
Linux 进程管理(六)总结
一个例子
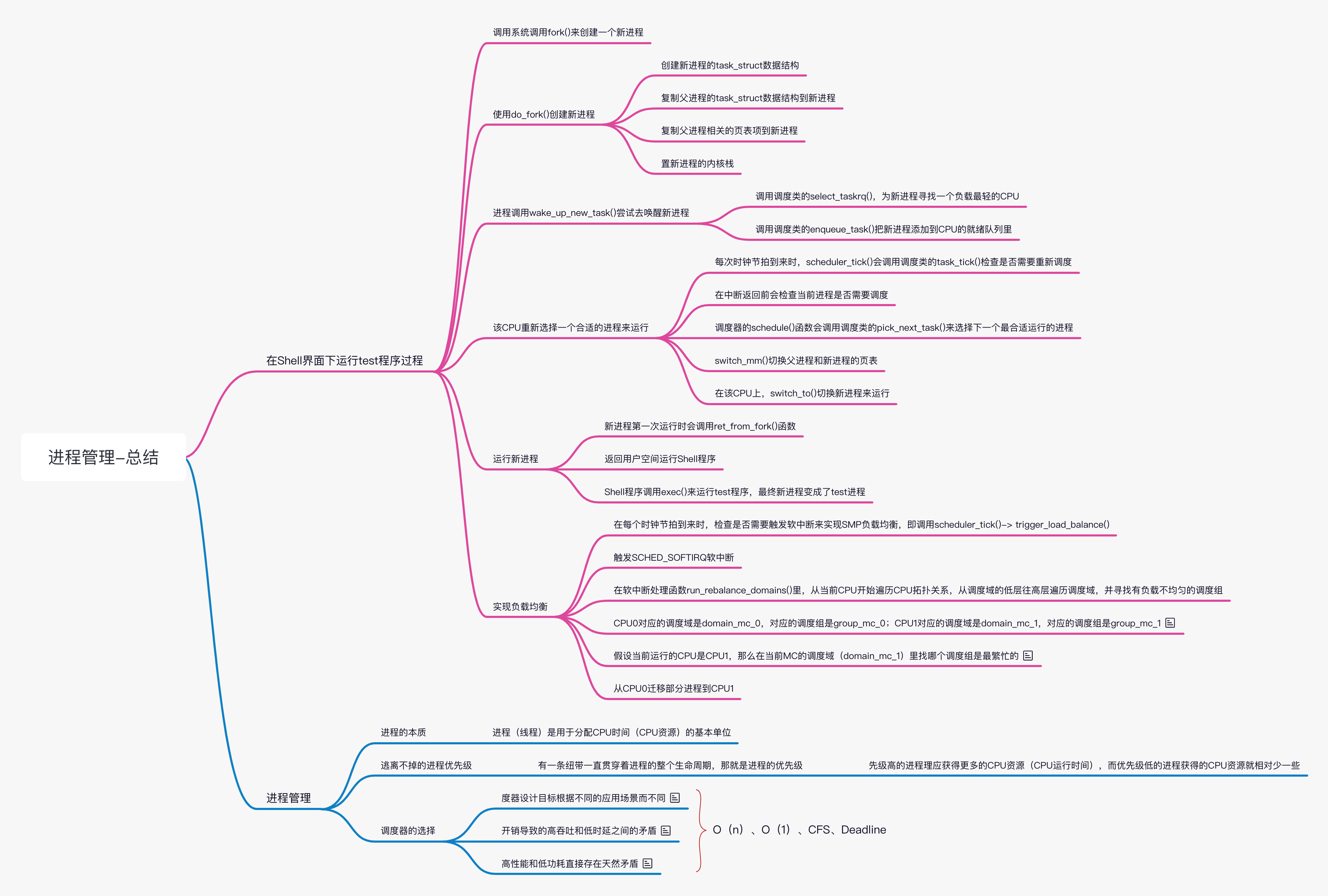
下面给出一个综合案例,在一个双核处理器的系统中,在 Shell 界面下运行 test 程序。CPUO 的就绪队列中有 4 个进程,而 CPU1 的就绪缓队列中有 1 个进程。test 程序和这 5 个进程的 nice 值都为 0。
1 |
|
站在用户空间的角度看问题,我们只能看到 test 程序被运行了,但是我们看不到新进程是如何创建的、它会添加到哪个 CPU 里、它是如何运行的,以及 CPU0 和 CPU1 之间如何做负载均衡等。
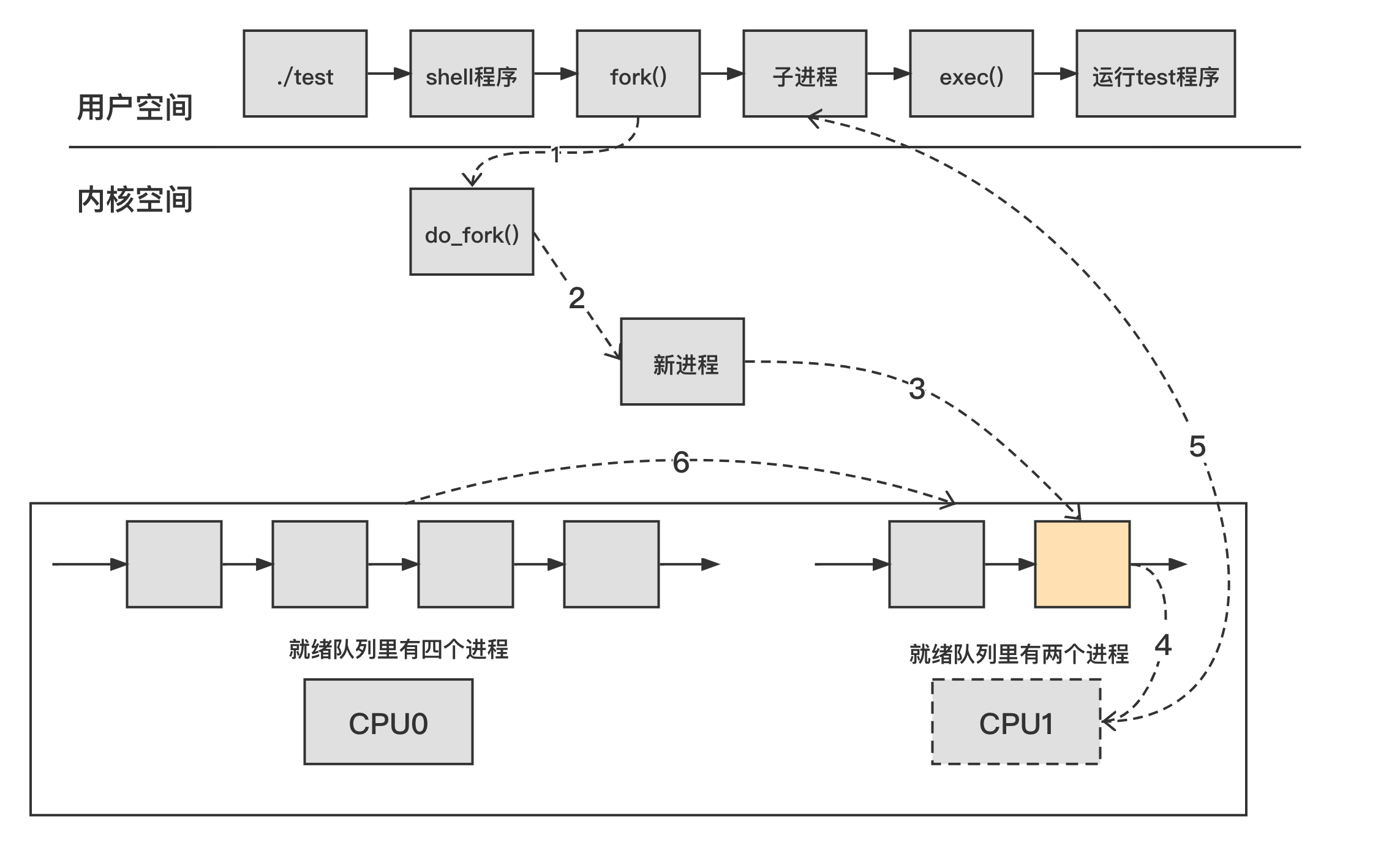
其中的操作步骤如下:
-
调用系统调用 fork() 来创建一个新进程
-
使用 do_fork() 创建新进程:
- 创建新进程的 task_struct 数据结构
- 复制父进程的 task_struct 数据结构到新进程
- 复制父进程相关的页表项到新进程
- 设置新进程的内核栈
-
父进程调用 wake_up_new_task() 尝试去唤醒新进程:
- 调用调度类的 select_taskirq(),为新进程寻找一个负载最轻的 CPU,这里选择 CPU1
- 调用调度类的 enqueue_task() 把新进程添加到 CPU1 的就绪队列里
-
CPU1 重新选择一个合适的进程来运行:
- 每次时钟节拍到来时,scheduler_tick() 会调用调度类的 task_tick() 检查是否需要重新调度。check_preempt_tick() 会做检查,当需要重新调度时会设置当前进程的 thread_info 中的 TIF_NEED_RESCHED 标志位。假设这时 CPU1 准备调度新进程,就会设置当前进程的 thread_info 中的 TIF_NEED_RESCHED 标志位
- 在中断返回前会检查当前进程是否需要调度。如果需要调度,调用 preempt_schedule_irq() 来切换进程运行
- 调度器的 schedule() 函数会调用调度类的 pick_next_task() 来选择下一个最合适运行的进程。在该场景中,选择新进程
- switch_mm() 切换父进程和新进程的页表
- 在 CPU1 上,switch_to() 切换新进程来运行
-
运行新进程:
- 新进程第一次运行时会调用 ret_from_fork() 函数
- 返回用户空间运行 Shell 程序
- Shell 程序调用 exec() 来运行 test 程序,最终新进程变成了 test 进程
-
实现负载均衡:
- 在每个时钟节拍到来时,检查是否需要触发软中断来实现 SMP 负载均衡,即调用 scheduler_tick()-> trigger_load_balance()。下一次实现负载均衡的时间点存放在就绪队列的 next_balance 成员里。
- 触发 SCHED_SOFTIRQ 软中断
- 在软中断处理函数 run_rebalance_domains() 里,从当前 CPU 开始遍历 CPU 拓扑关系,从调度域的低层往高层遍历调度域,并寻找有负载不均匀的调度组。本例子中的 CPU 拓扑关系很简单,只有一层 MC 层级的调度域
- CPU0 对应的调度域是 domain_mc_0,对应的调度组是 group_mc_0;CPU1 对应的调度域是 domain_mc_1,对应的调度组是 group_mc_1。CPU0 的调度域 domain_mc_0 管辖 CPU0 和 CPU1,其中 group_mc_0 和 group_mc_1 这两个调度组会被链接到 domain_mc_0 的一个链表中。同理,CPU1 的调度域 domain_mc_1 管理着 group_mc_1 和 group_mc_0 这两个调度组
- 假设当前运行的 CPU 是 CPU1,也就是说,运行 run_rebalance_domains() 函数的 CPU 为 CPU1,那么在当前 MC 的调度域(domain_mc_1)里找哪个调度组是最繁忙的。很容易发现 CPU0 的调度组(group_mc_0)是最繁忙的,然后计算需要迁移多少负载到 CPU1 上才能保持两个调度组负载平衡
- 从 CPU0 迁移部分进程到 CPU1
调度的流程
假设 Linux 内核只有 3 个线程,线程 0 创建了线程 1 和线程 2,它们永远不会退出。当系统时钟中断到来时,时钟中断处理函数会检查是否有进程需要调度。当有进程需要调度时,调度器会选择运行线程 1 或者线程 2。
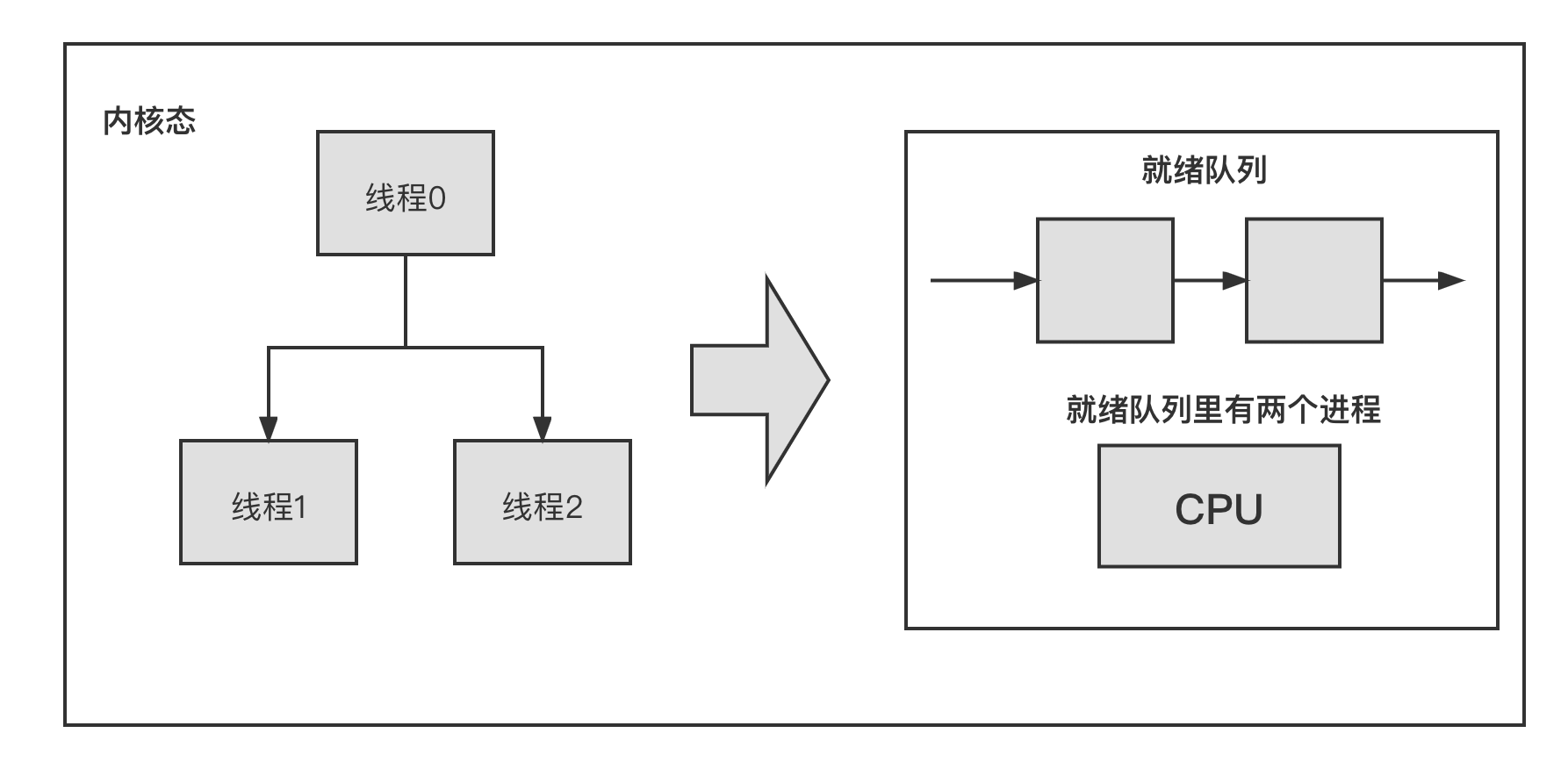
假设线程 0 先运行,那么在这个场景下会发生什么情况?
这是一个有意思的问题,涉及调度器的实现机制、中断处理、内核抢占、新建进程如何被调度、进程切换等知识点。我们只有把这些知识点都弄明白了,才能真正搞明白这个问题。
场景分析
这个场景中的主要操作步骤如下:
- start_kernel() 运行在线程 0 里。线程 0 创建了线程 1 和线程 2。函数调用关系是 start_kernel()->kerne_thread()->_do_fork()。在_do_fortk() 函数会创建新线程,并且把新线程添加到调度器的就绪队列中。线程 0 创建线程 1 和线程 2 后,进入 while 死循环,线程 0 不会退出,它正在等待被调度出去
- 产生时钟中断。时钟中断是普通外设中断的一种,调度器利用时钟中断来定时检测当前正在运行的线程是否需要调度
- 当时钟中断检测到当前线程需要调度时,设置 need_resched 标志位
- 当时钟中断返回时,根据 Linux 内核是否支持内核抢占来确定是否需要调度,下面分两种情况来讨论
- 支持内核抢占的内核:发生在内核态的中断返回时,检查当前线程的 need_resched 标志位是否置位,如果置位,说明当前线程需要调度
- 不支持内核抢占的内核:发生在内核态的中断在返回时不会检查是否需要调度
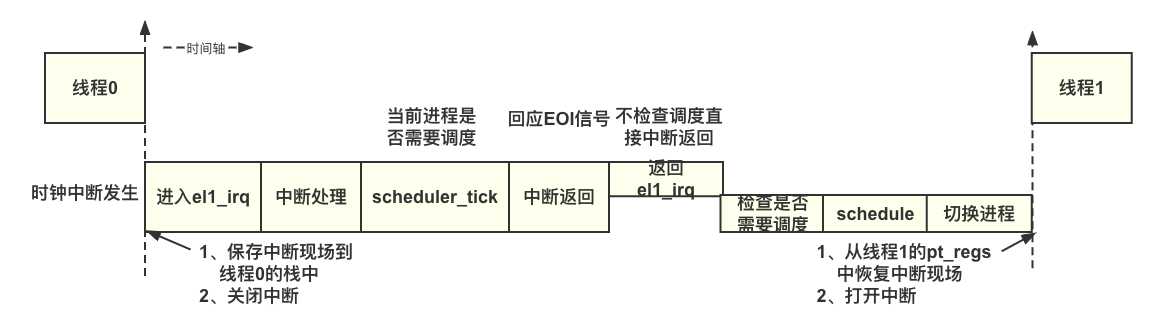
在不支持内核抢占功能的 Linux 内核里,即使线程 0 的 need_resched 标志位置位置位了,Linux 内核也不会调度线程 1 或者线程 2。只有发生在用户态的中断返回或者系统调用返回用户空间时,才会检查是否需要调度。在不支持抢占的 Linux 内核中,判断与调度的流程如下图所示。
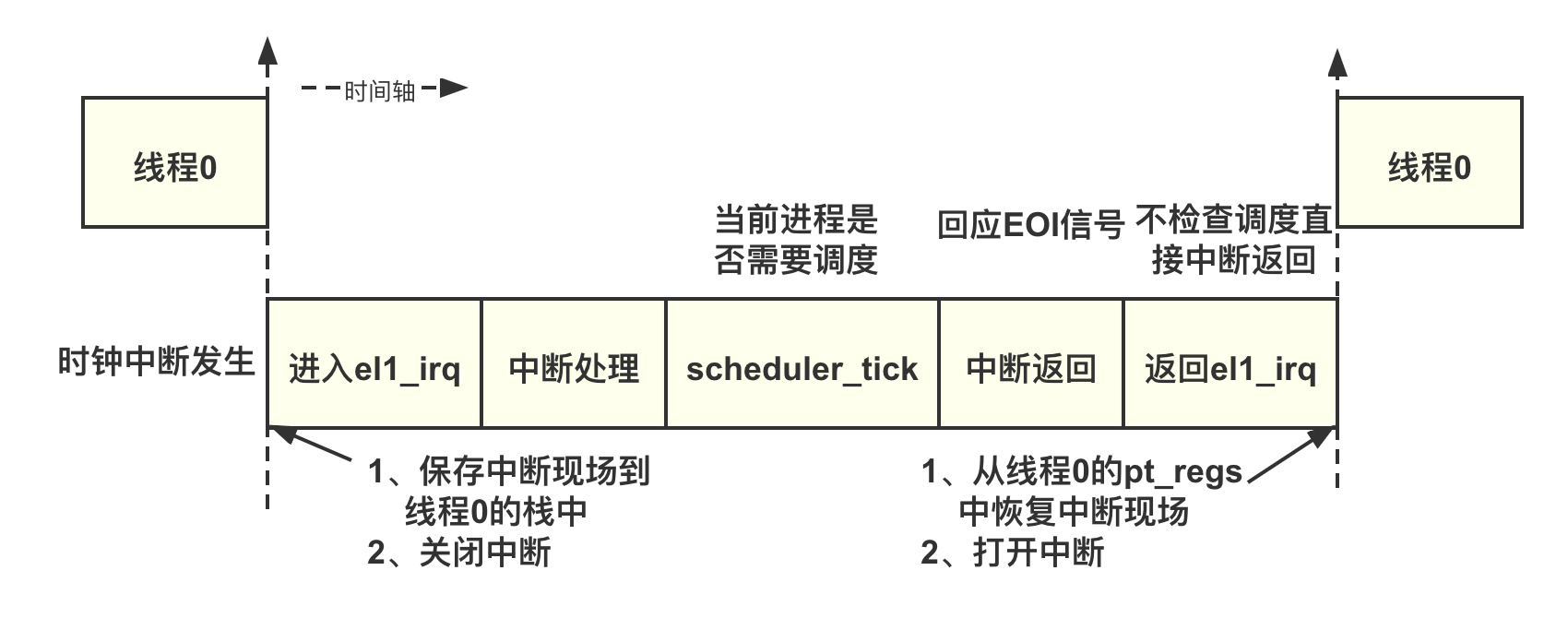
- 发生时钟中断。触发时钟中断时当前进程(线程)有可能在用户态执行,也可能在内核态执行。如果进程运行在用户态时发生了中断,那么会进入异常向量表的 el0_irq 汇编函数:如果进程运行在内核态时发生了中断,那么会进入异常向量表的 el1_irq 汇编函数中。在本场景中,因为 3 个线程都是内核线程,所以时钟中断只能跳转到 el1_irq 汇编函数里。当进入中断时 CPU 会自动关闭中断
- 在 el1_irq 汇编函数里,首先会保存中断现场(也称为中断上下文)到当前进程的栈中,Linux 内核使用 pt_regs 数据结构来实现 pt_regs 栈框,用来保存中断现场
- 中断处理过程包括切换到 Linux 内核的中断栈、硬件中断号的查询、中断服务程序的处理等
- 当确定当前中断源是时钟中断后,scheduler_tick() 函数会去检查当前进程的是否需要调度。如果需要调度,则设置当前进程的 need_resched 标志位(thread_info 中的 TIF_NEED_RESCHED 标志位)
- 中断返回。这里需要给中断控制器返回一个中断结束(End Of Interrupt,EOI)信号
- 在 el1_irq 汇编函数直接恢复中断现场,这里会使用线程 0 的 pt_regs 来恢复中断现场在不支持内核抢占的系统里,el1_irq 汇编函数不会检查是否需要调度。在中断返回时,CPU 打开中断,然后从中断的地方开始继续执行进程 0
在支持内核抢占功能的 Linux 内核中,中断返回时会检查当前进程是否设置了 need_resched 标志位置位。如果置位,那么调用 preempt schedule_irq() 函数以调度其他进程(线程)并运行。如下图所示,在支持内核抢占的 Linux 内核中,中断与调度的流程和下图略有不一样。在 el1_irq 汇编函数即将返回中断现场时,判断当前进程是否需要调度。如果需要调度,调度器会选择下一个进程,并且进行进程的切换。如果选择了线程 1,则从线程 1 的 pt_regs 中恢复中断现场并打开中断,然后继续执行内核线程 1 的代码。
如何让新进程执行
可能读者会有如下疑问:
- 如果线程 1 是新创建的,它的栈应该是空的,那它第一次运行时如何恢复中断现场呢?
- 如果不能从线程 1 的栈中恢复中断现场,那是不是线程 1 一直在关闭中断的状态下运行?
对于内核线程来说,在创建时会对如下两部分内容进行设置与保存。
- 进程的硬件上下文。它是保存在进程中的 cpu_context 数据结构,进程硬件上下文包括 X19~X28 寄存器、FP 寄存器、SP 寄存器以及 PC 寄存器。对于 ARM64 处理器来说,设置 PC 寄存器为 ret_from_fork,即指向 ret_from_fork 汇编函数。设置 SP 寄存器指向栈的 pt_regs 栈框
- ptregs 栈框
上述操作是在 copy_thread() 函数里实现的。
1 | <arch/arm64/kernel/process.c> |
stack_stat 指向内核线程的回调函数,而 x20 指向回调函数的参数。
在进程切换时,switch_to() 函数会完成进程硬件上下文的切换,即把下一个进程 (next 进程)的 cpu_context 数据结构保存的内容恢复到处理器的寄存器中,从而完成进程的切换。此时,处理器开始运行 next 进程了。根据 PC 寄存器的值、外理器会从 ret_from_fork 汇编函数里开始执行,新进程的执行过程如下图所示。
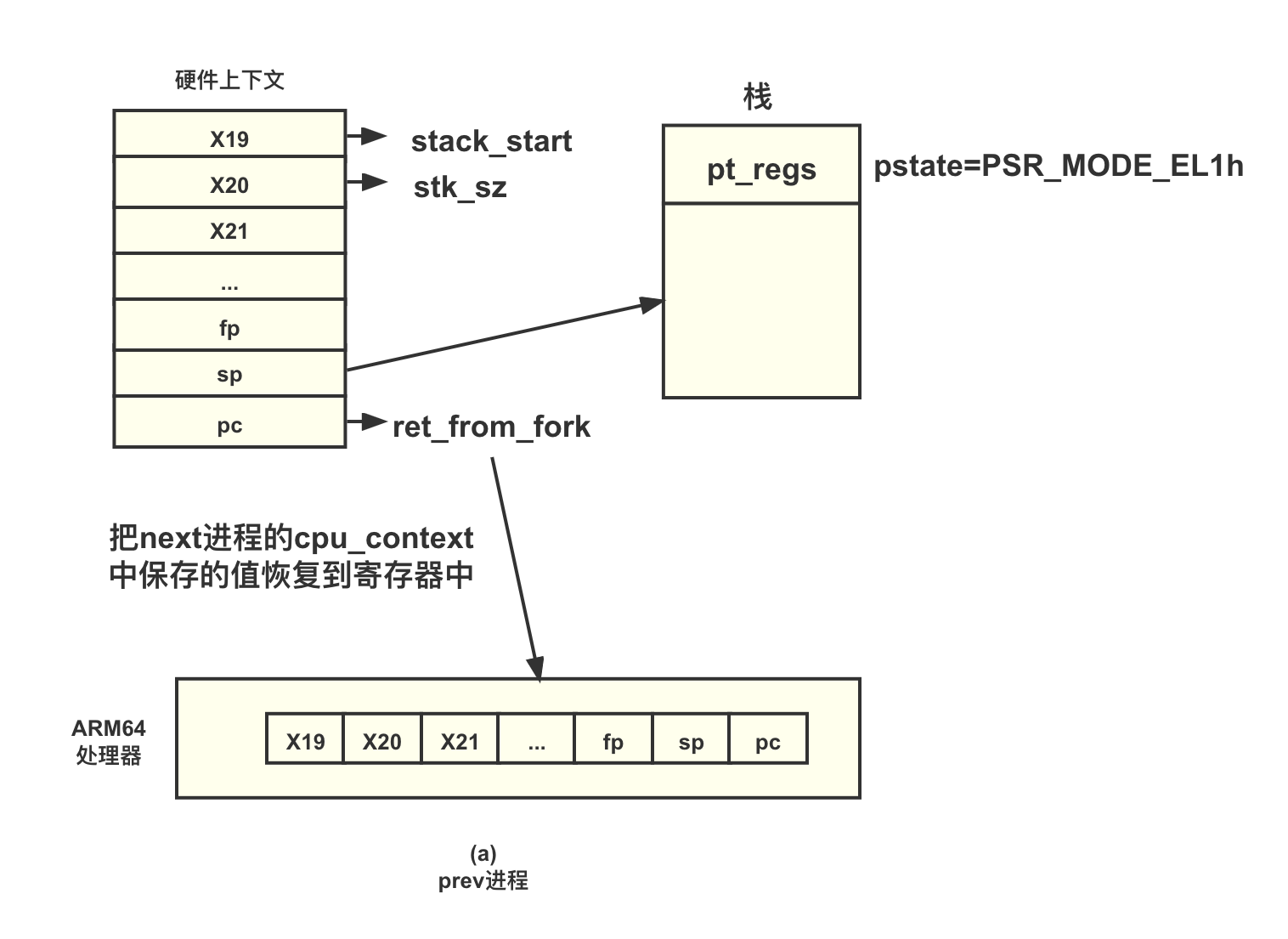
ret_from_fork 汇编函数实现在 arch/arm64/kernel/entry.S 文件中。
1 | SYM_CODE_START(ret_from_fork) |
在第 2 行中,调用 schedule_tail() 函数来对 prev 进程做收尾工作。在 finish_lock_switch() 函数里会调用 raw_spin_unlock_irq() 函数来打开本地中断。因此,next 进程是运行在打开中断的环境下的。
在第 3 行中,判断 next 线程是否为内核线程。如果 next 进程是内核线程,在创建时会设置 X19 寄存器指向 stack_start。如果 X19 寄存器的值为 0,说明这个 next 进程是用户进程,直接跳转到第 6 行,调用 ret_to_user 汇编函数,返回用户空间
在第 4~5 行中,如果 next 进程是内核线程,那么直接跳转到内核线程的回调函数里。
综上所述,当处理器切换到内核线程 1 时,它从 ret_from_fork 汇编函数开始执行 Schedule_tail() 函数会打开中断,因此,不用担心内核线程 1 在关闭中断的状态下运行。另外,此时,线程 1 不会从中断现场返回,因为到目前为止,线程 1 还没有触发任何一个中断。那么对于线程 0 触发的中断现场怎么处理呢?中断现场保存在中断进程的栈里,只有当调度器再、次调度该进程时,它才会从栈中恢复中断现场,然后继续运行该进程。
调度的本质
下面是一个常见的思考题
1 | raw_local_irq_disable()//关闭本地中断 |
有读者这么认为,假设进程 A 在关闭本地中断的情况下切换到进程 B 来运行,进程 B 会在关闭中断的情况下运行,如果进程 B 一直占用 CPU,那么系统会一直没有办法响应时钟中断,系统就处于瘫痪状态。
显然,上述分析是不正确的。因为进程 B 切换执行时会打开本地中断,以防止系统瘫痪我们接下来详细分析这个问题。
调度与中断密不可分,而调度的本质是选择下一个进程来运行。理解调度有如下几个关键点。
- 什么情况下会触发调度?
- 如何合理和高效选择下一个进程?
- 如何切换到下一个进程来执行?
- 下一个进程如何返回上一次暂停的地方?
我们以一个场景为例,假设系统中只有一个用户进程 A 和一个内核线程 B,在不考虑自愿调度和系统调用的情况下,请描述这两个进程(线程)是如何相互切换并运行的。
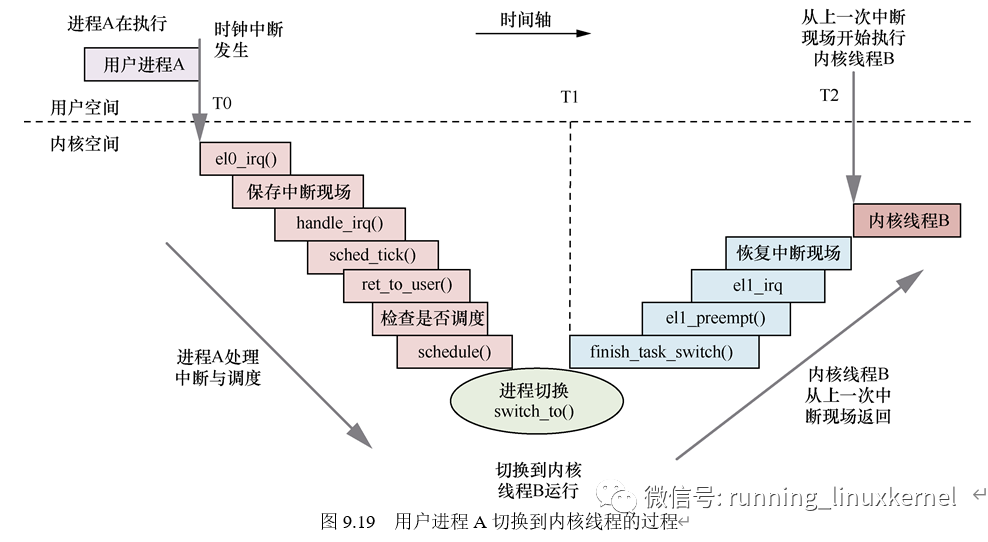
如图所示,用户进程 A 切换到内核线程 B 的过程如下。
- 假设在 T0 时刻之前,用户进程 A 正在用户空间运行
- 在 T0 时刻,时钟中断发生
- CPU 打断正在运行的用户进程 A,处于异常模式。CPU 会跳转到异常向量表中的 el0_irq 里。在 el0_irq 汇编函数里,首先把中断现场保存到进程 A 的 pt_regs 栈框中
- 处理中断
- 调度滴答处理函数。在调度滴答处理中,检查当前进程是否需要调度。如果需要调度,则设置当前进程的 need_resched 标志位(thread_info 中的 TIF_NEED_RESCHED 标志位)
- 中断处理完成之后,返回 el0_irq 汇编函数里。在即将返回中断现场前,ret_to_user 汇编函数会检查当前进程是否需要调度
- 若当前进程序需要调度,则调用 schedule() 函数来选择下一个进程并进行进程切换
- 在 switch_to() 函数里进行进程切换
- T1 时刻,switch_to() 函数返回时,CPU 开始运行内核线程 B 了
- CPU 沿着内核线程 B 保存的栈帧回溯,一直返回。返回路径为 finish_task_switch()->el1_preempt()->el1_irq
- 在 el1_irq 汇编函数里把上一次发生中断时保存在栈里的中断现场讲行恢复,最后从上一次中断的地方开始执行内核线程 B 的代码
从栈帧的角度来观察,进程调度的栈帧变化情况如下图所示。
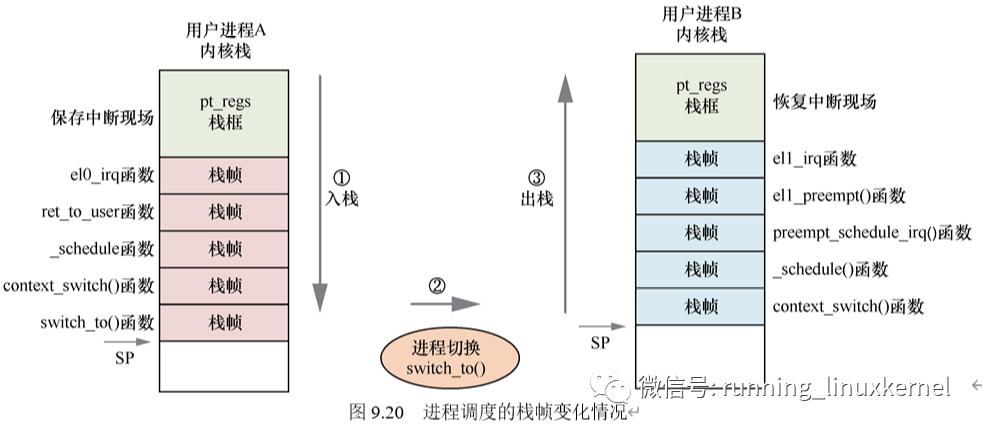
首先,对于用户进程 A,从中断触发到进程切换这段时间内,内核栈的变化情况如图 9.20 左边视图所示,栈的最高地址位于 pt_regs 栈框,用来保存中断现场。
然后,依次保存 el0_irq 汇编函数、ret_to_user 汇编函数、_schedule() 函数、context_switch() 函数以及 switch_to() 函数的栈帧,此时 SP 寄存器指向 switch_to() 函数栈帧,这个过程称为压栈。
接下来,切换进程。
switch_to() 函数返回之后,即完成了进程切换。此时,CPU 的 SP 寄存器指向了内核线程 B 的内核栈中的 switch_to() 函数栈帧。CPU 沿着栈帧一直返回,并且恢复了上一次保存在 pt_regs 栈框的中断现场,最后跳转到内核线程 B 中断的地方并开始执行,这个过程称为出栈。
参考文献
《奔跑吧 Linux 内核》
《Linux 内核设计与实现》
[[LinuxTaskSMP]]
[[LinuxTaskExt]]
[[LinuxTaskCFS]]
[[LinuxTaskDebug]]
[[LinuxTaskBasic]]
[[LinuxTaskCreate]]
[[LinuxTaskSummery]]





