Linux 内存管理(三)物理地址管理
 原图
原图
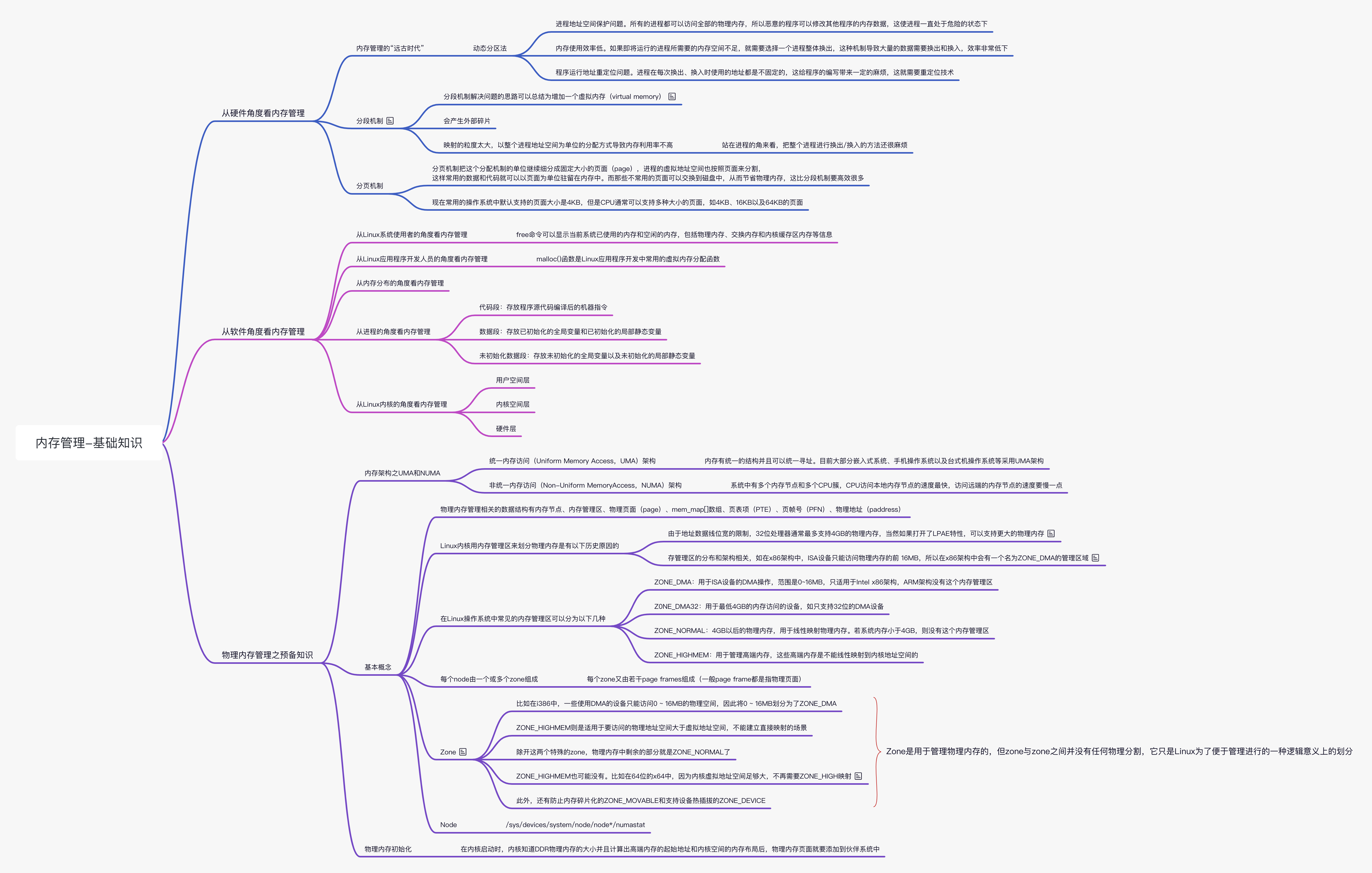
内存管理发展史
内存管理的“远古时代”
在分页机制出现之前,操作系统有很多不同的内存管理机制,如动态分区法。如图(a)所示。剩余的 4MB 内存不足以装载进程 D,如图(b)所示,因为进程 D 需要 5MB 内存,这个内存末尾就成了第一个空洞(内存碎片)。假设某个时刻,操作系统需要运行进程 D,因为系统中没有足够的内存,所以需要选择一个进程来换出,为进程 D 腾出足够的空间。假设操作系统选择进程 B 来换出,这样进程 D 就装载到了原来进程 B 的地址空间里,于是产生了第二个空洞,如图(c)所示。假设操作系统某个时刻需要运行进程 B,也需要选择一个进程来换出,假设进程 A 被换出,那么操作系统中又产生了第三个空洞,如图(d)所示。 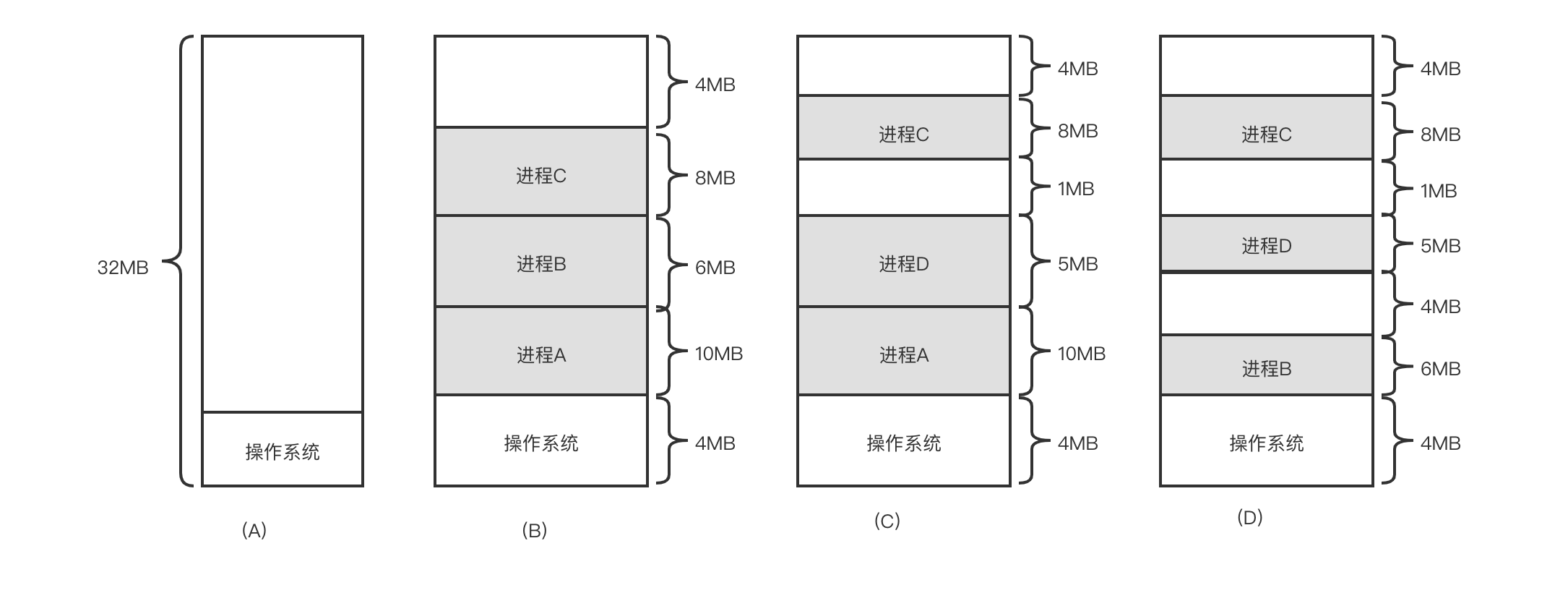
这种动态分区法在开始时是很好的,但是随着时间的推移会出现很多内存空洞,内存的利用率随之下降,这些内存空洞便是我们常说的内存碎片,动态分区法依然存在以下问题。
- 进程地址空间保护问题。所有的进程都可以访问全部的物理内存,所以恶意的程序可以修改其他程序的内存数据,这使进程一直处于危险的状态下。
- 内存使用效率低。如果即将运行的进程所需要的内存空间不足,就需要选择一个进程以进行整体换出,这种机制导致大量的数据需要换出和换入,效率非常低下。
- 程序运行地址重定位问题。从上图中看到,进程在每次换出、换入时使用的地址都是不固定的,这给程序的编写带来一定的麻烦,因为访问数据和指令跳转时的目标地址通常是固定的,这就需要重定位技术。
因此产生了分段机制和分页机制。
分段机制
- 把程序所需的内存空间的虚拟地址映射到某个物理地址空间中,解决地址空间保护问题。
- 分段机制把进程分成若干段(代码段、数据段栈段与堆段等),每个段的大小是不固定的,有点类似于动态分区法,这些段的物理地址可以不连续这样可以一定程度上解决内存碎片问题。
分段机制是一个比较明显的改进,但是它的内存使用效率依然比较低。分段机制对虚拟内存到物理内存的映射依然以进程为单位。进程在运行时,根据局部性原理,只有一部分数据是一直在使用的,若把那些不常用的数据交换出磁盘,就可以节省很多系统带宽。
分页机制
分页机制把分段机制的单位继续细分成固定大小的页面(page),进程的虚拟地址空间也按照页面来分割,这样常用的数据和代码就可以以页面为单位驻留在内存中,而那些不常用的页面可以交换到磁盘中。物理内存也以页面为单位来管理,这些物理内存称为物理页面(physical page)或者页帧(page frame)。进程的虚拟地址空间中的页面称为虚拟页面(virtualpage)。操作系统为了管理这些页帧需要按照物理地址给每个页帧编号,这个编号称为页帧号(Page Frame Number,PFN)。
从进程的角度看内存管理
在 Linux 系统中,应用程序常用的可执行文件格式是可执行与可链接格式(Executable Linkable Format,ELF)。ELF 最开始的部分是 ELF 文件头(ELF Header),它包含了描述整个文件的基本属性,如 ELF 文件版本、目标计算机型号、程序入口地址等信息。ELF 文件头后面是程序的各个段,包括代码段、数据段、未初始化数据段等。后面是段头表,用于描述 ELF 文件中包含的所有段的信息,如每个段的名字、段的长度、在文件中的偏移量、读写权限以及段的其他属性等,后面紧跟着是字符串表和符号表等。ELF 结构如下图所示: 
下面介绍常见的几个段,这些段与内核映像中的段也是基本类似的。
- 代码段:存放程序源代码编译后的机器指令。
- 数据段:存放已初始化的全局变量和已初始化的局部静态变量。
- 未初始化数据段:存放未初始化的全局变量以及未初始化的局部静态变量。下面编写一个简单的 C 程序。
1 |
|
这个 C 程序很简单,首先通过 malloc() 函数来分配 100KB 的内存,然后通过 memset() 函写入这块内存,最后用 while 循环是为了不让这个程序退出。我们通过如下命令来把它编成 ELF 文件。
1 | $ aarch64-linux-gnu-gcc-static test.c -o test.elf |
可以使用 objdump 或者 readelf 工具来查看 ELF 文件包含哪些段。
1 | vooxle@liushuai:~$ aarch64-linux-gnu-readelf -S test.elf |
可以看到刚才编译的 test.elf 文件一共有 28 个段,除了常见的代码段、数据段之外,还有一些其他的段,这些段在进程加载时起辅助作用,暂时先不用关注它们。程序在编译、链接时会尽量把相同权限属性的段分配在同一个空间里,如把可读、可执行的段放在一起,包括代码段、init 段等;把可读、可写的段放在一起,包括数据段和未初始化数据段等。ELF 把这些属性相似并且链接在一起的段叫作分段(segment),进程在加载时是按照这些分段来映射可执行文件的。描述这些分段的结构叫作程序头(program header),它描述了 ELF 文件是如何映射到进程地址空间的,这是我们比较关心的。我们可以通过 readelf -l 命今来查看这些程序头。
1 | vooxle@liushuai:~$ aarch64-linux-gnu-readelf -l test.elf |
从上面可以看到之前的 28 个段被分成了 6 个分段,我们只关注其中两个 LOAD 类型的分段。因为在加载时需要映射它,其他的分段在加载时起辅助作用。 先看第一个 LOAD 类型的分段,它是具有只读和可执行的权限,包含。init 段、代码段、只读数据段等常见的段,它映射的虚拟地址是 0x400000,长度是 0x78ba6。 第二个 LOAD 类型的分段具有可读和可写的权限,包含数据段和未初始化数据段等常见的段,它映射的虚拟地址是 0x489978,长度是 0x3608 上面从静态的角度来看进程的内存管理,我们还可以从动态的角度来看。Linux 操作系统提供了“proc”文件系统来窥探 Linux 内核的执行情况,每个进程执行之后,在/proc/pid/maps 节点会列出当前进程的地址映射情况。
1 | # cat /proc/721/maps |
第 1 行显示了地址 0x400000~0x46f000,这段进程地址空间的属性是只读和可执行的,由此我们知道它是代码段,也就是之前看到的代码段的程序头。
第 2 行显示了地址 0x47e000~0x48100,这段进程地址空间的属性是可读和可写的,也就是我们之前看到的数据段的程序头。
第 3 行显示了地址 0x272dd00~0x272ff000,这段进程地址空间叫作堆(heap)空间,也就是通常使用 malloc() 分配的内存,大小是 140KB。test 进程主要使用 malloc() 分配 100KB 的内存,这里看到 Linux 内核会分配比 100KB 稍微大一点的内存空间。
第 4 行显示了名为 vvar 的特殊映射。
第 5 行显示了名为 vdso 的特殊映射,VDSO 指 Virtual Dynamic Shared Object,用于解决内核和 libc 之间的版本问题。
第 6 行显示了 test 进程的栈(stack)空间。
对于这里的进程地址空间,在 Linux 内核中使用一个叫作 VMA 的术语来描述它,它是 vm_area_struct 数据结构的简称。 另外,/proc/pid/smaps 节点会提供更多地址映射的细节。 
物理内存管理之预备知识
内存架构之 UMA 和 NUMA
UMA 统一内存访问架构:内存有统一的结构并且可以统一寻址。目前大部分嵌入式系统、手机操作系统以及台式机操作系统等采用 UMA 架构
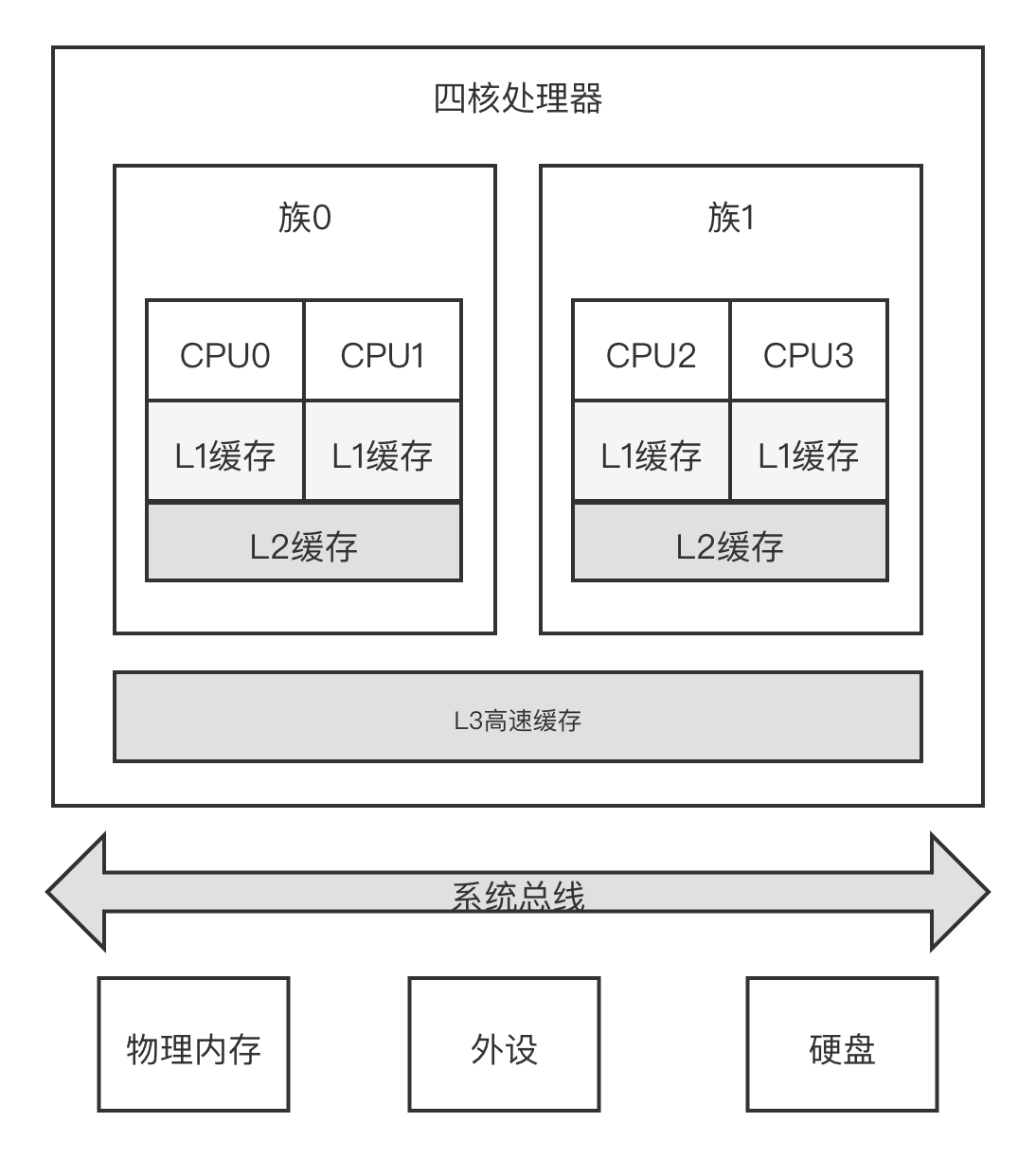
NUMA 非统一内存访问架构:系统中有多个内存节点和多个 CPU 簇,CPU 访问本地内存节点的速度最快,访问远端的内存节点的速度要慢一点
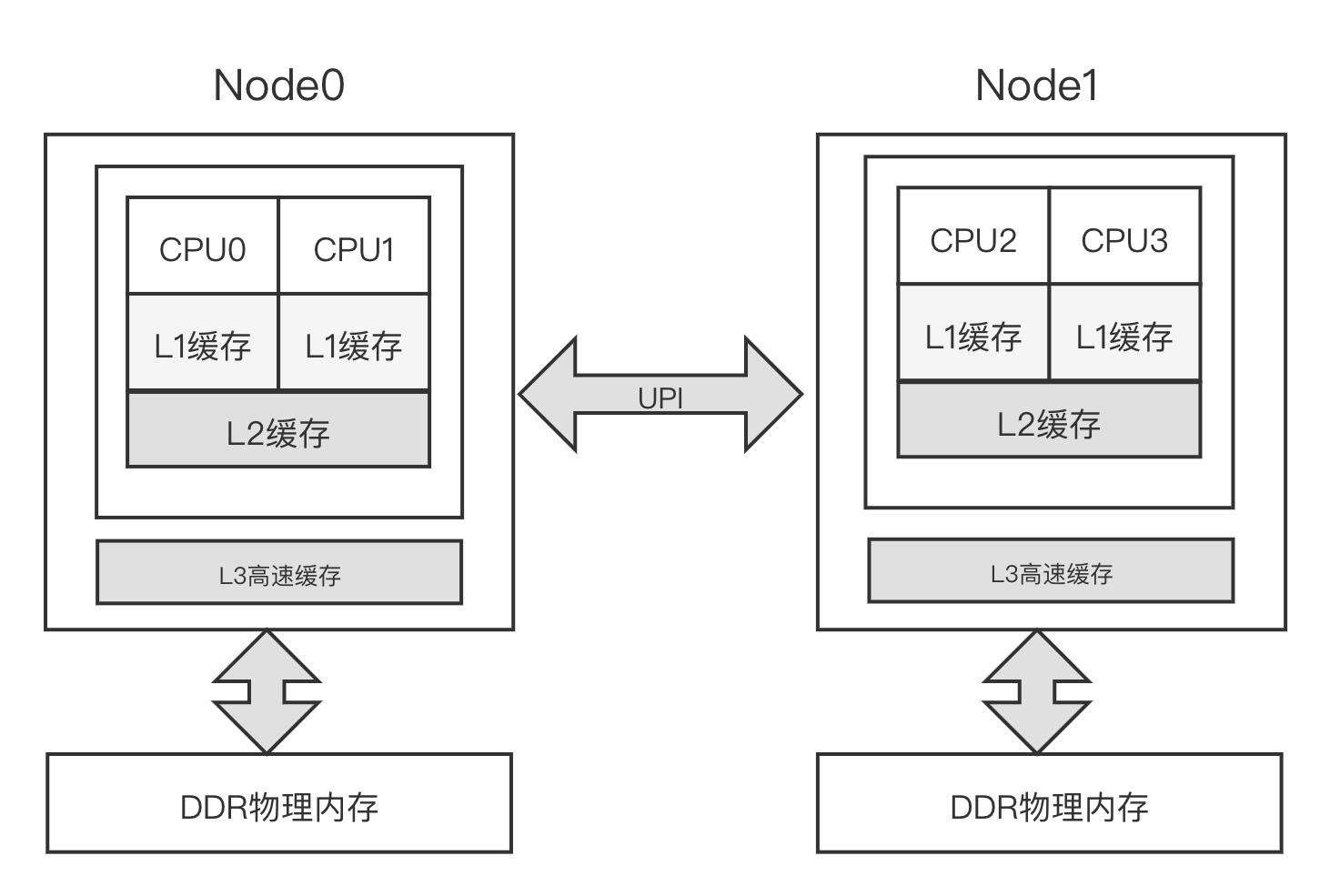
基本概念
从 Linux 内核的角度来看,DDR 存储设备其实就是一段物理内存空间。在 Linux 内核中,和内存硬件物理特性相关的一些数据结构主要集中在 MMU(如页表、高速缓存/TLB 操作等)中。因此大部分的 Linux 内核中关于内存管理的相关数据结构是软件层面的概念,如 mm、VMA、内存管理区(zone)、页面、pg_data 等。Linux 内核内存管理中的数据结构错综复杂,如下图所示。 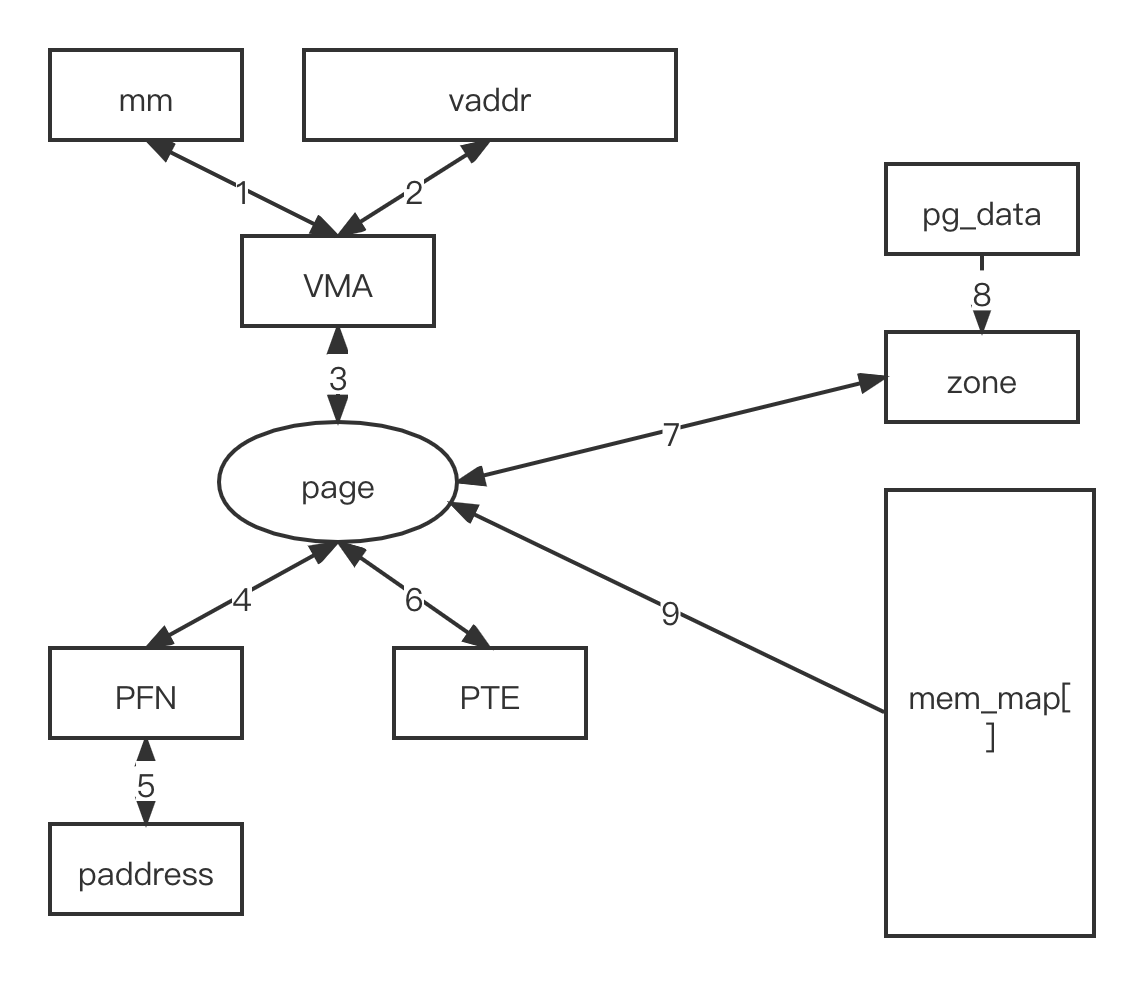
和物理内存管理相关的数据结构有内存节点(pglist data)、内存管理区、物理页面(page)、mem_map[] 数组、页表项(PTE)、页帧号(PFN)、物理地址(paddress)。
其中,pglist data 数据结构用来描述一个内存节点的所有资源。在 UMA 架构中,只有一个内存节点,即系统有一个全局的变量 contig_page_data 来描述这个内存节点。在 NUMA 架构中,整个系统的内存由一个 pglist_data *的指针数组 node_data[] 来管理,在系统初始化枚举 BIOS 固件(ACPI)来完成。
Linux 内核用内存管理区来划分物理内存是有以下历史原因的。
- 由于地址数据线位宽的限制,32 位处理器通常最多支持 4GB 的物理内存,如果打开了 LPAE 特性,可以支持更大的物理内存。在 4Gb 的地址空间中,通常内核空间只有 1GB 大小,因此对于大小为 4GB 的物理内存是无法进行--线性映射的。Linux 内核的做法是把物理内存分成两部分,其中一部分是线性映射的。如果用一个内存管理区来描述它,那就是 ZONE_NORMAL。剩余的部分叫从高端内存(high memory)同样使用一个内存管理区来描述它,称为 ZONE_HIGHMEM。
- 内存管理区的分布和架构相关,如在 x86 架构中,ISA 设备只能访问物理内存的前 16MB,所以在 x86 架构中会有一个名为 ZONE_DMA 的管理区域。在 x86_64 架构中,由于有足够大的内核空间可以线性映射物理内存,因此就不需要 ZONE_HIGHMEM 这个管理区域了。
在 Linux 操作系统中常见的内存管理区可以分为以下几种:
- ZONE_DMA:用于 ISA 设备的 DMA 操作,范围是 0~16MB,只适用于 Intel x86 架构,ARM 架构没有这个内存管理区。
- ZONE_DMA32:用于最低 4GB 的内存访问的设备,如只支持 32 位的 DMA 设备。
- ZONE_NORMAL:4GB 以后的物理内存,用于线性映射物理内存。若系统内存小于 4GB,则没有这个内存管理区。
- ZONE_HIGHMEM:用于管理高端内存,这些高端内存是不能线性映射到内核地址空间的。注意,在 64 位 Linux 操作系统中没有这个内存管理区。
Linux 内核中使用一个 page 数据结构来描述一个物理页面。Linux 内核为每个物理页面都分配了一个 page 数据结构,采用 mem_map[] 数组来存放这些 page 数据结构,并且它们和物理页面是一对一的映射关系,如下图所示 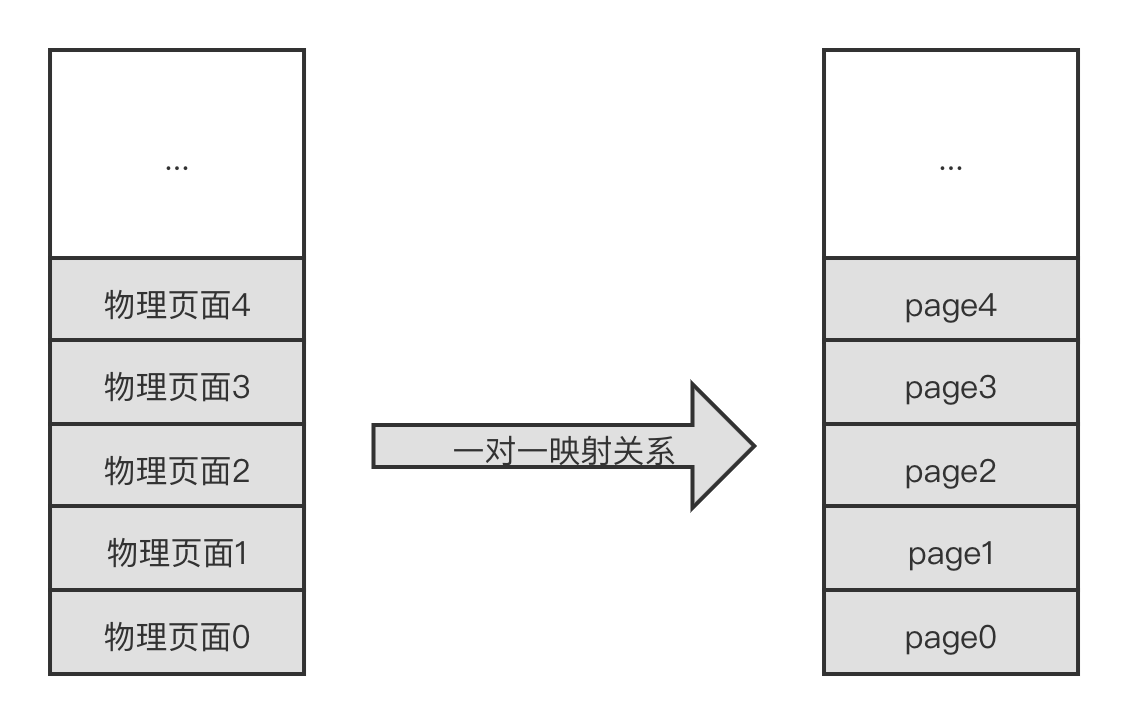
每个 node 由一个或多个 zone 组成,每个 zone 又由若干 page frames 组成(一般 page frame 都是指物理页面)。 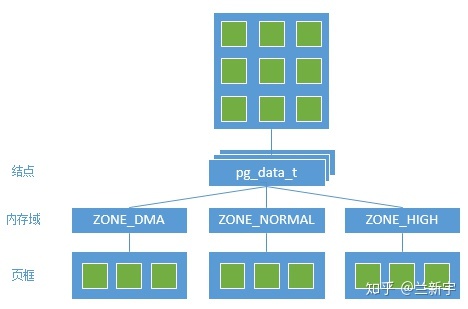
Memblock
Linux内核使用伙伴系统管理内存,在伙伴系统之前,内核通过memblock来管理内存。在系统启动阶段,使用memblock记录理内存的使用情况,可以分成好几块。
- 永久分配给系统内核:内核镜像占用的部分,如代码、数据段、设备树DTB等。
- 预留给外设的连续内存:如GPU/Camera/多核共享等需要预留大量连续内存。
- 其他部分:以上的剩余部分内存,需要进行内存管理。
初始化流程
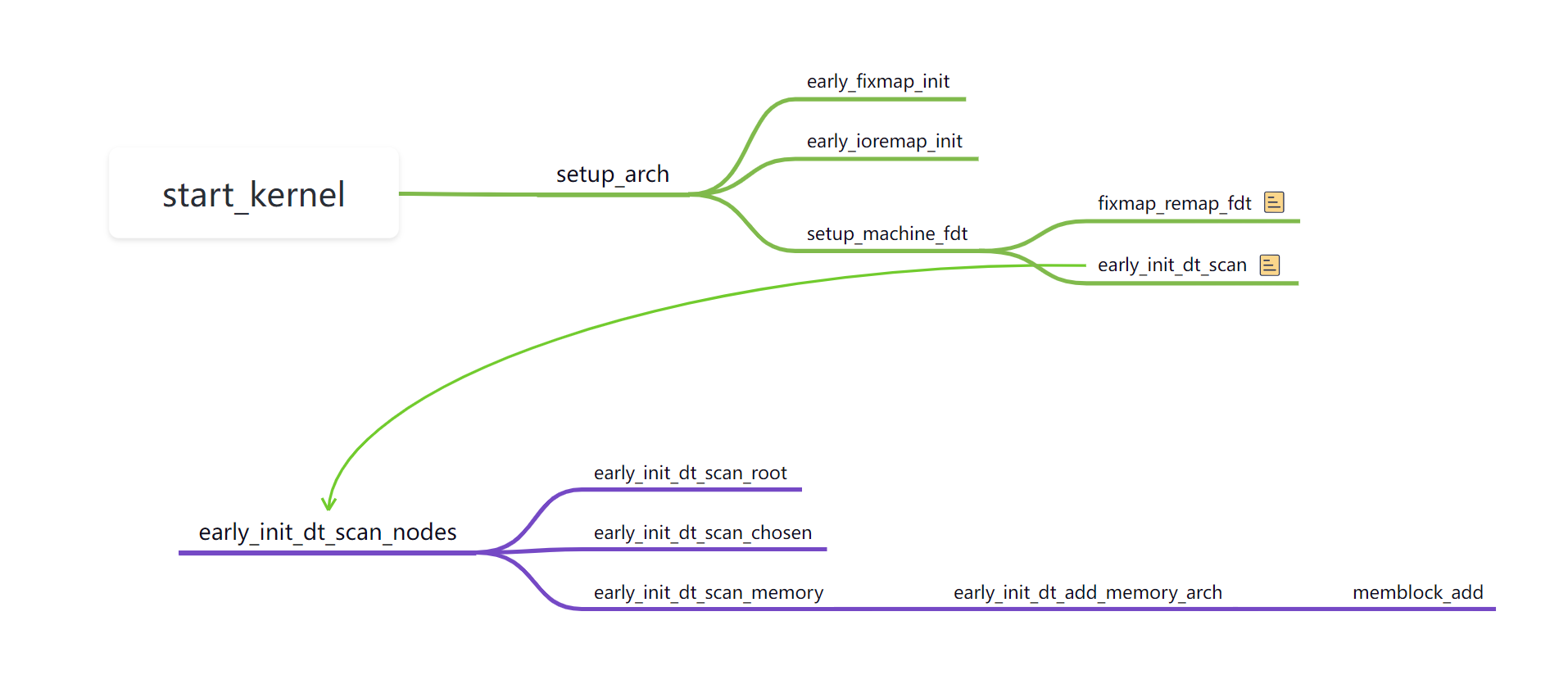
- 解析设备树二进制文件 /memory 节点, 将所有物理内存纳入到 memblock 分配器管理之下。
- 将kernel、dtb以及memory节点下的reserved内存组织为reserved内存,提供申请和释放内存的接口,避免使用到reserved内存。
数据结构
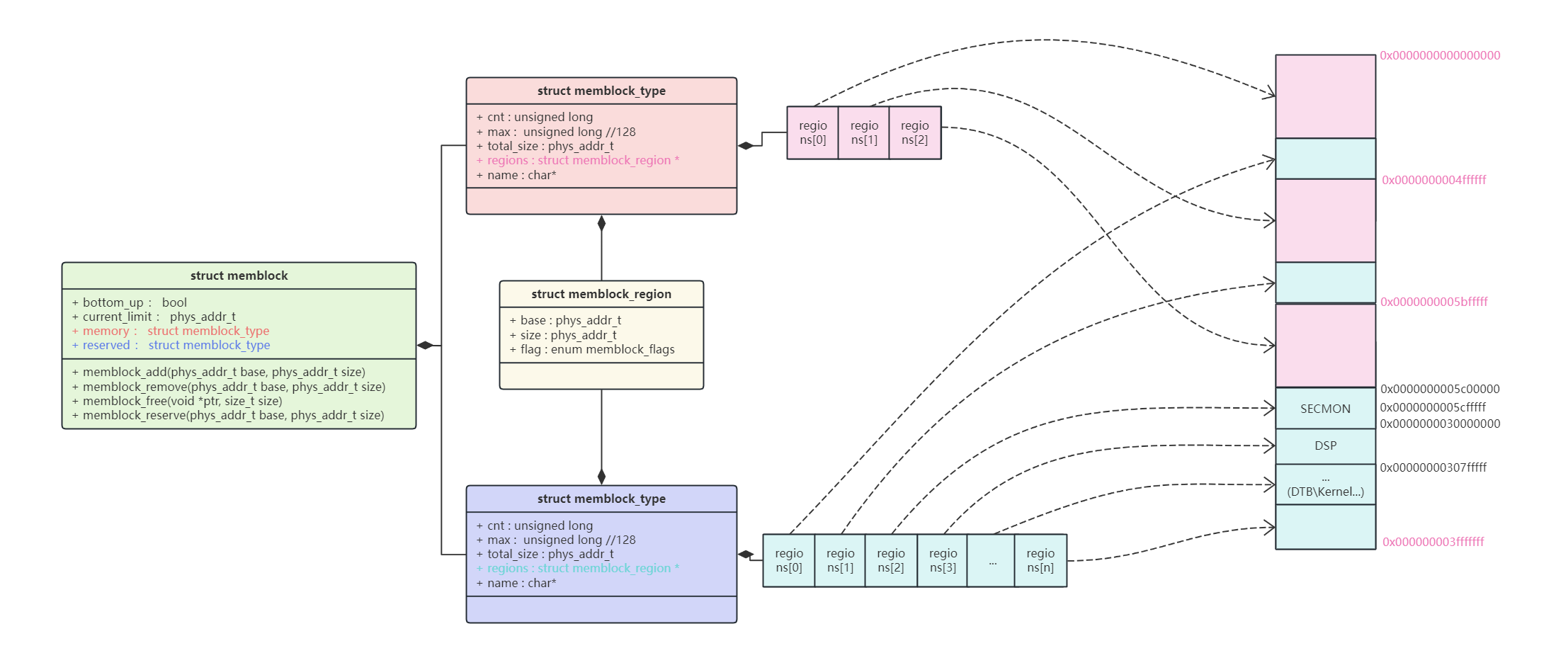 struct memblock结构体通过struct memblock_type管理mem和reserved内存,memblock_type里通过struct memblock_regions指针分别指向系统的可以内存和reserver内存。如上图Memblock将Secmon、DSP、dtb和kernel的内存组织位reserver,其他内存为mem。
struct memblock结构体通过struct memblock_type管理mem和reserved内存,memblock_type里通过struct memblock_regions指针分别指向系统的可以内存和reserver内存。如上图Memblock将Secmon、DSP、dtb和kernel的内存组织位reserver,其他内存为mem。
memblock_alloc接口
1 | memblock_alloc |
可见 memblock_alloc 函数和 memblock_phy_alloc 函数均是调用 memblock_find_in_range_node 实现物理内存的分配,不同的是 memblock_alloc 会在分配后调用了 phys_to_virt 函数将物理地址转换成虚拟地址。这里有个疑问phys_to_virt 是转为线性映射区,此时线性映射区以及映射好了?
对于Paging_init之前应该是不能直接调用phys_to_virt 的因为这个时候线性映射还没完成,这个时候应该是利用fixedmap映射区的fix_{pud、pmd、pte}页表完成映射,在paging_init之后因为完成了线性映射,这个ddr(除了no map外)都在线性映射范围内,这个时候是可以直接调用phys_to_virt 将Memblock分配的物理内存转为虚拟地址供内核使用的.
另外,调用 memblock_alloc_range_nid 之前会检查是否启用了 slab 分配器,如果已启用,说明 memblock 已将管理权移交给伙伴系统。这时会直接调用 kzalloc_node 从 slab 分配器分配内存。
memblock调试
在内核启动bootargs,可以加入"memblock=debug",会打开memblock的dbg打印,通过打印可以看出memblock的预留、分配等操作。 在内核编译时使能了内核debug功能后,还可以通过以下操作查看memblock信息。
1 | cat /sys/kernel/debug/memblock/memory |
Node-Zone-Page(Linux掌管物理内存的神)
为什么有了Memblock后还要设计Node-Zone来管理内存呢,Memblock管理内存太粗糙了,没有对内存的访问权限划分,以及内存属性等进行管理。为了对物理内存进行更精细的划分管理于是有了Node-Zone,在多cpu阵列中不同cpu对相同内存或相同cpu对不同内存的访问权限速度可能不同,这个时候需要对内存进行划分管理,设备DMA可能不能访问所有内存空间,只能访问部分空间这个时候DMA访问的地址空间需要划分出来管理,对于支持内存插拔的场景也需要一套机制来管理而这些是Memblock做不到的。
内存模型
Linux使用两种内存模型FLATMEM和SPARSEM。所有的内存模型都使用排列在一个或多个数组中的 struct page 来跟踪物理页帧的状态。 无论选择哪种内存模型,物理页框号(PFN)和相应的 struct page 之间都存在一对一的映射关系。 每个内存模型都定义了 pfn_to_page 和 page_to_pfn helper函数,允许从PFN到 struct page 的转换,反之亦然。
FLATMEM
在FLATMEM内存模型中,有一个全局的 mem_map 数组来映射整个物理内存。对于大多数架构,孔隙在 mem_map 数组中都有条目。与孔洞相对应的 struct page对象从未被完全初始化。
SPARSEMEM
SPARSEMEM是Linux中最通用的内存模型,它是唯一支持若干高级功能的内存模型,如物理内存的热插拔、非易失性内存设备的替代内存图和较大系统的内存图的延迟初始化。
SPARSEMEM模型将物理内存显示为一个部分的集合。一个区段用mem_section结构体表示,它包含 section_mem_map ,从逻辑上讲,它是一个指向 struct page阵列的指针。然而,它被存储在一些其他的magic中,以帮助分区管理。区段的大小 和最大区段数是使用 SECTION_SIZE_BITS 和 MAX_PHYSMEM_BITS 常量来指定的,这两个常量是由每个支持SPARSEMEM的架构定义的。 MAX_PHYSMEM_BITS是一个架构所支持的物理地址的实际宽度,而 SECTION_SIZE_BITS 是一个任意的值。
mem_section 对象被安排在一个叫做 mem_sections 的二维数组中。这个数组的大小和位置取决于 CONFIG_SPARSEM_EXTREME 和可能的最大段数:
- 当 CONFIG_SPARSEMEM_EXTREME 被禁用时, mem_sections 数组是静态的,有NR_MEM_SECTIONS 行。每一行持有一个 mem_section 对象。
- 当 CONFIG_SPARSEMEM_EXTREME 被启用时, mem_sections 数组被动态分配。每一行包含价值 PAGE_SIZE 的 mem_section 对象,行数的计算是为了适应所有的内存区。
架构设置代码应该调用sparse_init()来初始化内存区和内存映射。
通过SPARSEMEM,有两种可能的方式将PFN转换为相应的 struct page --"classic sparse"和"sparse vmemmap"。选择是在构建时进行的,它由 CONFIG_SPARSEMEM_VMEMMAP 的值决定。
Classic sparse在page->flags中编码了一个页面的段号,并使用PFN的高位来访问映射该页框的段。在一个区段内,PFN是指向页数组的索引。
Sparse vmemmapvmemmap使用虚拟映射的内存映射来优化pfn_to_page和page_to_pfn操作。有一个全局的 struct page *vmemmap 指针,指向一个虚拟连续的 struct page对象阵列。PFN是该数组的一个索引,struct page 从 vmemmap 的偏移量是该页的PFN。
为了使用vmemmap,一个架构必须保留一个虚拟地址的范围,以映射包含内存映射的物理页,并确保 vmemmap指向该范围。此外,架构应该实现 vmemmap_populate 方法,它将分配物理内存并为虚拟内存映射创建页表。如果一个架构对vmemmap映射没有任何特殊要求,它可以使用通用内存管理提供的默认 vmemmap_populate_basepages。
mem_section组织下的内存
Section相关宏定义
1 |
|
SECTION_SIZE_BITS 为什么要定义成27呢,我们知道我们的PAGE_SIZE是4096,而2^27 / 4096 = 32768,这刚好是一个s16类型能表示的范围这个是section_to_node_table的数据类型。
每一个mem_section可以用来描述SECTION_SIZE_BITS个bit位的地址,也就是2^27 = 32768 * 4k = 128M 用一个page来表示SECTIONS_PER_ROOT,每个SECTIONS_PER_ROOT里面有256个struct mem_section结构体,每个struct mem_section结构体可以描述一个128M,则SECTIONS_PER_ROOT能描述的地址空间是256 * 128M = 32G
32 * 8192 = 262144G = 256T = 2^48
数据结构与组织形式概览
先来一张整体图,表示mem_section是怎么组织内存的。 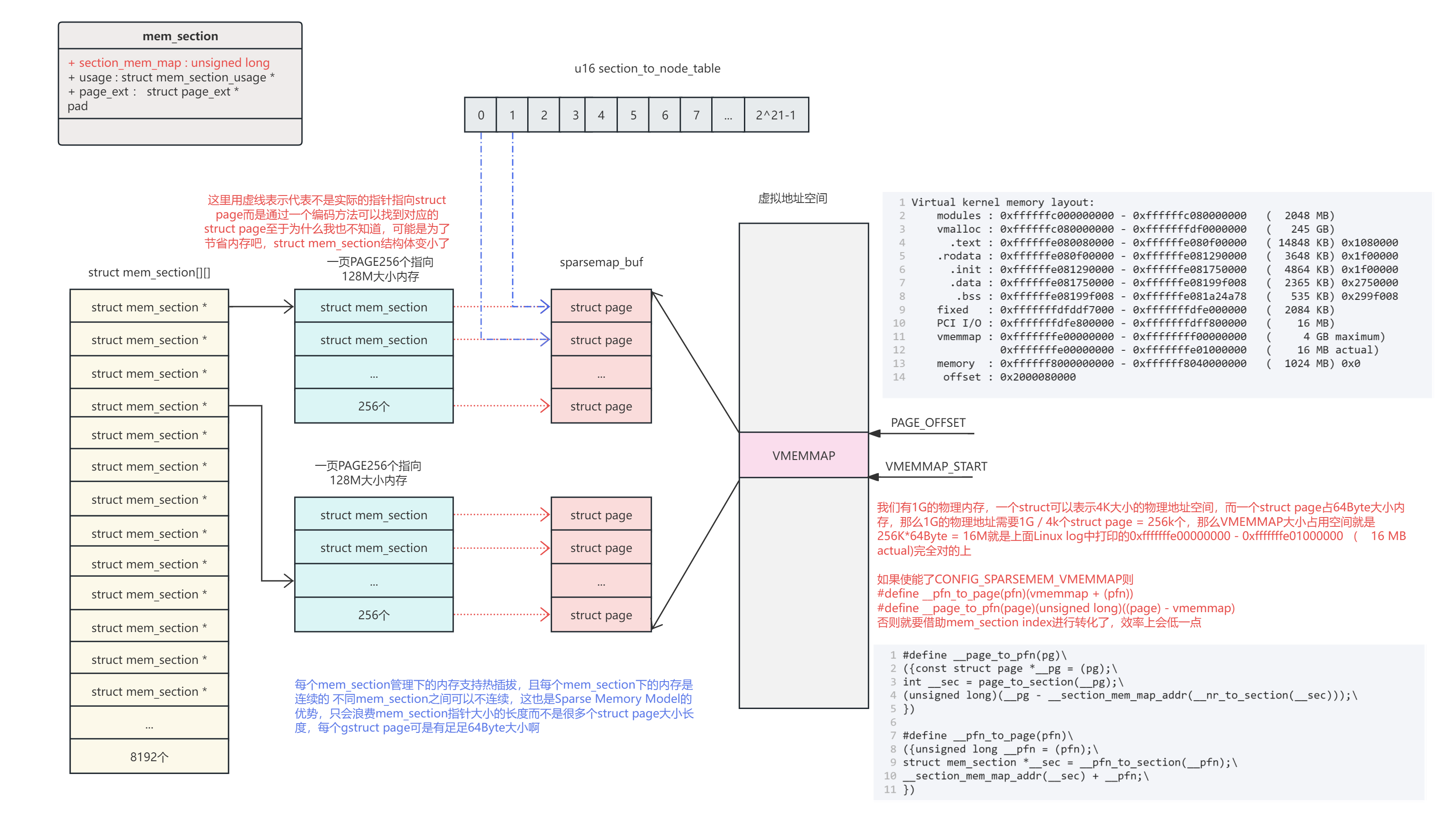
通过一个struct mem_section指针数组来表示所有PA范围,当然实际内存没有那么多,那么会浪费掉一些指针占用的空间,而这个浪费相对而言就比较小了。mem_section指针数组的每一项都指向一个mem_section结构体,一个mem_section结构体管理128MByte内存。mem_section通过一定的编码方式可以找到对于的struct page结构体,而每一个struct page对应着一块物理内存,而struct page结构体的虚拟地址空间在vmemmap映射区域,struct page的物理地址可能不连续,但是虚拟地址连续,这样可以方便将page与pfn进行快速转换。
数据结构
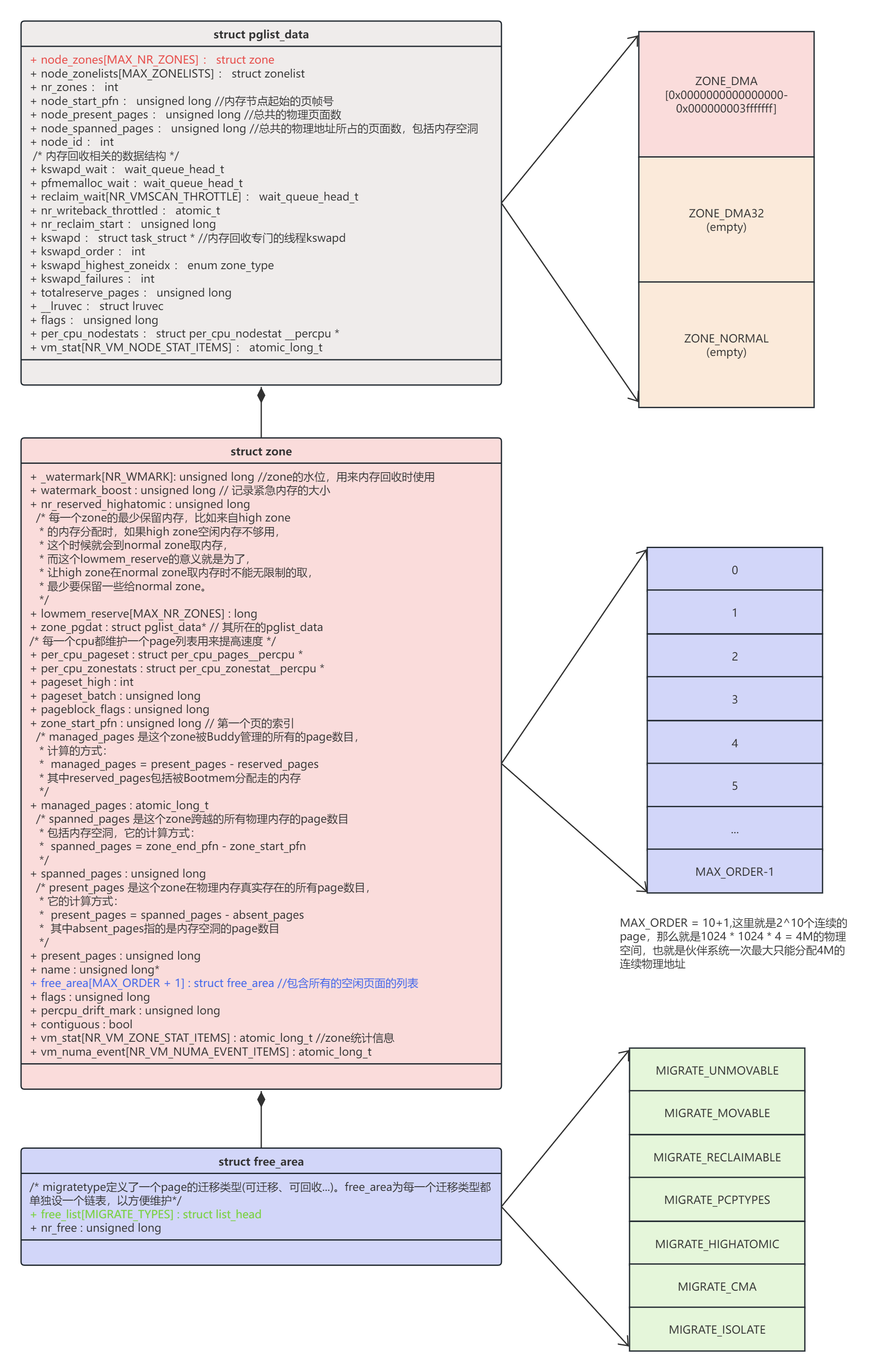
组织形式
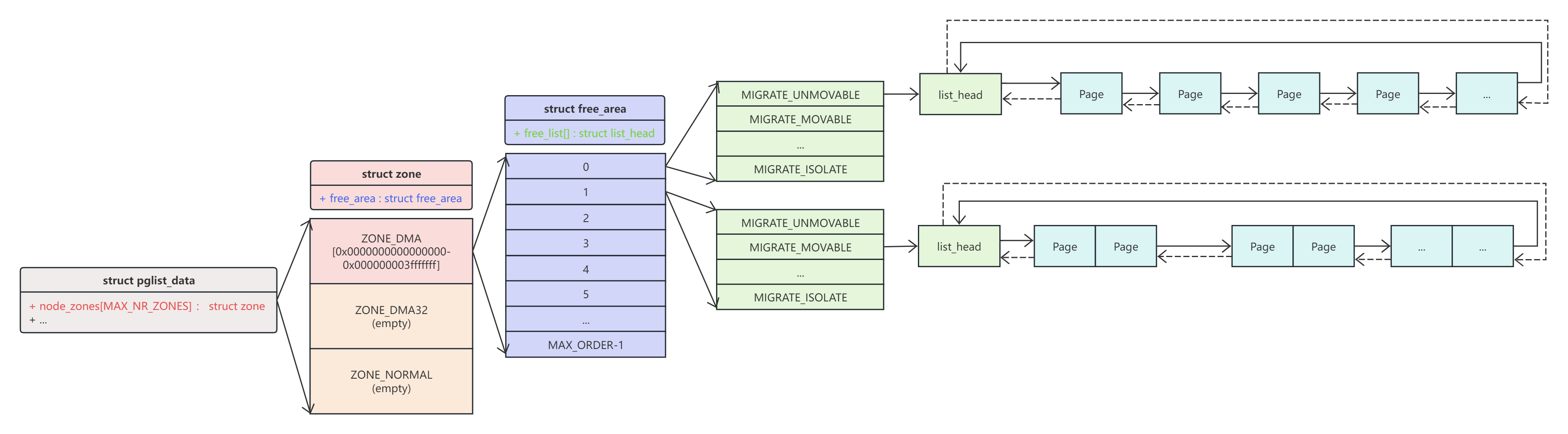
pglist_data就是node节点,对于UMA内存来讲就是一个node,node下管理数个zone,在我的ARM64设备上实际就一个zone就是Zone DMA(ARM64下没有ZONE HIGHT,因为虚拟内存足够大,不需要)ZONE DMA按照2^order次方组织page,有MAX_ORDER-1个数组,每个数组下又根据page是否可移动、是否可回收等权限分MIGRATE_MAX个链表来组织page,这为伙伴系统提供了page的组织和管理形式。
调试
1 | cat /proc/zoneinfo |
参考文献
https://zhuanlan.zhihu.com/p/68465952
https://zhuanlan.zhihu.com/p/68473428
《奔跑吧 Linux 内核》