应用崩溃调试分析
前言
应用崩溃,各种空指针等大概是应用开发过程中最常遇到的问题了。而我们传统的调试利器 syslog 能快速解决 90%的问题,但是对于那些低概率,需要老化几十小时才能复现到的问题通过 syslog 就很难定位到问题了。这时如果可以提供一种情景再现的方式将应用崩溃现场的调用栈以及栈内数据给展现出来那么对于我们定位问题是大有帮助的。而笔者最近就遇到大量这种(基本都是老化过程中遇到的低概率)问题,于是这里尝试提供一种方法来快速定位问题。当然这类问题都是一个路子,掌握这种分析方法以后遇到这类问题就都可以轻松处理了。
本文提供的一种解决方案是通过 gdb+core dump 文件分析调试方法,具体如下:
开启 core dump 功能
在 init 脚本的 start_service 中添加
1 | procd_set_param limits core="unlimited" |
这样一条代码,例如 xxxapp 中的添加如下: 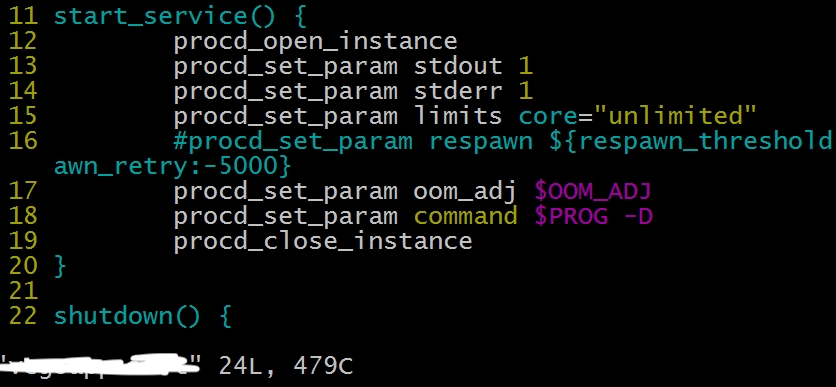
或者直接在 shell 中执行:
1 | ulimit -c unlimited |
然后执行应用。
添加添加调试信息和符号表
去掉编译系统的全局 strip(由 strip 改为 none)
1 | make menuconfig |

注意:因为 xxxapp 上存储容量限制,可以在 strip 模式下编译完系统后再改为 none,然后在编译 xxxapp,这样就只有 xxxapp 有符号表和调试信息。
应用中添加符号信息
应用或者库中添加符号信息只需要在 gcc 编译的时候加上-g 选项,一般为了方便调试需要去掉-Ox 选项。例如 xxxapp 调试时的编译选项如下: 
开启 gdb
1 | make menuconfig |
调试应用崩溃现场
在小机端使用“gdb 可执行程序 core 文件”开启 gdb,例如:
1 | $ gdb /usr/bin/xxxapp /tmp/core-startEventCall-675-1610194273 |
加载完符号表之后,就可以查看程序 dump 时候的栈追溯,命令为 bt
1 | $ (gdb) bt |
如果没有符号表,bt 打印的就只有地址;如果有符号表,bt 的打印如下: 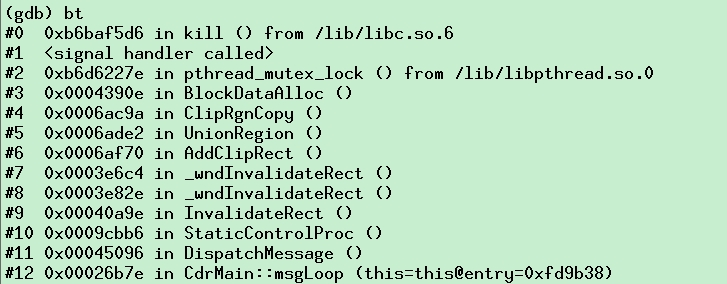
说明:这个调用栈是从#0 到#12 这个顺序看的,就是说应用是在#0 这个点退出,调用顺序是从#12 到#0,
如果既有符号表,又有 debug 信息,函数的参数会同步打印出来 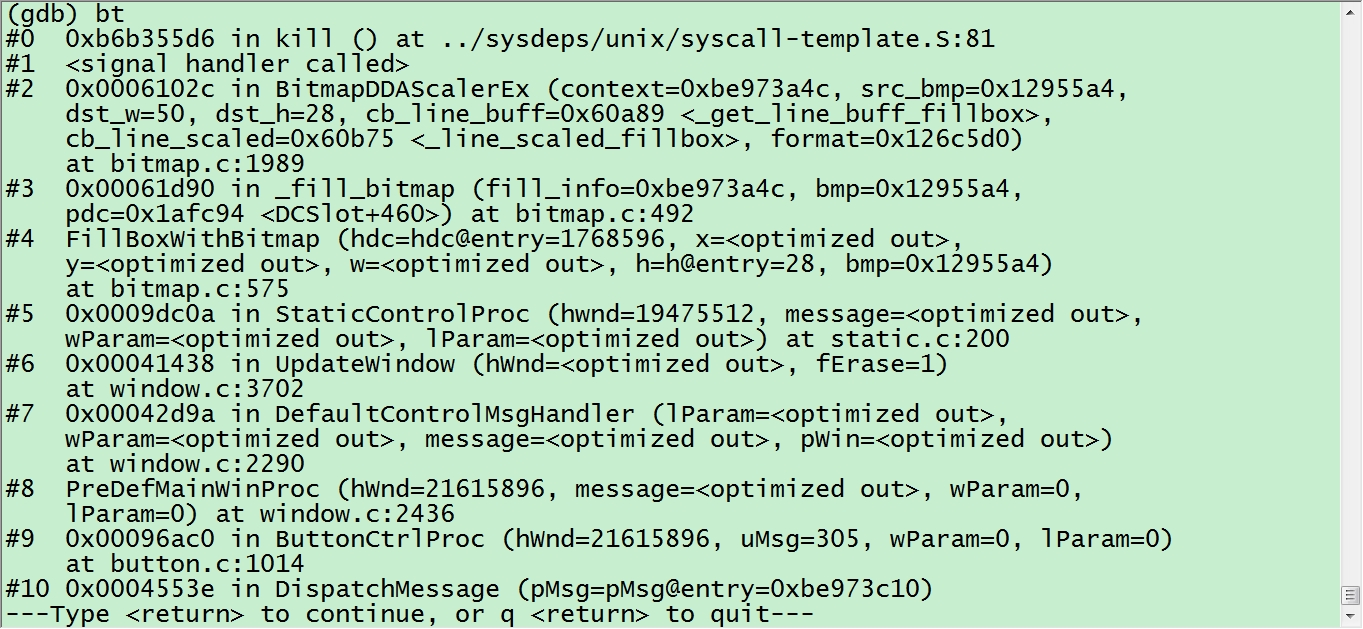
说明:添加符号表后会标识出调用函数所在的文件和行数,以及调用的时候的参数,通过调用栈可以知道程序是在#2(BitmapDDAScalerEx)这个点出错,然后进入到了 c 库的崩溃处理函数
进入#2 帧进行调试的命令如下:
1 | $ frame 2 |

说明:通过 pc 端打开 bitmap.c 定位到 1989 行(也可以把文件放到 tf 卡上使用 gdb 同步调试)
这部分的代码如下: 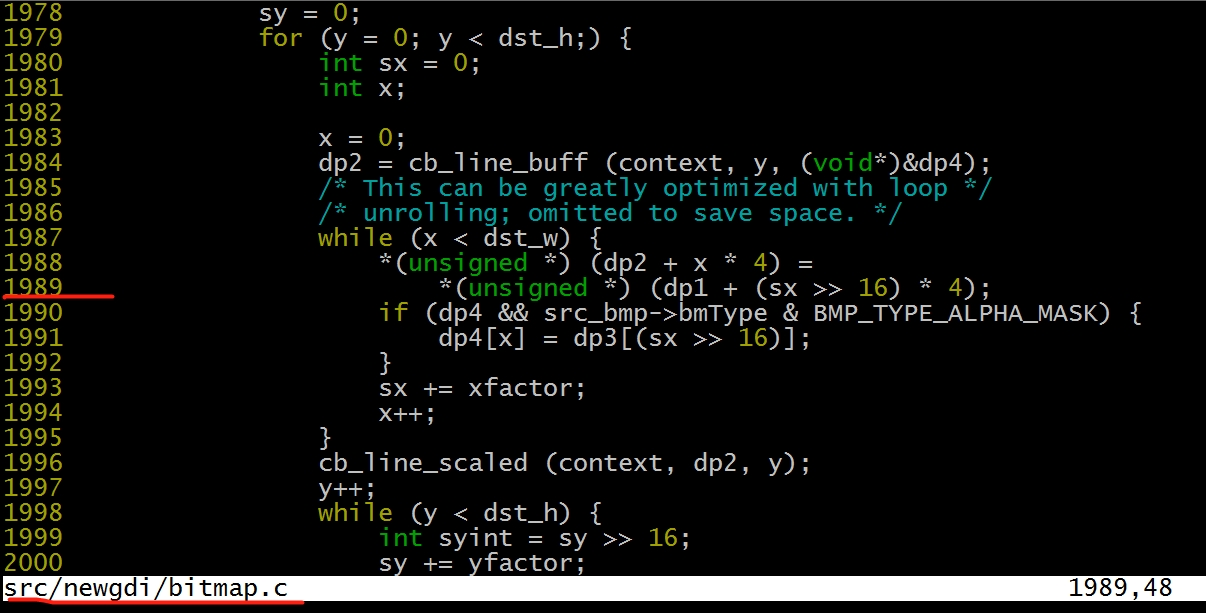
对照源码可以打印现场 dp1,dp2 以及 sx 的值 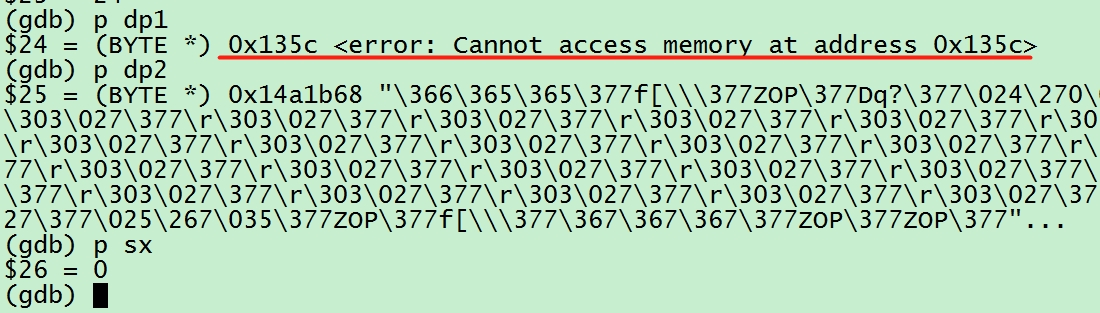
说明:通过源码可以看出这里的 dp1 已经是一个错误的地址,程序无法访问,接来下就要探索 dp1 的值从哪里来的。
找到该程序的上下文 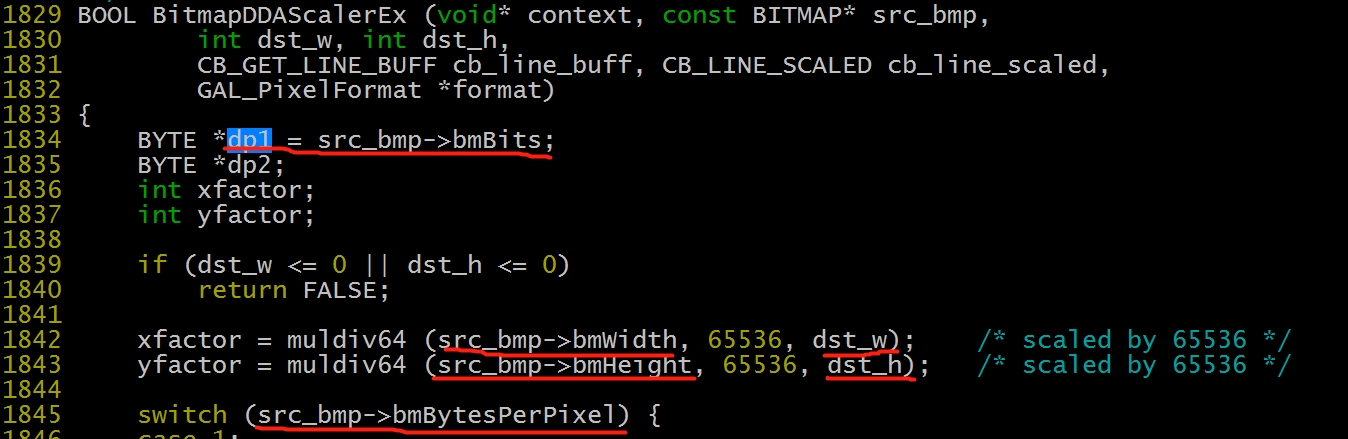
通过源码走读,需要打印的变量如下: 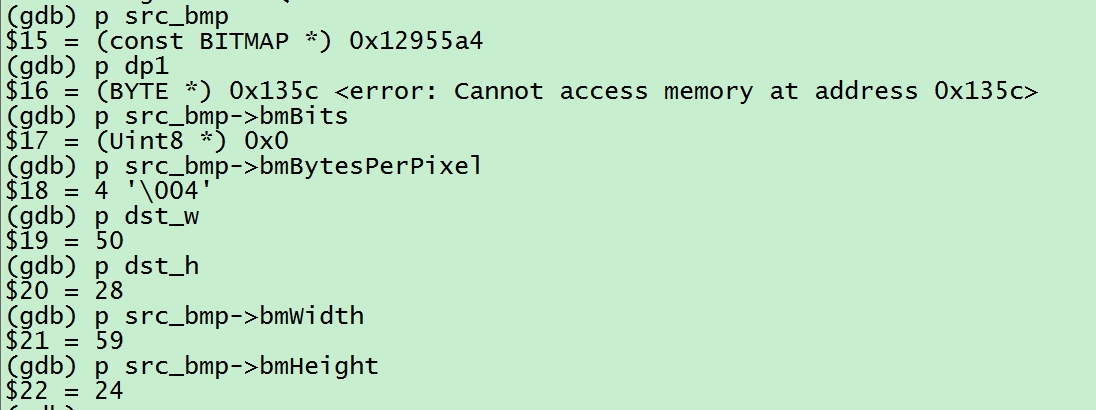
说明:通过这里我们可以知道这里是要将一个长为 59,宽为 24 的图片,缩放成长为 50,宽为 28 的图片,图片的像素宽度为 4 个字节,但是图片的内容已经被改写没有了。
但是没有有找到 dp1 对应的值的来源,汇编看看:
1 | $ (gdb) disassemble |

1 | $ (gdb) info registers |
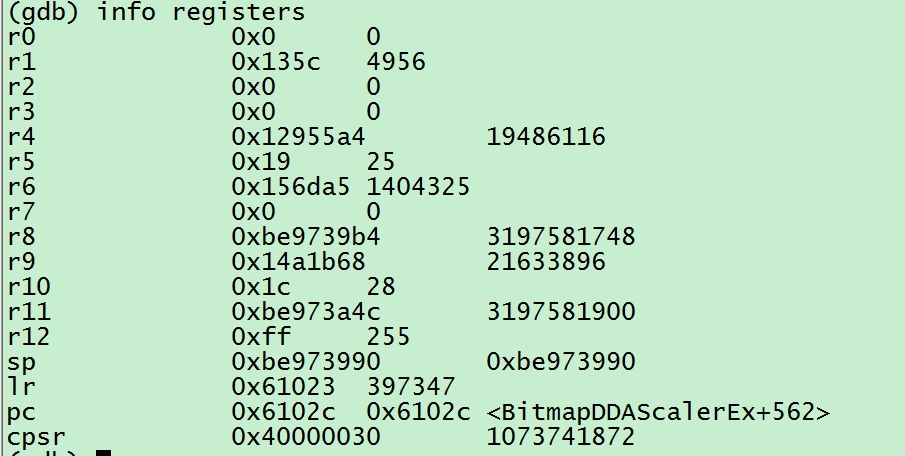
说明:通过现场能够知道 dp1 对应地址为栈上的地址 0xbe973990,这个地址里保存的值为 0x135c,但是这个函数的汇编太长了,追踪内存很耗时先放弃了。
通过在 xxxapp 中查找对应的图片,能够知道目前缩放的图片是电池电量图标的图片,这个是 minigui 里的一个 bug,跟图标刷新有关。这里不再继续下去了。以上就是一个应用崩溃后通过 gdb+core dump 文件对现场进行分析调试过程。以后遇到的应用崩溃问题都可以通过类似分析方法进行分析。
在 pc 上进行调试
最近在开发中遇到一个新问题,flash(16M nor flash)满了,机器端 flash 没有空间放 gdb 了,内存、带宽和 cpu 都超极限了,需要对系统进行优化,而优化的改动是很大的,期间非常容易引入各种死机问题,而此时又没有 gdb 了。只能通过 syslog 来调试,一些低概率的老化很久才会出现的问题很难通过 syslog 的打印查找出来,还是需要 gdb+core dump 文件才能快速定位问题。为此我们又研究了在 pc 端使用 gdb 和 core dump 文件的方法。具体差异点如下:
去掉 gdb
当然你的 flash 已经容不下 gdb 了,此时。
设置交叉编译工具链(gdb)
在~/.bashrc 文件里添加如下:
1 | export PATH=$PATH:/home/liushuai/workspace/project/prebuilt/gcc/linux-x86/arm/toolchain-sunxi-musl/toolchain/bin |
拷贝文件 (xxxapp 和 core dump 文件,要拷贝带符号表的 xxxapp)
1 | cp ~/workspace/project/out/v833-perf1/staging_dir/target/rootfs/usr/bin/***app ./ |
将机器端复现到问题后产生的 core 文件拷贝到 pc 端,adb pull /tmp/core****
运行交叉编译工具链中的 gdb 程序
1 | arm-openwrt-linux-gdb vegoapp core-startEventCall-675-1610194273 |
在运行 gdb 之后设置系统库路径(由于是在 pc 端运行,xxxapp 里不包含共享库的内容但是 sdk 路径里是有 rootfs 文件的)
1 | $ (gdb) set sysroot /home/liushuai/workspace/project/out/v833-perf1/staging_dir/target/rootfs |
打印追溯栈
1 | $ (gdb) bt |
剩下的就跟在机器端调试一样了。