C++(一)对象模型
 原图
原图
对象模式
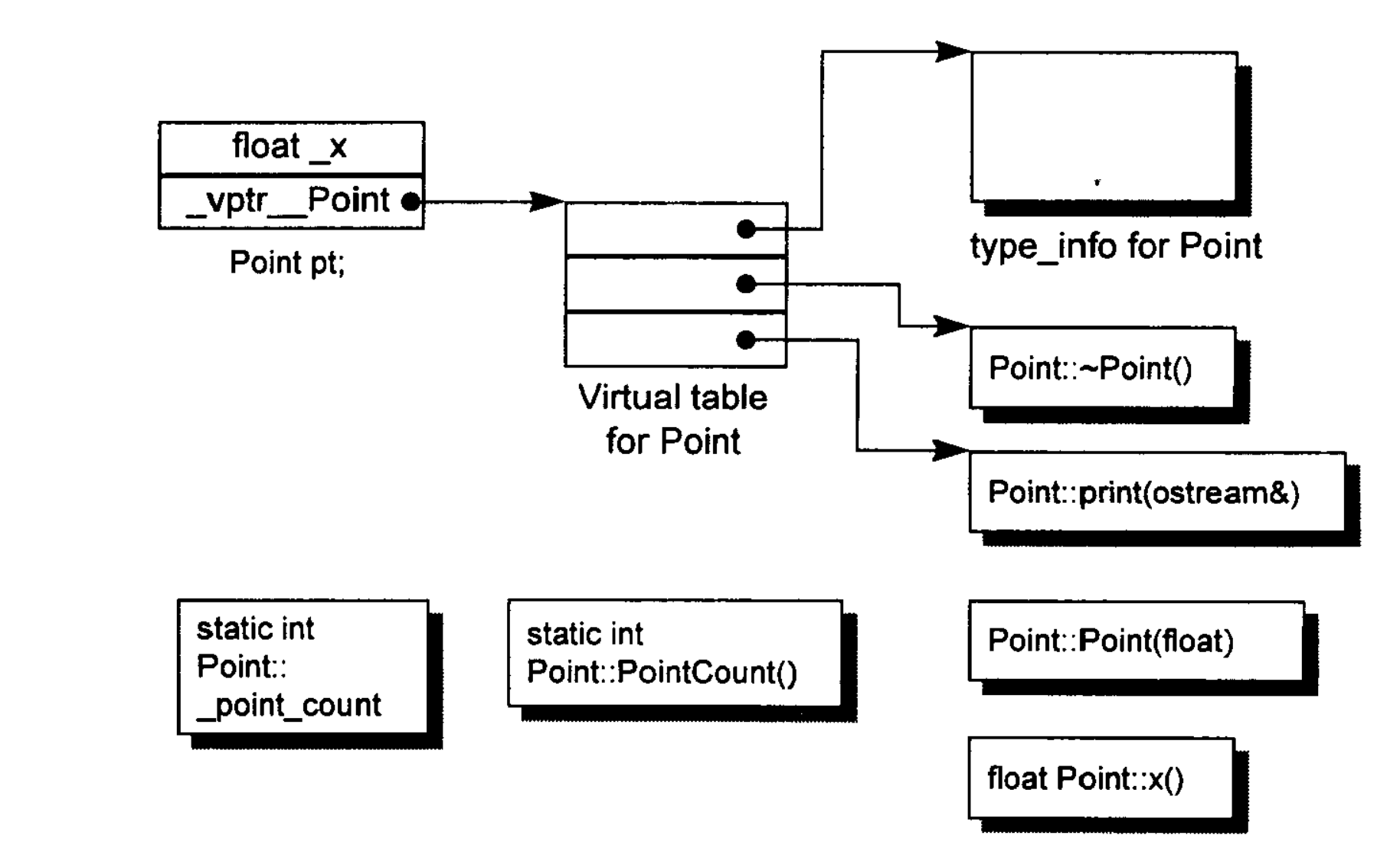
在 C++中,有两种 class data members:static 和 nonstatic,以及三种 class member functions:static、nonstatic 和 virtual。已知下面这个 class Point 声明:
1 | class Point { |
这个 class Point 在机器中将会被怎么样表现呢?也就是说,我们如何模塑(modeling)出各种 data members 和 function members 呢?
C++对象模型(The C++ Object Model)
Stroustrup 当初设计的 C++对象模型是从简单对象模型派生而来的,并对内存空间和存取时间做了优化。在此模型中:
- Nonstatic datamembers 被配置于每一个 class object 之内。
- static data members 则被存放在所有的 class object 之外(data 段或 bss 段)。
- Static 和 nonstatic function members 也被放在所有的 class object 之外(代码段)。
- Virtual functions 则以两个步骤支持之:
- 每一个 class 产生出一堆指向 virtual functions 的指针,放在表格之中。这个表格被称为 virtual table(vtbl)
- 每一个 class object 被添加了一个指针,指向相关的 virtual table。通常这个指针被称为 vptr。vptr 的设定(setting)和重置(resetting)都由每一个 class 的 constructor、destructor 和 copy assignment 运算符自动完成。每一个 class 所关联的 type_info object(用以支持:runtime type identifcation,RTTI)也经由 virtual table 被指出来,通常是放在表格的第一个 slot 处
加上继承(Adding Inheritance)
单一继承:
1 | class Library_materials {...} |
多重继承:
1 | //原本的(更早于标准版的)iostream 实现方式 |
甚至,继承关系也可以指定为虚拟(virtual,也就是共享的意思):
1 | class istream : virtual public ios {...} |
在虚拟继承的情况下,base class 不管在继承串链中被派生(derived)多少次,永远只会存在一个实体(称为 subobject)。例如 iostream 之中就只有 virtual ios base class 的一个实体。 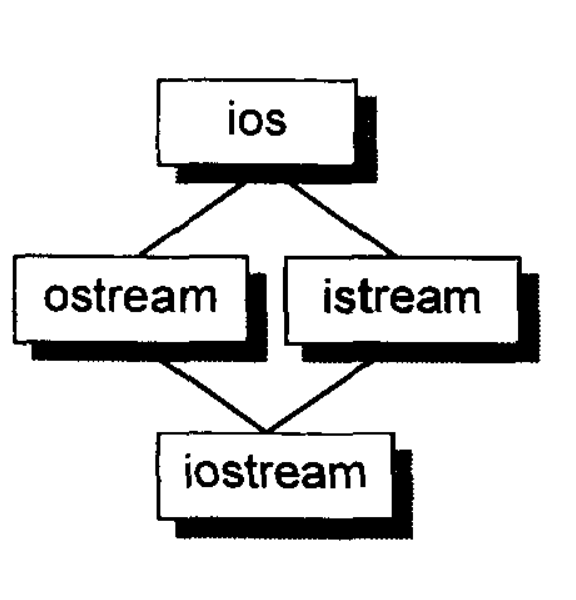
base class table 被产生出来时,表格中的每一个 slot 内含一个相关的 base class 地址,这很像 virtual table 内含每一个 virtual function 的地址一样。每一个 class object 内含一个 bptr,它会被初始化,指向其 base class table。
- 缺点:主要缺点是由于间接性而导致的空间和存取时间上的额外负担,
- 优点:
- 在每一个 class object 中对于继承都有一致的表现方式:每一个 class object 都应该在某个固定位置上安放一个 base table 指针,与 base classes 的大小或数目无关
- 不需要改变 class objects 本身,就可以放大、缩小、或更改 base class table

需要多少内存才能够表现一个 class object?一般而言要有:
- 其 nonstatic data members 的总和大小。
- 加上任何由于 alignment 的需求而填补(padding)上去的空间。
- 加上为了支持 virtual 而由内部产生的任何额外负担(overhead)。
构造函数语义学
Default Constructor 的建构操作
C++ Standard【ISO-C++95】的 Section12.1 这么说: 对于 class X,如果没有任何 user-declared constructor,那么会有一个 default constructor 被暗中(implicitly)声明出来。一个被暗中声明出来的 default constructor 将是一个 trivial(浅薄而无能,没啥用的)constructor。
C++ Standard 然后开始叙述在什么样的情况下这个 implicit default constructor 会被视为 trivial。一个 nontrivial default constructor 在 ARM 的术语中就是编译器所需要的那种,必要的话会由编译器合成出来。下面分别讨论 nontrivial default constructor 的四种情况。
带有 Default Constructor 的 Member Class Object
如果一个 class 没有任何 constructor,但它内含一个 member object,而后者有 default constructor,那么这个 class 的 implicit default constructor 就是“nontrivial'”,编译器需要为此 class 合成出一个 default constructor。
- 在 C++各个不同的编译模块中,编译器如何避免合成出多个 default constructor 呢?解决方法是把合成的 default constructor、copy constructor、destructor、assignment copy operator 都以 inline 方式完成。一个 inline 函数有静态链接(static linkage),不会被档案以外者看到。如果函数太复杂,不适合做成 inline,就会合成出一个 explicit non-inline static 实体
- “如果 class A 内含一个或一个以上的 member class objects,那么 class A 的每一个 constructor 必须调用每一个 member classes 的 default constructor”。编译器会扩张已存在的 constructors,在其中安插一些代码,使得 user code 在被执行之前,先调用必要的 default constructors
- 如果有多个 class member objects 都要求 constructor 初始化操作,将如何呢?C++语言要求以“member objects 在 class 中的声明次序”来调用各个 constructors
带有 Default Constructor 的 Base Class
类似的道理,如果一个没有任何 constructors 的 class 派生自一个“带有 default constructor'”的 base class,那么这个 derived class 的 default constructor 会被视为 nontrivial,并因此需要被合成出来。它将调用上一层 base classes 的 default constructor(根据它们的声明次序)。
如果设计者提供多个 constructors,但其中都没有 default constructor 呢?编译器会扩张现有的每一个 constructors,将“用以调用所有必要之 default constructors”的程序代码加进去。它不会合成一个新的 default constructor,这是因为其它“由 user 所提供的 constructors”存在的缘故。
如果同时亦存在着“带有 default constructors”的 member class objects,那些 default constructor 也会被调用-—在所有 base class constructor 都被调用之后。
带有一个 Virtual Function 的 Class
- class 声明(或继承)一个 virtual function
- class 派生自一个继承串链,其中有一个或更多的 virtual base classes
不管哪一种情况,由于缺乏由 user 声明的 constructors,编译器会详细记录合成一个 default constructor 的必要信息。
- 一个 virtual function table(在 cfront 中被称为 vtbl)会被编译器产生出来,内放 class 的 virtual functions 地址
- 在每一个 class object 中,一个额外的 pointer member(也就是 vptr)会被编译器合成出来,内含相关的 class vtbl 的地址
带有一个 Virtual Base Class 的 Class
Virtual base class 的实现法在不同的编译器之间有极大的差异。然而,每一种实现法的共通点在于必须使 virtual base class 在其每一个 derived class object 中的位置,能够于执行期准备妥当。例如下面这段程序代码中:
1 | class X {public:int i;}; |
原先 cfront 的做法是靠“在 derived class object 的每一个 virtual base classes 中安插一个指针”完成。所有“经由 reference 或 pointer 来存取一个 virtual base class”的操作都可以通过相关指针完成。foo() 可以被改写如下,以符合这样的实现策略:
1 | //可能的编译器转变操作 |
其中__vbcX 表示编译器所产生的指针,指向 virtual base class X。正如你所臆测的那样,__vbcX(或编译器所做出的某个什么东西)是在 class object 建构期间被完成的。对于 class 所定义的每一个 constructor,编译器会安插那些“允许每一个 virtual base class 的执行期存取操作”的码。如果 class 没有声明任何 constructors,编译器必须为它合成一个 default constructor。
Copy Constructor 的建构操作
有三种情况,会以一个 object 的内容作为另一个 class object 的初值。最明显的一种情况当然就是对一个 object 做明确的初始化操作,另两种情况是当 object 被当作参数交给某个函数以及当函数传回一个 class object 时。
Default Memberwise Initialization
如果 class 没有提供一个 explicit copy constructor 又当如何?当 class object 以“相同 class 的另一个 object”作为初值时,其内部是以所谓的 default memberwise initializatior 手法完成的,也就是把每一个内建的或派生的 datamember(例如一个指针或数目组)的值,从某个 object 拷贝一份到另一个 object 身上。不过它并不会拷贝其中的 member class object,而是以递归的方式施行 memberwise initializaon。
如果一个 String object 被声明为另一个 class 的 member,像这样:
1 | class Word |
那么一个 Word object 的 default memberwise initialization 会拷贝其内建的 member _occurs,然后再于 String member object_word 身上递归实施 memberwise initialization
就像 default constructor 一样,C++ Standard 上说,如果 class 没有声明一个 copy constructor,就会有隐含的声明(implicitly declared)或隐含的定义(implicitlydefined)出现。和以前一样,C++Standard 把 copy constructor 区分为 trivial 和 nontrivial 两种。只有 nontrivial 的实体才会被合成于程序之中。决定一个 copy constructor 是否为 trivial 的标准在于 class 是否展现出所谓的“bitwise copysemantics'”。
Bitwise Copy Semantics(位逐次拷贝)
在下面的程序片段中:
1 |
|
很明显 verb 是根据 noun 来初始化。但是在尚未看过 class Word 的声明之前,我们不可能预测这个初始化操作的程序行为。如果 class Word 的设计者定义了一个 copy constructor,verb 的初始化操作会调用它。但如果该 class 没有定义 explicit copy constructor,那么是否会有一个编译器合成的实体被调用呢?这就得视该 class 是否展现"bitwise copy semantics'”而定。举个例子,已知下面的 class Word 声明:
1 | //以下声明展现了 bitwise copy semantic |
这种情况下并不需要合成出一个 default copy constructor,因为上述声明展现了“default copy semantics”,而 verb 的初始化操作也就不需要以一个函数调用收场。
一般来说,如果你的 class 仅包含了 POD(Plain Object Data) 这样的,是展现出了 Bitwise Copy Semantics,即编译器在内部可以一个字节一个字节的拷贝(如 memcpy)也不会出现问题。
然而,如果 class Word 是这样声明:
1 | //以下声明并未展现出 bitwise copy semantics |
其中 String 声明了一个 explicit copy constructor:
1 | class String |
在这个情况下,编译器必须合成出一个 copy constructor 以便调用 member class String object 的 copy constructor:
1 | //一个被合成出来的 copy constructor |
有一点很值得注意:在这被合成出来的 copy constructor 中,如整数、指针、数组等等的 nonclass members 也都会被复制,正如我们所期待的一样。
不要 Bitwise Copy Semantics!
什么时候一个 class 不展现出“bitwise copy semantics”呢?有四种情况:
- 当 class 内含一个 member object 而后者的 class 声明有一个 copy constructor 时(不论是被 class 设计者明确地声明,就像前面的 String 那样;或是被编译器合成,像 class Word 那样)。
- 当 class 继承自一个 base class 而后者存在有一个 copy constructor 时(再次强调,不论是被明确声明或是被合成而得)。
- 当 class 声明了一个或多个 virtual functions 时。
- 当 class 派生自一个继承串链,其中有一个或多个 virtual base classes 时。
前两种情况中,编译器必须将 member 或 base class 的“copy constructors 调用操作”安插到被合成的 copy constructor 中。前一节 class Word 的“合成而得的 copy constructor”正足以说明情况 1,2。情况 3 和 4 有点复杂,是我接下来要讨论的题目。
重新设定 Virtual Table 的指针
回忆编译期间的两个程序扩张操作(只要有一个 class 声明了一个或多个 virtual functions 就会如此):
- 增加一个 virtual function table(vtbl),内含每一个有作用的 virtual function 的地址。
- 将一个指向 virtual function table 的指针(vptr),安插在每一个 class object 内。
很显然,如果编译器对于每一个新产生的 class object 的 vptr 不能成功而正确地设好其初值,将导致可怕的后果。因此,当编译器导入一个 vptr 到 class 之中时,该 class 就不再展现 bitwise semantics 了。现在,编译器需要合成出一个 copy constructor,以求将 vptr 适当地初始化。 
yogi 会被 default Bear constructor 初始化。而在 constructor 中,yogi 的 vptr 被设定指向 Bear class 的 virtual table(靠编译器安插的码完成)。因此,把 yogi 的 vptr 值拷贝给 winnie 的 vptr 是安全的。
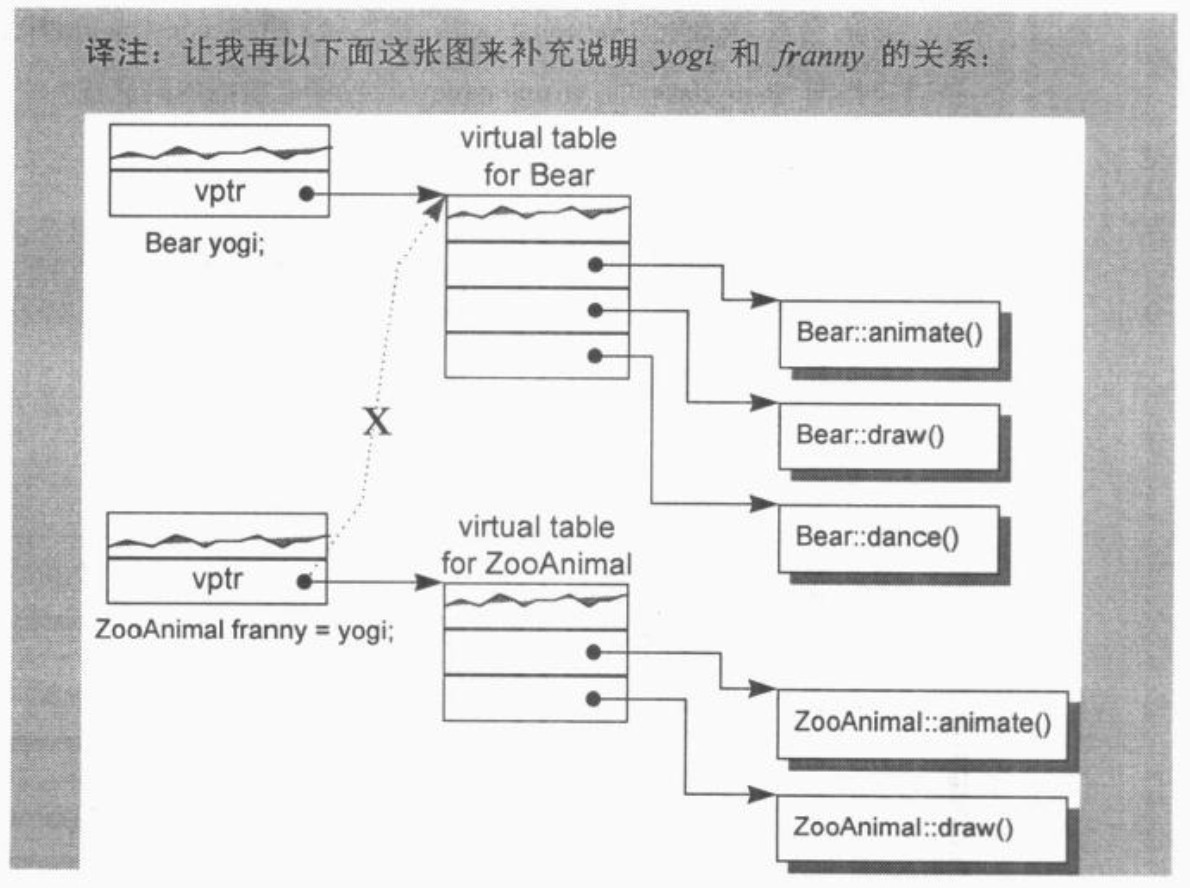 合成出来的 ZooAnimal copy constructor 会明确设定 object 的 vptr 指向 ZooAnimal class 的 virtual table,而不是直接从右手边的 class object 中将其 vptr 现值拷贝过来。
合成出来的 ZooAnimal copy constructor 会明确设定 object 的 vptr 指向 ZooAnimal class 的 virtual table,而不是直接从右手边的 class object 中将其 vptr 现值拷贝过来。
Data 语意学
类对象大小受三个因素影响
- virtual base 和 virtual function 带来的 vptr 影响
- EBO(Empty Base class Optimize)空基类优化处理,EBC(Empty Base Class)占用一个字节,其他含有数据成员的从 EBC 派生的派生类,只会算自己数据成员的大小,不受 EBC 一字节的影响
- alignment 字节对齐
Nonstatic data members
- Nonstatic data members 在 class object 中的排列顺序将和其被声明顺序一样,任何中间介入的 static data members 都不会被放进布局之中
- 每一个 nonstatic data member 的偏移量在编译时即可获知,不管其有多么复杂的派生,都是一样的。通过对象存取一个 nonstatic data member,其效率和存取一个 C struct member 是一样的
- 从对象存取 obj.x 和指针存取 pt->x 有和差异? 当继承链中有虚基类时,查找虚基类的成员变量时延迟到了执行期,根据 virtual class offset 查找到虚基类的部分,效率稍低
静态成员变量 static data members
- 存放在程序的 data segment 之中
- 通过指针和对象来存取 member,完全一样,不管继承或者是虚拟继承得来,全局也只存在唯一一个实例
- 静态常量成员可以在类定义时直接初始化,而普通静态常量成员只能在。o 编译单元的全局范围内初始化
“迷承”与 Data Member
只要继承不要多态(Inheritance without Polymorphism)
1 | class Concrete |

在一部 32 位机器中,每一个 Concrete class object 的大小都是 8 bytes,细分如下:
- val 占用 4 bytes
- c1、c2 和 c3 各占用 1 bytes
- alignment(调整到 word 边界)需要 1 bytes
现在假设,经过某些分析之后,我们决定了一个更逻辑的表达方式,把 Concrete 分裂为三层结构:
1 | class Concrete1 |
Concrete1 内含两个 members:val 和 bit1,加起来是 5 bytes。而一个 Concrete.object 实际用掉 8 bytes,包括填补用的 3 bytes,以使 object 能够符合一部机器的 word 边界。不论是 C 或 C++都是这样。一般而言,边界调整(alignment)是由处理器(processor)来决定的。
Concrete2 的 bit2 实际上被放在填补空间所用的 3 bytes 之后。于是其大小变成 12 bytes,不是 8 bytes。其中有 6 bytes 浪费在填补空间上。相同的道理使得 Concrete3 object 的大小是 16 bytes,其中 9 bytes 用于填补空间。 
多重继承(Multiple Inheritance)
多重继承既不像单一继承,也不容易模塑出其模型。例如,考虑下面这个多重继承所获得的 class Vertex3d:
1 | class Point2d |
其继承关系如下: 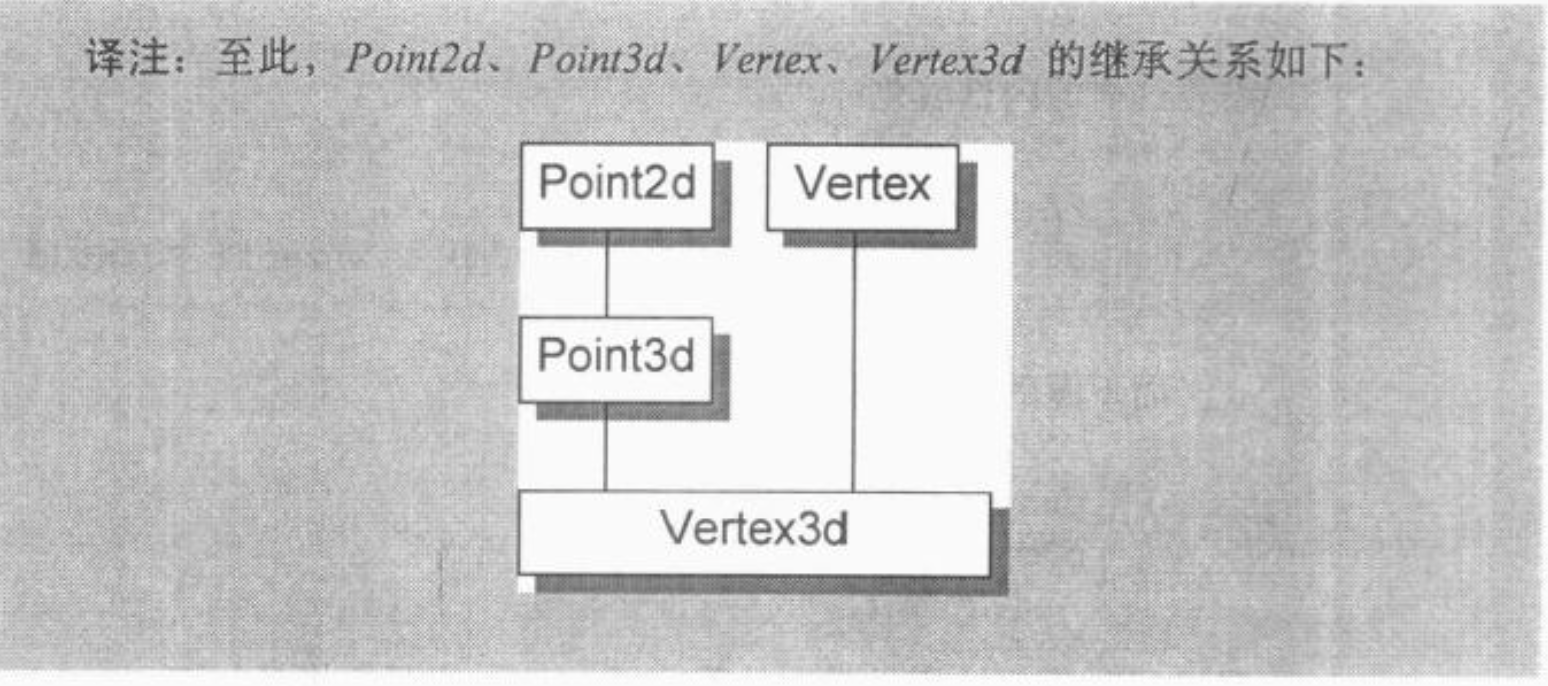
内存布局如下: 
虚拟继承 (Vitual Inheritance)
一般的实现方法如下所述。Class 如果内含一个或多个 virtual base class subobjects,将被分割为两部分:一个不变局部和一个共享局部。不变局部中的数据,不管后继如何衍化,总是拥有固定的 offset(从 object 的开头算起),所以这一部分数据可以被直接存取。至于共享局部,所表现的就是 virtual base class subobject。这一部分的数据,其位置会因为每次的派生操作而有变化,所以它们只可以被间接存取。各家编译器实现技术之间的差异就在于间接存取的方法不同。下面是 Vertex3d 虚拟继承的层次结构:
1 | class Point2d |
其继承关系如下: 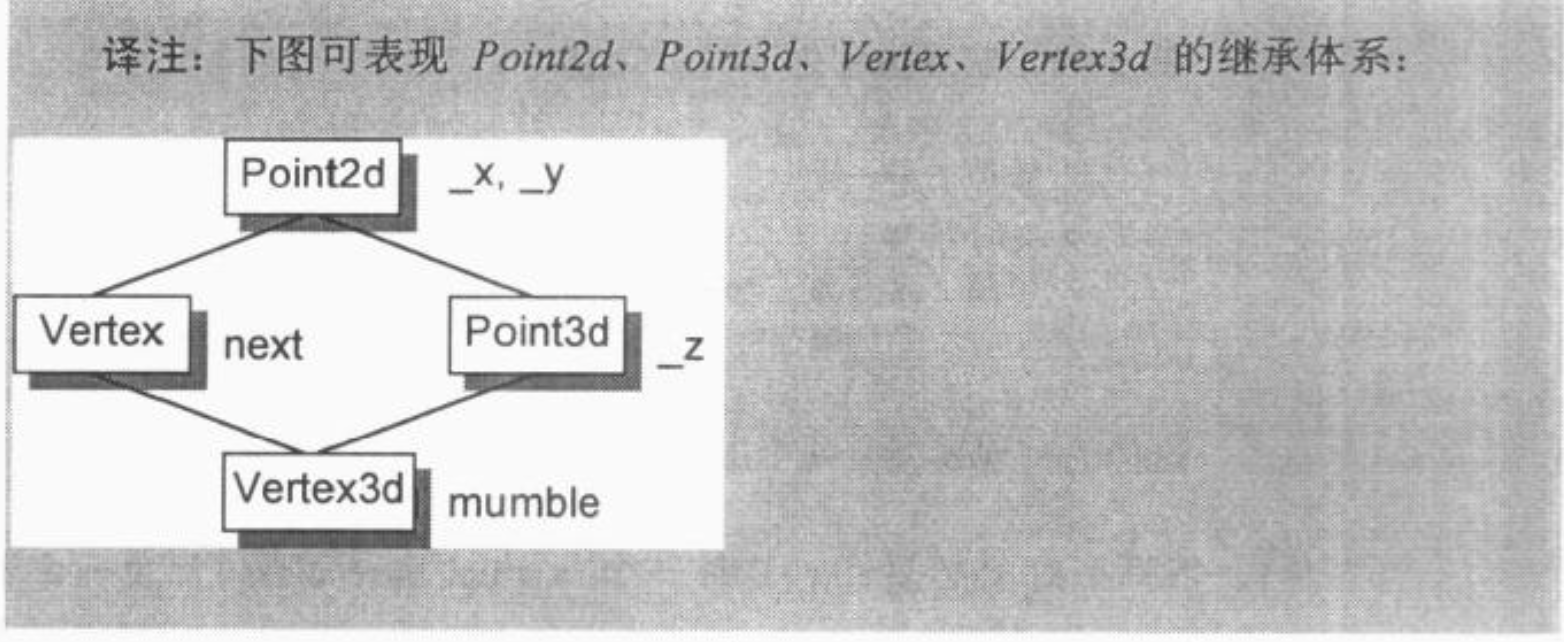
内存布局如下: 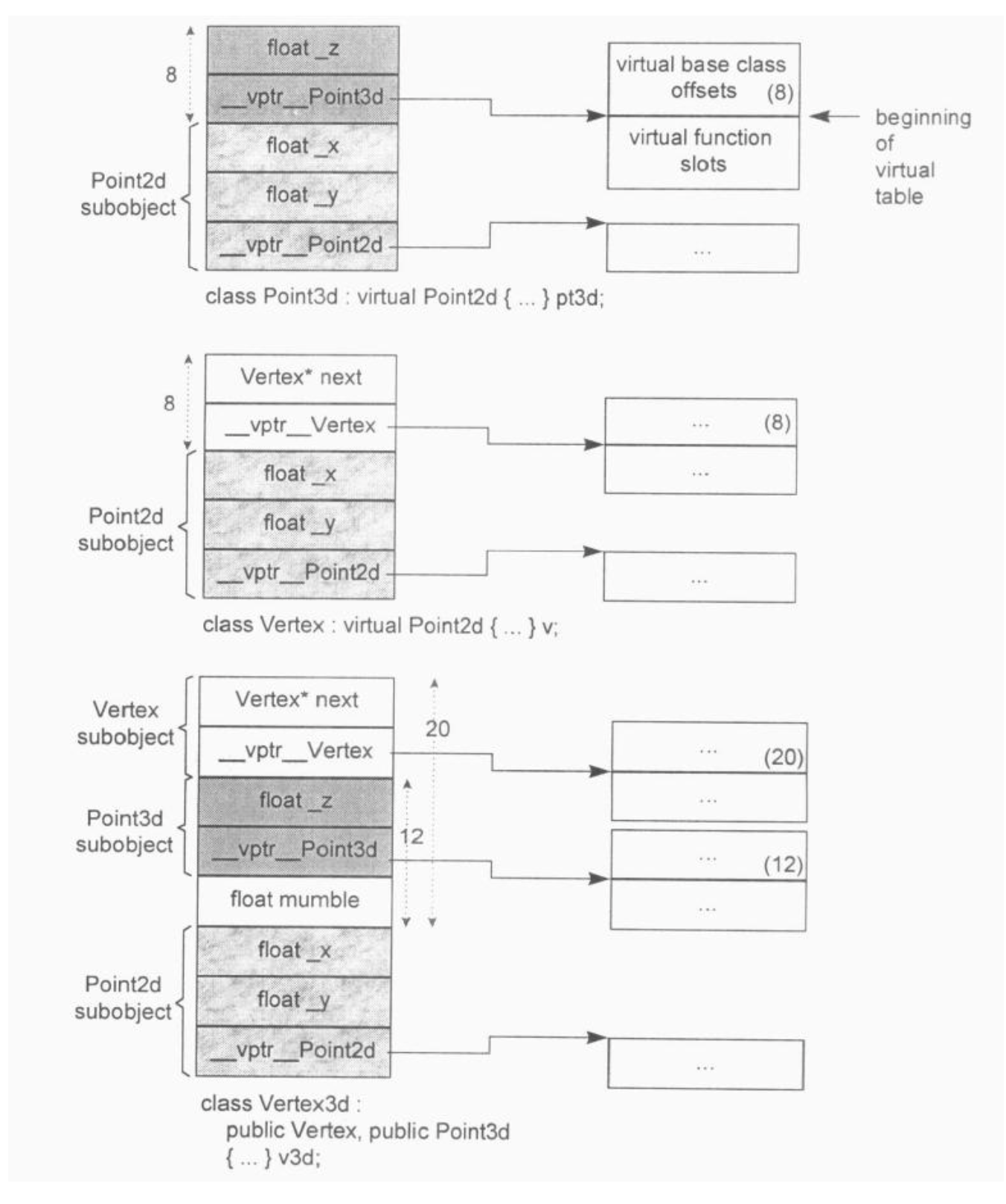
Function 语意学
C++的设计准则之一:nostatic member function 至少必须和一般的 nonmember function 有相同的效率
- 改写函数原型,在参数中增加 this 指针。
- 对每一个"nonstatic data member 的存取操作"改为由 this 指针来存取。
- 将 member function 重写为一个外部函数,经过"mangling"处理。
覆盖(override)、重写(overload)、隐藏(hide)的区别
- 重载是指不同的函数使用相同的函数名,但是函数的参数个数或类型不同。调用的时候根据函数的参数来区别不同的函数。
- 覆盖(也叫重写)是指在派生类中重新对基类中的虚函数(注意是虚函数)重新实现。即函数名和参数都一样,只是函数的实现体不一样。
- 隐藏是指派生类中的函数把基类中相同名字的函数屏蔽掉了。隐藏与另外两个概念表面上看来很像,很难区分,其实他们的关键区别就是在多态的实现上。
Virtual Member Functions(虚拟成员函数)
我们已经看过了 virtual function 的一般实现模型:每一个 class 有一个 virtual table,内含该 class 之中有作用的 virtual function 的地址,然后每个 object 有一个 vptr,指向 virtual table 的所在。在这一节中,我要走访一组可能的设计,然后根据单一继承、多重继承和虚拟继承等各种情况,从细部上探究这个模型、为了支持 virtual function 机制,必须首先能够对于多态对象有某种形式的“执行期类型判断法(runtime type resolution)”。也就是说,以下的调用操作将需要 ptr 在执行期的某些相关信息,
1 | ptr->z(); |
如此一来才能够找到并调用 z() 的适当实体。或许最直接了当但是成本最高的解决方法就是把必要的信息加在 ptr 身上。在这样的策略之下,一个指针(或是一个 reference)含有两项信息:
- 它所参考到的对象的地址。
- 对象类型的某种编码,或是某个结构的地址。
这个方法带来两个问题
- 第一,它明显增加了空间负担,即使程序并不使用多态(polymorphism)。
- 第二,它打断了与 C 程序间的链接兼容性。如果这份额外信息不能够和指针放在一起,下一个可以考虑的地方就是把它放在对象本身。
欲鉴定哪些 classes 展现多态特性,我们需要额外的执行期信息。一如我所说,关键词 class 和 struct 并不能够帮助我们。由于没有导入如 polymorphic 之类的新关键词,因此识别一个 class 是否支持多态,唯一适当的方法就是看看它是否有任何 virtual function。只要 class 拥有一个 virtual function,它就需要这份额外的执行期信息。
下一个明显的问题是,什么样的额外信息是我们需要存储起来的?也就是说,如果我有这样的调用:
1 | ptr->z(); |
其中 z() 是一个 virtual function,那么什么信息才能让我们在执行期调用正确的 z() 实体?我需要知道:
- ptr 所指对象的真实类型。这可使我们选择正确的 z() 实体。
- z() 实体位置,以便我能够调用它。
那么,我如何有足够的知识在编译时期设定 virtual function 的调用呢?
- 一般而言,我并不知道 ptr 所指对象的真正类型,然而我知道,经由 ptr 可以存取到该对象的 virtual table。虽然我不知道哪一个 z() 函数实体会被调用,但我知道每一个 z() 函数地址都被放在 slot4。这些信息使得编译器可以将该调用转化为:
1 | *ptr->vptr[4]) (ptr ); |
在这个转化中,ptr 表示编译器所安的指针,指向 virtual table;4 表示 z() 被赋值的 slot 编号(关联到 Point 体系的 virtual table)唯一个在执行期才能知道的东西是:slot4 所指的到底是哪一个 z() 函数实体?
在一个单一继承体系中,virtual function 机制的行为十分良好,不但有效率而且很容易塑造出模型来。但是在多重继承和虚拟继承之中,对 virtual functions 的支持就没有那么美好了。
多重继承下的 Virtual Functions
在多重继承中支持 virtual functions,其复杂度围绕在第二个及后继的 base classes 身上,以及“必须在执行期调整 this 指针”这一点。以下面的 class 体系为例:
1 | //class 体系,用来描述多重继承(MI)情况下支持 virtual function 时的复杂度 |
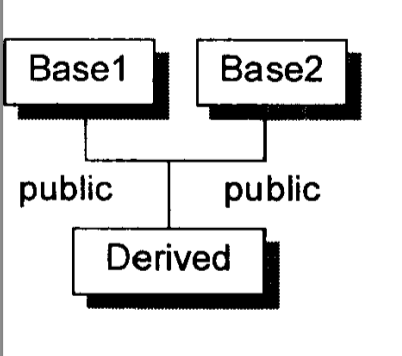
“Derived 支持 virtual functions”的困难度,统统落在 Base2 subobject 身上。有三个问题需要解决,以此例而言分别是
- virtual destructor。
- 被继承下来的 Base2:mumble()。
- 一组 clone() 函数实体。
让我依次解决每一个问题
第一种情况:
我把一个从 heap 中配置而得的 Derived 对象的地址,指定给一个 Base2 指针:
1 | Base2 *pbase2 = new Derived; |
新的 Derived 对象的地址必须调整,以指向其 Base2 subobject。编译时期会产生以下代码:
1 | //转移以支持第二个 base class |
如果没有这样的调整,指针的任何“非多态运用”(像下面那样)都将失败:
1 | //即使 pbase2 被指定一个 Derived 对象,这也应该没有问题 |
当程序员要删除 pbase2 所指的对象时:
1 | //必须首先调用正确的 virtual destructor 函数实体 |
指针必须被再一次调整,以求再一次指向 Derived 对象的起始处(推测它还指向 Derived 对象)。然而上述的 offset 加法却不能够在编译时期直接设定,因为 pbase2 所指的真正对象只有在执行期才能确定。
一般规则是,经由指向“第二或后继之 base class”的指针(或 reference)来调用 derived class virtual function。泽注就像本例的:
1 | Base2 *pbase2 = new Derived; |
该调用操作所连带的“必要的 this 指针调整”操作,必须在执行期完成。也就是说,offset 的大小,以及把 offset 加到 this 指针上头的那一小段程序代码必须由编译器在某个地方插人。问题是,在哪个地方?
offset
Bjarne 原先实施于 cfront 编译器中的方法是将 virtual table 加大,使它容纳此处所需的 this 指针,调整相关事物。每一个 virtual table slot,不再只是一个指针,而是一个聚合体,内含可能的 offset 以及地址。于是 virtual function 的调用操作由:
1 | (*pbase2->vptr [1])(pbase2 ) |
改变为:
1 | (*pbase2->vptr[1].faddr) |
其中 faddr 内含 virtual function 地址,offset 内含 this 指针调整值。
这个做法的缺点是,它相当于连带处罚了所有的 virtual function 调用操作。不管它们是否需要 offset 的调整我所谓的处罚,包括 offset 的额外存取及其加法,以及每一个 virtual table slot 的大小改变。
比较有效率的解决方法是利用所谓的 thunk。Thunk 技术初次引进到编译器技术中,我相信是为了支持 ALGOL 独一无二的 pass-by-name 语意。所谓 thunk 是一小段 assembly 码,用来以适当的 offset 值调整 this 指针,跳到 virtual function 去。例如,经由一个 Base?指针调用 Derived destructor,其相关的 thunk 可能看起来是这个样子:
1 | //虚拟 C++码 |
Bjarne 并不是不知道 thunk 技术,问题是 thunk 只有以 assembly 码完成才有效率可言。由于 cfront 使用 C 作为其程序代码产生语言,所以无法提供一个有效率的 thunk 编译器。 Thunk 技术允许 virtual table slot 继续内含一个简单的指针,因此多重继承不需要任何空间上的额外负担。Slots 中的地址可以直接指向 virtual function,也可以指向一个相关的 thunk(如果需要调整 this 指针的话)。于是,对于那些不需要调整 this 指针的 virtual function(相信大部分是如此,虽然我手上没有数据)而言,也就不需承载效率上的额外负担。 调整 this 指针的第二个额外负担就是,由于两种不同的可能:
- 经由 derived class 调用,经由第二个 base class 调用,同一函数在 virtual table 中可能需要多笔对应的 slots。例如:
1 | Base1 *pbase1 = new Derived; |
虽然两个 delete 操作导致相同的 Derived destructor,但它们需要两个不同的 virtual table slots:
- pbase1 不需要调整 this 指针(因为 Base1 是最左端 base class 之故,它已经指向 Derived 对象的起始处)。其 virtual table slot 需放置真正的 destructor 地址。
- pbase2 需要调整 this 指针。其 virtual table slot 需要相关的 thunk 地址。
在多重继承之下,一个 derived class 内含 n-1 个额外的 virtual tables,n 表示其上一层 base classes 的数目(因此,单一继承将不会有额外的 virtual tables)。对于本例之 Derived 而言,会有两个 virtual tables 被编译器产生出来:
- 一个主要实体,与 Basel(最左端 base class)共享。
- 一个次要实体,与 Base2(第二个 base class)有关。
针对每一个 virtual tables,Derived 对象中有对应的 vptr。图 4.2 说明了这一点。vptrs 将在 constructor(s)中被设立初值(经由编译器所产生出来的码) 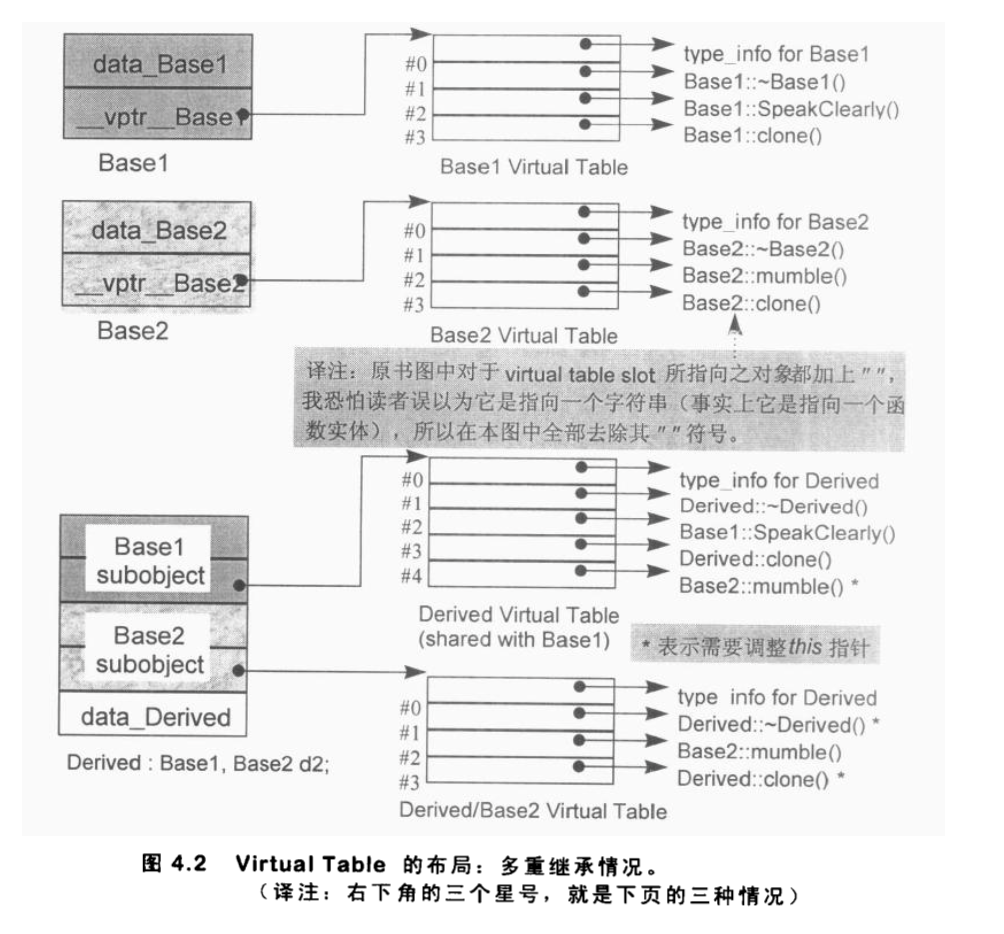
用以支持“一个 class 拥有多个 virtual tables'”的传统方法是,将每一个 tables 以外部对象的形式产生出来,并给予独一无二的名称。例如,Derived 所关联的两个 tables 可能有这样的名称:
1 | vtbl Derived; //主要表格 |
于是当你将一个 Derived 对象地址指定给一个 Base1 指针或 Derived 指针时,被处理的 virtual table 是主要表格 vtbl Derived。而当你将一个 Derived 对象地址指定给一个 Base2 指针时,被处理的 virtual table 是次要表格 vtbl Base2 Derived。
由于执行期链接器(runtime linkers)的降临,符号名称的链接可能变得非常缓慢。为了调节执行期链接器的效率,Sun 编译器将多个 virtual tables 连锁为一个;指向次要表格的指针,可由主要表格名称加上一个 offset 获得。在这样的策略下,每一个 class 只有一个具名的 virtual table。“对于许多 Sun 项目程序代码而言,速度的提升十分明显。
稍早我曾写道,有三种情况,第二或后继的 base class 会影响对 virtual functions 的支持。第一种情况是,通过一个“指向第二个 base class”的指针,调用 derived class virtual function。例如:
1 | Base2 *ptr = new Derived; |
从图 4.2 之中,你可以看到这个调用操作的重点:ptr 指向 Derived 对象中的 Base2 subobject;为了能够正确执行,ptr 必须调整指向 Derived 对象的起始处。
第二种情况:
是第一种情况的变化,通过一个“指向 derived class”的指针,调用第二个 base class 中一个继承而来的 virtual function。在此情况下,derived class 指针必须再次调整,以指向第二个 base subobject。例如:
1 | Derived *pder = new Derived; |
第三种情况:
发生于一个语言扩充性质之下:允许一个 virtual function 的返回值类型有所变化,可能是 base type,也可能是 publicly derived type。这一点可以通过 Derivea:clone() 函数实体来说明。clone 函数的 Derived 版本传回一个 Derived class 指针,默默地改写了它的两个 base class 函数实体。当我们通过“指向第二个 base class'”的指针来调用 clone() 时,this 指针的 offset 问题于是诞生:
1 | Base2 *pb1 = new Derived; |
当进行 pb1->clone() 时,pb1 会被调整指向 Derived 对象的起始地址,于是 clone() 的 Derived 版会被调用:它会传回一个指针,指向一个新的 Derived 对象;该对象的地址在被指定给 pb2 之前,必须先经过调整,以指向 Base2 subobject。
当函数被认为“足够小”的时候,Sun 编译器会提供一个所谓的“splitfunctions”技术:以相同算法产生出两个函数,其中第二个在返回之前,为指针加上必要的 offset。于是不论通过 Base1 指针或 Derived 指针调用函数,都不需要调整返回值;而通过 Base2 指针所调用的,是另一个函数。
如果函数并不小,“split function”策略会给予此函数中的多个进入点(entrypoints)中的一个。每一个进人点需要三个指令,然而 OO 程序员都会尽量使用小规模的 virtual function 将操作“局部化”。通常,virtual function 的平均大小是 8 行。
函数如果支持多重进入点,就可以不必有许多“thunks'”。如 IBM 就是把 thunk 搂抱在真正被调用的 virtual function 中。函数一开始先调整 this 指针,然后才执行程序员所写的函数码:至于不需调整的函数调用操作,就直接进人的部分。
虚拟继承下的 Virtual Functions
两者之间的转换也就需要调整 this 指针。至于在虚拟继承的情况下要消除 thunks,一般而言已经被证明是一项高难度技术。
当一个 virtual base class 从另一个 virtual base class 派生而来,并且两者都支持 virtual functions 和 nonstatic data members 时,编译器对于 virtual base class 的支持简直就像进了迷宫一样。我的建议是:
不要在一个 virtual base class 中声明 nonstatic data members
静态成员函数 static member functions
- 不能访问非静态成员。
- 不能声明为 const、volatile 或 virtual。
- 参数没有 this。
- 可以不用对象访问,直接 类名:: 静态成员函数访问。
vtable 虚函数表一定是在编译期间获知的,其函数的个数、位置和地址是固定不变的,完全由编译器掌控,执行期间不允许任何修改
vtable 的内容:
- virtual class offset(有虚基类才有)。
- topoffset。
- typeinfo。
- 继承基类所声明的虚函数实例,或者是覆盖(override)基类的虚函数。
- 新的虚函数(或者是纯虚函数占位)。
执行期虚函数调用步骤
- 通过 vptr 找到 vtbl。
- 通过 thunk 技术以及 topoffset 调整 this 指针(因为成员函数里面可能调用了成员变量)。
- 通过 virtual class offset 找到虚基类共享部分的成员。
- 执行 vtbl 中对应 slot 的函数。
- 多重继承中,一个派生类会有 n-1 个额外的 vtbl(也可能有 n 或者 n 以上个 vtbl,看是否有虚基类),它与第一父类共享 vtbl,会修改其他父类的 vtbl。
最后:Inline 对编译器只是请求,并非命令。inline 中的局部变量+有表达式参数-->大量临时变量-->程序规模暴涨
执行期语意学
- 尽量推迟变量定义,避免不必要的构造和析构(虽然 C++编译器会尽量保证在调用变量的时候才进行构造,推迟变量定义会使得代码好阅读).
- 全局类变量在编译期间被放置于 data 段中并被置为 0.
- GOOGLE C++编程规范:禁止使用 class 类型的静态或全局变量,只允许使用 POD 型静态变量 (Plain Old Data) 和原生数据类型。因为它们会导致很难发现的 bug 和不确定的构造和析构函数调用顺序
- 解决:改成在 static 函数中,产生局部 static 对象
- 如果有表达式产生了临时对象,那么应该对完整表达式求值结束之后才摧毁这些创建的临时对象。有两个例外:
- 该临时对象被 refer 为另外一个对象的引用;
- 该对象作为另一对象的一部分被使用,而另一对象还没有被释放。
站在对象模型的尖端
- 对于 RTTI 的支持,在 vtbl 中增加一个 type_info 的 slot。
- dynamic_cast 比 static_cast 要花费更多的性能(检查 RTTI 释放匹配、指针 offset 等),但是安全性更好。
- 对引用施加 dynamic_cast:1)成功;或 2)抛出 bad_cast 异常;对指针施加:1)成功;2)返回 0 指针。
- 使用** typeid() **进行判断,合法之后再进行 dynamic_cast,这样就能够避免对引用操作导致的 bad_cast 异常: if(typeid(rt) == typeid(rt2)) …。但是如果 rt 和 rt2 本身就是合法兼容的话,就会损失了一次 typeid 的操作性能。
参考文献
https://github.com/zfengzhen/Blog/blob/master/article/%E3%80%8A%E6%B7%B1%E5%85%A5%E6%8E%A2%E7%B4%A2C%2B%2B%E5%AF%B9%E8%B1%A1%E6%A8%A1%E5%9E%8B%E3%80%8B%E8%AF%BB%E4%B9%A6%E7%AC%94%E8%AE%B0.md
《深入探索 C++对象模型》