
Linux 内存管理(九)页面迁移和内存规整
声明本文转载自知乎 Linux 内存管理:页面迁移 和 Linux 内存管理 (16) 内存规整 内存相关文章
页面迁移
概述
页面迁移 (migrate) 是内存管理中很多功能实现的基础,比方说内存规整、NUMA balance、内存热插拔、CMA、HugeTLB、内存气球等等,本文主要讲一下页面迁移的主要流程和应用。
页面迁移的 API
migrate_pages( ) 这是页面迁移在内核态的主要接口,内核中涉及到页面迁移的功能大都会调到它。当然,在用户空间也存在着内存迁移相关的系统调用,最终也会调到它。这里我们通过 migrate_pages( ) 的几个形参展开全文。
1 | /* |
形参含义根据上面的注释很好理解,我们单独说下 mode 和 reason,他们分别表示迁移模式和迁移原因。
迁移模式
迁移模式主要会影响迁移过程中对一些行为的过滤:
1 | MIGRATE_ASYNC //异步迁移,过程中不会发生阻塞 |
举例:内存规整 (compact) 中会调用 migrate_pages(),同时也会设置迁移模式(位于 compact_control->mode)。若是 sysfs 主动触发的内存规整会用 MIGRATE_SYNC 模式;若是 kcompactd 触发的规整会用 MIGRATE_SYNC_LIGHT 模式;若是内存分配 slowpath 中触发的会根据 compact prior 去设置用 MIGRATE_ASYNC 或 MIGRATE_SYNC_LIGHT 模式。
迁移原因
迁移原因主要使用来记录是什么功能触发了迁移的行为,毕竟页面迁移对系统本身是个不小的 overhead,所以知道迁移的原因很有必。
1 | MR_COMPACTION //内存规整导致的迁移 |
延伸:对上面 MR_SYSCALL 迁移原因中提到的两个 API(位于 libnuma 库)的简单介绍。
1 | // 含义:把某 pid 进程的所有页面从源 numa node 迁移到目标 numa nodes 组中,对应系统调用 sys_migrate_pages() |
migrate_pages() 介绍
通过上面对迁移原因的介绍,我们知道了页面迁移的原因各种各样,这里我们通过内存规整 (memory compact) 这样一个实际的例子展开介绍,下图主要体现了内存规整和页面迁移的关系:
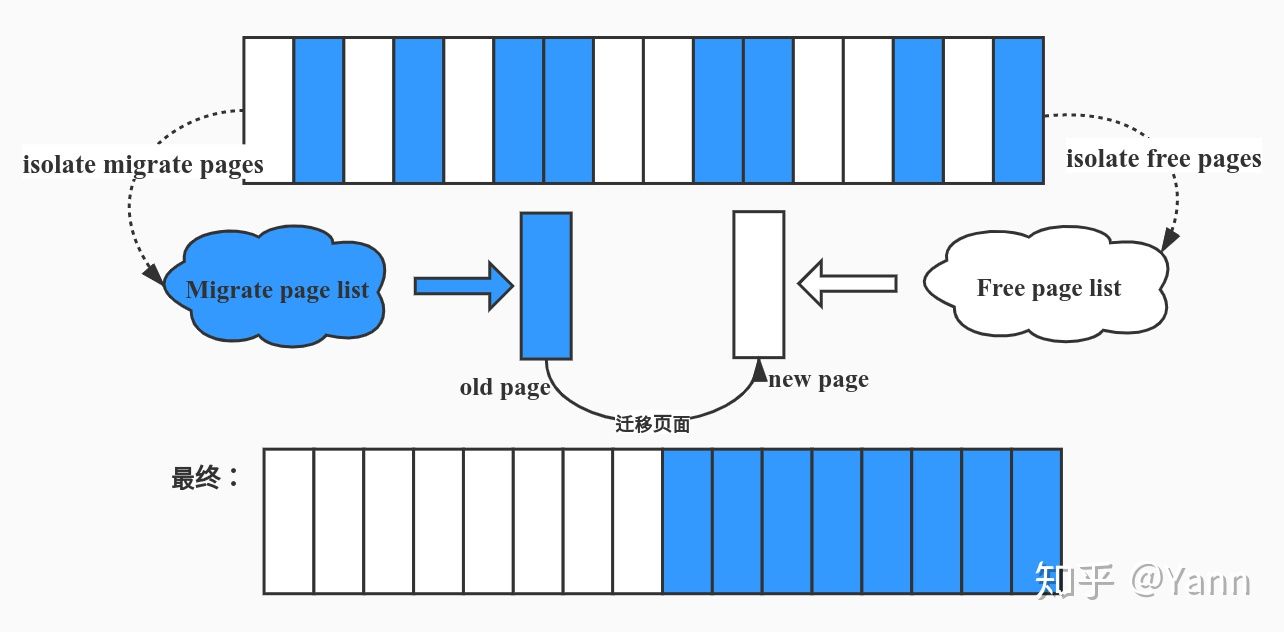
通过上图,我们看出页面迁移在内存规整中举足轻重的地位。下面则是内存规整调用 migrate_pages() 的函数关系:
1 | compact_zone //内存规整 |
现在切入重点,页面迁移 (migrate) 过程做了那些事情:
迁移前的准备
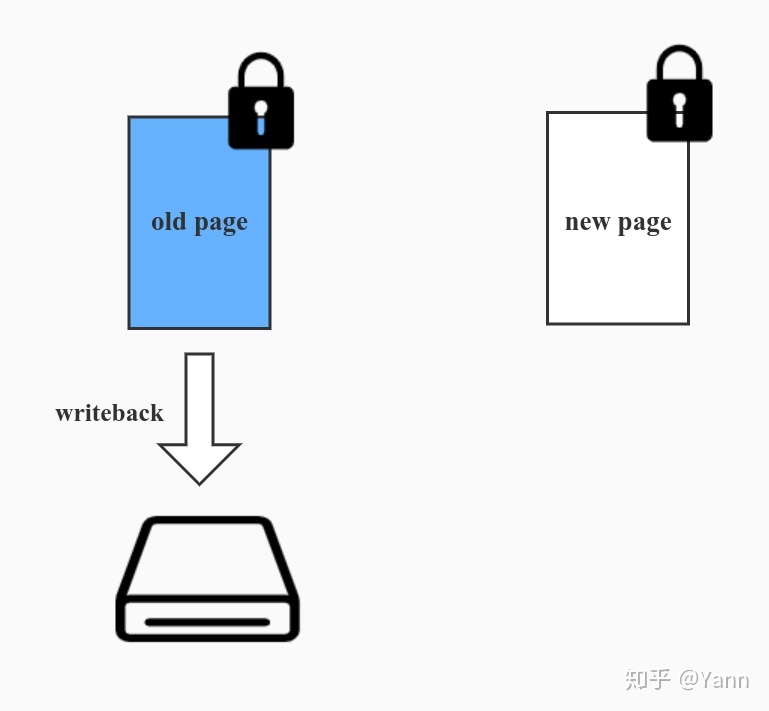
- 获取 old page 的页面锁 PG_locked (异步模式拿不到锁就直接跳过此页面)
- 若是正在 writeback 的页面,则根据迁移模式判断是否等待页面 wirteback(MIGRATE_SYNC_LIGHT 和 MIGRATE_ASYNC 不等待)
- 获取 new page 的页面锁 PG_locked (new page 正常情况下不会获取失败)
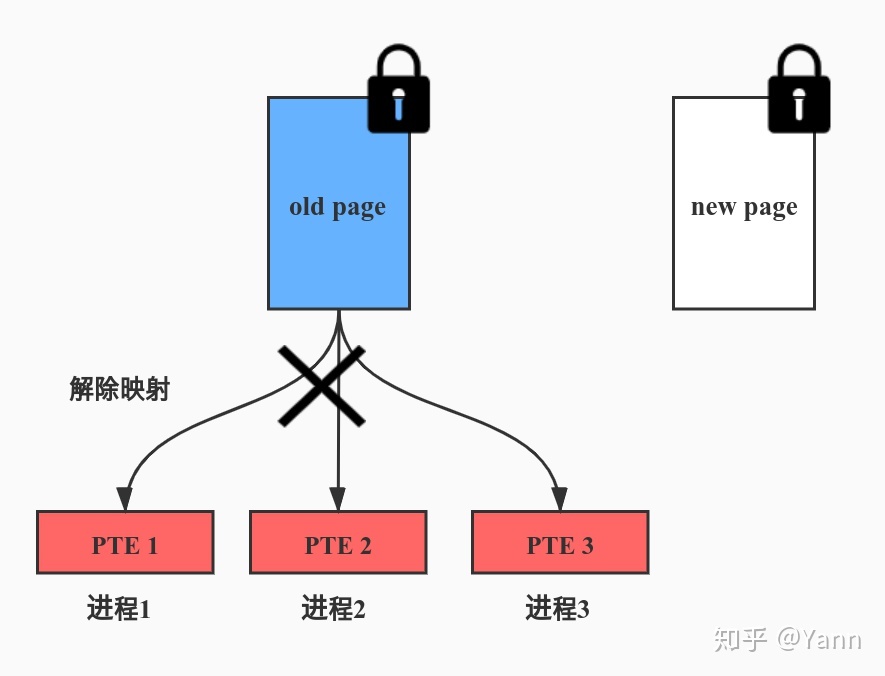
解除 old page 的页表映射
调用 try_to_unmap(),通过反向映射机制解除 old page 所有相关的 PTEs
设置 new page 的页面内容、元数据及映射关系
调用 move_to_new_page 拷贝 old page 的内容和 struct page 元数据到 new page,并通过反向映射机制建立 new page 的映射关系。
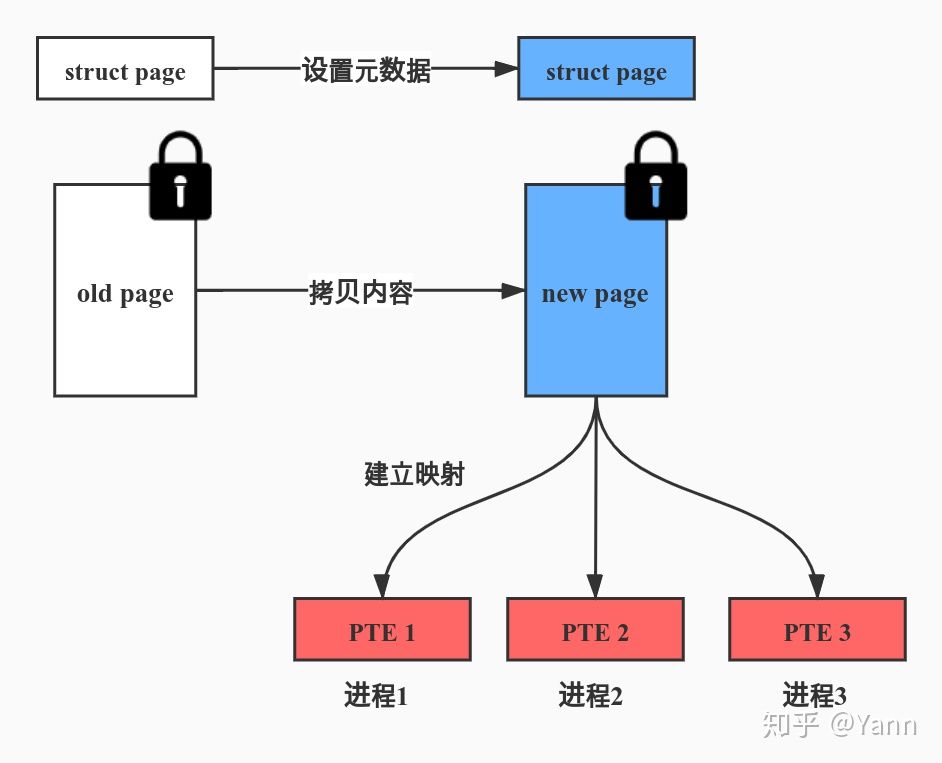
页面迁移的收尾工作
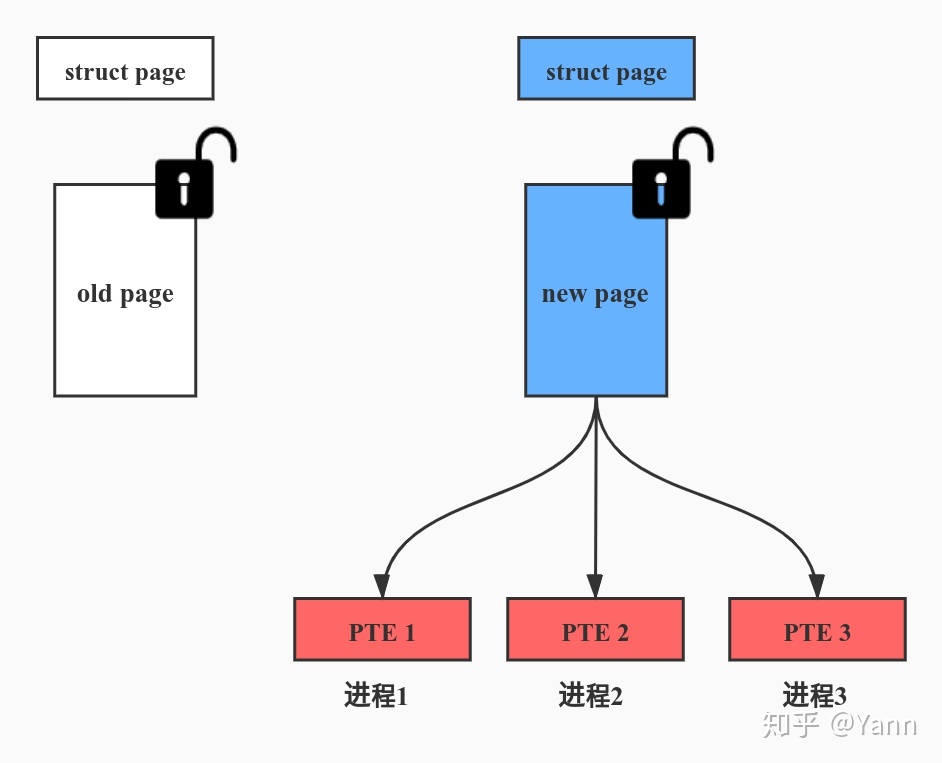
- 迁移完成释放新旧页面的 PG_locked
- 设置迁移原因
- 调用 put_page 释放 old page 引用计数 (_refcount 减 1)
补充:什么样的页面才支持迁移呢?
- lru 上的 page,因为上面挂的是 user spcace 用的 pages,都是从 buddy 分配器 migrate type 为 movable 或 reclaim 的 pageblock 上分来的
- no-lru 但是 movable 的页面。no-lru 的页面通常是为 kernel space 分配的 page,这种页面通常是 unmovable 的,但是下面这个 commit 使得驱动中用到的页面也可以支持迁移。但是在驱动实现的过程中需要置位 page->mapping 中的 second bit,并且实现 page->mapping->a_ops 中的相关方法
内存规整
内存碎片的产生:伙伴系统以页为单位进行管理,经过大量申请释放,造成大量离散且不连续的页面。这时就产生了很多碎片。 n 内存规整也即内存碎片整理,内存碎片也是以页面为单位的。实现基础是内存页面按照可移动性进行分组。内存规整的实现基础是页面迁移。
Linux 内核以 pageblock 为单位来管理页的迁移属性。
内存规整的触发
下面是内存页面分配,以及分配失败之后采取的措施,以便促成分配成功。
可以看出采取的措施,越来越重。首先采用 kswapd 来进行页面回收,然后尝试页面规整、直接页面回收,最后是 OOM 杀死进程来获取更多内存空间
1 | alloc_pages-------------------------------------页面分配的入口 |
另一条路径是在 kswapd 的 balance_pgdat 中会判断是否需要进行内存规整。
1 | kswapd |
其中 compact_pddat->__compact_pgdat->compact_zone,最终的实现和__alloc_pages_direct_compact 调用 compact_zone 一样。
内存规整相关节点
内存规整相关有两个节点,compact_memory 用于触发内存规整;extfrag_threshold 影响内核决策是采用内存规整还是直接回收来满足大内存分配。
节点入口代码:
1 | static struct ctl_table vm_table[] = { |
-
/proc/sys/vm/compact_memory:
打开 compaction Tracepoint:echo 1 > /sys/kernel/debug/tracing/events/compaction/enable
触发内存规整:sysctl -w vm.compact_memory=1
查看 Tracepoint:cat /sys/kernel/debug/tracing/trace -
/proc/sys/vm/extfrag_threshold:
在 compact_zone 中调用函数 compaction_suitable->__compaction_suitable 进行判断是否进行内存规整
和 extfrag_threshold 相关部分如下,如果当前 fragindex 不超过 sysctl_extfrag_threshold,则不会继续进行内存规整
所以这个参数越小越倾向于进行内存规整,越大越不容易进行内存规整1
2
3
4
5
6
7
8
9
10static unsigned long __compaction_suitable(struct zone *zone, int order,
int alloc_flags, int classzone_idx)
{
...
fragindex = fragmentation_index(zone, order);
if (fragindex >= 0 && fragindex <= sysctl_extfrag_threshold)
return COMPACT_NOT_SUITABLE_ZONE;
return COMPACT_CONTINUE;
}设置 extfrag_threshold:sysctl -w vm.extfrag_threshold=500
-
其它 Debug 信息:
/sys/kernel/debug/extfrag/extfrag_index
/sys/kernel/debug/extfrag/unusable_index
参考文献
https://zhuanlan.zhihu.com/p/270366827
https://www.bbsmax.com/A/ZOJPrQgodv/





