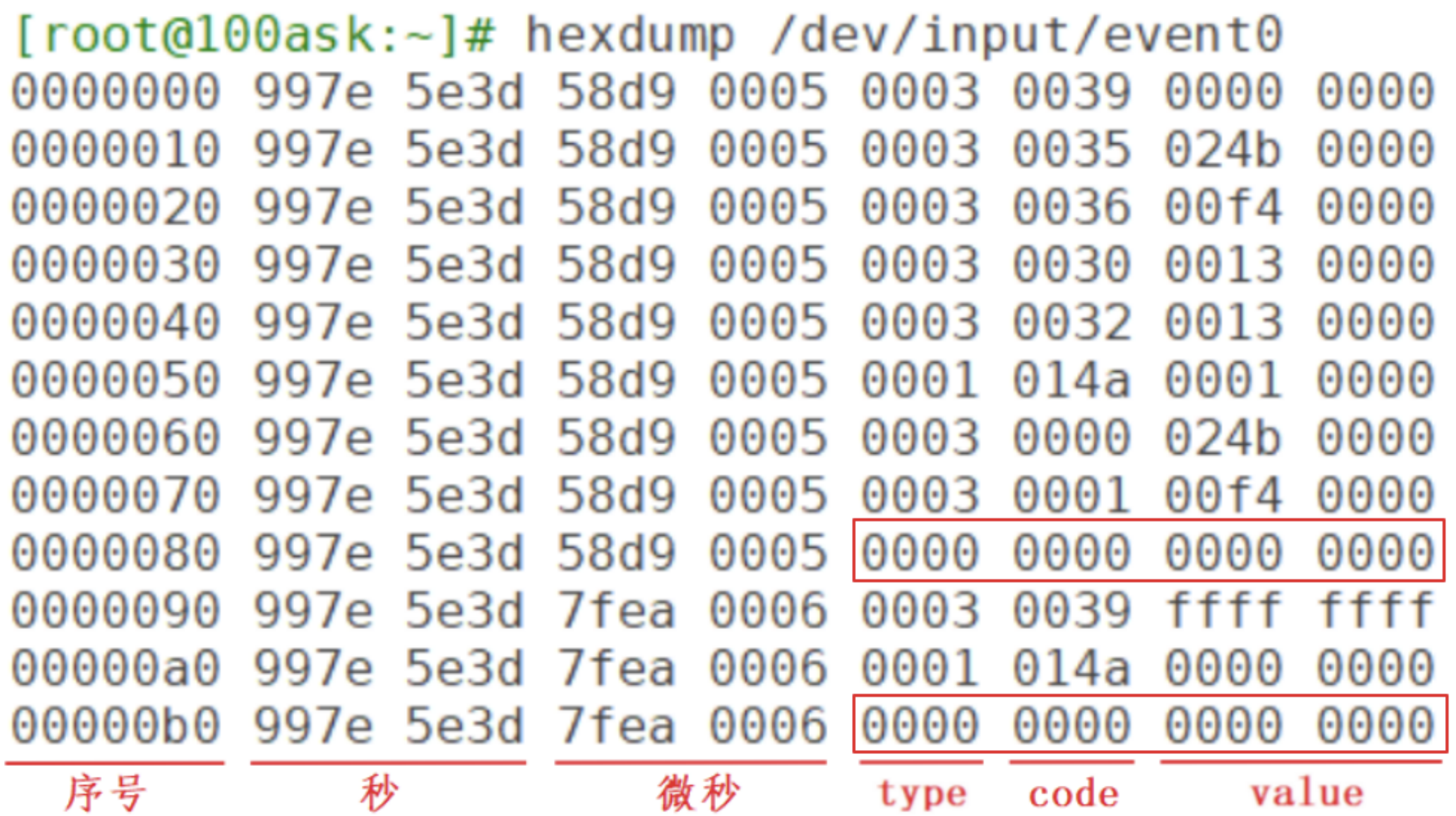
上图中的 type 为 3,对应 EV_ABS;code 为 0x35 对应 ABS_MT_POSITION_X;code 为 0x36 对应 ABS_MT_POSITION_Y。上图中还发现有 2 个同步事件:它的 type、code、value 都为 0。表示电容屏上报了 2 次完整的数据。
不使用库的应用程序示例
输入系统支持完整的 API 操作
支持这些机制:阻塞、非阻塞、POLL/SELECT、异步通知。
APP 访问硬件的 4 种方式:妈妈怎么知道孩子醒了
查询方式
APP 调用 open 函数时,传入“O_NONBLOCK”表示“非阻塞”。APP 调用 read 函数读取数据时,如果驱动程序中有数据,那么 APP 的 read 函数会返回数据,否则也会立刻返回错误。
休眠-唤醒方式
APP 调用 open 函数时,不要传入“O_NONBLOCK”。APP 调用 read 函数读取数据时,如果驱动程序中有数据,那么 APP 的 read 函数会返回数据;否则 APP 就会在内核态休眠,当有数据时驱动程序会把 APP 唤醒,read 函数恢复执行并返回数据给 APP。
POLL/SELECT 方式
POLL 机制、SELECT 机制是完全一样的,只是 APP 接口函数不一样。简单地说,它们就是“定个闹钟”:在调用 poll、select 函数时可以传入“超时时间”。在这段时间内,条件合适时(比如有数据可读、有空间可写)就会立刻返回,否则等到“超时时间”结束时返回错误。
用法如下。
APP 先调用 open 函数时。
APP 不是直接调用 read 函数,而是先调用 poll 或 select 函数,这 2 个函数中可以传入“超时时间”。它们的作用是:如果 驱动程序中有数据,则立刻返回;否则就休眠。在休眠期间,如果有人操作了硬件,驱动程序获得数据后就会把 APP 唤 醒,导致 poll 或 select 立刻返回;如果在“超时时间”内无人操作硬件,则时间到后 poll 或 select 函数也会返回。APP 可 以根据函数的返回值判断返回原因:有数据?无数据超时返回?
APP 根据 poll 或 select 的返回值判断有数据之后,就调用 read 函数读取数据时,这时就会立刻获得数据。
poll/select 函数可以监测多个文件,可以监测多种事件:在调用 poll 函数时,要指明:
你要监测哪一个文件:哪一个 fd
你想监测这个文件的哪种事件:是 POLLIN、还是 POLLOUT
最后,在 poll 函数返回时,要判断状态。
异步通知方式
所谓异步通知,就是 APP 可以忙自己的事,当驱动程序用数据时它会主动给 APP 发信号,这会导致 APP 执行信号处理函数。
tslib
tslib 框架分析
tslib 的主要代码如下:

核心在于“plugins”目录里的“插件”,或称为“module”。这个目录下的每个文件都是一个 module,每个 module 都提供 2 个函数:read、read_mt,前者用于读取单点触摸屏的数据,后者用于读取多点触摸屏的数据
要分析 tslib 的框架,先看看示例程序怎么使用,我们参考 ts_test.c 和 ts_test_mt.c,前者用于一般触摸屏(比如电阻屏、单点电容屏),后者用于多点触摸屏。
一个图就可以弄清楚 tslib 的框架:
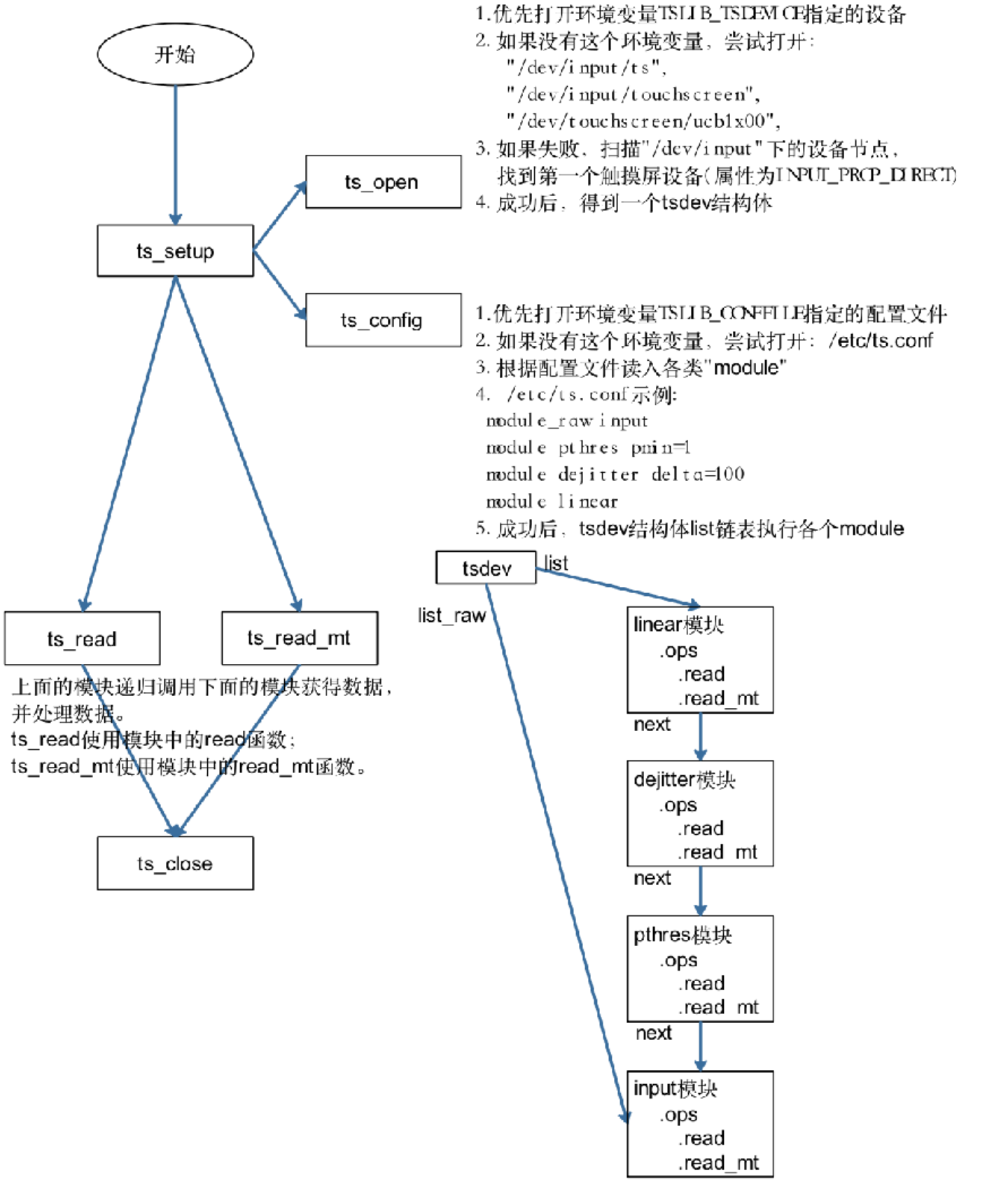
参考文献
《韦东山老师课程》





