
Linux 内存管理(七)进程地址空间
进程地址空间
进程地址空间在内核中使用 vm_area_struct 数据结构来描述,简称 VMA,表示进程地址空间或进程线性区。由于这些地址空间属于各个用户进程,因此在用户进程的 mm_struct 数据结构中有相应的成员,用于对这些 VMA 进行管理。
内存区域
进程地址空间(process address space)是指进程可寻址的虚拟地址空间,进程可以通过内核的内存管理机制动态地添加和删除内存区域,这些内存区域在 Linux 内核采用 VMA 数据结构来抽象描述。
每个内存区域具有相关的权限,如可读、可写或者可执行权限。若一个进程访问了不在有效范围的内存区域,或者非法访问了内存区域,或者以不正确的方式访问了内存区域,那么处理器会报告缺页异常。在 Linux 内核的缺页异常处理中会处理这些情况,严重的会报告“SegmentFault’”并终止该进程。
内存区域主要包含内容如下:
- 代码段映射:可执行文件中包含只读并可执行的程序头,如代码段和 init 段等
- 数据段映射:可执行文件中包含可读/可写的程序头,如数据段和未初始化数据段等
- 用户进程栈:通常位于用户空间的最高地址,从上往下延伸。它包含栈帧,里面包含了局部变量和函数调用参数等
- mmap 映射区域:位于用户进程栈下面,主要用于 mmap 系统调用
- 堆映射区域:malloc() 函数分配的进程虚拟地址就是这段区域
每个进程都有一套页表,这样每个进程地址空间就是相互隔离的。即使两个进程地址空间的虚拟地址是相同的,但是经过两套不同页表的转换之后,它们也会对应不同的物理地址。
mm_struct 数据结构
Linux 内核需要管理每个进程所有的内存区域以及它们对应的页表映射,所以必须抽象出一个数据结构,这就是 mm_struct 数据结构。进程控制块(Process Control Block,PCB)数据结构 task_struct 中有一个指针 mm,该指针指向这个 mm_struct 数据结构。mm_struct 数据结构定义在 include/linux/mm_types.h 文件中,下面是它的主要成员。
1 | struct mm_struct { |
mm_struct 数据结构中主要成员的含义如下:
- mmap:进程里所有的 VMA 形成一个单链表,这是该链表的头
- mmrb:VMA 红黑树的根节点
- get_unmapped_area:用于判断虚拟内存空间是否有足够的空间,返回一段没有映射过的空间的起始地址,这个函数会使用具体的处理器架构的实现
- mmap_base:指向 mmap 空间的起始地址。在 32 位处理器中,mmap 空间的起始地是 0x4000 0000
- pgd:指向进程的 PGD(一级页表)
- mm_users:记录正在使用该进程地址空间的进程数目,如果两个线程共享该地址空间那么 mm_users 的值等于 2
- mm_count:mm_struct 结构体的主引用计数
- mmap_sem:保护 VMA 的一个读写信号量
- mmlist:所有的 mm_struct 数据结构都连接到一个双向链表中,该链表的头是 init_mm 内存描述符,它是 init 进程的地址空间
- start_code,end_code:代码段的起始地址和结束地址
- start_data,end_data:数据段的起始地址和结束地址
- start_brk:堆空间的起始地址
- brk:表示当前堆中的 VMA 的结束地址
- total_vm:已经使用的进程地址空间总和
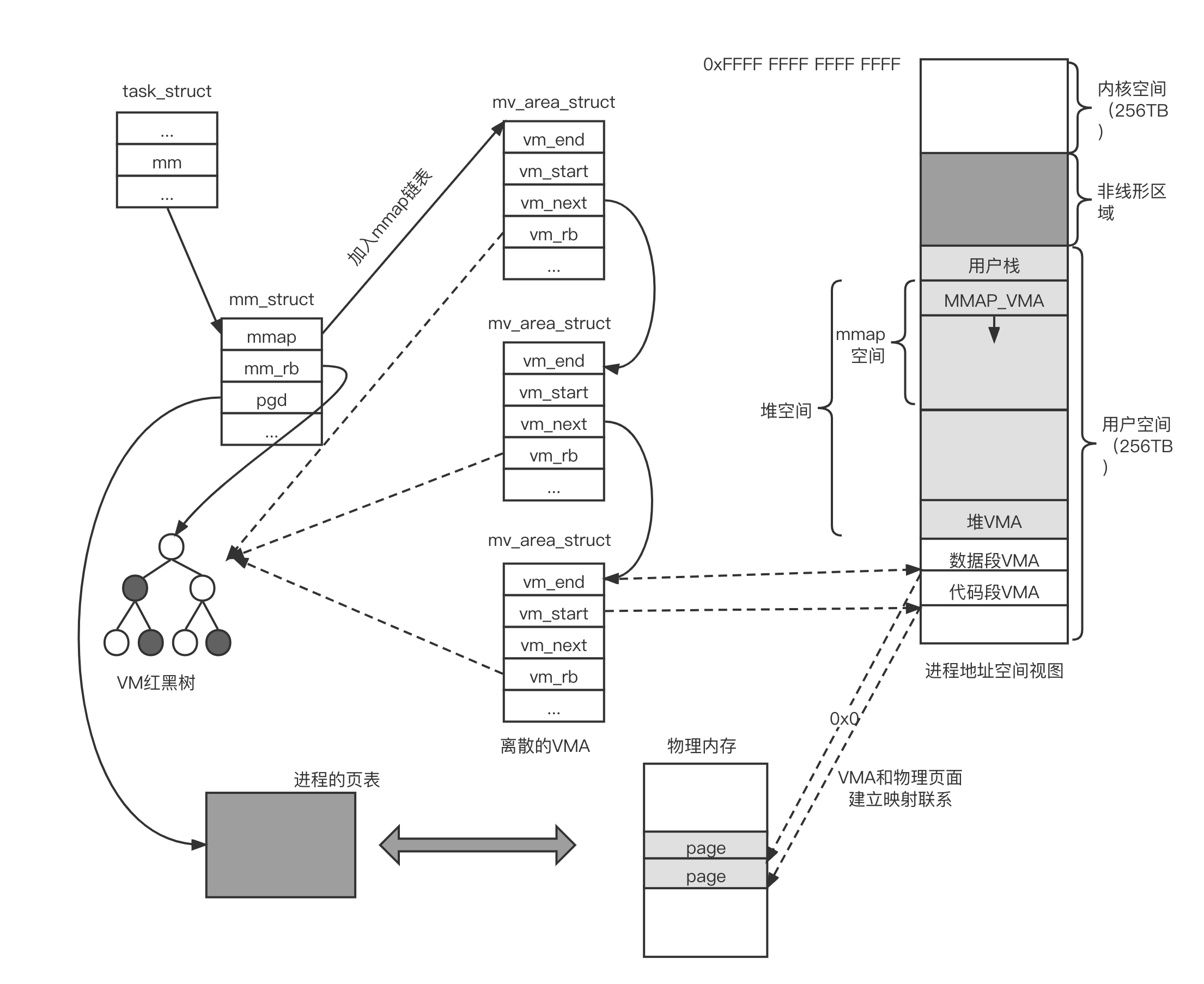
从进程的角度来观察内存管理,可以沿着 mm_struct 数据结构进行延伸和思考,如下图所示。
VMA 数据结构
VMA(vm_area_struct)数据结构定义在 mm_types.h 文件中,其主要成员如下。
1 | include/1inux/mm_types.h> |
VMA 数据结构中各个成员的含义如下:
- vm_start 和 vm_end:指定 VMA 在进程地址空间的起始地址和结束地址
- vm_next 和 vm_prev:进程的 VMA 都连接成一个链表
- vmrb:VMA 作为一个节点加入红黑树,每个进程的 mm_struct 数据结构中都有一棵红黑树 mm->mm_rb
- vm_mm:指向该 VMA 所属进程的 mm_struct 数据结构
- vm_page_prot:VMA 的访问权限
- vm_flags:描述该 VMA 的一组标志位
- anon_vma_chain 和 anon_vma:用于管理反向映射(Reverse Mapping,RMAP)
- vm_ops:指向许多方法的集合,这些方法用于在 VMA 中执行各种操作,通常用于文件映射
- vm_pgoff:指定文件映射的偏移量,这个变量的单位不是字节,而是页面的大小件映射。(PAGE SIZE)。对于匿名页面来说,它的值可以是 0 或者 vm_addr/PAGE_SIZE
- vm_file:指向 file 的实例,描述一个被映射的文件
mm_struct 数据结构是描述进程内存管理的核心数据结构,该数据结构提供了管理 VMA 所需要的信息,每个 VMA 都要连接到 mm_struct 中的链表和红黑树,以方便查找。
VMA 按照起始地址以递增的方式插入 mm_struct->mmp 链表中。当进程拥有大量的 VMA 时,扫描链表和查找特定的 VMA 是非常低效的操作,如在云计算的机器中,所以内核中通常需要红黑树来协助,以便提高查找速度。
站在进程的角度来看,我们可以从进程控制块。task_struct 数据结构里顺藤摸瓜找到该进程所有的 VMA,如图所示。
- task_struct 结结构中有一个 mm 成员指向进程的内存管理描述符 mm_struct 数据结构
- 可以通过 mm_struct 数据结构中的 mmap 成员来遍历所有的 VMA
- 也可以通过 mm_struct 数据结构中的 mm_rb 成员来遍历和查找 VMA
- mm_struct 数据结构的 pgd 成员指向进程的页表,每个进程都有一份独立的页表
- 当 CPU 第一次访问虚拟地址空间时会触发缺页异常。在缺页异常处理中,分配物理页面,利用分配的物理页面来创建页表项并且填充页表,完成虚拟地址到物理地址的映射关系的建立
VMA 的属性
作为一个进程地址空间的区间,VMA 是有属性的,如可读/可写、共享等属性。vm_flags 成员描述这些属性,描述了该 VMA 的全部页面信息,包括如何映射页面、访问每个页面的权限等信息,VMA 属性的标志位如下所示。
- VM_READ: 可读属性
- VM_WRITE: 可写属性
- VM_EXEC: 可执行
- VM_SHARED: 允许被多个进程共享
- VM_MAYREAD: 允许设置 VM_READ 属性
- VM_MAYWRITE: 允许设置 VM WRITE 属性
- VM_MAYEXEC: 允许设置 VM EXEC 属性
- VM_MAYSHARE: 允许设置 VM SHARED 属性
- VM_GROWSDOWN: 该 VMA 允许向低地址增长
- VM_UFFD_MISSING: 表示该 VMA 适用于用户态的缺页异常处理
- VM_PFNMAP: 表示使用纯正的 PFN,不需要使用内核的 page 数据结构来管理物理页面
- VM_DENYWRITE: 表示不允许写入
- VM_UFFD_WP: 用于页面的写保护跟踪
- VM_LOCKED: 表示该 VMA 的内存会立刻分配物理内存,并且页面被锁定,不会被交换到交换分区
- VM_IO: 表示 I/0 内存映射
- VM_SEQ_READ: 表示应用程序会顺序读该 VMA 的内容
- VM_RAND_READ: 表示应用程序会随机读该 VMA 的内容
- VM_DONTCOPY: 表示在创建分支时不要复制该 VMA
- VM_DONTEXPAND: 通过 mremapo 系统调用禁止 VMA 扩展
- VM_ACCOUNT: 在创建 IPC 以共享 VMA 时,检测是否有足够的空闲内存用于映射
- VM_HUGETLB: 用于巨页的映射
- VM_SYNC: 表示同步的缺页异常
- VM_ARCH_1: 与架构相关的标志位
- VM_WIPEONFORK: 表示不会从父进程相应的 VMA 中复制页表到子进程的 VMA 中
- VM_DONTDUMP: 表示该 VMA 不包含到核心转储文件中
- VM_SOFTDIRTY: 软件模拟实现的脏位。用于一些特殊的架构,需要打开 CONFIG_MEM_SOFT_DIRTY
- VM_MIXEDMAP: 表示混合使用了纯 PFN 以及 page 数据结构的页面,如使用 vm_insert_page() 函数插入 VMA
- VM_HUGEPAGE: 表示在 madvise 系统调用中使用 MADV_HUGEPAGE 标志位来标记该 VMA
- VM_NOHUGEPAGE: 表示在 madvise 系统调用中使用 MADV_NOHUGEPAGE 标志位来标记该 VMA
- VM_MERGEABLE: 表示该 VMA 是可以合并的,用于 KSM 机制
- VM_SPECIAL: 表示该 VMA 是不可以合并的
VMA 属性的标志位可以任意组合,但是最终要落实到硬件机制上,即页表项的属性中。VMA 属性到页表属性的转换如下图所示。vm_area_struct 数据结构中有两个成员和属性相关:一个是 vm_flags 成员,用于描述 VMA 的属性;另外一个是 vm_page_prot 成员,用于将 VMA 属性标志位转换成与处理器相关的页表项的属性,它和具体架构相关。
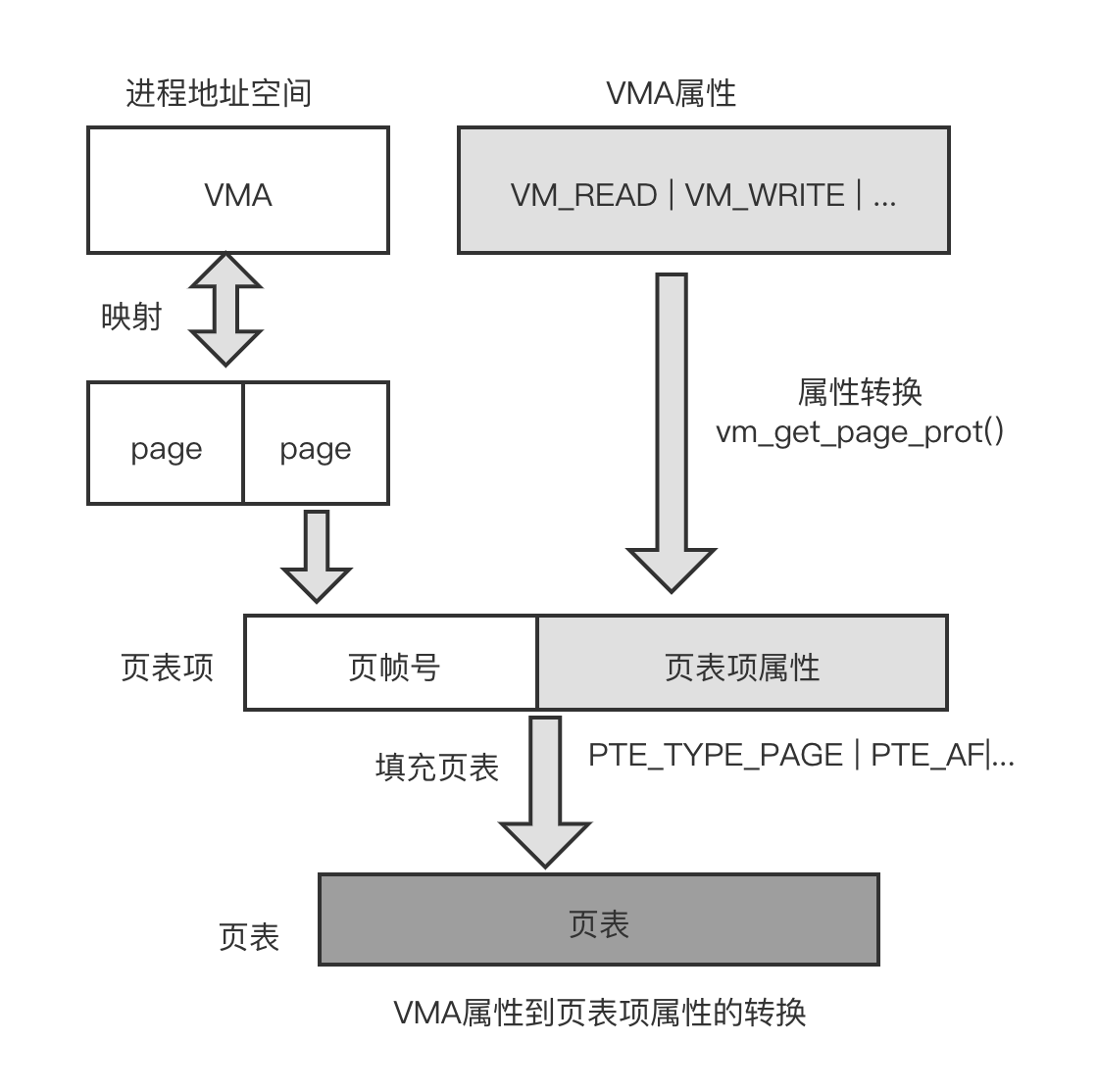
在创建一个新的 VMA 时使用 vm_get_page_prot() 函数可以把 vm_flags 标志位转化成具页表项的硬件标志位。
1 | <mm/mmap.c> |
这个转化过程得益于内核预先定义了一个内存属性数组 protection_map[], 我们只需要根据 vm_flag 标志位来查询这个数组即可,在这个场景下,通过查询 protection_map[] 数组可以获得页表属性。
1 | pgprot_t protection_map[16] __ro_after_init = { |
protection_map[] 数组的每个成员代表一个属性的组合,如__P000 表示无效的 PTE 属性,__P001 表示只读属性,__P1O0 表示可执行属性(PAGE_EXECONLY)等。
1 |
下面以只读属性(PAGE_READONLY)来看,它究竟包含哪些页表项的标志位。
1 |
把上述的宏全部展开,我们可以得到如下页表项的标志位。
- PTE_TYPE_PAGE:表示这是一个基于页面的页表项,即设置页表项的 Bit[1:O]
- PTE_AF:设置访问位
- PTE_SHARED:设置内存共享属性
- MT_NORMAL:设置内存属性为 normal
- PTE_USER:设置 AP 访问位,允许通过用户权限访问该内存
- PTE_NG:设置该内存对应的 TLB 只属于该进程
- PTE_PXN:表示该内存不能在特权模式下执行
- PTE_UXN:表示该内存不能在用户模式下执行
- PTE_RDONLY:表示只读属性
内核如何管理内存
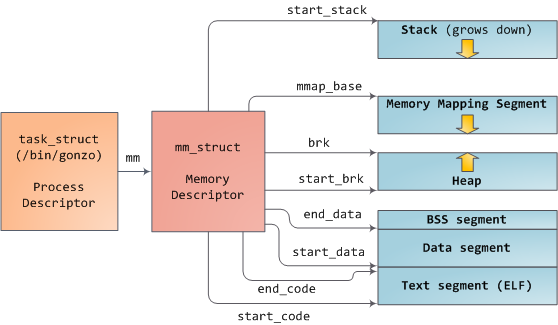
Linux 进程在内核中作为进程描述符 task_struct 的实例实现。task_struct 中的 mm 字段指向内存描述符 mm_struct ,它是程序内存的执行内容。它存储了如上所示的内存段的开始和结束、进程使用的物理内存页数(rss 代表 Resident Set Size)、使用的虚拟地址空间 以及其他信息。
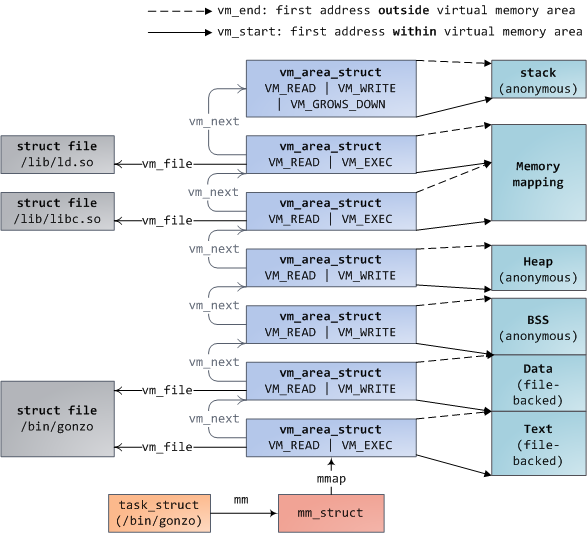
每个虚拟内存区域(VMA)是一个连续的虚拟地址范围;这些区域永远不会重叠。vm_area_struct 的实例完整地描述了一个内存区域,包括其起始和结束地址、用于确定访问权限和行为的标志,以及用于指定该区域映射的文件(如果有)的 vm_file 字段。不映射文件的 VMA 是匿名的。除了内存映射段之外,上面的每个内存段(例如,堆、堆栈)对应于单个 VMA。这不是必需的,尽管这在 x86 机器中很常见。VMA 不关心它们位于哪个段。
程序的 VMA 都以链表形式存储在其内存描述符中 mmap 字段,按起始虚拟地址排序,并作为以 mm_rb 字段为根的红黑树 。红黑树允许内核快速搜索覆盖给定虚拟地址的内存区域。当您读取文件/proc/pid_of_process/maps 时,内核只是遍历进程的 VMA 链接列表并打印每一个 VMA。
VMA 的大小必须是页面大小的倍数。处理器查阅页表以将虚拟地址转换为物理内存地址。每个进程都有自己的一组页表;每当发生进程切换时,用户空间的页表也会切换。Linux 在内存描述符的 pgd 字段中存储指向进程页表的指针。页表中的每个虚拟页都对应一个页表项 (PTE),在常规 x86 分页中,它是一个简单的 4 字节记录,如下所示:

malloc 函数
malloc() 函数是 C 标准库封装的一个核心函数,C 标准库做一些处理后会调用 Linux 的系线调用接口 brk 向系统申请内存。
brk 系统调用
brk 系统调用主要实现在 mm/mmap.c 文件中。
1 | SYSCALL_DEFINE1(brk, unsigned long, brk) |
详细流程这里不一一列出来了,下面用一张图概括 brk 的流程,如下:
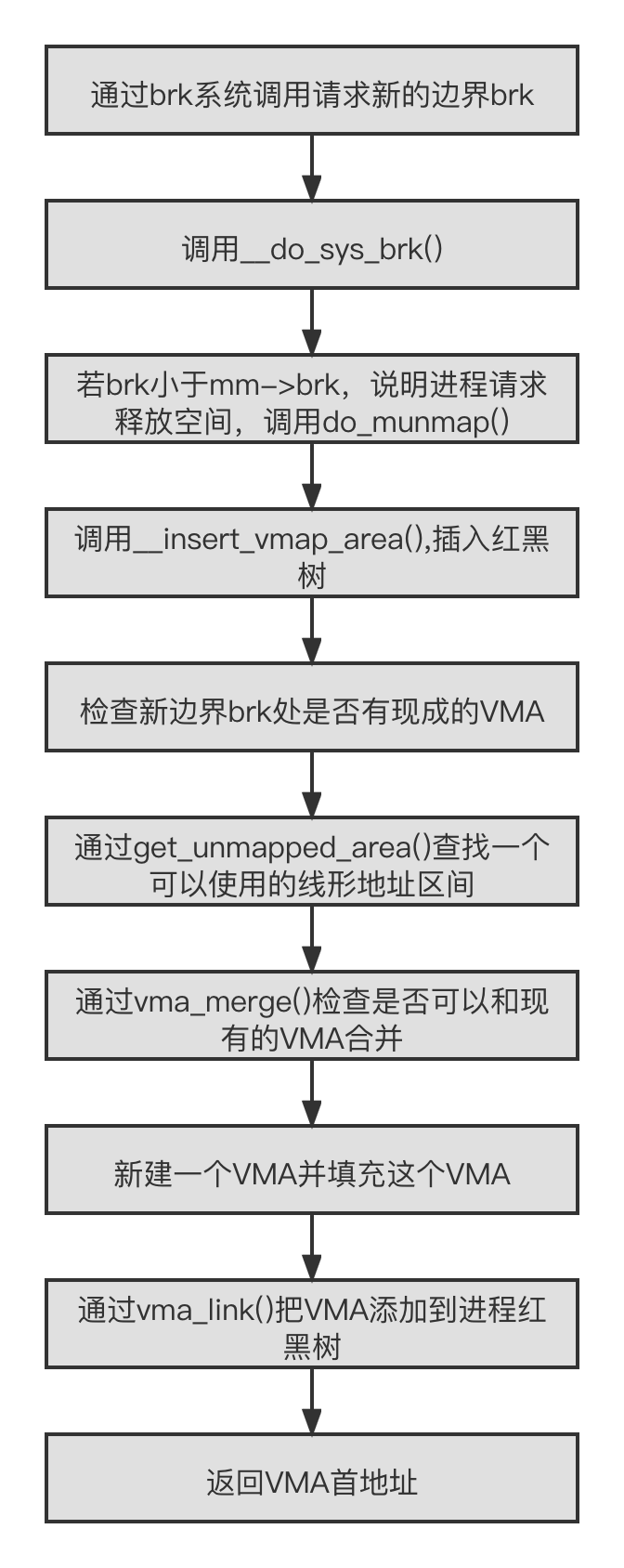
malloc 流程
假设不考虑 libc 的因素,malloc() 分配 100 字节,那么内核会分配多少字节呢?处理器的 MMU 的最小处理单元是页面,所以内核分配内存、建立虚拟地址和物理地址映射关系都以页面为单位,PAGE_ALIGN(addr)宏让地址按页面大小对齐。
下图所示为 malloc() 函数的实现流程。
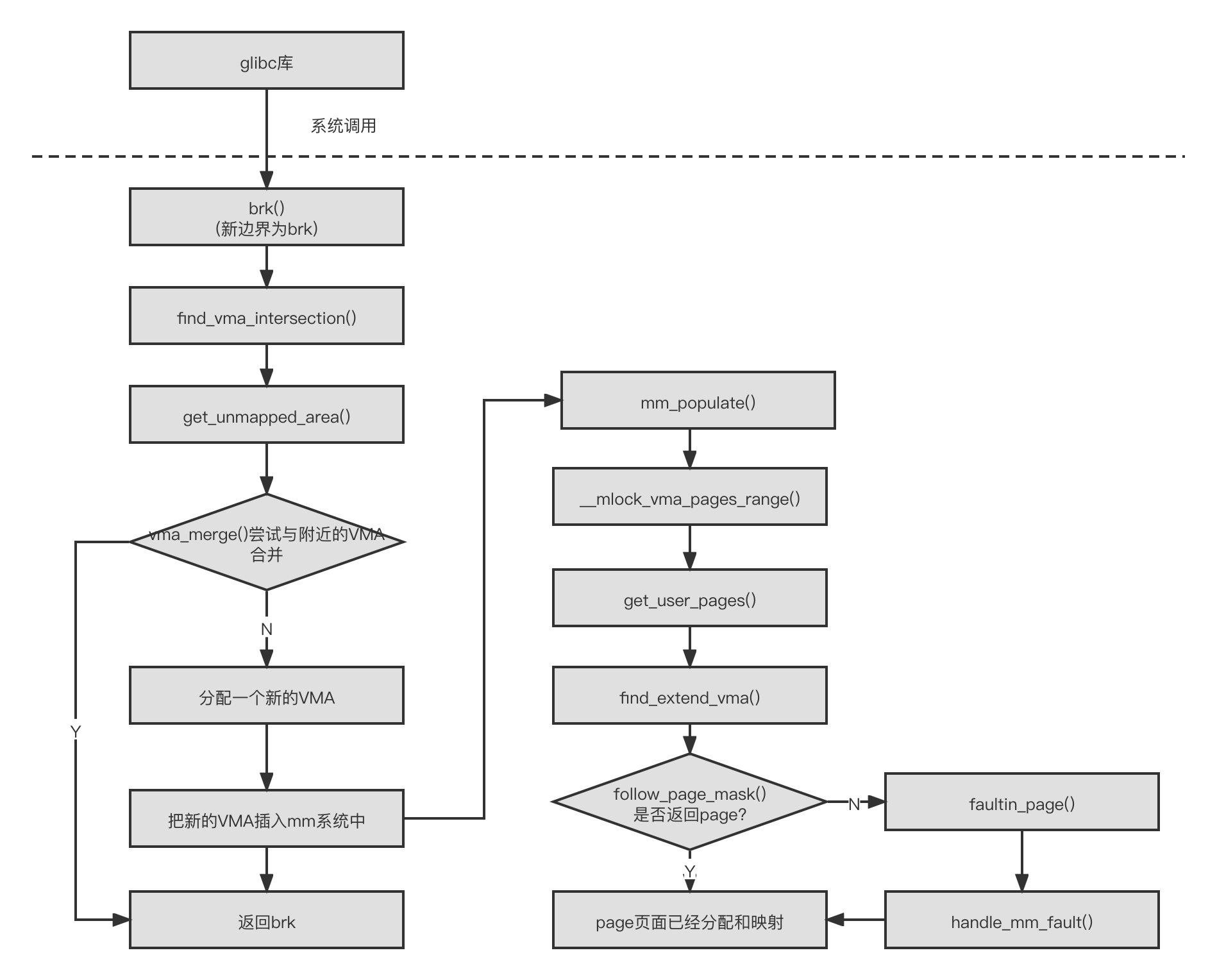
mmap 函数
mmap/munmap 函数是用户空间中常用的系统调用函数,无论是在用户程序中分配内存、读写大文件、链接动态库文件,还是多进程间共享内存,都可以看到 mmp/munmap() 函数的身影。mmp/munmap 函数的声明如下。
1 |
|
mmap/munmap 函数的参数如下。
- addr:用于指定映射到进程地址空间的起始地址,为了提高应用程序的可移植性,一般设置为 NULL,让内核来分配一个合适的地址
- length:表示映射到进程地址空间的大小
- prot:用于设置内存映射区域的读写属性等
- flags:用于设置内存映射的属性,如共享映射、私有映射等
- fd:表示这是一个文件映射,fd 是打开的文件的句柄
- offset:在文件映射时,表示文件的偏移量。prot 参数通常表示映射页面的读写权限,有如下参数组合
- PROT_EXEC:表示映射的页面是可以执行的
- PROT_READ:表示映射的页面是可以读取的
- PROT_WRITE:表示映射的页面是可以写入的
- PROT_NONE:表示映射的页面是不可访问的
flags 参数是一个很重要的参数,可以设置为以下值。
- MAP_SHARED:创建一个共享映射的区域。多个进程可以通过共享映射方式来映射一个文件,这样其他进程也可以看到映射内容的改变,修改后的内容会同步到磁盘文件中
- MAP_PRIVATE:创建一个私有的写时复制的映射。多个进程可以通过私有映射的方式来映射一个文件,这样其他进程不会看到映射内容的改变,修改后的内容也不会同步到磁盘文件中
- MAP_ANONYMOUS:创建一个匿名映射,即没有关联到文件的映射
- MAP_FIXED:使用参数 addr 创建映射,如果在内核中无法映射指定的地址,那么 mmap 会返回失败,参数 addr 要求按页对齐。如果 addr 和 length 指定的进程地址空间和已有的 VMA 重叠,那么内核会调用 do_munmapO 函数把这段重叠区域销毁,然后重新映射新的内容
- MAP_POPULATE:对于文件映射来说,会提前预读文件内容到映射区域,该特性只支持私用映射
通过参数 fd 可以看出 mmap 映射是否和文件相关联,因此在 Linux 内核中,映射可以分成匿名映射和文件映射。
- 匿名映射:没有映射对应的相关文件,匿名映射的内存区域的内容会初始化为 0
- 文件映射:映射和实际文件相关联,通常把文件内容映射到进程地址空间,这样应用程序就可以像操作进程地址空间一样读写文件
私有匿名映射
当使用参数 fd=-1 且 flags = MAP_ANONYMOUS|MAP_PRIVATE 时,创建的 mmap 映射是私有匿名映射。私有匿名映射常见的用途是在 glbc 分配大内存块时,如果需要分配的内存大 MMAP_THREASHOLD(128KB),glibc 会默认使用 mmap 代替 brk 来分配内存。
共享匿名映射
当使用参数 fd=-1 且 flags = MAP_ANONYMOUS | MAP_SHARED 时,创建的 mmap 映射是共享匿名映射。共享匿名映射让相关进程共享一块内存区域,通常用于父、子进程之间的通信创建共享匿名映射有如下两种方式。
- 使 fd=-1 且 flags = MAP_ANONYMOUS | MAP_SHARED。在这种情况下,do_mmap_pgoffO->mmap_region() 函数最终会调用 shmem_zero_setup():来打开一个特殊的“/dev/zero”设备文件
- 直接打开“/dev/zero”设备文件,然后使用这个文件句柄来创建 mmap
上述两种方式最终都调用 shmem 模块来创建共享匿名映射。
私有文件映射
创建文件射时如果 flags 设置为 MAPP_PRIVATE,就会创建私有文件映射。私有文件映射常用的场景是加载动态共享库。
共享文件映射
创建文件映射时,如果 flags 设置为 MAP_SHARED,就会创建共享文件映射。如果 prot 参数指定了 PROT_WRITE,那么打开文件时需要指定 O_RDWR 标志位。共享文件映射通常有 mmap 如下两个常用的场景。
- 读写文件。把文件内容映射到进程地址空间,同时对映射的内容做了修改,内核的回写(writeback)机制最终会把修改的内容同步到磁盘中
- 进程间通信。进程之间的进程地址空间相互隔离,一个进程不能访问另外一个进程的地址空间。如果多个进程同时映射到一个文件,就实现了多进程间的共享内存通信。如果一个进程对映射内容做了修改,那么另外的进程是可以看到的
小结
mmap 机制在 Linux 内核中实现的代码框架和 brk 机制非常类似,其中有很多关于 VMA 的操作。mmap 机制和缺页中断机制结合在一起会变得复杂很多。mmap 机制在 Linux 内核中的实现流程如图所示。
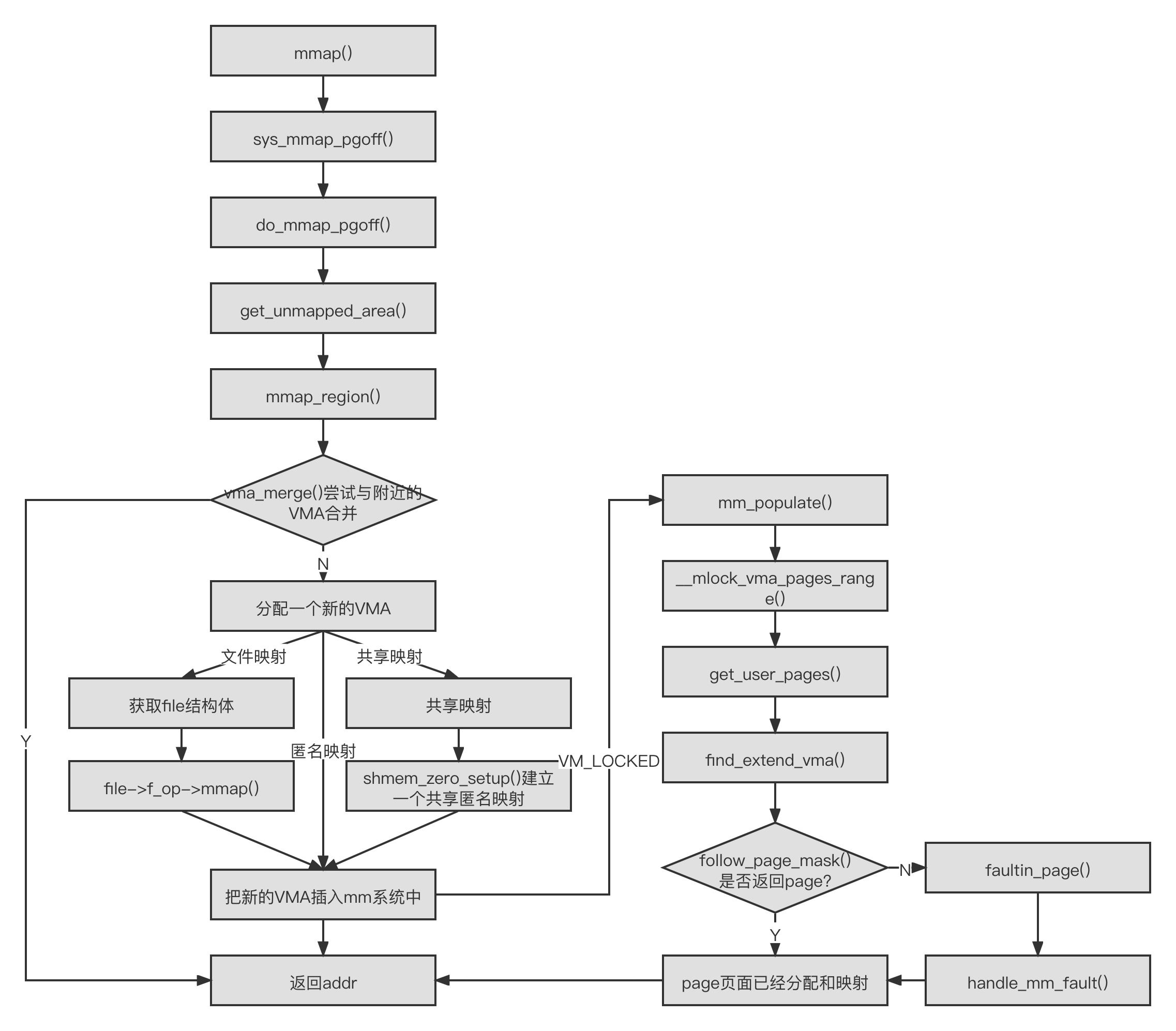
参考文献
https://letrungthang.blogspot.com/2010/12/chuyen-tiet-kiem-mua-nha-cua-gioi.html
《奔跑吧 Linux 内核》





