Linux 内存管理(八)页面回收
 原图
原图
Linux 操作系统会使用存储设备作为交换分区,内核将很少使用的内存换出到交换分区,以便释放出物理内存,这个机制称为页交换(swapping),这些处理机制统称为页面回收 (pagereclaim)。
LRU 链表
Linux 内核中采用的页交换算法主要是经典 LRU 链表算法和第二次机会(secondchance)法。 LRU 是 Least Recently Used 的缩写,意为最近最少使用。根据局部性原理,LRU 假定最近不使用的页面在较短的时间内也不会频繁使用,在内存不足时,这些页面将成为被换出的候选者。内核使用双向链表来定义 LRU 链表,并且根据页面的类型将 LRU 链表分为 LRU_ANON 和 LRU_FILE。每种类型根据页面的活跃性分为活跃 LRU 链表和不活跃 LRU 链表,所以内核中一共有如下 5 个 LRU 链表。
- 不活跃匿名页面链表 LRU_INACTIVE_ANON
- 活跃匿名页面链表 LRU_ACTIVE_ANON
- 不活跃文件映射页面链表 LRU_INACTIVE_FILE
- 活跃文件映射页面链表 LRU_ACTIVE_FILE
- 不可回收页面链表 LRU_UNEVICTABLE
LRU 链表之所以要分成这样,是因为当内存紧缺时总是优先换出文件映射的文件缓存页面(LRU FILE 链表中的页面)而匿名页面总是要在写入交换分区之后,才能被换出。
LRU 链表按照内存节点(之前版本是 zpone)配置,也就是说,每个内存节点中都有一整套 LRU 链表,因此内存节点的描述符数据结构(pglist_data)中有一个成员 lruvec 指向这些链表。枚举类型变量 lru_list 列举出上述各种 LRU 链表的类型,lruvec 数据结构中定义了上述各种 LRU 类型的链表。
第二次机会法
第二次机会法的改进是为了避免把经常使用的页面置换出去。当选择置换页面时,依然和经典 LRU 链表算法一样,选择最早置入链表的页面,第二次机会法设置了一个访问状态位(硬件控制的位),所以要检查页面的访问位。如果访问位是 0,就淘汰这个页面;如果访问位是 1,就给它第二次机会,并选择下一个页面来换出。当该页面得到第二次机会时,它的访问位被清零,如果该页面在此期间再次被访问过,则访问位设置为 1。于是,给了第二次机会的页面将不会被淘汰,直至其他页面被淘汰(或者也给了第二次机会)。因此,如果一个页面经常被使用,其访问位总保持为 1,它一直不会被淘汰。
Linux 内核使用 PG_active 和 PG_referenced 这两个标志位来实现第二次机会法。PG_active 表示该页面是否活跃,PG_referenced 表示该页面是否被引用过。
实现
LRU 链表维护
我们需要有 timestamp 来标识一个 page 最近被访问的时间,然而像 x86 这样的架构并没有从硬件上提供这种机制。
Linux 采用的方法是维护 2 个双向链表,一个是包含了最近使用页面的 active list,另一个是包含了最近不使用页面的 inactive list,并且在 struct page 的 page flags 中使用了 PG_referenced 和 PG_active 两个标志位来标识页面的活跃程度。
- PG_active 标志位决定 page 在哪个链表,也就是说 active list 中的 pages 的 PG_active 都为 1,而 inactive list 中的 pages 的 PG_active 都为 0。
- PG_referenced 标志位则是表明 page 最近是否被使用过。当一个 page 被访问,mark_page_accessed() 会检测该 page 的 PG_referenced 位,如果 PG_referenced 为 0,则将其置为 1。
如果 inactive list 上 PG_referenced 为 1 的 page 在回收之前被再次访问到,也就是说它在 inactive list 中时被访问了 2 次,mark_page_accessed() 就会调用 activate_page() 将其置换到 active list 的头部,同时将其 PG_active 位置 1,PG_referenced 位清 0(可以理解为两个 PG_referenced 才换来一个 PG_active),这个过程叫做 promotion(逆袭)。
这 3 种情景的代码实现是这样的(为了演示需要在源代码的基础上做了简化和修改):
1 | void mark_page_accessed(struct page *page) |
当 active list 中的一个 page 在到达链表尾端时,如果其 PG_referenced 位为 1,则被放回链表头部,但同时其 PG_referenced 会被清 0。如果其 PG_referenced 位为 0,那么就会被放入 inactive list 的头部,这个过程叫做 demotion。可见,Linux 采用的这种 active list 和 inactive list 并不是严格按照时间顺序来置换 page 的,所以是一种伪 LRU 算法。
Inactive list 中尾端的页面不断被释放,相当于一个消费者,active list 则不断地将尾端 PG_referenced 为 0 的页面放入 inactive list,相当于一个生产者。不难想象,这 2 个链表的锁(lru_lock)应该是高度竞争的,如果从 active list 向 inactive list 的页面转移是一个一个进行的,那对锁的争抢将会十分严重。
为了解决这个问题,内核加入了一个 per-CPU 的 lru cache(用 struct pagevec 表示),从 active list 换出的页面先放入当前 CPU 的 lru cache 中,直到 lru cache 中已经积累了 PAGEVEC_SIZE(15)个页面,再获取 lru_lock,将这些页面批量放入 inactive list 中。 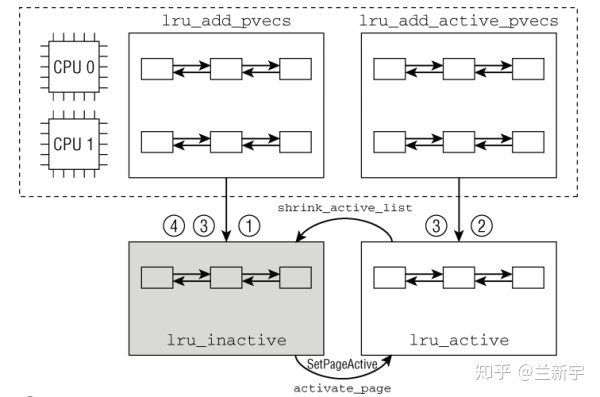
如果 inactive list 比较长,那么每个页面在被回收之前有充分的时间被再次访问,从而被 promote 到 active list,这样可以减少刚刚被回收又发生 refault 的页面数量(page thrashing)。但是由于内存总量有限,inactive list 较长就意味着 active list 相对较短,那这 2 个链表应该分别多长比较合适呢?
我们可以在一个页面被回收时记录一个 timestamp,当这个页面 refault 被换入时再记录一个 timestamp,如果将 inactive list 的长度增加,使得页面回收增长的时间超过这 2 个 timestamp 的差值时,那么这个页面就可以因为在 inactive list 中被再次访问,避免了被回收的命运,也减小了 refault 造成的开销。
可是前面也提到过,由于硬件的限制,给每个 page 维护一个 timestamp 是不现实的。还是类似的解决办法,用 inactive 中回收页面的个数来替代 timestamp,每回收一个页面,计数器加 1(相当于用 counter 替代了 timer)。那这个 counter 的值保存在哪里呢?
对于属于 page cache 的页面,由于其被换出之前是放在 radix tree/xarray 中的,当页面被回收时,我们可以把它曾经所在的 entry 利用起来,记录一下当前的 counter 值,页面被换入的时候再比较一下 entry 中的 counter 值,这种 entry 被称为 shadow entry。
对于一个基于文件的 page frame,好像它既在 page cache 结构中,又在 active/inactive list 结构中?没错,放在 page cache 中以 radix tree/xarray 的方式组织,是为了方便快速查找和读写它的内容,放在 active/inactive list 中则是为了方便内存回收。当一个基于文件的 page frame 被创建时,它就已经被加入到这 2 个结构中了:
1 | int add_to_page_cache_lru(struct page *page, struct address_space *mapping, |
这里同样是先放入 lru cache,而不是直接放进 active/inactive list 中。
匿名页面的处理
对于 anonymous pages,总是需要先写入 swap area 才能回收。而对于 page cache,有一些可以直接 discard(比如 elf 的 text 段对应的页面,data 段对应的页面中 clean 的部分),有一些 dirty 的页面需要先 write back 同步到磁盘。
由于有 flusher thread 定期的 write back,回收时还是 dirty 的 page cache 页面不会太多。而且,page cache 中的页面有对应的文件和在文件中的位置信息,需要换入恢复的时候也更加容易。
因此,内核通常更倾向于换出 page cache 中的页面,只有当内存压力变得相对严重时,才会选择回收 anonymous pages。用户可以根据具体应用场景的需要,通过"/proc/sys/vm/swappiness"调节内存回收时 anonymous pages 和 page cache 的比重。
swappiness 的值从 0 到 100 不等(默认一般是 60),这个值越高,则回收的时候越优先选择 anonymous pages。当 swappiness 等于 100 的时候,anonymous pages 和 page cache 就具有相同的优先级。至于为什么不从开销最小的角度将 swappiness 设为 0,将在后面给出答案。
1 | /* |
早期的 Linux 实现中,每个 zone 中有 active 和 inactive 两个链表,每个链表上存放的页面不区分类型。为了实现优先回收 page cache,之后每个链表拆分成了 LRU_ANON 和 LRU_FILE,因此形成了 LRU_INACTIVE_ANON, LRU_ACTIVE_ANON, LRU_INACTIVE_FILE 和 LRU_ACTIVE_FILE 四种链表,而且改成了一个 node 对应一组链表(per-node),由代表 node 的 struct pglist_data 中的 struct lruvec 包含各个链表的头结点 。
1 |
|
这里还有一个 LRU_UNEVICTABLE 链表。这个链表存储了 flag 为 PG_unevictable 的页面,因为 unevictable 的页面是不可以回收的,扫描的时候忽略 LRU_UNEVICTABLE 链表,将可以减少回收时扫描页面的总体时间。
可以通过"/proc/zoneinfo"查看这 4 种链表在 node 的各个 zone 上的分布: 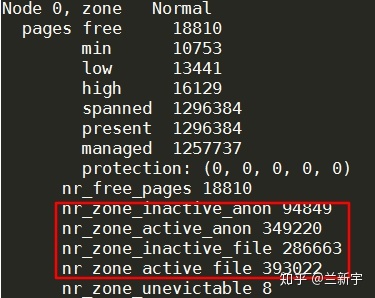
更丰富的信息则包含在"/proc/meminfo"中,比如"Dirty"表示修改后还没有 write back 的页面,"Writeback"表示正在执行 I/O 操作进行回写的页面,还有就是系统所有"active"和"inactive"的 page cache 和 anonymous page 的统计数据。
如果 swappiness 的值为 0,那么内核在启动内存回收时,将完全忽略 anonymous pages,这将带来一个好处,就是内核只需要扫描 page cache 对应的 inactive list(LRU_ACTIVE_FILE)就可以了,根本不用扫描 anonymous pages 对应的 inactive list(LRU_ACTIVE_ANON),这样能极大的节约内存回收时花在扫描 LRU 链表上的时间。
但是,swappiness 设置为 0 只适用于系统中 page cache 比较多的场景,如果系统中 anonymous pages 比 page cache 多很多,只回收 page cache 的话,可能无法满足 direct relaim 或者 kswapd 的需求。
这时本来系统中还有很多 anonymous pages 可供回收以释放内存,由于 swappiness 的限制,内核也许只有选择 OOM killer 了,所以用户在设置 swappiness 参数的时候,需要对自己的应用场景和内存的使用情况有比较深入的了解,要不然你可能会困惑:明明 available 的内存还很多啊,为啥老有进程被 OOM kill 呢。
触发机制
Linux 内核中触发页面回收的机制大致有 3 个。
- 直接页面回收机制。在内核态里调用页面分配接口函数 alloe_pages() 分配物理页面时,由于系统内存短缺,不能满足分配请求,因此内核会直接自陷到页面回收机制,这称为直接页面回收
- 周期性回收内存机制。这是 kswapd 内核线程的工作职责。当内核路径调用 alloc_pages() 分配物理页面时,由于系统内存短缺,没法在低水位情况下分配出内存,因此会唤醒 kswapd 内核线程来异步回收内存
- slab 收割机(slab shrinker)机制。这是用来回收 slb 对象的。当内存短缺时,直接页面回收和周期性回收内存两种机制都会调用 slab 收割机机制来回收 slab 对象。slab 机制分配的内存主要用于 slab 对象和 kmalloc 接口,也可用于内核空间的内存分配,而本节重点介绍的是用户内存的回收
读者需要注意的是,直接回收内存的进程主体是调用者本身。另外,还有一个重要的特点一直接回收内存是同步回收,这会阻塞调用者进程的执行。 kswapd 本身是内核线程,它和调用者的关系是异步的。
一个理想的情况是,我们能在内存压力不那么大的时候,就提前启动内存回收。而且,在某些场景下(比如在 interrupt context 或持有 spinlock 时),内存分配根本就是不能等待的。因此,Linux 中另一种更为常见的内存回收机制是使用 kswapd。
每个 node 对应一个内核线程 kswapd,kswapd 在被唤醒后将扫描各个 zone 的内存使用状态,并据此进行必要的内存回收操作,因此 kswapd 的回收方式又被称为"background reclaim"。至于什么情况下触发 direct reclaim,什么情况下又会触发 background reclaim,是由内存的"watermark"决定的。 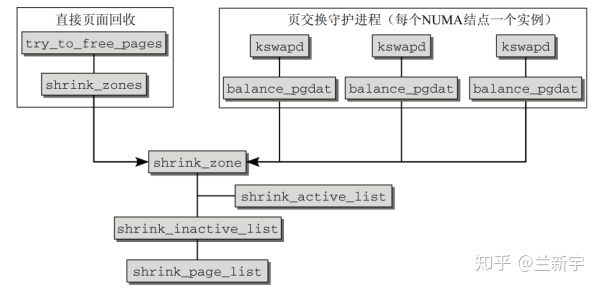
Kswapd 虽然名字中含有"swap",但它不光处理 anonymous page 的 swap out 回收,同样处理 page cache 的回收,而且它还肩负着平衡 active list 和 inactive list 的重任,所以被它调用的函数叫做 balance_pgdat()。
不管是 direct reclaim,还是 kswapd,最终都是调用 shrink_zone() --> shrink_page_list() 进行回收操作。
1 | static unsigned long shrink_list(enum lru_list lru, unsigned long nr_to_scan, |
当 inactive list 中的页面比较少时,shrink_active_list() 会从 active list 尾端转移一部分页面到 inactive list 中。这里的“少”是相对的,通常物理内存越大,inactive list 的页面占比可以越小(页面总数还是增加的),因为 inactive list 的长度主要是用来减少短时间内 refault 的。
shrink_inactive_list --> shrink_page_list 将从 inactive list 尾端移除选定数目的页面,进行释放。 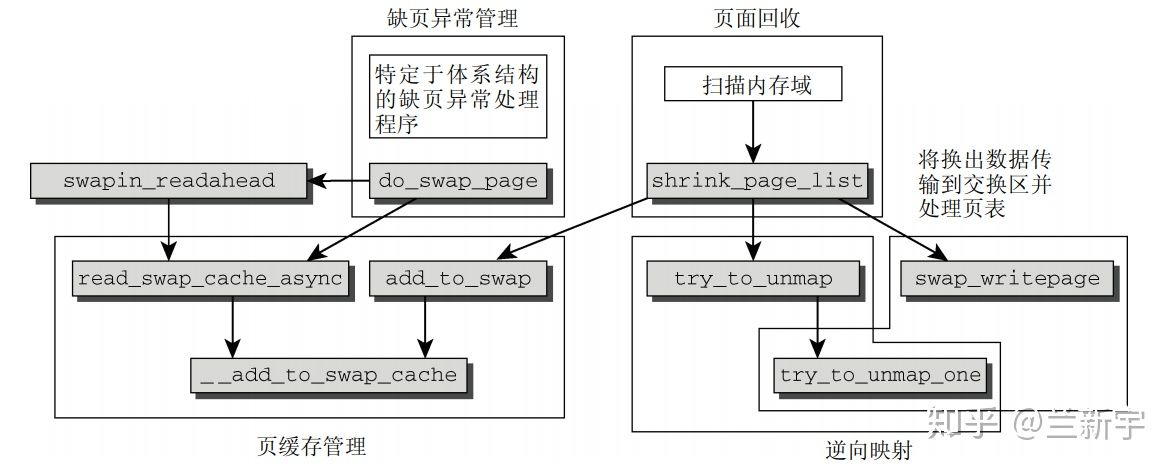
回收一个页面之前,如果该页面当前是被映射的(根据 struct page 的_mapcount 域判断),需要调用 try_to_unmap(),通过 reserve mapping 更改所有指向这个页面的 PTEs。对于 anonymous page,还需要在 swap space 中分配 slot,并且将这个 page 标记为 dirty 的。anonymous page 是没有 backing store 的,从 dirty 的角度,它可以算是一直 dirty 的。
前面提到过,不是所有的页面都可以被回收的。如果检测到页面的 flag 是 PG_locked 或者是 PG_reserved 的,则只能跳过。对于正在回写的(flag 是 PG_writeback 的),通常也是放弃回收,有这功夫去等待回写完成,还不如去找链表上其他的 clean page。 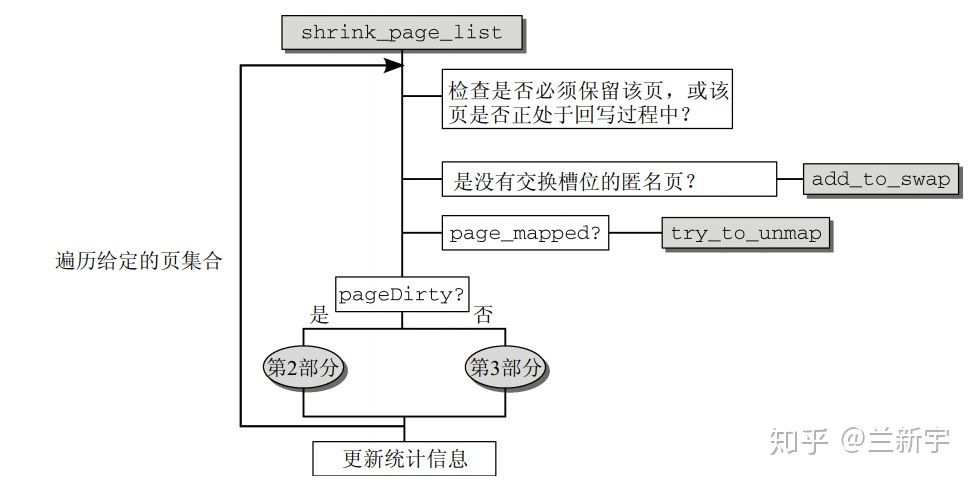
之后,对于 flag 是 PG_dirty 的页面,启动 pageout() 将这些页面备份或者同步到外部磁盘,这里“备份”针对的是 anonymous page,“同步”针对的是 page cache。
设置不回收
进程可以用申请 swap token,拥有了 swap token,就可以被内存回收算法暂时豁免,除非,内存实在已经紧张的不行了。在 3.4 版本中被移除了。
OOM
虽然 OOM killer 有时候可能导致严重的损失,但总比系统完全崩溃要好。这个无辜的 bad process 可不是随便挑的,应该优先选择这些:
- 占有 page frames 比较多的,占有的多释放的才多,kill 掉才有意义
- 静态优先级比较低的
而不能选择这些:
- 内核线程,因为内核线程往往执行的都是比较关键的任务
- 进程号为 1 的 init 进程。如果父进程退出,而它的一个或多个子进程还在运行,那么这些子进程将被 init 进程托管,kill 掉 init 进程是内核不允许的行为
- 直接访问硬件设备的进程,如果强行终结这样的进程,可能将硬件置于一个不确定的状态
Refault Distance 算法
在学术界和 Linux 内核社区,页面回收算法的优化一直没有停止过,其中 Refault Distance 算法在 Linux3.15 内核中加入,作者是社区专家 Johannes Weiner,该算法目前只针对页面高速缓存类型的页面。 如下图所示,对于内容缓存类型的 LRU 链表来说,有两个链表值得关注,分别是活跃 LRU 链表和不活跃 LRU 链表。新产生的页面总是被添加到不活跃 LRU 链表的头部,页面回收也总是从不活跃 LRU 链表的尾部开始。不活跃 LRU 链表的页面第二次访问时会升级(promote)为活跃 LRU 链表的页面,防止被回收;另一方面,如果活跃 LRU 链表增长太快,那么活跃页面也会被降级(demote)到不活跃 LRU 链表中。 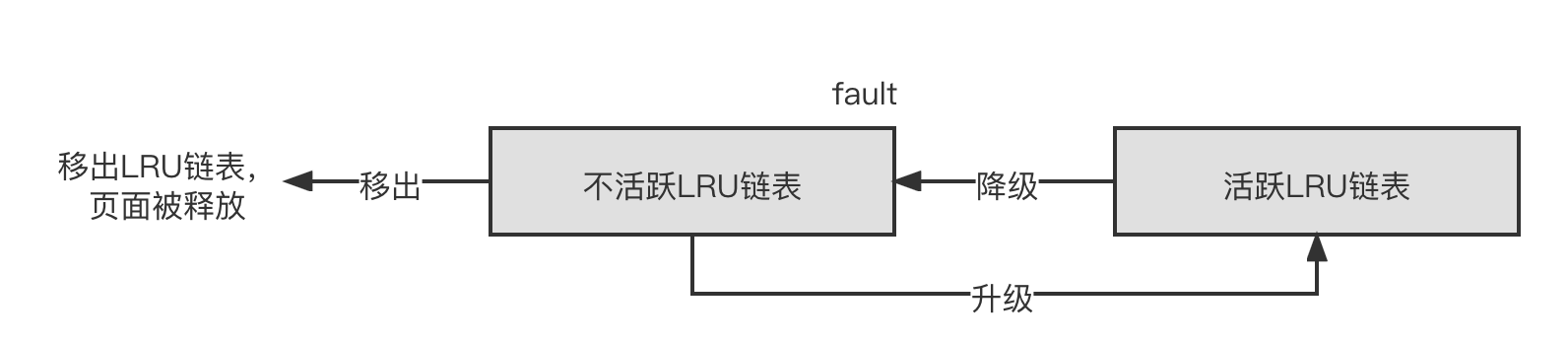
实际上,一些场景下,某些页面经常被访问,但是在下一次访问之前在不活跃 LRU 链表中回收并释放了它们,因此须从存储系统中读取这些内容缓存页面,这会产生颠簸(thrashing)现象。当我们观察文件缓存中不活跃 LRU 链表的行为特征时,会发现如下有趣特征。
- 第一次访问一个文件缓存页面时,它被添加到不活跃 LRU 链表头,然后慢慢从链表头向链表尾方向移动,链表尾的内容缓存会被移出 LRU 链表且释放页面,这个过程叫作移出
- 当第二次访问时,页面高速缓存被升级为活跃 LRU 链表中的页面高速缓存,这样不活跃 LRU 链表也空出一个位置,在不活跃 LRU 链表的页面整体移动了一个位置,这个过程叫作激活
- 从宏观时间轴来看,移出过程处理的页面数量与激活过程处理的页面数量的总和等于不活跃 LRU 链表的长度 NR_inactive
- 要从不活跃 LRU 链表中释放一个页面,需要移动 N 个页面(N 表示不活跃链表长度)
综合上面的一些行为特征,定义了 Refault Distance 的概念。第一次访问内容缓存称为 fault,第二次访问该页称为 refault。内容缓存页面第一次被移出 LRU 链表并回收的时刻称为 E,第二次再访问该页面的时刻称为 R,那么 R-E 的时间里需要移动的页面个数称为 Refault Distance。
Refault Distance 概念再加上第一次访问的时刻,可以用一个公式来概括第一次和第二次访问的间隙(read distance)。
read_distance=nr_inactive + (R - E)如果页面想一直保持在 LRU 链表中,那么 read_distance 不应该比内存的大小还大;否则,该页面永远会被移出 LRU 链表。因此,下式成立。
NR_inactive + (R - E) ≤ NR_inactive + NR_active
(R - E) ≤ NR_active换句话说,Refault Distance 可以理解为不活跃 LRU 链表的“财政赤字”。如果不活跃 LRU 链表的长度至少再延长到 Refault Distance,就可以保证该内容缓存在第二次访间之前不会被移出 LRU 链表并释放内存:否则,就要把该内容缓存重新加入活跃 LRU 链表加以保护,以防颠簸。在理想情况下,内容缓存的平均访问间隙要大于不活跃 LRU 链表的大小、小于总的内存大小。 上述内容讨论了两次读的间隙小于或等于内存大小的情况,即 NR_inactive+(R-E)≤ NR_inactive - NR_active。如果两次读的间隙大于内存大小呢?这种特殊情况不是 Refault Distance 算法能解决的,因为它在第二次访问时己经永远被移出 LRU 链表,可以假设第二次访向发生在遥远的末来,但谁都无法保证它在 LRU 链表中。其实 Refault Distance 算法用于在第二次访问时,人为地把内容缓存添加到活跃 LRU 链表中,从而防止该内容缓存被移出 LRU 链表而带来的内存颠簸。
Refault Distance:算法如下图所示。T0 时刻表示第一次访问一个内容缓存这时会调用 add_to_page_cache_lru 而配一个 shadow 来存储 zone->inactive_age 值。每当有页面被升级为活跃 LRU 链表中的页面时,zone->inactive_age 值会加 1 每当有面被移出不活跃 LU 表时,zone->inactive_age 值也加 1. T1 时刻,该页面被移出 LRU 链表并从 LRU 链表中回收释放因此把当前 T1 时刻的 zone->inactive_age 的值编码存放到 shadow 中。T2 时刻,第二次访问该页面,因此要计算 Refault Distance,Refault Distance:=T2-T1,如果 Retault Distances ≤ NR_active. 说明该内容缓存极有可能在下一次读时已经被移出 LRU 链表,因此要人为地激活该页面并且将其加入活跃 LRU 链表中。 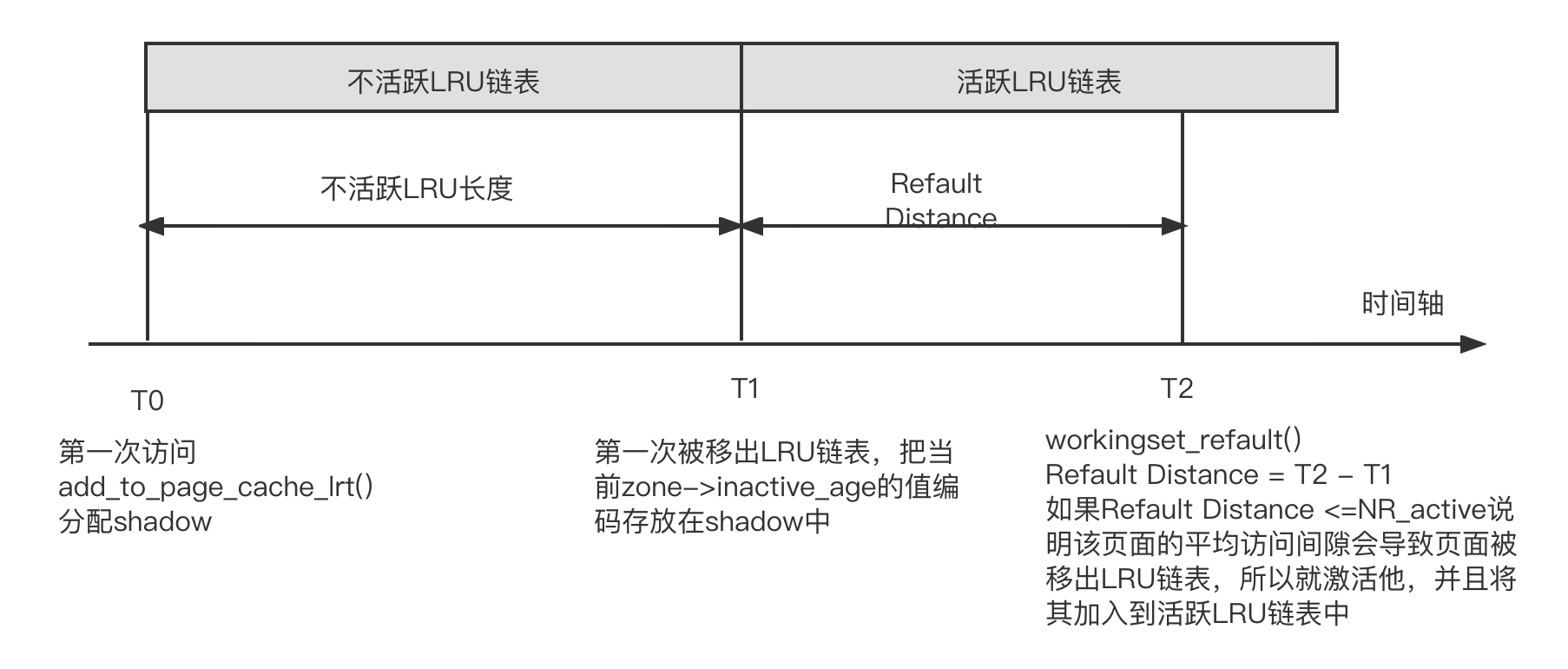
参考文献
https://zhuanlan.zhihu.com/p/70964195
https://zhuanlan.zhihu.com/p/72998605
《奔跑吧 Linux 内核》