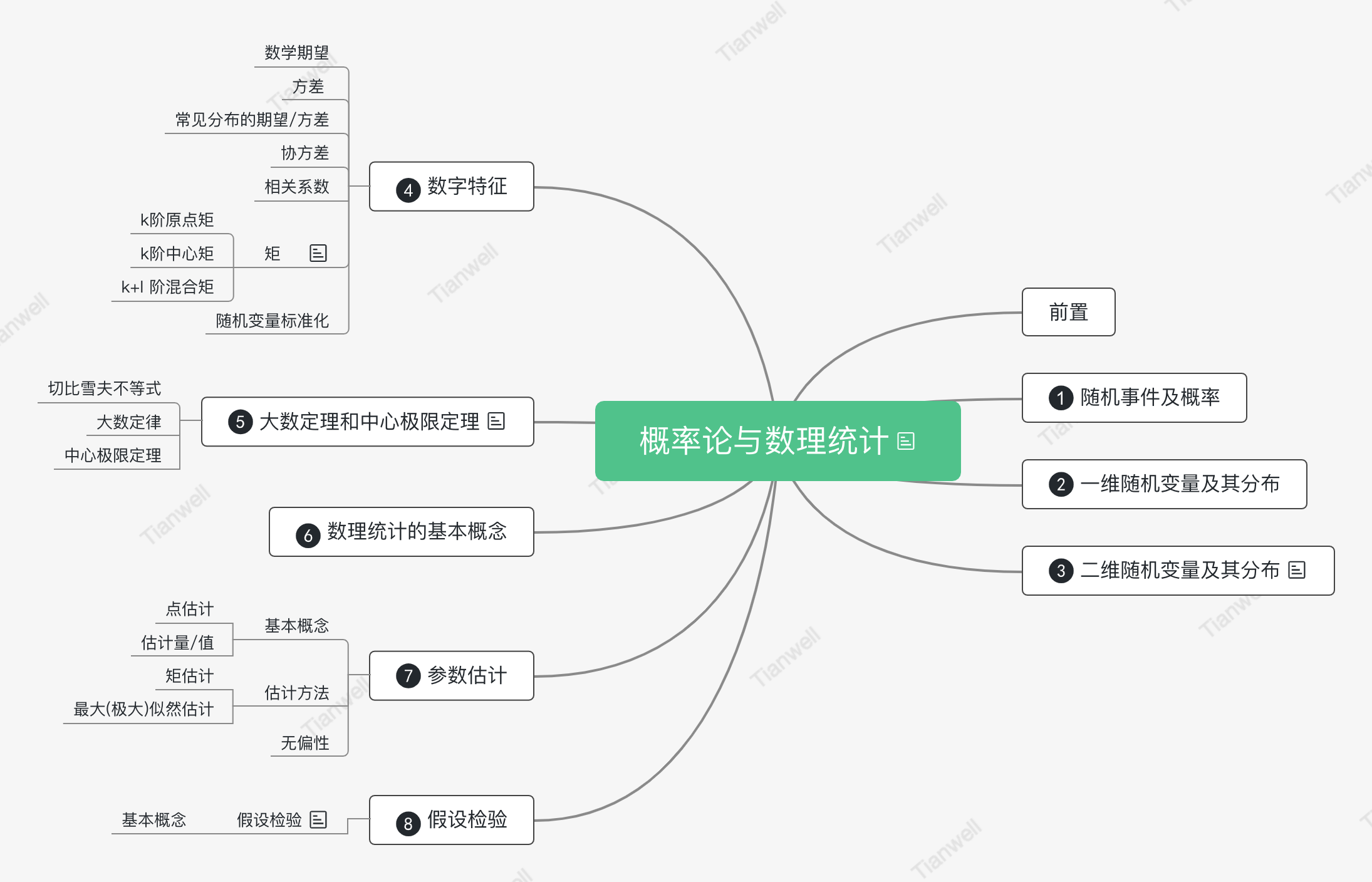
概率论与数理统计
概率论基本概念
概率的派别
对于概率的定义有几个主流的派别:
频率派: 频率派认为如果频率存在稳定性,即当
古典派: 如果因为无知,使得我们没有办法判断哪一个结果会比另外一个结果更容易出现,那么应该给予它们相同的概率,此称为不充分理由原则(Insufficient Reason Principle)。以不充分理由原则为基础,经由拉普拉斯:之手,确立了古典概率的定义,即: 未知的概率都为等概率
主观派: 最后介绍下主观派,主观派认为概率是信念强度(degree of belief)。比如说,我个人相信 20 年后人类从网络时代进入人工智能时代的概率为 70%.
三个流派大概有以下的区别:
概率公理化
已知某样本空间
非负性公理:
规范性公理:
可加性公理: 设
则
事件之间的运算和关系
并运算: 对于事件
交运算: 对于事件
差运算: 对于事件
补运算: 对于事件 A、B,如果:
基本运算的性质:
德摩根定律:
小结:
事件之间的关系:
条件概率
设 A 和 B 是样本空间
为“假设条件为 B 时的 A 的概率”,简称条件概率。也常写作:
乘法公式
若
若
若
63 4、 贝叶斯与全概率 对于同一样本空间
设
若
有了全概率公式后,可以得到贝叶斯定理真正的样子: 设
也就是把
独立事件
对于两个随机事件
则称 A 与 B 相互独立,或简称 A 与 B 独立,否则称 A 与 B 不独立或相依。
设
则称
若从中任取有限个
则称
随机变量及其分布
随机变量
定义在样本空间
称为随机变量。随机变量是一个函数,所以都用大写字母来表示,以示和自变量 x 的区别。
二项分布
概率质量函数
如果
非负性:
规范性:
则称其为概率质量函数(PMF)。
伯努利分布
某样本空间只包含两个元素,
若
或写作:
则此概率分布称作 0-1 分布,也称作伯努利分布。
在数学中,类似于扔一次硬币这样的“是非题”称为一次伯努利试验,像上面这样独立地重复扔 n 次硬币(做同样的“是非题”n 次),就称为 n 重伯努利试验。
二项分布
对于 n 重伯努利实验,如果每次得到“是”的概率为 p,设随机变量:
则称:
为随机变量 X 的二项分布,也可以记作:
当 n=1 的时候,对应的就是伯努利分布,所以伯努利分布也可以记作
离散的累积分布函数
设
因为是把概率质量函数累加起来,所以称为累积分布函数(Cumulative Distribution Function,或者缩写为 CDF),也简称为分布函数。
离散的数学期望 设离散随机变量
如果:
为随机变量 X 的数学期望(expected
value,或,expectation),简称期望或均值(mean),也有很多文档会用
若级数
学期望也称作矩。更准确点说,由于数学期望:
数学期望的性质
复合: 假设
常数: 若 c 为常数,则:
线性组合: 数学期望满足:
- 齐次性,对于任意常数
- 可加性,对于随机变量的函数
- 齐次性,对于任意常数
伯努利分布和二项分布的期望分别如下:
方差与标准差
方差
代数式:
方差的性质
化简: 可以通过下式来化简运算:
常数: 若 c 为常数,则:
相加与数乘: 若 a、b 为常数,则:
标准差
假如随机变量
二项分布的方差
马尔可夫不等式
设
切比雪夫不等式
设
泊松分布
对于随机变量
其数学期望和方差为:
条件
更一般地,在某一段时间 T
内发生特定事件的次数,如果满足以下假设,都可以看作泊松分布:
- 平稳性:在此时间段 T 内,此事件发生的概率相同(在实际应用中大致相同就可以了)。
- 独立性:事件的发生彼此之间独立(或者说,关联性很弱)。
- 普通性:把 T 切分成足够小的区间、Delta T,在、Delta T 内恰好发生两个、或多个事件的可能性为 0(或者说,几乎为 0)。
泊松分布是二项分布的极限:
所以在泊松分布的
重要的离散分部
几何分布
对于 n 重伯努利实验,如果每次得到“是”的概率为 p,设随机变量:
则称:
为随机变量 X 的几何分布,也可以记作:
其数学期望和方差为:
负二项分布
对于 n 重伯努利实验,如果每次得到“是”的概率为 p,设随机变量:
则称:
为随机变量 X 的负二项分布,也称为帕斯卡分布,也可以记作:
其数学期望为:
负二项分布与几何分布
几何是负二项的特例 : 负二项分布是这样的:
负二项是几何的和: 参数为 r、p 的负二项分布可以表示为如下事件序列:
 图中所示的每一段
图中所示的每一段
超几何分布
设有 N 件产品,其中有 M 件不合格品,随机抽取 n 件产品,则其中含有 m
件不合格产品的概率为多少? 假设随机变量:
然后有 m 件从不合格品中抽取,剩下的在合格品中抽取,则有:
所求概率即为:
其中
其数学期望和方差为:
超几何分布与二项分布
超几何分布与二项分布类似,都是求抽取 n 次其中有 m 次“是”的概率,只是:
- 二项分布:相当于抽取之后放回。
- 超几何分布:抽取之后不放回。
所以在超几何分布中,如果被抽取的总数 N
特别大,那么放回不放回区别也就不大了,此时,那么超几何分布可以近似看作二项分布。
这点从两者的期望、方差也可以看出来:
对超几何分布而言,当 N 足够大的时候,
总结
概率密度函数
概率密度函数
如果函数
非负性:
规范性(暗含了可加性),因为是连续的,所以通过积分相加:
则称其为概率密度函数(Probability Density Function,简写为 PDF)。
期望
离散随机变量的期望定义为:
可以用类似的方法定义连续随机变量的期望,当然期望的意义是没有改变的:
复合: 假设
常数: 若 c 为常数,则:
线性: 数学期望满足:
- 齐次性,对于任意常数 a 有:
- 可加性,对于任意两个函数
- 齐次性,对于任意常数 a 有:
方差
方差的定义依然是:
相关的性质也是成立的:
化简: 可以通过下式来化简运算:
常数: 若 c 为常数,则:
相加与数乘: 若 a、b 为常数,则:
累积分布函数
连续随机变量
正态分布
正态分布
如果连续随机变量
则称
我们称
期望与方差
正态分布
指数分布
若随机变量
其中
累积分布函数为:
指数分布
总结
首先是一维离散随机变量的概率分布:
然后是一维连续随机变量的概率分布:
多维随机变量及其分布
多维随机变量及其分布
联合概率质量函数
如果二维随机向量
且此函数满足如下性质(即概率的三大公理):
非负性:
规范性和可加性:
则称此函数为
联合概率密度函数
对于某二维随机变量
非负性:
规范性和可加性(连续的都通过积分来相加):
则称此函数为
联合累积分布函数
设
称为二维随机变量
得到
多维均匀分布
设
边缘分布与随机变量的独立性
边缘概率质量函数
如果二维离散随机变量
对
称为
称为
边缘概率密度函数
如果二维连续随机变量
称为
称为 Y 的边缘概率密度函数。
边缘累积分布函数
如果二维连续随机变量
称为
同理可以得到 Y 的边缘累积分布函数:
条件分布
离散的条件分布
设
为
为
条件分布和条件概率没有什么区别,一样可以用于全概率公式、贝叶斯公式。
连续的条件分布
设二维连续型随机变量
同样的道理,以
连续的全概率和贝叶斯
全概率:
贝叶斯:
多维随机变量函数的分布
随机变量的和
离散: 设 X、Y 为两个相互独立的离散随机变量,取值范围为
连续: 设
随机变量的数字特征
数学期望
数学期望的定义
离散随机变量的数学期望定义为:
连续随机变量的数学期望定义为:
函数的数学期望
一维随机变量: 设
- 若
- 若
- 若
多维随机变量: 设
- 若
- 若
- 若
线性的数学期望
数学期望满足:
齐次性,对于任意常数 a 有:
可加性,对于任意两个函数
对于多维也成立:
施瓦茨不等式
对任意随机变量
独立的数学期望
设
方差与标准差
方差与标准差的定义
方差定义为(因为直接通过数学期望定义的,所以没有区分离散和连续):
为了写的简单一点,也常常令
之前也介绍过,由于方差里面含有平方,在实际应用中需要开平方才能保持单位一致,这就是标准差:
线性的方差
若
独立的方差
设
这个结论可以推广到 n 维独立随机变量:
协方差
协方差的定义
设
特别地有
很显然会有:
协方差的性质
化简: 可以通过下式来化简运算:
方差: 对于任意的二维随机变量
分配律:
数乘:
独立与不相关
独立必不相关: 根据刚才的性质:
不相关不能推出独立: 不相关只能说明 X、Y 之间没有正相关规律,也没有负相关规律,但可能还有很多别的规律,所以:
相关系数
对于二维随机变量
对于任意的二维随机变量
有界性让比较有了一个范围,我们可以得到如下结论:
二维正态分布
如果二维随机变量
则称
它含有五个参数
大数定律及中心极限定理
大数定律
伯努利大数定律
整个概率论的得以存在的基础是,其所研究的随机现象虽然结果不确定,但又有规律可循。这个基础在概率论中被称为大数定律(Law of large numbers)。大数定律是一系列的定律,先来介绍伯努利大数定律:
设
或:
这里需要注意不能直接用:
依概率收敛
因为
这个极限同样表达了“随着
辛钦大数定律
伯努利大数定律局限于伯努利分布,下面介绍辛钦大数定律就没有这个限制,只是要求遵循相同的分布:
设有随机变量:
切比雪夫大数定律
相同的分布也算比较严格的限制,下面介绍切比雪夫大数定律对于分布就更加宽松,只要各自的方差有共同上界即可:
设有随机变量:
总结
这里总共介绍了三个大数定律,主要区别如下:
强大数定律
前面介绍的大数定律又称为弱大数定律(Weak Law of large
numbers),有弱就自然就有强,下面就来介绍强大数定律(Strong Law of large
numbers): 设有随机变量:
这个强大数定律和之前的辛钦大数定律非常接近:
弱大数定律(辛钦大数定律),极限符号在 P 函数外面:
强大数定律,极限符号在 P 函数里面:
中心极限定理
棣莫弗-拉普拉斯定理
设随机变量
林德伯格-莱维定理
设随机变量:
参考文献
《马同学的概率论与数理统计》
感兴趣的可以购买他的课程,写的很好(强烈推荐)!!!
预览: