
C++11(三)auto、decltype 与 for
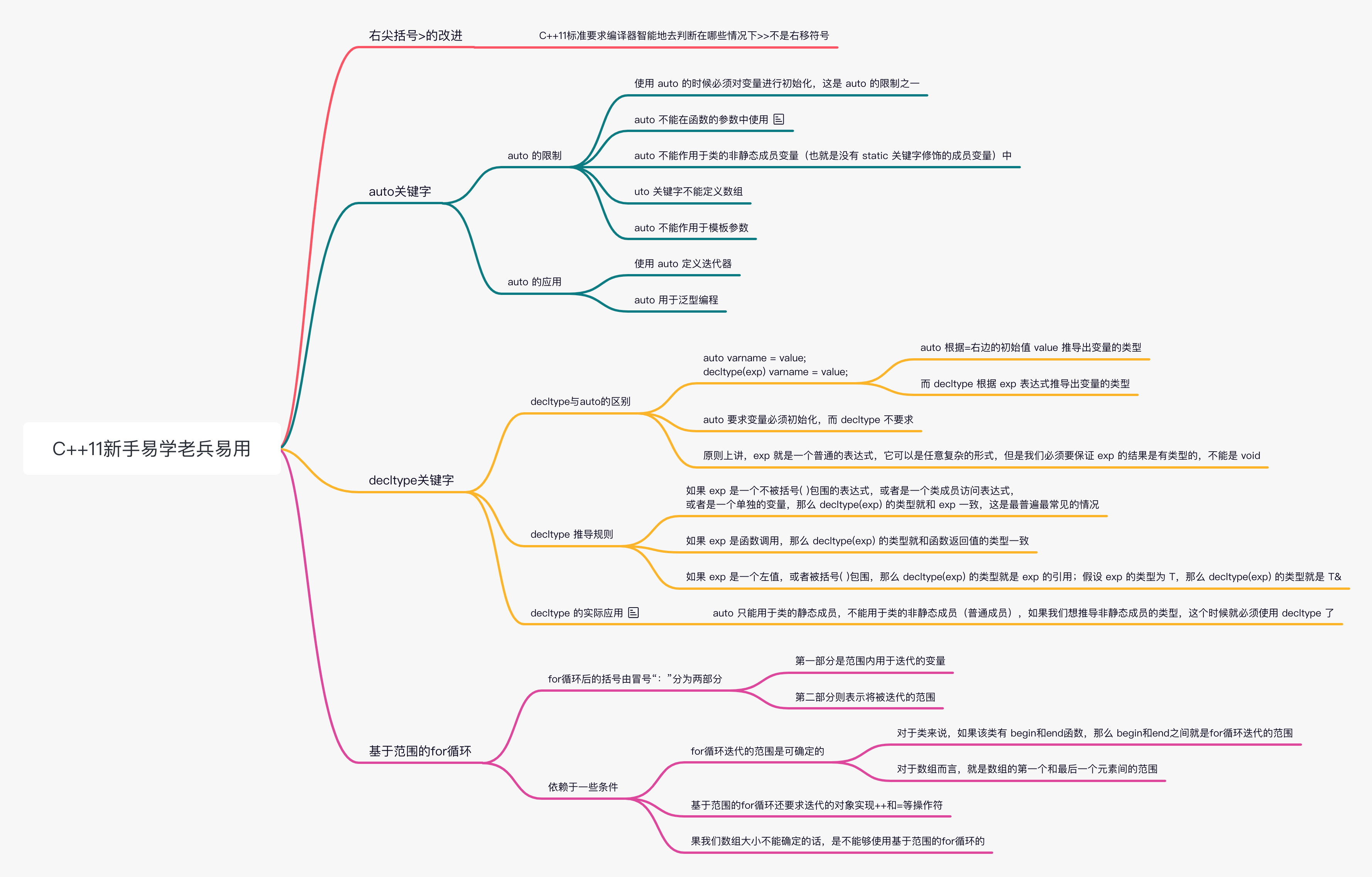
右尖括号>的改进
在 C++98 中,有一条需要程序员规避的规则:如果在实例化模板的时候出现了连续的两个右尖括号>,那么它们之间需要一个空格来进行分隔,以避免发生编译时的错误。
1 | template <int i> class X{}; |
在 x2 的定义中,编译器会把>>优先解析为右移符号。
C++98 同样会将>>优先解析为右移。C++11 中,这种限制被取消了。事实上,C++11 标准要求编译器智能地去判断在哪些情况下>>不是右移符号。使用 C++11 标准,上述所示代码则会成功地通过编译。
auto 关键字
auto 的限制
使用 auto 的时候必须对变量进行初始化,这是 auto 的限制之一。那么,除此以外,auto 还有哪些其它的限制呢?
- auto 不能在函数的参数中使用 这个应该很容易理解,我们在定义函数的时候只是对参数进行了声明,指明了参数的类型,但并没有给它赋值,只有在实际调用函数的时候才会给参数赋值;而 auto 要求必须对变量进行初始化,所以这是矛盾的
- auto 不能作用于类的非静态成员变量(也就是没有 static 关键字修饰的成员变量)中
- auto 关键字不能定义数组
- auto 不能作用于模板参数
auto 的应用
- 使用 auto 定义迭代器
- auto 用于泛型编程
decltype 关键字
decltype 与 auto 的区别
既然已经有了 auto 关键字,为什么还需要 decltype 关键字呢?因为 auto 并不适用于所有的自动类型推导场景,在某些特殊情况下 auto 用起来非常不方便,甚至压根无法使用,所以 decltype 关键字也被引入到 C++11 中。
auto 和 decltype 关键字都可以自动推导出变量的类型,但它们的用法是有区别的:
1 | auto varname = value; |
其中,varname 表示变量名,value 表示赋给变量的值,exp 表示一个表达式。
auto 根据=右边的初始值 value 推导出变量的类型,而 decltype 根据 exp 表达式推导出变量的类型,跟=右边的 value 没有关系。
另外,auto 要求变量必须初始化,而 decltype 不要求。这很容易理解,auto 是根据变量的初始值来推导出变量类型的,如果不初始化,变量的类型也就无法推导了。decltype 可以写成下面的形式: decltype(exp) varname;
原则上讲,exp 就是一个普通的表达式,它可以是任意复杂的形式,但是我们必须要保证 exp 的结果是有类型的,不能是 void;例如,当 exp 调用一个返回值类型为 void 的函数时,exp 的结果也是 void 类型,此时就会导致编译错误。
decltype 推导规则
- 如果 exp 是一个不被括号 ( ) 包围的表达式,或者是一个类成员访问表达式,或者是一个单独的变量,那么 decltype(exp) 的类型就和 exp 一致,这是最普遍最常见的情况。
- 如果 exp 是函数调用,那么 decltype(exp) 的类型就和函数返回值的类型一致。
- 如果 exp 是一个左值,或者被括号 ( ) 包围,那么 decltype(exp) 的类型就是 exp 的引用;假设 exp 的类型为 T,那么 decltype(exp) 的类型就是 T&。
decltype 的实际应用
auto 的语法格式比 decltype 简单,所以在一般的类型推导中,使用 auto 比使用 decltype 更加方便,本节仅演示只能使用 decltype 的情形。
我们知道,auto 只能用于类的静态成员,不能用于类的非静态成员(普通成员),如果我们想推导非静态成员的类型,这个时候就必须使用 decltype 了。下面是一个模板的定义:
1 |
|
单独看 Base 类中 m_it 成员的定义,很难看出会有什么错误,但在使用 Base 类的时候,如果传入一个 const 类型的容器,编译器马上就会弹出一大堆错误信息。原因就在于,T::iterator 并不能包括所有的迭代器类型,当 T 是一个 const 容器时,应当使用 const_iterator。
要想解决这个问题,在之前的 C++98/03 版本下只能想办法把 const 类型的容器用模板特化单独处理,增加了不少工作量,看起来也非常晦涩。但是有了 C++11 的 decltype 关键字,就可以直接这样写:
1 | template <typename T> |
基于范围的 for 循环
1 |
|
在上述代码中,我们使用了指针 p 来遍历数组 arr 中的内容,两个循环分别完成了每个元素自乘以 2 和打印工作。而 C++的标准模板库中,我们还可以找到形如 for_each 的模板函数。如果我们使用 for_each 来完成上述代码中的工作,代码看起来会是这个样子。
1 |
|
for_each 使用了迭代器的概念,其迭代器就是指针,迭代器内含了自增操作。
我们可以看一下基于范围的 for 循环改写的例子:
1 |
|
上述代码就是一个基于范围的 for 循环的实例。for 循环后的括号由冒号“:”分为两部分,第一部分是范围内用于迭代的变量,第二部分则表示将被迭代的范围。这样一来,遍历数组和 STL 容器就非常容易了。
值得指出的是,是否能够使用基于范围的 for 循环,必须依赖于一些条件。首先,就是 for 循环迭代的范围是可确定的。对于类来说,如果该类有 begin 和 end 函数,那么 begin 和 end 之间就是 for 循环迭代的范围。对于数组而言,就是数组的第一个和最后一个元素间的范围。其次,基于范围的 for 循环还要求迭代的对象实现++和=等操作符。对于标准库中的容器,如 string、aray、 vector、 deque、it、 queue、map、set 等,不会有问题,因为标准库总是保证其容器定义了相关的操作。普通的已知长度的数组也不会有问题。而用户自己写的类,则需要自行提供相关操作。相反,如果我们数组大小不能确定的话,是不能够使用基于范围的 for 循环的。
参考文献
http://c.biancheng.net/view/6984.html
http://c.biancheng.net/view/7151.html
《深入理解 C++11:C++11 新特性解析与应用》





