Linux 并发与同步(一)自旋锁
 原图
原图
经典自旋锁
如果临界区中只有一个変量,那么原子变量可以解決问题,但是临界区有一个数据操作的集合,需要通过锁机制来保障,自旋锁( spinlock)是 Linux 内核中最常见的锁机制。
- 忙等待的锁机制。操作系统中锁的机制分为两类,一类是忙等待,另一类是睡眠等待
- 同一时刻只能有一个内核代码路径可以获得该锁
- 要求自旋锁持有者尽快完成临界区的执行任务,特别是自旋锁临界区里不能睡眠
- 自旋锁可以在中断上下文中使用
自旋锁的实现
先看 spinlock 数据结构的定义:
1 | <include/linux/spinlock_types.h> |
spinlock 数据结构的定义既考虑到了不同处理器架构的支持和实时性内核的要求,还定义了 raw_spinlock 和 arch_spinlock_t 数据结构,其中 arch_spinlock_t 数据结构和架构有关。在 Linux2.6.25 内核之前, spinlock 数据结构就是一个简单的无符号类型变量。若 slock 值为 1,表示锁未被持有;若为 0,表示锁被持有。这会存在两个严重问题,不公平和效率低下。因此在 Liux2.6.25 内核后,自旋锁实现了“基于排队的 FIFO”算法的自旋锁机制,称为基于排队的自旋锁。
基于排队的自旋锁仍然使用原来的数据结构,但 slock 域被拆分成两个部分,如下图: 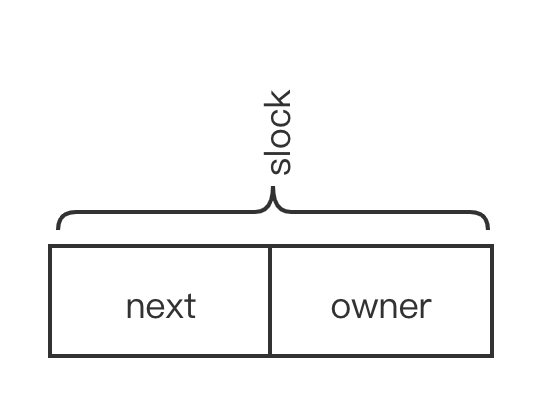
owner 表示自旋锁持有者的牌号,next 表示外面排队的队列中末尾者的牌号。当有线程要获取锁时 next++,当持有锁的线程释放锁时 owner++。当 owner 和 next 相等时,该线程将获得自旋锁。
自旋锁的原型定义在 include/linux/spinlock.h 头文件中。
1 | <include/linux/spin_lock. h> |
spin_locke 函数最终调用 __raw_spin_lock() 函数来实現。首先关闭内核抢占,这是自旋锁实现的关键点之一。那么为什么自旋锁临界区中不允许发生抢占呢?如果自旋锁临界区中允许抢占,假设在临界区内发生中断,中断返回时会检查抢占调度,这里将有两个问题、一是抢占调度会导致持有锁的进程睡眠,这违背了自旋锁不能睡眠和快速执行完成的设计语义;二是抢占调度进程也可能会申请自旋锁,这样会导致发生死锁。
自旋锁的变体
在驱动中很多操作都需要访问和更新链表,如 open、 ioctl 等,因此操作链表的地方就是一个临界区,需要自旋锁来保护。若在临界区中发生了外部硬件中断,系统暂停当前进程的执行转而处理该中断。假设中断处理程序恰巧也要操作该链表,链表的操作是一个临界区,所以在操作之前要调用 spin_lock() 函数来对该链表进行保护。中断处理程序试图获取该自旋锁,但因为它己经被其他 CPU 持有了,于是中断处理程序进入忙等待状态或者 wfe 睡眠状态。在中断上下文中出现忙等待或者睡眠状态是致命的,中断处理程序要求“短”和“快”,自旋锁的持有者因为被中断打断而不能尽快释放锁,而中断处理程序一直在忙等待该锁,从而导致死锁的发生。 Linux 内核的自旋锁的变体 spin_lock_irq() 函数通过在获取自旋锁时关闭本地 CPU 中断,可以解决该问题。
1 | static __always_inline void spin_lock_irq(spinlock_t *lock) |
spin_lock_irq() 函数的实现比 spin_lock() 函数多了一个 local_irq_disable() 函数。local_irq_disable() 函数用于关闭本地处理器中断,这样在获取自旋锁时可以确保不会发生中断,从而避免发生死锁问题,即 local_irq_disable() 函数主要防止本地中断处理程序和自旋锁持有者之间产生锁的争用。
可能有的读者会有疑问,既然关闭了本地 CPU 的中断,那么别的 CPU 依然可以响应外部中断,这会不会也可能导致死锁呢?自旋锁持有者在 CPUO 上,CPU1 响应了外部中断且中断处理程序同样试图去获取该锁,因为 CPU0 上的自旋锁持有者也在继续执行,所以它很快会离开临界区并释放锁,这样 CPU1 上的中断处理程序可以很快获得该锁。
自旋锁还有另外一个常用的变体-- spin_lock_bh() 函数,用于处理进程和延迟处理机制导致的并发访问的互斥问题。
spin_lock() 和 raw_spin_lock() 函数
这要从 Linux 内核的实时补丁( Rt-patch)说起。实时补丁旨在提升 Linux 内核的实时性它允许在自旋锁的临界区内抢占锁,且在临界区内允许进程睡眠。这样会导致自旋锁语义被修改。当时内核中大约有 10000 处使用了自旋锁,直接修改自旋锁的工作量巨大,但是可以修改那些真正不允许抢占和睡眠的地方,大概有 100 处,因此改为使用 raw_spin_lock()。
spin_lock() 和 raw_spin_lock() 函数的区别如下:
- 在绝对不允许抢占和睡眠的临界区,应该使用 raw_spin_lock() 函数,否则使用 spin_lock()。
- 对于没有更新实时补丁的 Linux 内核来说,spin_lock() 函数可以直接调用 raw_spin_lock(),对于更新实时补丁的 Linux 内核来说, spin_lock() 会变成可抢占和睡眠的锁,这需要特别注意。
效率
根据硬件维护的 cache 一致性协议,如果 spinlock 的值没有更改,那么在 busy wait 时,试图获取 spinlock 的 CPU,只需要不断地读取自己包含这个 spinlock 变量的 cache line 上的值就可以了,不需要从 spinlock 变量所在的内存位置读取。
但是,当 spinlock 的值被更改时,所有试图获取 spinlock 的 CPU 对应的 cache line 都会被 invalidate,因为这些 CPU 会不停地读取这个 spinlock 的值,所以"invalidate"状态意味着此时,它们必须重新从内存读取新的 spinlock 的值到自己的 cache line 中。
而事实上,其中只会有一个 CPU,也就是队列中最先达到的那个 CPU,接下来可以获得 spinlock,也只有它的 cache line 被 invalidate 才是有意义的,对于其他的 CPU 来说,这就是做无用功。内存比 cache 慢那么多,开销可不小。
MCS 锁
假设在一个锁争用激烈的系统中,所有等待自旋锁的线程都在同一个共享变量上自旋,申请和释放锁都在同一个变量上修改,高速内存一致性原理(如 MESI 协议)导致参与自旋的 CPU 中的高速缓存行变得无效。在锁争用的激烈过程中,可能导致严重的 CPU 高速缓存行颠簸现象( CPU cacheline bouncing),即多个 CPU 上的高速缓存行反复失效,大大降低系统整体性能。
MCS 算法可以解决自旋锁遇到的问题,显著缓解 CPU 高速缓存行颠簸问题。
MCS 算法的核心思想是每个锁的申请者只在本地 CPU 的变量上自旋,而不是全局的变量上,大大降低锁的争用。
OSQ 锁
早期 MCS 算法的实现需要比较大的数据结构,在 Linux4.2 内核中引进了基于 MCS 算法的排队自旋锁(One Spinlock, Qspinlock)OSQ 锁的实现需要两个数据结构:
1 | <include/linux/osq_lock.h> |
每个 MCS 锁有一个 optimistic_spin_queue 数据结构,该数据结构只有一个成员 tail, 初始化为 0。 optimistic_spin_node 数据结构表示本地 CPU 上的节点,它可以组织成一个双向链表包含 next 和 prev 指针, locked 成员用于表示加锁状态,cpu 成员用于重新编码 CPU 编号,表示该节点在哪个 CPU 上。 optimistic_spin_node 数据结构会定义成 per-CPU 变量,即每个 CPU 有一个节点结构。
1 | <kernel/locking/osq_lock.c> |
MCS 锁在 osq_lock_init() 函数中初始化。如互斥锁会初始化为一个 MCS 锁,因为 __mutex_init() 函数会调用 osq_lock_init() 函数
1 | <kernel/locking/mutex.c> |
OSQ 自旋锁的特点:
- 集成 MCS 算法到自旋锁中,继承了 MCS 算法的所有优点,有效解决了 CPU 高速缓存行颠簸问题。
- 没有增加 spinlock 数据结构的大小,把 val 细分成多个域,完美实现了 MCS 算法。
- 当只有两个 CPU 试图获取自旋锁时,使用 pending 域就可以完美解决问题,第 2CPU 只需要设置 pending 域,然后自旋等待锁释放。当有第 3 个或者更多 CPU 来争用时,则需要使用额外的 MCS 节点。第 3 个 CPU 会自旋等待锁被释放,即 pending 域和 locked 域被清零,而第 4 个 CPU 和后面的 CPU 只能在 MCS 节点中自旋等待 locked 域被置 1,直到前继节点把 locked 控制器过继给自己才能有机会自旋等待自旋锁的释放,从而完美解决激烈锁争用带来的高速缓存行颠簸问题 16 信号量。
- 解决 MCS 锁占内存大的问题。
参考文献
《奔跑吧 Linux 内核》
https://zhuanlan.zhihu.com/p/80727111
https://zhuanlan.zhihu.com/p/89058726
https://zhuanlan.zhihu.com/p/100546935