
Linux 内存管理(十二)内存调优
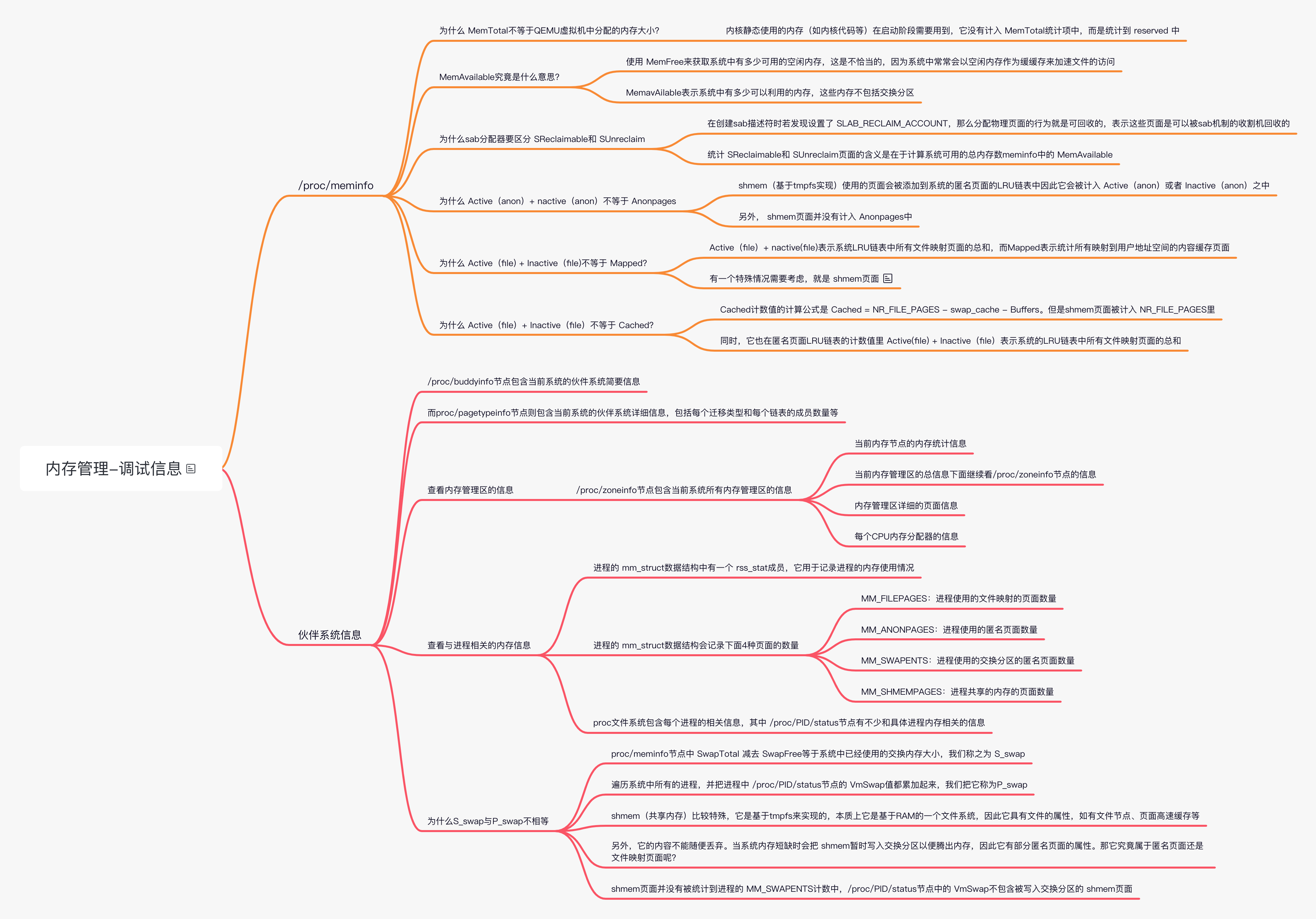
内存管理调优参数
对服务器或者嵌入式产品做性能调优的过程中,避免不了需要深入了解和使用 Linux 内内存管理模块提供的调优参数。Linux 内核支持的内存管理调优参数都在/proc/sys/vm 目录下面,共有 40 多个调优参数,如下所示:
1 | root@liushuai:/proc/sys/vm# ls |
内存管理的调优参数定义在 kerne\sysctl.c 文件中,通过 proc 文件系统机制来实现。
1 | static struct ctl_table vm_table[] = { |
- procname:表示这个节点的名称,显示在 proc/sys/vm 目录下面
- data:传递的数据,通常是某个全局变量,如 sysctl_overcommit_memory
- maxlen:参数 data 的长度。
- mode 节点的文件权限。0644 表示用户具有读写权限,组用户和其他用户具有只读权
- proc_handler:该节点在内核中的回调函数
- extral:表示这个参数的最小值
- exra2:表示这个参数的最大值,如。 overcommit_memory 调优参数的最大值为 2,最小值为 0
影响内存管理区水位的调优参数 min_free_kbytes
Linux 内核为了防止内存被恶意进程占用,在每个内存管理区设置了一部分预留内存,即最低警戒水位(watermark[WMARK_MIN])。进程分配内存的行为是有优先级的,对于普通优先级的分配行为,是不能访问预留内存的,只有对于高优先级的分配行为,才能访问,如高优先级的进程可以通过设置 __GFP_HIGH、__GFP_ATOMIC 甚至 __GFP_MEMALLOC 来访问预留内存。若系统预留内存小于 1024KB,那么可能会导致系统出问题,具有高优先级分配行为的进程没办法得到内存。
系统初始化时通过 init_per_zone_wmark_min() 函数来计算 min_free_kbytes 的大小,然后计算每个内存管理区的水位。 min_free_kbytes 的计算公式如下
min_free_bytes = 4 sqrt(lowmem_kbytes)
lommen_kbytes 是系统中所有内存管理区的管理页面数量减去高水位页面数量( managed_pages - high_pages)的总和。最后计算出来的 min_free_kbytes 有范围限制,最小值为 128KB, 最大值为 64MB.
min_free_kbytes 的值会影响每个内存管理区的水位,它是在 __setup_per_zone_marks() 函数中设置的。
1 | static void __setup_per_zone_wmarks(void) |
内存管理区的 3 个水位的计算都和 min_free_kbytes 有关。当系统只有一个内存管理区时最低警戒水位(watermark[WMARK_MIN])等于 min_free_kbytes 低水位、高水位与 watermark_scale_factor 参数、内存管理区管理的内存大小( managed_pages)有关。 watermark_boost 表示临时提高的水位(它是在 Linux5.0 内核中引入的)。
读者可以通过查看 proc/zoneinfo 节点来获取每个内存管理区水位的值。
1 | vooxle@liushuai:~/workspace/blog$ cat /proc/zoneinfo |
在实际内存调优过程中,设置 min_free_kbytes 值过大或者过小都会有相应的副作用。若 min_free_kbytes 值过大,会影响内存管理区的 3 个水位,因此把该值设置过大,相当于提高了低水位。若页面分配器在低水位情况下分配失败,则唤醒 kswapd 内核线程异步扫描 LRU 链表和回收内存。这相当于提前唤醒了 kswapd 内核线程。另外,留给普通优先级分配请求的内存就少了,这样可能导致进程提前使用 OOM Killer 机制。但是凡事都不能太绝对,当系统发现有外碎片化现象发生时,临时提高水位并且提前唤醒 kswapd 内核线程,反而可以缓解外片化的进一步恶化,这是 Linux5.0 内核新增的优化特性。
若 min_free_kbytes 值过小,内存管理区中预留的内存就越少,这样导致系统有一些高优先级分配行为的进程(或内核路径)在特别紧急情况下分配内存失败。若访向预留内存也失那么可能会导致系统进入死锁状态,如 kswapd 内核线程等通过没置 PF_MEMALLOC 标志位来告诉页面分配器,它们在紧急情况下访间少量的系统预留内存以保证程序的正确运行。
影响页面分配的参数 lowmem_reserve_ratio
Linux 内核把内存节点分成了多个内存管理区,位于低地址的称为低端内存管理区,位于高地址的称为高端内存管理区。在一个 x86_64 计算机上,通常分成如下几个内存管理区
- ZONE_DMA
- ZONE_DMA32
- ZONE_NORMAL
- ZONE_MOVAR
- ONE_DEVICBLE
可以通过查看/proc/zoneinfo 节点来获取每个内存管理区中的一些重要参数,如内存管理区的空闲内存、最低警戒水位、低水位、高水位、管理页面数量等。
1 | pages free 3971 |
一个非常重要的参数就是 protection,它读取内存管理区中 lowmem_reserve[] 数组的值。
1 | <include/linux/mmzone h> |
lowmem_reserve[] 数组的单位是页面,设置 lowmem_reserve[] 数组是为了防止页面分配器过度地从低端内存管理区中分配内存,因为低端内存管理区的内存一般是有特殊用途的,如 ZONE_DMA 用于 ISA 总线的设备。通常有些应用程序分配内存之后会使用 mlock() 来锁住这都分内存,因此这些内存就不能被交换到交换分区,从而导致 ZONE_DMA 变少了。另外,防止系统过早在低端内存管理区中触发 OOM Killer 机制,而系统的高端内存管理区却有大量空内存。因此, Linux 内核设置 lowmem_reserve[] 数组为了防止进程过度使用低端内存管理区的内存。
那 Linux 内核是如何使用这个数组呢?
从 /proc/zoneinfo 节点可以看到,ZONE_DMA 的 lowmem_reserve[] 数组值要比 ZONE_DMA32 的大。另外, ZONE_NORMAL 的 lowmem_reserve[] 数组元素全是 0,这说明不需要做额外保护。
判断一个内存管理区是否满足这次分配任务的函数是__zone_watermark_ok()。
1 | <mm/page_alloc.c> |
其中 z 表示当前扫描的内存管理区, classzone_idx 表示这次分配请求通过分配掩码计算出来的首选的内存管理区,如 GFP_KERNEL 会首选 ZONE_NOMAL。min 表示 z 内存管理区中判断水位的条件,free_pages 表示 z 内存管理区的空闲内存。
假设现在分配请求中 order 为 2,分配掩码为 GFP_KERNEL,为了判断当前的 ZONE_DMA 是否适合这次分配请求,假设判断水位条件为低水位。
在这种情况下需要读取 ZONE_DMA 中 lowmem_reserve[] 的值,从 /proc/zoneinfo 节点中我们可以读出值为 7610,7610KBx4=30440KB,加上 43KB,因此内存管理区的空闲页
面必须要大于 30484KB 才能满足分配请求。
每个内存管理区的 lowmem_reserve[] 值可以通过设置 lowmem_reserve_ratio 节点的值来修改,最终它是调用 setup_per_zone_lowmem_reserver[] 函数来实现的。
影响页面回收的参数
sappiness
swampiness 用于控制 kswapd 内核线程把页面写入交换分区的活跃程度,该值可以设置为 0~100 该值越小,说明写入交换分区的活跃度越低,这样有助于提高系统的 I/O 性能该值越大,说明越来越多进程的匿名页面被写入交換分区了,这样有利于系统腾出内存空间,但是发生磁盘交换会导致大量的 I/O,影响系统的用户体验和系统性能。0 表示不写入匿名页面到磁盘,直到系统的空闲页面加上文件映射页面的总数少于内存管理区的高水位オ启动匿名页面回收并将其写入交换磁盘。 swampiness 的默认值为 60。
zone_reclaim_mode
当页面分配器在一个内存管理区里分配失败时,若 zone_reclaim_mode 为 0,则表示可以从下一个内存管理区或者下一个内存节点中分配内存;否则,表示可以在这个内存管理区中进行一些内存回收,然后继续尝试在该内存管理区中分分配内存。
在 kernel/sysctl.c 文件中, zone_reclaim_mode 的值由 node_reclaim_mode 去来存储。
1 | static struct ctl_table vm_table[] = { |
在 get_page_from_freelist() 函数中,当 zone_watermark_fast() 判断当前的内存管理区不能满足分配请求时,若 node_reclaim_mode 的值不为 0,则调用 node_reclaim() 函数对该内存管理区进行页面回收。下面是 get page_ from freelis 函数的代码片段。
1 | static struct page * |
zone_reclaim_mode 是一个按位或操作的数值,读者可以根据如下位来设置不同的组合。
- 1(bit[0]):表示打开内存管理区回收模式・扫描该内存管理区的页面并进行页面回收。
- 2(bit[1]):表示只回收该内存管理区的内容缓存页面,将脏的内容缓存页面回写到磁盘,从而回收页面。
- 4(bit[2]):表示只回收该内存管理区的匿名页面。
通常情况下, zone_reclaim_mode 模式是关闭的。但是,读者可以根据不同的场景来选择打开或者关闭。
- 打开的场景。如果应用场景对跨 NUMA 内存节点的访问延时比较敏感,可以打开 zone_reclaim_mode 模式,这样页面分配器会优先从本地内存节点回收内存并分配内存。
- 关闭的场景。如文件服务器中,系统需要大量的内容来作为内容缓存,即使内容缓存在远端 NUMA 节点上,读其中的内容也比直接读磁盘中的内容要快。
watermark_boost_factor
watermark_boost_factor 用于优化内存外碎片化。它临时提高内存管理区的水位,即 zone->watermark_boost 从而提高内存管理区的高水位( WMARK_HIGH),这样 kswapd 可以回收更多内存,内存规整模块( compactd 内核线程)就比较容易合并大块的连续物理内存。
watermark_boost_factor 的默认值是 15000,表示会临时把原来的高水位提升到 150%。若把这个值设置为 0,则关闭临时提高内存管理区水位的机制。临时提高 zone->watermark_boost 是在 boost_watermark() 函数中实现的。
watermark_scale_factor
除了和 min_free_kbyt 有关外, watermark_scale_factor 还会影响每个内存管理区的低水位 WMARK_LOW)和高水位
内存管理区的低水位会影响 kswapd 内核线程唤醒的时机,内存管理区的高水位会影响 kswapd 内核线程进入睡眠的时机。通常,当页面分配器发现在低水位分配失败时,会唤醒 kswapd 内核线程:而当内存管理区水位高于高水位时,会让 kswapd 内核线程停止工作并进入睡眠状态。
在__setup_per_zone_marks() 函数中,watermark_scale_factor 的默认值为 10,分母为 10000 因比表示两个水位之间的距离是系统总内存的 0.1%,如最低警戒水位与低水位的差距是总内存的 0.1% watermark_scale_factor 最大可以设置为 1000 即两个水位之间的差距最大为总内存的 10%。
影响脏页回写的参数
内存的回收和胜页回写有密切的关系,尽管本节没有介绍文件系统的相关内容,但是对于系统调优来说,影响脏页回写的参数不可忽视。
-
dirty_background_bytes:当脏页所占的内存数量(指所有可用内存,即空闲页面+可回收内存页面)超过 dirty_background_bytes 时,内核回写线程( writeback thread)开始回写脏页。
-
dirty_background_ratio:当脏页所占的百分比达到 dirty_background_ratio 时,内核回写线程开始回写脏页数据,直到脏页比例低于此值。注意,对于 dirty_backgound_byts 和 dirty_background_ratio,我们只能设置其中一个。当设置其中一个时。另外一个立即变成 0。 dirty_background_ratio 的默认值为 10。
-
diry_bytes:当系统的脏页总数达到 diry_bytes 值时, wrte 系统调用会被阻塞,并开始回写脏页数据,直到脏页总数低于此值。注意,该值不能设置为小于两个页面大小的字节数,否则,设置不生效并且系统会默认加载之前的旧值。
-
dirty_ratio:当脏页所占的百分比(空闲内存页+可回收内存页)达到 dirty_ratio 时,write 系统调用被阻塞并开始回写脏页数据,直到脏页比例低于此值。 dirty_ratio 的默认值为 20。注意,对于 dirty_ratio 和 dirty_bytes,我们只能设置其中一个。
-
dirty_expire_centisecs:脏数据的过期时间。当内核回写线程被唤醒后会检査哪些数据的存在时间超过了这个时间,并将这些脏数据回写到磁盘,单位是百分之一秒,也就是 10ms。该值默认是 3000,即若脏数据的存在时间超过 30s,那么内核回写线程唤醒之后优先回写这些脏数据。
-
dirty_writeback_centisecs:内核回写线程周期性唤醒的时间间隔,默认是 5。
-
drop_caches:用来回收干净的页面高速缓存和一些可以回收的 sab 对象,如文件系统中 inode、dentries 等。其默认值的含义如下:
- 1、回收和释放内容缓存页面
- 2、回收和释放可回收的 sab 对象。
- 3、同时回收和释放内容缓存页面、slb 对象
读者可能会对 dirty_background_* 和 dirty_* 这两组参数产生疑感。其实它们之间不冲突,下面以 ratio 为例来说明, dirty_background_ratio 是内存可以产生脏页的百分比。若系统脏页超过这个比例,这些脏页会在稍后某个时刻回写到磁盘里,这由内核回写线程来完成。而 dirty_ratio 的语义是脏页的限制,即脏页的百分比不能超过这个值。如果脏数据超过这个数量,新的 I/O 请求( write 系统调用)将会被阻塞,直到脏数据被写进磁盘。这是造成 I/O 延迟的重要原因,但这是保证内存中不会存在过量脏数据的保护机制
参考文献
《奔跑吧 Linux 内核》
[[LinuxMemoryKSM]]
[[LinuxMemoryslab]]
[[LinuxMemoryDebug]]
[[LinuxMemoryCache]]
[[LinuxMemoryBasic]]
[[LinuxMemorymigrate]]
[[LinuxMemoryPageMngr]]
[[LinuxMemoryARM64linux]]
[[LinuxMemoryPageRecycle]]
[[LinuxMemoryProcessSpace]]
[[LinuxMemoryPageAllocate]]
[[Blog/LinuxKernel/LinuxMemoryOptimization|LinuxMemoryOptimization]]





