Linux 进程管理(二)进程的创建和终止
 原图
原图
概述
最新版本的 POSIX 标准中定义了进程创建和终止的操作系统层面的原语。进程创建包括 fork() 和 execve() 函数族,进程终止包括 wait()、waitpid()、kill() 以及 exit() 函数族。Linux 在实现过程中为了提高效率,把 POSIX 标准的 fork 原语扩展成了 vfork 和 clone 两个原语。
我们最常见的一种场景是在 shell 界面中输入命令,然后等待命令返回,如图所示: 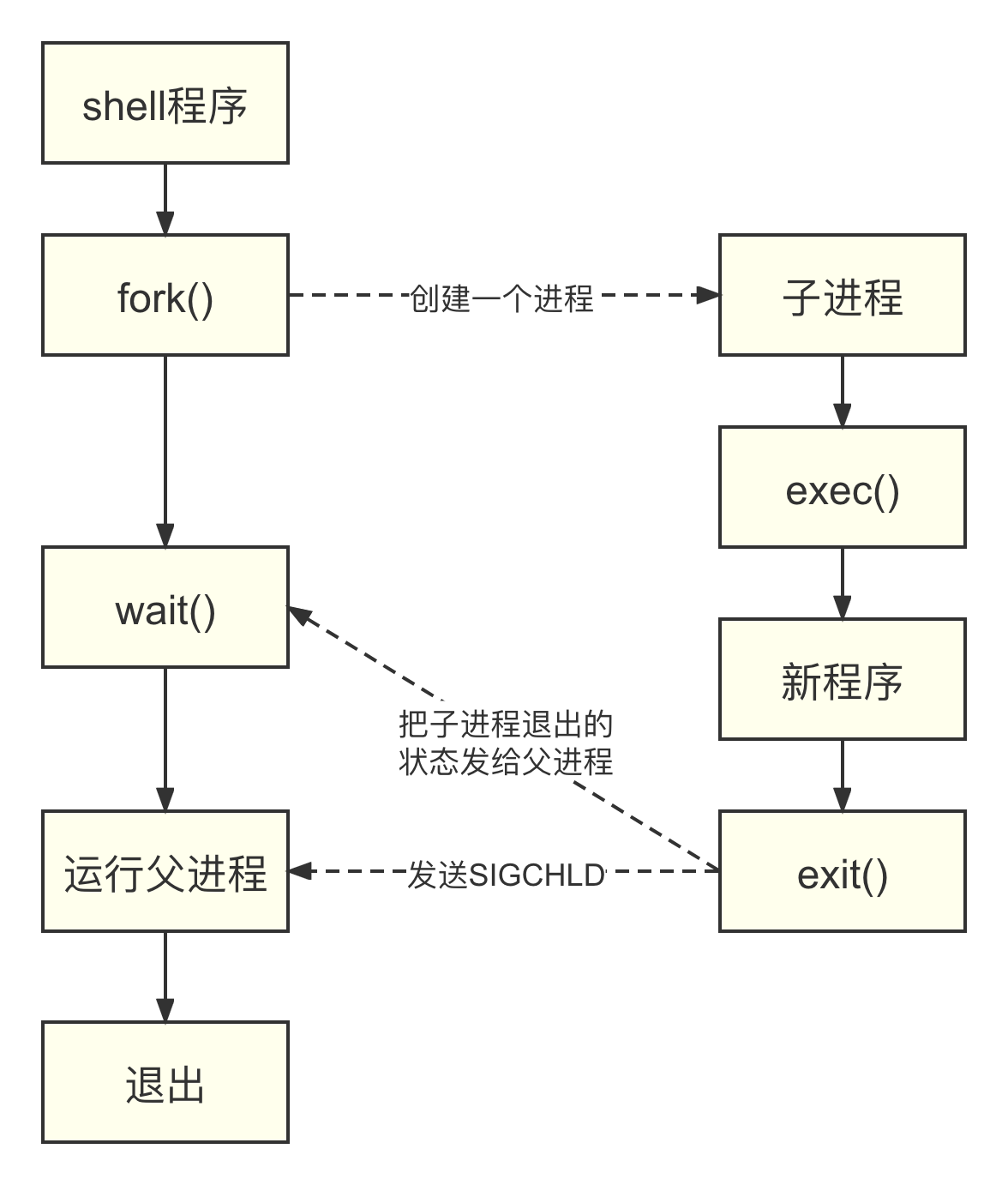
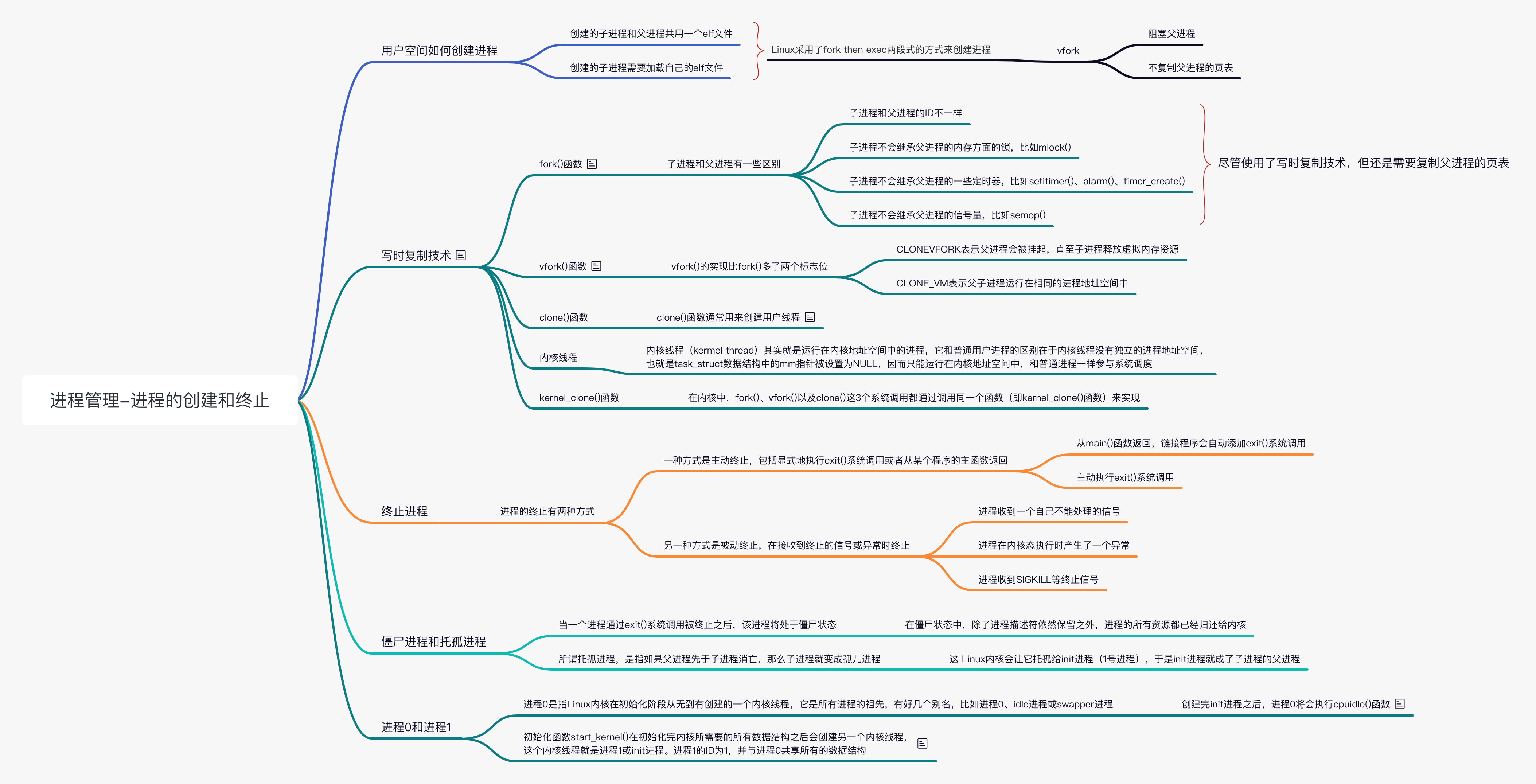
用户空间如何创建进程
应用程序在用户空间创建进程有两种场景:
- 创建的子进程和父进程共用一个 elf 文件:这种情况适合于大多数的网络服务程序
- 创建的子进程需要加载自己的 elf 文件:例如 shell
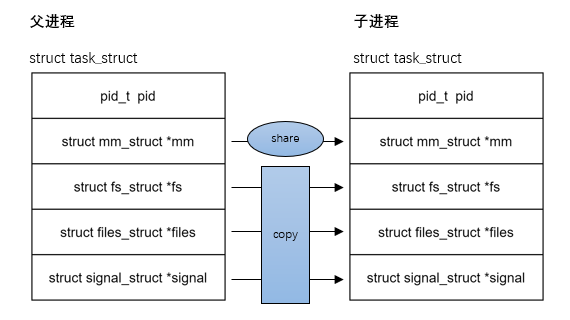
应用程序可以通过 fork 系统调用创建进程,fork 之后,子进程复制了父进程的绝大部分的资源(文件描述符、信号处理、当前工作目录等)。完全复制父进程的资源的开销非常大且没有什么意义,特别是对于场景 2。不过,在引入 COW(copy-on-write) 技术后,fork 的开销其实也不算特别大,大部分的 copy 都是通过 share 完成的,主要的开销集中在复制父进程的页表上。linux 还提供了 vfork 函数,vfork 和 fork 是类似的,除了下面两点:
- 阻塞父进程
- 不复制父进程的页表
之所以 vfork 要阻塞父进程是因为 vfork 后父子进程使用的是完全相同的 memory descriptor, 也就是说使用的是完全相同的虚拟内存空间,包括栈也相同。所以两个进程不能同时运行,否则栈就乱掉了。除了 fork 和 vfork,Linux 内核还提供的 clone 的系统调用接口主要用于线程的创建。其实通过传递不同的参数,clone 接口可以实现 fork 和 vfork 的功能。
创建进程
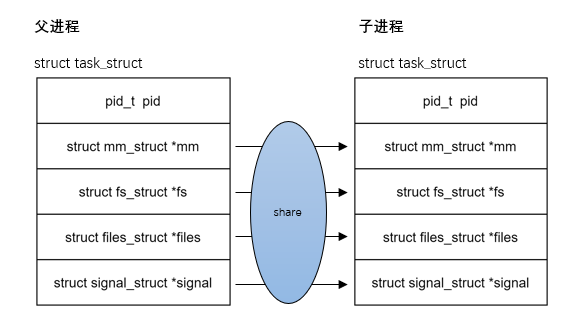
现代操作系统都采用写时复制(Copy On Write,cow)技术。写时复制技术就是父进程在创建子进程时不需要复制进程地址空间的内容给子进程,只需要复制父进程的进程地址空间的页表给子进程,这样父子进程就可以共享相同的物理内存。当父子进程中有一方需要修改某个物理页面的内容时,触发写保护的缺页异常,然后才把共享页面的内容复制出来,从而让父子进程拥有各自的副本,如图所示: 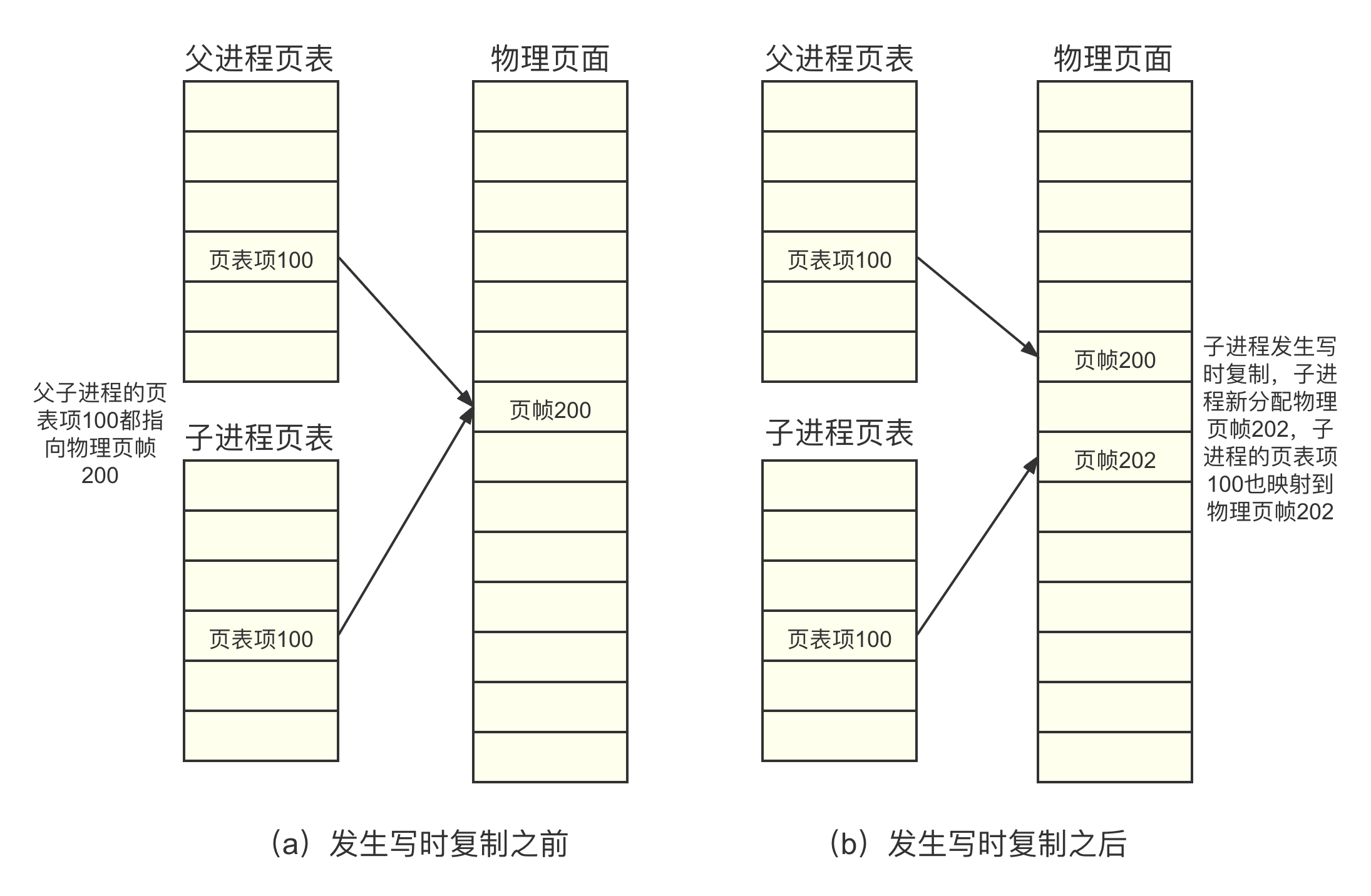
fork() 函数
如果使用 fork() 函数来创建子进程,子进程和父进程将拥有各自独立的进程地址空间,但是共享物理内存资源,包括进程上下文、进程栈、内存信息、打开的文件描述符、进程优先级、资源限制等。在创建期间,子进程和父进程共享物理内存空间,当它们开始运行各自的程序时,它们的进程地址空间开始分道扬镳,这得益于写时复制技术的优势。子进程和父进程有如下一些区别。
- 子进程和父进程的 ID 不一样
- 子进程不会继承父进程的内存方面的锁,比如 mlock()
- 子进程不会继承父进程的一些定时器,比如 setitimer()、alarm()、timer_create()
- 子进程不会继承父进程的信号量,比如 semop()
尽管使用了写时复制技术,但还是需要复制父进程的页表,在某些场景下会比较慢,所以有了后来的 vfork 原语和 clone 原语。
vfork() 函数
vfork() 函数通过系统调用进入 Linux 内核,然后通过 kernel_clone() 函数来实现。
1 | SYSCALL_DEFINE0(vfork) |
vfork() 的实现比 fork() 多了两个标志位,分别是 CLONE_VFORK 和 CLONE_VM。CLONE_VFORK 表示父进程会被挂起,直至子进程释放虚拟内存资源。CLONE_VM 表示父子进程运行在相同的进程地址空间中。vfork() 的另一个优势是连父进程的页表项复制动作也被省去了。
clone() 函数
clone() 函数通常用来创建用户线程。clone() 函数功能强大,可以传递众多参数,可以有选择地继承父进程的资源,比如可以和 vfork() 一样与父进程共享进程地址空间,从而创建线程;也可以不和父进程共享进程地空间,甚至可以创建兄弟关系进程。
1 | /*glibc 库的封装*/ |
以 glibc 封装的 clone() 函数为例,fn 是子进程执行的函数指针;child_stack 用于为子进程分配栈;flags 用于设置 clone 标志位,表示需要从父进程继承哪些资源;arg 是传递给子进程的参数。clone() 函数通过系统调用进入 Linux 内核,然后通过 kernel_clone() 函数来实现。
1 | SYSCALL_DEFINE5(clone, unsigned long, clone_flags, unsigned long, newsp, |
内核线程
内核线程(kermel thread)其实就是运行在内核地址空间中的进程,它和普通用户进程的区别在于内核线程没有独立的进程地址空间,也就是 task_struct 数据结构中的 mm 指针被设置为 NULL,因而只能运行在内核地址空间中,和普通进程一样参与系统调度。所有的内核线程都共享内核地址空间。常见的内核线程有页面回收线程“kswapd”等。Linux 内核提供了多个接口函数来创建内核线程。
1 |
kthread_create() 接口函数创建的内核线程被命名为 namefmt。新建的内核线程将运行 threadfn() 函数。新建的内核线程处于不可运行状态,需要调用 wake_up_process() 函数来将其唤醒并添加到就绪队列中,要创建一个马上可以运行的内核线程,可以使用 kthread_run() 函数。内核线程最终还是通过 kernel_clone() 函数来实现。
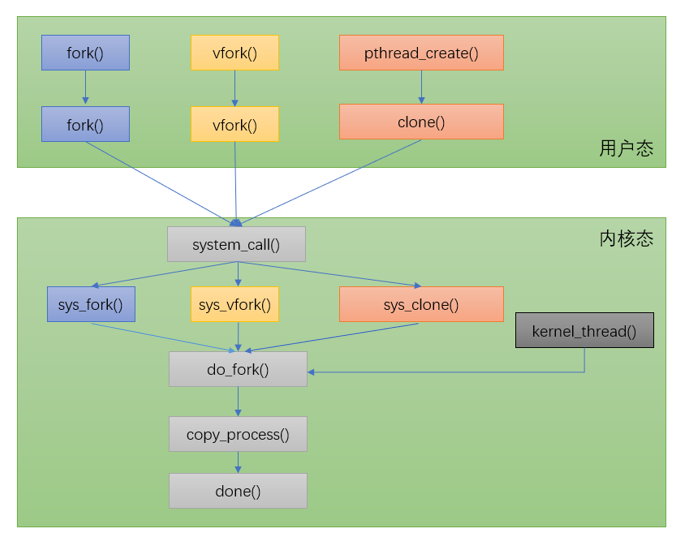
在内核中,fork()、vfork() 以及 clone() 这 3 个系统调用都通过调用同一个函数即 kernel_clone() 函数来实现,该函数定义在 fork.c 文件中,感兴趣的可以自行查看,这个函数最终调用调用 copy_process 函数。
fork、vfork 和 pthread_create 区别
fork:
vfork:
pthread_create:
do_fork 实现:
终止进程
进程的终止有两种方式:一种方式是主动终止,包括显式地执行 exit() 系统调用或者从某个程序的主函数返回;另一种方式是被动终止,在接收到终止的信号或异常时终止。
当一个进程终止时,Linux 内核会释放它所占有的资源,并把这条消息告知父进程。一个进程的终止可能有两种情况。
- 它有可能先于父进程终止,这时子进程会变成僵尸进程,直到父进程调用 wait() 才算最终消亡
- 它也有可能在父进程之后终止,这时 init 进程将成为子进程新的父进程
僵尸进程和托孤进程
当一个进程通过 exit() 系统调用被终止之后,该进程将处于僵尸状态。在僵尸状态中,除了进程描述符依然保留之外,进程的所有资源都已经归还给内核。Linux 内核这么做是为了让系统可以知道子进程的终止原因等信息,因此进程终止时所需要做的清理工作和释放进程描述符是分开的。当父进程通过 wait() 系统调用获取了已终止的子进程的信息之后,内核才会释放子进程的 task_struct 数据结构。
所谓托孤进程,是指如果父进程先于子进程消亡,那么子进程就变成孤儿进程,这时 Linux 内核会让它托孤给 init 进程(1 号进程),于是 init 进程就成了子进程的父进程。
进程 0 和进程 1
进程 0 是指 Linux 内核在初始化阶段从无到有创建的一个内核线程,它是所有进程的祖先,有好几个别名,比如进程 0、idle 进程或 swapper 进程。进程 0 的进程描述符是在 init/init_task.c 文件中静态初始化的。
初始化函数 start_kernel() 在初始化完内核所需要的所有数据结构之后会创建另一个内核线程,这个内核线程就是进程 1 或 init 进程。与进程 0 共享所有的数据结构。
1 | noinline void __ref rest_init(void) |
进程 1 会执行 kernel_init() 函数,它会通过 execve() 系统调用装入可执行程序 init(“sbin/init”,“/bin/init”或“bin/sh”),进程 1 变成一个用户进程,是内核启动的第一个用户级进程。init 有许多很重要的任务,比如像启动 getty(用于用户登录)、实现运行级别、以及处理孤立进程。进程 1 在从内核线程变成普通进程 init 之后,它的主要作用是根据/etc/inittab 文件的内容启动所需要的任务,包括初始化系统配置、启动一个登录对话等。
当检测到来自终端的连接信号时,getty 进程将通过函数 do_execve() 执行注册程序 login,此时用户就可输入注册名和密码进入登录过程,如果成功,由 login 程序再通过函数 execv() 执行 shell,该 shell 进程接收 getty 进程的 pid,取代原来的 getty 进程。再由 shell 直接或间接地产生其他进程。
上述过程可描述为:0 号进程->1 号内核进程->1 号用户进程(init 进程)->getty 进程->shell 进程
参考文献
http://www.wowotech.net/process_management/Process-Creation-1.html
https://blog.csdn.net/qq_20817327/article/details/108289647
https://cloud.tencent.com/developer/article/1842307
《奔跑吧 Linux 内核》
《Linux 内核设计与实现》