Linux 内存管理(二)ARM64 的虚拟地址转换在 linux 中的实现
 原图
原图
arm64 内存管理
如图所示,ARM 处理器内核的 MMU 包括 TLB 和页表遍历单元(Table Walk Unit)两个部件。TLB 是一个高速缓存。一个完整的页表翻译和查找的过程叫作页表查询,页表查询的过程由硬件自动完成,但是页表的维护需要软件来完成。 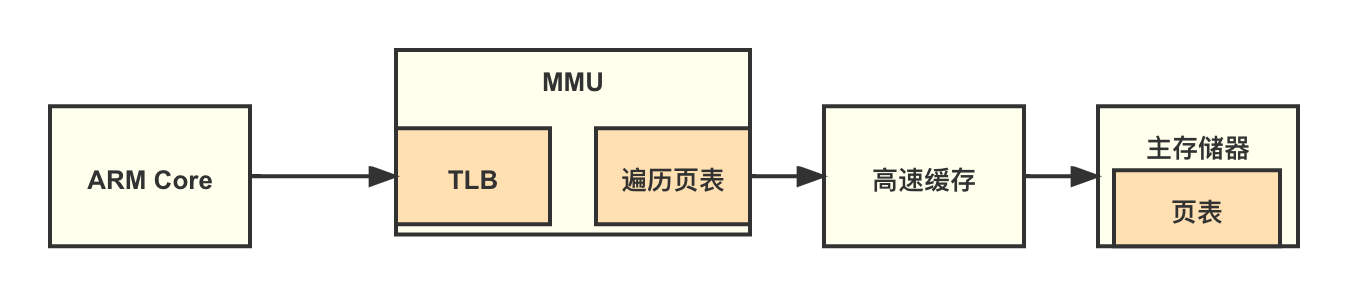
下图为进程地址空间和物理地址空间的映射关系,左边是进程地址空间视图,右边是物理地址空间视图。进程地址空间又分成内核空间(Kermel Space)和用户空间(User Space)。无论是内核空间还是用户空间都可以通过处理器提供的页表机制映射到实际的物理地址。 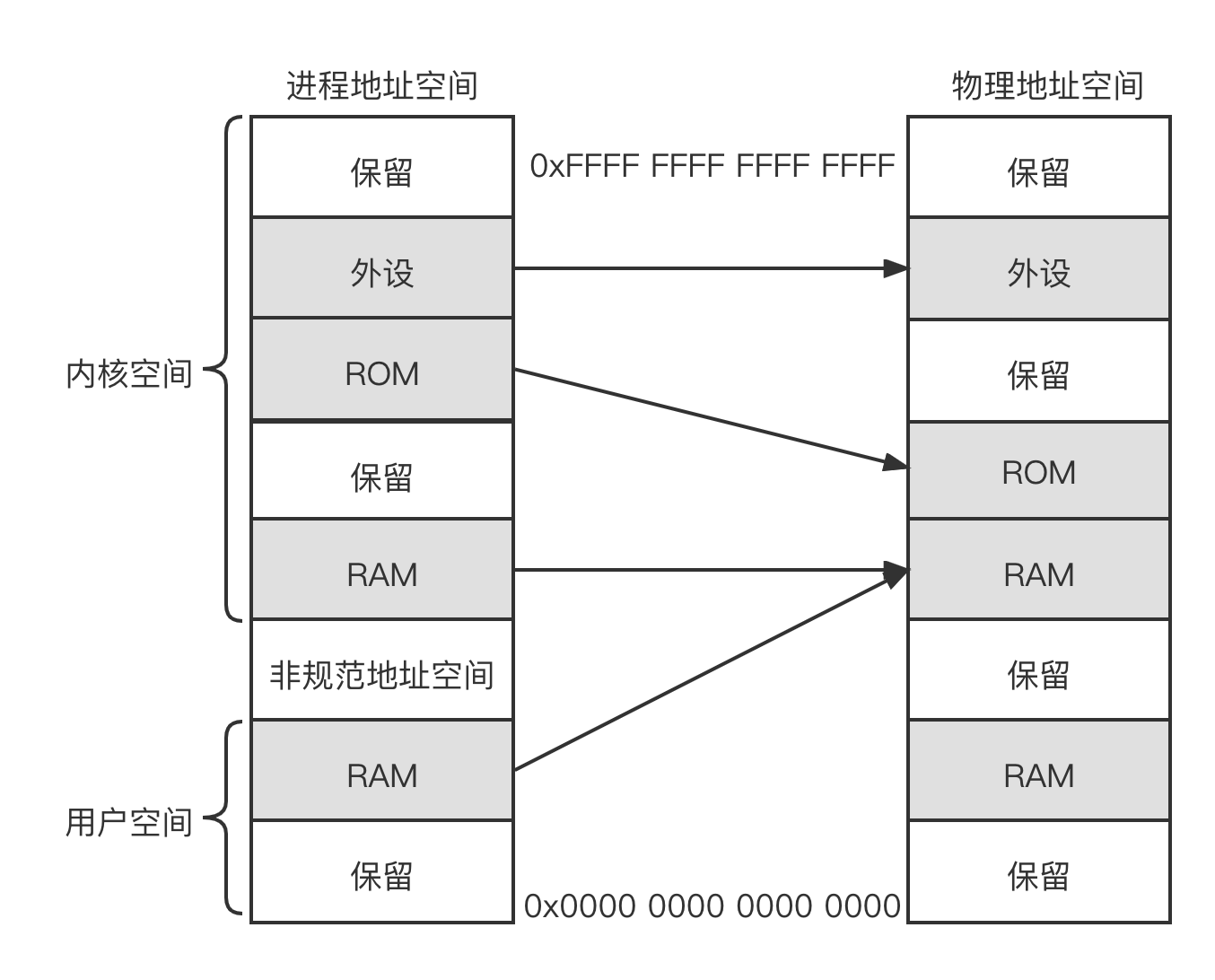
页表
在 AArch64 架构中的 MMU 支持单一阶段的页表转换,同样也支持虚拟化扩展中两阶段的页表转换。
- 单一阶段的页表转换,把虑虚拟地址(VA)翻译成物理地址(PA)。
- 两阶段的页表转换:包括两个阶段。在阶段 1,把虚拟地址翻译成中间物 (Intermediate Phvsical Address,IPA);在阶段 2,把 IPA 翻译成最终 PA 另外,ARMv8 架构支持多种页表格式。具体如下。
- ARMv8 架构的长描述符页表格式(Long Descriptor Translation Table Format)
- ARMv7 架构的长描述符页表格式,需要打开大物理地址扩展(Large PhysicalA Extention, LPAE)
- ARMv7 加构的短描述符页表格式(Short Descriptor Translation Table Format)
ARMv8 架构还支持 4KB、16KB 或 64KB 这 3 种页面粒度。
页表映射
在 AArch64 架构中,因为地址总线位宽最多支持 48 位,所以 VA 被划分为两个空间,每个空间最多支持 256TB。
- 低位的虚拟地址空间位于 0x0000 0000 0000 0000 到 0x0000 FFFF FFFF FFFF。虚拟地址的最高位等于 0,就使用这个虚拟地址空间,并且使用 TTBRO_ELx 来存放的基地址。
- 高位的虚拟地址空间位于 0xFFFF 0000 0000 0000 到 0xFFFF FFFF FFFF FFFF。虚拟地址的最高位等于 1,就使用这个虚拟地址空间,并且使用 TTBR1_ELx 来存放的基地址。
AArch64 架构中的页表支持如下特性。
- 最多可以支持 4 级页表
- 输入地址的最大有效位宽为 48 位
- 输出地址的最大有效位宽为 48 位
- 翻译的页面粒度可以是 4KB、16KB 或 64KB
注意,本文以 4KB 大小的页面和 48 位地址宽度为例来说明 AArch64 架构页表映射。如下图所示为 AArch64 架构的地址映射,其中页面是 4KB 的小页面。当 TLB 未命中时,处理器查询页表的过程如下。 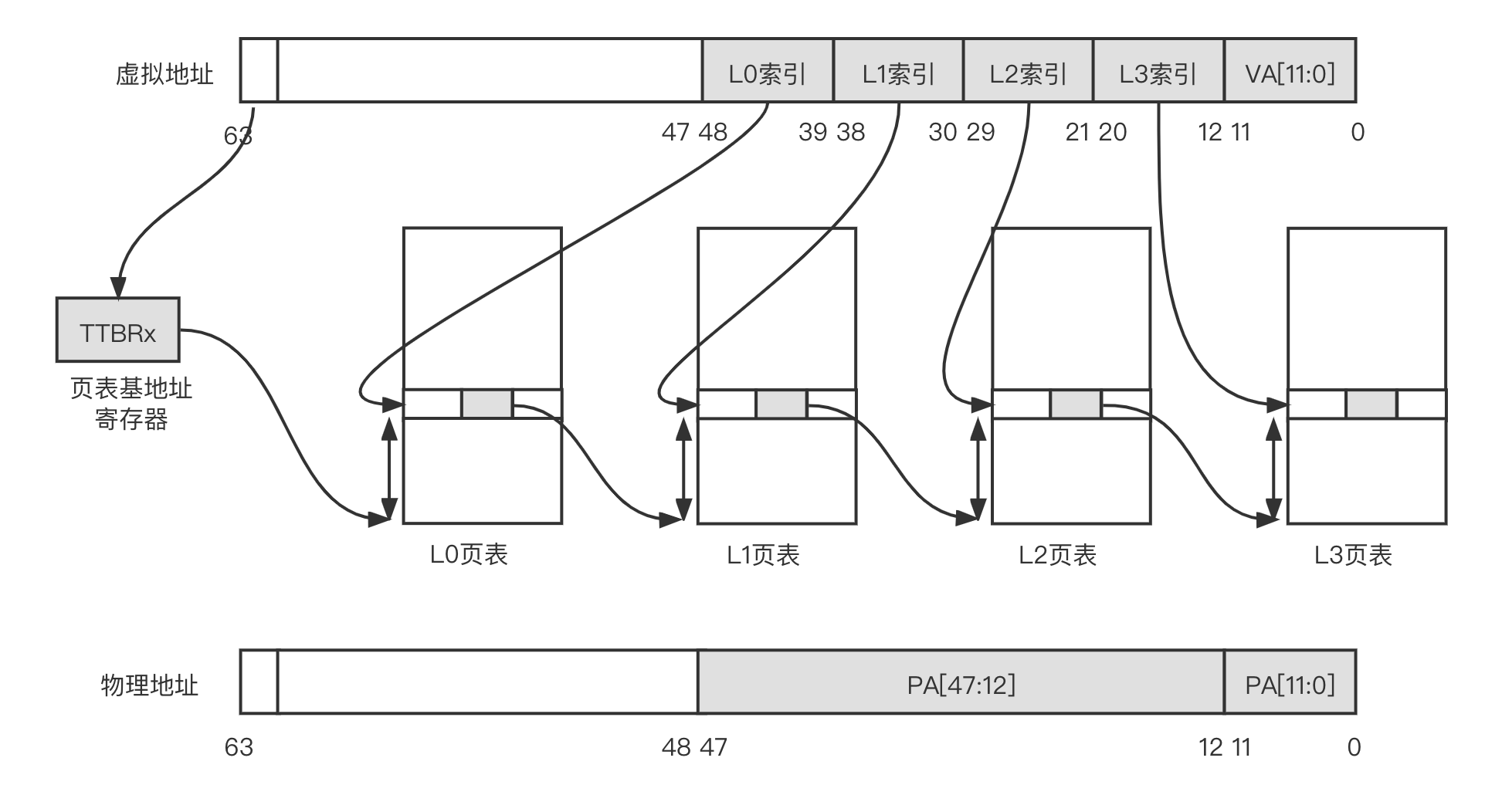
- 处理器根据页表基地址控制寄存器和虚拟地址来判断使用哪个页表基地址寄存器 TTBRO 还是 TTBR1。当虚拟地址第 63 位简称 VA[63] 为 1 时选择 TTBR1;当 VA[63] 为 0 时选择 TTBR0。页表基地址寄存器中存放着 1 级页表
- 处理器将 VA[47:39] 作为 L0 索引,在 1 级页表(L0 页表)中找到页表项,1 级页表有 512 个页表项
- 1 级页表的页表项中存放着 2 级页表(L1 页表)的物理基地址。处理器将 VA[38] 作为 L1 索引,在 2 级页表中找到相应的页表项,2 级页表有 512 个页表项
- 2 级页表的页表项中存放着 3 级页表(L2 页表)的物理基地址。处理器以 VA[29:21] 作为 L2 索引,在 3 级页表(L2 页表)中找到相应的页表项,3 级页表有 512 个页表项
- 3 级页表的页表项中存放着 4 级页表(L3 页表)的物理基地址。处理器以 VA[20:12] 作为 L3 索引,在 4 级页表(L3 页表)中找到相应的页表项,4 级页表有 512 个页表项
- 4 级页表的页表项里存放着 4KB 页面的物理基地址,然后加上 VA[11:0],就构成了新的物理地址,因此处理器就完成了页表的查询和翻译工作
页表项描述符
从下图可知,AArch64 架构页表分成 4 级页表,每一级页表都有页表项,我们把它们称为页表项描述符,每个页表项描述符占 8 字节,那么这些页表项描述符的格式和内容是否都一样?
L0~L2 页表项描述符
AArch64 架构中 L0 ~ L3 页表项描述符的格式不完全一样,其中 L0 ~ L2 页表项的内容比较类似,如下图所示。 
L0~L2 页表项根据内容可以分成 3 类,一是无效的页表项,二是块(block)类型的页表项,三是页表(table)类型的页表项。
- 当页表项描述符 Bit[0] 为 1 时,表示有效的描述符;当 Bit[0] 为 0 时,表示无效描述符
- 页表项描述符 Bit[1] 用来表示类型
- 页表类型:当 Bit[1] 为 1 时,表示该描述符包含了指向下一级页表的基地址,是一个页表类型的页表项
- 块类型,当 Bit[1] 为 0 时表示一个大内存块(memory block)的页表项,其中包含了最终的物理地址。大内存块通常是用来描述大的连续的物理内存,如 2MBit 或者 1GB 大小的连续物理内存
- 在块类型的页表项中,Bit[47:n] 表示最终输出的物理地址
- 若页面粒度是 4KB,在 L1 页表项描述符中 n 为 30,表示 1GB 大小的连续物存。在 L2 页表项描述符中 n 为 21,用来表示 2MB 大小的连续物理内存
- 若页面粒度为 16KB,在 L2 页表项描述符中 n 为 25,用来表示 32MB 大小的连续物理内存
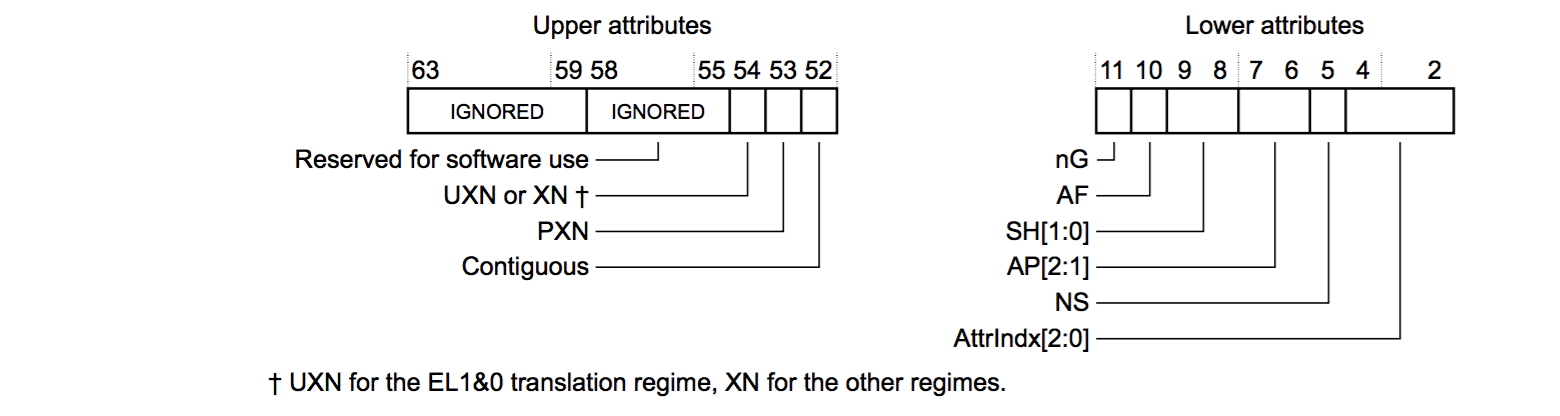
- 在块类型的页表项中,Bit[11:2] 是低位属性(lower attribute),Bit[63:52] 是高位属性 (upper attribute)
- 在页表类型的页表项描述符中,Bit[47:m] 用来指向下一级页表的基地址
- 当页面粒度为 4KB 时 m 为 12
- 当页面粒度为 16KB 时 m 为 14
- 当页面粒度为 64KB 时 m 为 16
L3 页表项描述符
如下图所示,L3 页表项描述符包含 5 种页表项,分别是无效的页表项、保留的页表项 4KB 粒度的页表项、16KB 粒度的页表项、64KB 粒度的页表项。 
L3 页表项描述符的格式如下。
- 当页表项描述符 Bit[0] 为 1 时,表示有效的描述符;当 Bit[0] 为 0 时,表示无效描述符
- 当页表项描述符 Bit[1] 为 0 时,表示保留页表项;当 Bit[1] 为 1 时,表示页表类型的页表项
- 页表描述符 Bit[11:2] 是低位属性,Bit[63:51] 是高位属性
- 页表描述符中间的位域中包含了输出地址(output address),也就是最终物理页面的高地址段
- 当页面粒度为 4KB 时输出地址为 Bit[47:12]
- 当页面粒度为 16KB 时输出地址为 Bit[47:14]
- 当页面粒度为 64KB 时输出地址为 Bit[47:16]
Linux 内核中的页表
在 ARM64 的 Linux 内核中采用以下 4 级分页模型:
- 页全局目录(Page Global Directory,PGD)
- 页上级目录(Page Upper Directory,PUD)
- 页中间目录(Page Middle Directory,PMD)
- 页表(Page Table,PT)
上述 4 级分页模型分别对应 ARMv8 架构页表的 L0~L3 页表。上述 4 级分页模型在 64 位虚拟地址的划分如下图所示。 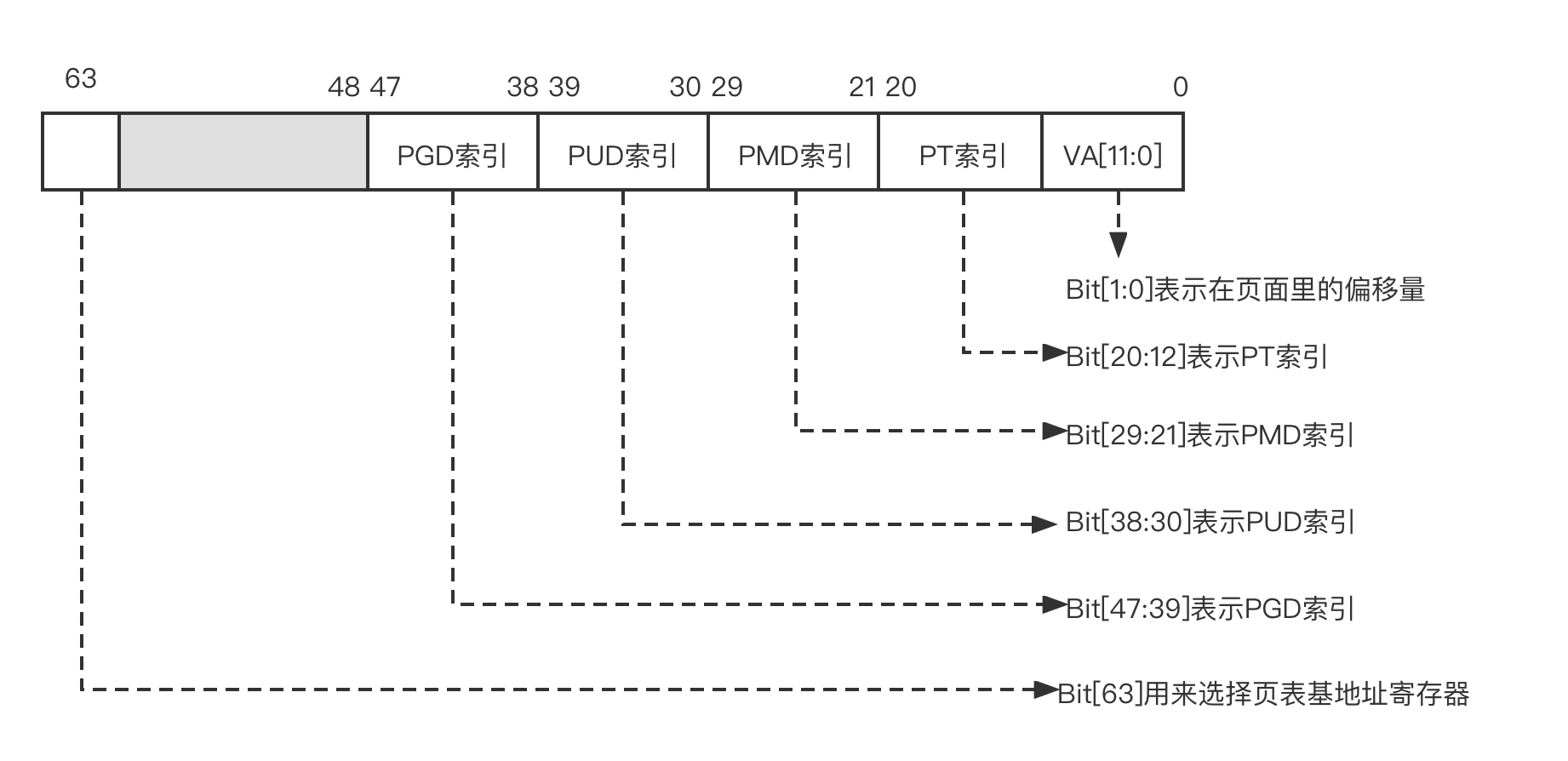
64 位的虚拟地址分成如下几个部分。
- Bit[63]:用来选择页表基地址寄存器
- Bit[62:48]:保留
- Bit[47:39]:表示 PGD 索引,即 ARM64 中的 L0 索引
- Bit[38:30]:表示 PUD 索引,即 ARM64 中的 L1 索引
- Bit[29:21]:表示 PMD 索引,即 ARM64 中的 L2 索引
- Bit[20:12]:表示 PT 索引,即 ARM64 中的 L3 索引
- Bit[11:0]:表示页面内的偏移量
基于 ARMv8-A 架构的处理器可以通过配置 ARM64_VA_BITS 宏来设置虚拟地址的宽度。
1 | <arch/arm64/Kconfig> |
另外,基于 ARMv8-A 架构的处理器支持的最大物理地址宽度也是 48 位。 Linux 内存空间布局与地址映射的粒度和地址映射的层级有关。基于 ARMv8-A 架构的处理器支持的页面粒度可以是 4KB、16KB 或者 64KB。映射的层级可以是 3 级或者 4 级。
AArch64 在 Linux 中的内存布局
AArch64 Linux 使用 3 级或 4 级转换表,其页大小配置为 4KB,对于用户和内核分别都有 39-bit (512GB) 或 48-bit (256TB) 的虚拟地址空间。对于页大小为 64KB 的配置,仅使用 2 级转换表,有 42-bit (4TB) 的虚拟地址空间,但内存布局相同。
用户地址空间的 63:48 位为 0,而内核地址空间的相应位为 1。TTBRx 的选择由虚拟地址的 63 位给出。swapper_pg_dir 仅包含内核(全局)映射,而用户 pgd 仅包含用户(非全局)映射。swapper_pg_dir 地址被写入 TTBR1 中,且从不写入 TTBR0。
AArch64 Linux 在页大小为 4KB,并使用 4 级转换表时的内存布局:
起始地址 结束地址 大小 用途
-----------------------------------------------------------------------
0000000000000000 0000ffffffffffff 256TB 用户空间
ffff000000000000 ffffffffffffffff 256TB 内核空间AArch64 Linux 在页大小为 64KB,并使用 2 级转换表时的内存布局:
起始地址 结束地址 大小 用途
-----------------------------------------------------------------------
0000000000000000 000003ffffffffff 4TB 用户空间
fffffc0000000000 ffffffffffffffff 4TB 内核空间更详细的内核虚拟内存布局,请参阅内核启动信息。
4KB 页大小的转换表查找:
+--------+--------+--------+--------+--------+--------+--------+--------+
|63 56|55 48|47 40|39 32|31 24|23 16|15 8|7 0|
+--------+--------+--------+--------+--------+--------+--------+--------+
| | | | | |
| | | | | v
| | | | | [11:0] 页内偏移
| | | | +-> [20:12] L3 索引
| | | +-----------> [29:21] L2 索引
| | +---------------------> [38:30] L1 索引
| +-------------------------------> [47:39] L0 索引
+-------------------------------------------------> [63] TTBR0/164KB 页大小的转换表查找:
+--------+--------+--------+--------+--------+--------+--------+--------+
|63 56|55 48|47 40|39 32|31 24|23 16|15 8|7 0|
+--------+--------+--------+--------+--------+--------+--------+--------+
| | | | |
| | | | v
| | | | [15:0] 页内偏移
| | | +----------> [28:16] L3 索引
| | +--------------------------> [41:29] L2 索引
| +-------------------------------> [47:42] L1 索引
+-------------------------------------------------> [63] TTBR0/1当使用 KVM 时,管理程序(hypervisor)在 EL2 中通过相对内核虚拟地址的一个固定偏移来映射内核页(内核虚拟地址的高 24 位设为零):
起始地址 结束地址 大小 用途
-----------------------------------------------------------------------
0000004000000000 0000007fffffffff 256GB 在 HYP 中映射的内核对象高速缓存管理
ARM64 指今集提供了对高速缓存进行管理的指令,包括管理无效高速缓存和清除高速缓存的指令。高速缓存的管理主要有如下 3 种情况。
- 使整个高速缓存或者某个高速缓存行无效。
- 清除(clean)整个高速缓存或者某个高速缓存行。之后,相应的高速缓存行会被标为脏的,数据会写回到下一级高速缓存中或者主存储器中。
- 清零(zero)操作。在某些情况下,对高速缓存进行清零操作以起到一个预取和加速的作用。例如,当程序需要使用较大的临时内存时,如果在初始化阶段对这个内存行清零操作,高速缓存控制器就会主动把这些零数据写入高速缓存行中。若程序主动使用高速缓存的清零操作,那么将大大减少系统内部总线的带宽。
对高速缓存的操作可以指定如下不同的范围。
- 整块高速缓存
- 某个虚拟地址
- 特定的高速缓存行或者组和路
另外,在 ARMv8 架构中最多可以支持 7 级的高速缓存,即 L1~L7 高速缓存。当对一个高速缓存行进行操作时,我们需要知道高速缓存操作的范围。ARMv8 架构中将从以下角度观察内存。
全局缓存一致性角度(Point of Coherency,PoC):系统中所有可以发起内存访问的硬件单元(如处理器、DMA 设备、GPU 等)都能保证观察到的某一个地址上的数据是一致的或者是相同的副本。通常 PoC 表示站在系统的角度来看高速缓存的一致性问题。
处理器缓存一致性角度(Point of Unification,PoU):表示站在处理器角度来看高速缓存的一致性问题。对于一个内部共享(inner shareable)的 PoU,所有的处理器都能看到相同的内存副本 假设在一个双核处理器系统中,每一个处理器都有独自的 L1 高速缓存,它们共享一个 L2 高速缓存,它们都可以共同访问 DDR4 内存。另外,系统中还有 GPU 等硬件单元。
如果以 PoU 看高速缓存,那么这个观察点就是 L2 高速缓存,因为两个处理器都可以在 L2 高速缓存中看到相同的副本。
如果以 PoC 看高速缓存,那么这个观察点是 DDR4 内存,因为 CPU 和 GPU 都能共同访问 DDR4 内存。
ARMv8 架构提供 DC 和 IC 两条与高速缓存相关的指令,它们根据不同的辅助操作符可以有不同的含义,如下所示。
1 | //DC 指令的格式 |
- DC:
- cisw:清除并使指定的组和路的高速缓存无效
- civac:从 PoC,清除并使指定的虚拟地址对应的高速缓存无效
- csw:清除指定的组或路的高速缓存
- cvac:从 PoC,清除指定的虚拟地址对应的高速缓存
- cvau:从 PoU,清除指定的虚拟地址对应的高速缓存
- isw:使指定的组或路的高速缓存无效
- ivac:从 PoC,使指定的虚拟地址中对应的高速缓存无效
- zva:把虚拟地址中的高速缓存清零
- IC:
- ialluis:从 PoU,使所有的指令高速缓存无效,内部共享属性
- iallu:从 PoU,使所有的指令高速缓存无效
- ivau:从 PoU,使指定虚拟地址对应的指令高速缓存无效
Linux 内核提供了多个与高速缓存管理相关的接口函数,它们定义在 arch/arm64/include/asm/cacheflush.h 头文件中,它们实现在 arch/arm64/mm/cache.S 汇编文件中,如下:
1 | flush_cache_mm(mm) //在修改页表之前清除和无效该进程的进程地址空间中所有的高速缓存页表项 |
内存属性
ARMv8 架构处理器实现了弱一致性内存模型,在某些情况下,处理器在执行指令时不一定完全按照程序员编写的指令顺序来执行。处理器为了提高指令执行效率会乱序执行指令和预测指令。现代处理器为了提高系统吞吐率都会做如下优化。
- 并发执行多条指令(multiple issue ofinstructions)。处理器可以在一个时钟周期内发射和执行多条指令。
- 乱序执行(out of order execution)。处理器可以乱序执行没有依赖关系的指令。
- 预测执行(speculation)。处理器在遇到一个条件判断时会预测将来可能发生的情况并且提前执行分支代码。
- 预测加载。若可以预测一个加载指令,那么高速缓存就可以提前把数据预取到高速缓存行中,从而提高效率。
- 加载和存储优化。读写外部内存是一个耗时的操作,处理器应该尽量减少读写次数,如处理器将多次访问内存的操作合并为一次传输,这样可以提高系统效率。
在一个单核处理器系统中,指令乱序和并发执行对于程序员来说是透明的,因为处理器会处理这些数据依赖关系。但是,在多核处理器系统中,多个处理器内核同时访问共享数据或内存时,与处理器相关的乱序和预测执行等优化手段就可能会对程序造成意想不到的麻烦。因此,了解内存属性和内存屏障就显得非常重要。
内存属性
普通内存
普通内存是弱一致性的(weakly ordered),没有额外的约束,可以提供最高的内存访问性能。通常代码段、数据段以及其他数据都会放在普通内存中。普通内存可以让处理器做很多的优化,如分支预测、数据预取、高速缓存行预取和填充、乱序加载等硬件优化。
设备内存
处理器访问设备内存会有很多限制,如不能进行预测访问等。设备内存是严格按照指令顺序来执行的。ARMv8 架构定义了多种设备内存的属性:
- Device-nGnRnE
- Device-nGnRE
- Device-nGRE
- Device-GRE
Device 后的字母是有特殊含义的。
- G 和 nG:分别表示聚合(Gathering)与不聚合(non Gathering)。聚合表示在同一个内存属性的区域中允许把多次访问内存的操作合并成一次总线传输:
- 若一个内存地址标记为“nG”,则会严格按照访问内存的次数和大小来访问内存,不会做合并优化
- 若一个内存地址标记为“G”,则会做总线合并访问,如合并两个相邻的字节访问为一次多字节访问。若程序访问同一个内存地址两次,那么处理器只会访问内存一次,但是在第二次访问内存指令后返回相同的值。若这个内存区域标记为“nG”,那么处理器则会访问内存两次
- R 和 nR:分别表示指令重排(Re-ordering)与不重排(non Re-ordering)。
- E 和 nE:分别表示提前写应答(Early Write Acknowledgement)与不提前写应答 Early Write Acknowledgement)往外部设备写数据时,处理器先把数据写入写终 (write huffer)中,若使能了提前写应答,则数据到达写缓冲区时会发送写应答: 有使能提前写应答,则数据到达外设时才发送写应答。 Linux 内核中定义了如下几个内存属性。
1 |
- MT_DEVICE_nGnRnE:设备内存属性,不支持聚合操作,不支持指令重排,不支提前写应答
- MT_DEVICE_nGnRE:设备内存属性,不支持聚合操作,不支持指令重排,支持提写应答
- MT_DEVICE_GRE:设备内存属性,支持聚合操作,支持指令重排,支持提前写应
- MT_NORMAL_NC:普通内存属性,关闭高速缓存,其中 NC 是 Non-Cacheable 意思
- MT_NORMAL:普通内存属性
- MT_NORMAL_WT:普通内存属性,高速缓存的回写策略为直写(write through)策内存属性并没有存放在页表项中,而是存放在 MAIR_ELn (Memory Attribute IndirectRegister Eln)中。页表项中使用一个 3 位的索引值来查找 MAIR_ELn
MAIR_ELn 分成 8 段,每一段都可以用于描述不同的内存属性。
高速缓存共享属性
普通内存可以设置高速缓存为可缓存的和不可缓存的。进一步地,我们可以设置高速缓为内部共享和外部共享的高速缓存。一个处理器系统中,除了处理器之外,还有其他的可以访问内存的硬件单元,这些硬件单元通常具有访问内存总线(bus master)的能力,如 DMA 设备、GPU 等,这些硬件单元可以称为处理器之外的观察点。在一个多核系统中,DMA 设备和 GPU 通过系统总线连接到 DDR 内存,而处理器也通过系统总线连接到 DDR 内存,它们都能同时通过系统总线访问到内存。
- 如果一个内存区域被标记为“不可共享的”表示它只能被一个处理器访问,其他处理器不能访问这个内存区域。
- 如果一个内存区域被标记为“内部共享的”,表示它可以被多个处理器访问和共享,但是系统中其他的访问内存的硬件单元就不能访问了,如 DMA 设备、GPU 等。
- 如果一个内存区域被标记为“外部共享的”,表示系统中很多访问内存的单元(如 DMA 设备、GPU 等)都可以和处理器一样访问这个内存区域。
内存屏障
内存屏障指令
ARMv8 指令集提供了 3 条内存屏障指令。
- 数据存储屏障(Data Memory Barrier,DMB)指令:仅当所有在它前面的存储器访问操作都执行完毕后,才提交(commit)在它后面的访问指令。DMB 指令保证的是 DMB 指令之前的所有内存访问指令和 DMB 指令之后的所有内存访问指令的顺序。
- 数据同步屏障(Data synchronization Barrier,DSB)指令:比 DMB 指令要严格一些,仅当所有在它前面的访问指令都执行完毕后,才会执行在它后面的指令,即任何指令都要等待 DSB 指令前面的访问指令完成。位于此指令前的所有缓存,如分支预测和 TLB 维护操作需全部完成。
- 指令同步屏障(Instruction synchronization Barrier,ISB)指令:比 DMB 指令和 DSB 指令严格,刷新流水线(flush pipeline)和预取缓冲区后,才会从高速缓存或者内存中预取 ISB 指令之后的指令。ISB 指令通常用来保证上下文切换的效果,如 ASID 更改、TLB 维护操作和 C15 寄存器的修改等。
DMB 指令和 DSB 指令还可以带参数,来指定内存屏障指令的顺序以及共享属性等信息。 内存屏障指令参数如下所示。
- 全系统共享:
- SY:内存读写指令
- ST:内存写指令
- LD:内存读指令
- 内部共享:
- ISH:内存读写指令
- ISHST:内存写指令
- ISHLD:内存读指令
- 不共享:
- NSH:内存读写指令
- NSHST:内存写指令
- NSHLD:内存读指令
- 外部共享:
- OSH:内存读写指令
- OSHST:内存写指令
- OSHLD:内存读指令
加载-获取屏障原语与存储-释放屏障原语
ARMv8 指令集还支持隐含内存屏障原语的加载和存储指令,这些内存屏障原语影响了加和存储指令的执行顺序,它们对执行顺序的影响是单方向的。
- 获取(acquire)屏障原语:该屏障原语之后的读写操作不能重排到该屏障原语前面,通常该屏障原语和加载指令结合
- 释放(release)屏障原语:该屏障原语之前的读写操作不能重排到该屏障原语后面通常该屏障原语和存储指令结合
- 加载-获取(load-acquire)屏障原语:含有获取屏障原语的读操作,相当于单方向向后的屏障指令。所有加载-获取内存屏障指令后面的内存访问指令只能在加载-获取内存屏障指令执行后才能开始执行,并且被其他 CPU 观察到。普通的读和写操作可以向后越过该屏障指令,但是之后的读和写操作不能向前越过该屏障指令
- 存储-释放(store-release)屏障原语:含有释放屏障原语的写操作,相当于单方向前的屏障指令。只有所有存储-释放屏障原语之前的指令完成了,才能执行存储-释屏障原语之后的指令,这样其他 CPU 可以观察到存储-释放屏障原语之前的指令已执行完。普通的读和写可以向前越过存储-释放屏障指令,但是之前的读和写操作不能向后越过存储-释放屏障指令
加载-获取和存储-释放屏障指令相当于是单方向的半条 DMB 指令,而 DMB 指令相当于是全方向的栅障。任何读写操作都不能跨越该栅障。它们组合使用可以增强代码灵活性并提高执行效率。
如图所示,加载-获取屏障指令和存储-释放屏障指令组成了一个临界区,这相当于一个栅栏。在加载-获取屏障指令之前的内存访问指令(如读指令 1 和写指令 1)可以挪到加载-获取屏障指令后面执行,但是不能向前越过存储-释放屏障指令。而存储-释放屏障指令后面的内存访问指令(如读指令 2 和写指令 2)不能向前穿越过加载-获取屏障指令。在临界区中的内存不能越过临界区,如读指令 2 必须在加载-获取屏障指令后开始执行;如读指令 2 和写指令 2 必须在存储-释放屏障指令之前完成,即保证其他 CPU 在存储-释放屏障指令执行完成时能观察到读指令 1 和写指令 1、读指令 2 和写指令 2 已经完成。 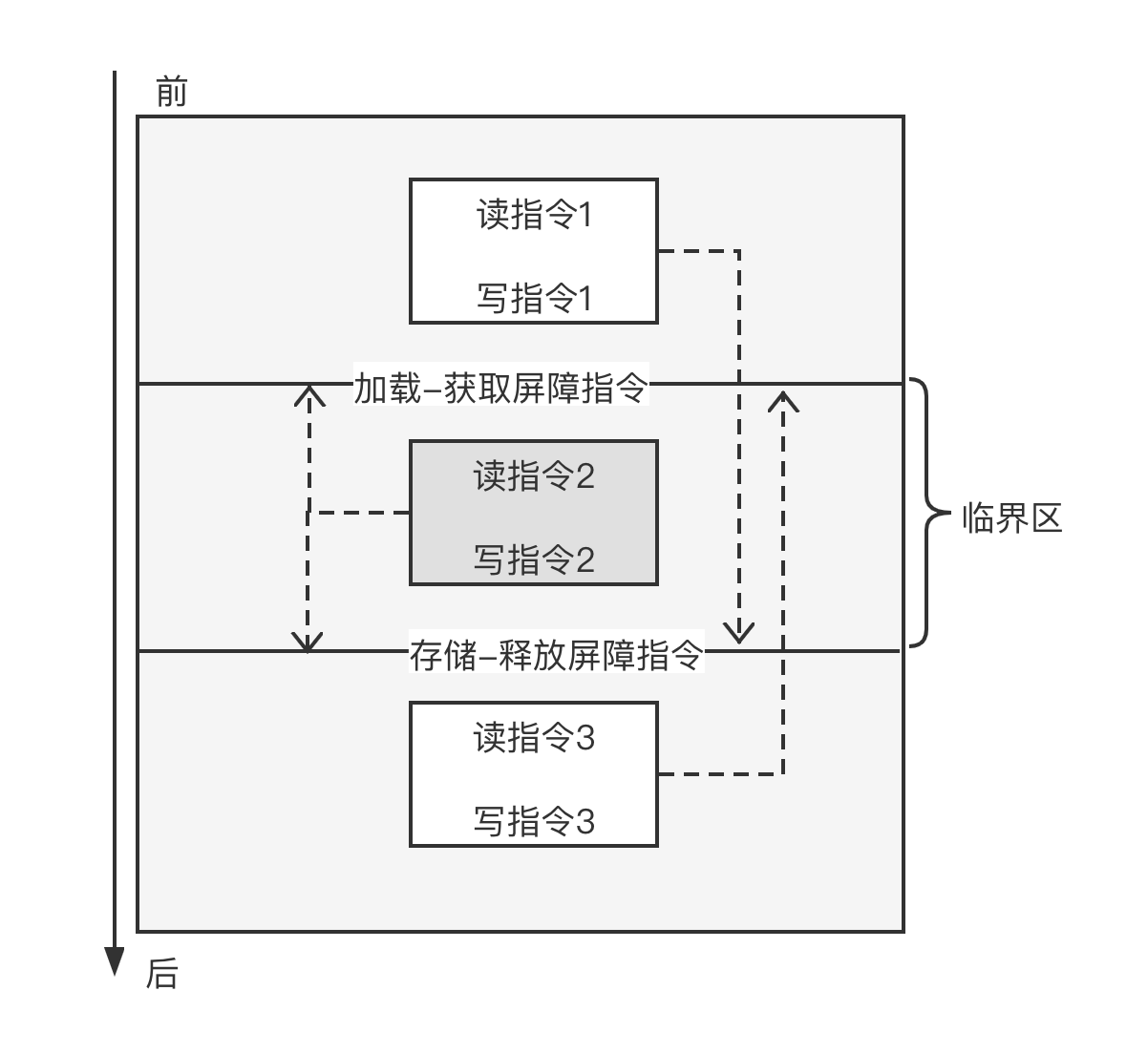
ARM64 指令集中提供了如下指令。
- LDAR 和 STLR 指令:用于加载和存储
- CAS 指令:用于比较和交换
参考文献
https://armv8-ref.codingbelief.com/zh/chapter_d4/d43_3_memory_attribute_fields_in_the_vmsav8-64_translation_table_formats_descriptors.html
《奔跑吧 Linux 内核》