
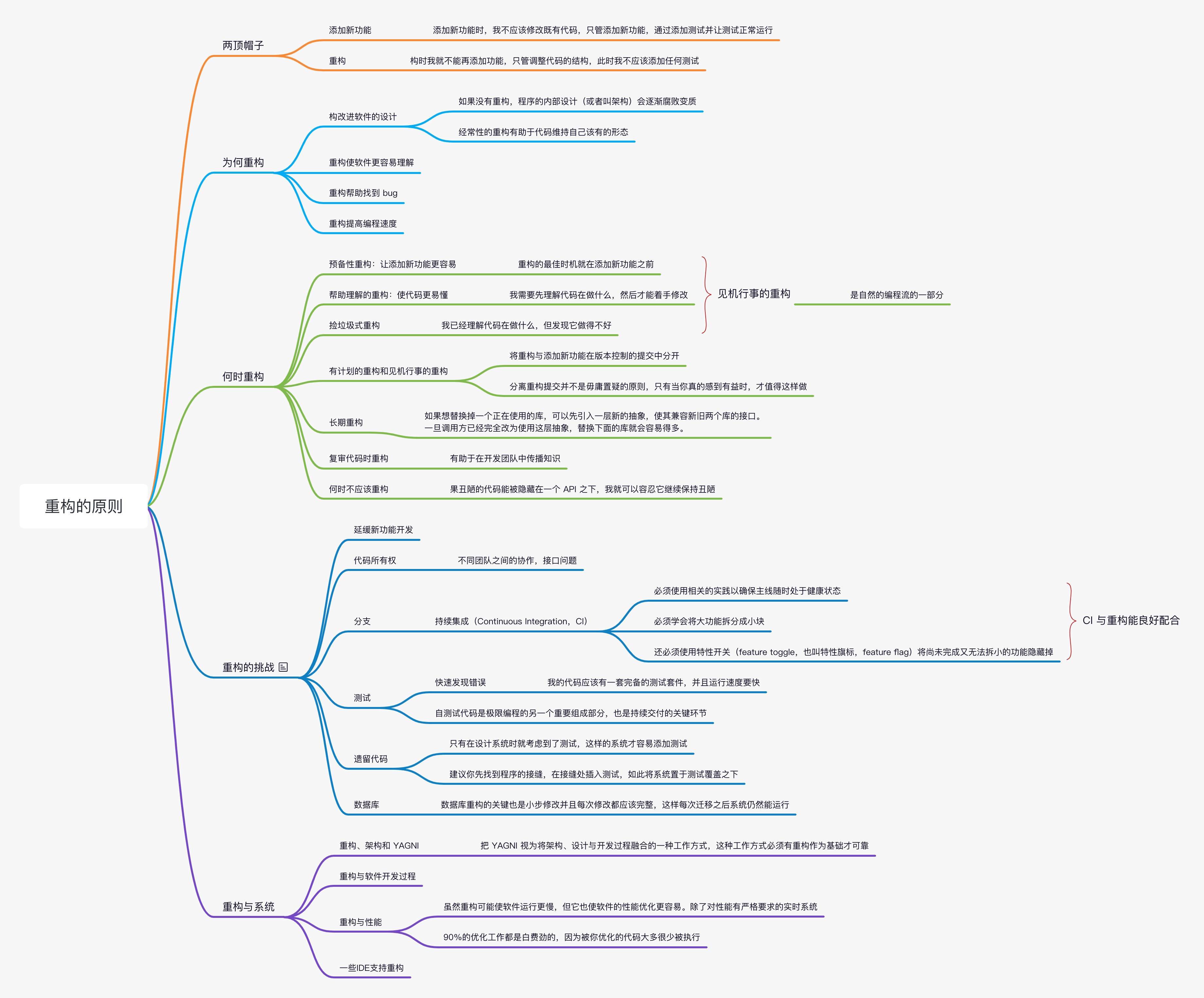
重构(一)重构的原则
何谓重构
“重构”这个词既可以用作名词也可以用作动词。
- 重构(名词):对软件内部结构的一种调整,目的是在不改变软件可观察行为的前提下,提高其可理解性,降低其修改成本。
- 重构(动词):使用一系列重构手法,在不改变软件可观察行为的前提下,调整其结构。
重构的关键在于运用大量微小且保持软件行为的步骤,一步步达成大规模的修改。每个单独的重构要么很小,要么由若干小步骤组合而成。因此,在重构的过程中,我的代码很少进入不可工作的状态,即便重构没有完成,我也可以在任何时刻停下来。
Tip
如果有人说他们的代码在重构过程中有一两天时间不可用,基本上可以确定,他们在做的事不是重构。
在上述定义中,我用了“可观察行为”的说法。它的意思是,整体而言,经过重构之后的代码所做的事应该与重构之前大致一样。这个说法并非完全严格,并且我是故意保留这点儿空间的:重构之后的代码不一定与重构前行为完全一致。比如说,提炼函数会改变函数调用栈,因此程序的性能就会有所改变;改变函数声明和搬移函数等重构经常会改变模块的接口。不过就用户应该关心的行为而言,不应该有任何改变。如果我在重构过程中发现了任何 bug,重构完成后同样的 bug 应该仍然存在。
两顶帽子
Kent Beck 提出了“两顶帽子”的比喻。使用重构技术开发软件时,我把自己的时间分配给两种截然不同的行为:添加新功能和重构。添加新功能时,我不应该修改既有代码,只管添加新功能。通过添加测试并让测试正常运行,我可以衡量自己的工作进度。重构时我就不能再添加功能,只管调整代码的结构。此时我不应该添加任何测试,只在绝对必要(用以处理接口变化)时才修改测试。
软件开发过程中,我可能会发现自己经常变换帽子。首先我会尝试添加新功能,然后会意识到:如果把程序结构改一下,功能的添加会容易得多。于是我换一顶帽子,做一会儿重构工作。程序结构调整好后,我又换上原先的帽子,继续添加新功能。新功能正常工作后,我又发现自己的编码造成程序难以理解,于是又换上重构帽子……整个过程或许只花 10 分钟,但无论何时我都清楚自己戴的是哪一顶帽子,并且明白不同的帽子对编程状态提出的不同要求。
为何重构
重构改进软件的设计
如果没有重构,程序的内部设计(或者叫架构)会逐渐腐败变质。当人们只为短期目的而修改代码时,他们经常没有完全理解架构的整体设计,于是代码逐渐失去了自己的结构。程序员越来越难通过阅读源码来理解原来的设计。代码结构的流失有累积效应。越难看出代码所代表的设计意图,就越难保护其设计,于是设计就腐败得越快。经常性的重构有助于代码维持自己该有的形态。
消除重复代码,我就可以确定所有事物和行为在代码中只表述一次,这正是优秀设计的根本。
重构使软件更容易理解
用于协作
重构帮助找到 bug
对代码的理解,可以帮我找到 bug。我承认我不太擅长找 bug。有些人只要盯着一大段代码就可以找出里面的 bug,我不行。但我发现,如果对代码进行重构,我就可以深入理解代码的所作所为,并立即把新的理解反映在代码当中。搞清楚程序结构的同时,我也验证了自己所做的一些假设,于是想不把 bug 揪出来都难。
重构提高编程速度
最后,前面的一切都归结到了这一点:重构帮我更快速地开发程序。
有的团队:
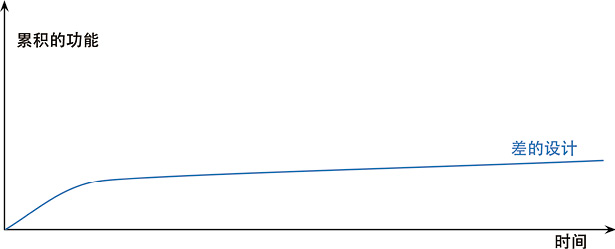
但有些团队的境遇则截然不同。他们添加新功能的速度越来越快,因为他们能利用已有的功能,基于已有的功能快速构建新功能。
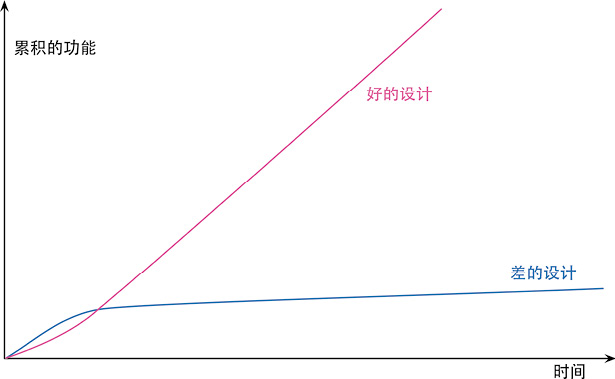
两种团队的区别就在于软件的内部质量。良好的模块划分使我只需要理解代码库的一小部分,就可以做出修改。如果代码很清晰,我引入 bug 的可能性就会变小,即使引入了 bug,调试也会容易得多。理想情况下,我的代码库会逐步演化成一个平台,在其上可以很容易地构造与其领域相关的新功能。
20 年前,行业的陈规:良好的设计必须在开始编程之前完成,因为一旦开始编写代码,设计就只会逐渐腐败。重构改变了这个图景。现在我们可以改善已有代码的设计,因此我们可以先做一个设计,然后不断改善它,哪怕程序本身的功能也在不断发生着变化。
何时重构
预备性重构:让添加新功能更容易
重构的最佳时机就在添加新功能之前。在动手添加新功能之前,我会看看现有的代码库,此时经常会发现:如果对代码结构做一点微调,我的工作会容易得多。
修复 bug 时的情况也是一样。在寻找问题根因时,我可能会发现:如果把 3 段一模一样且都会导致错误的代码合并到一处,问题修复起来会容易得多。或者,如果把某些更新数据的逻辑与查询逻辑分开,会更容易避免造成错误的逻辑纠缠。用重构改善这些情况,在同样场合再次出现同样 bug 的概率也会降低。
帮助理解的重构:使代码更易懂
我需要先理解代码在做什么,然后才能着手修改,这些都是重构的机会。
看代码时,我会在脑海里形成一些理解,但我的记性不好,记不住那么多细节。正如 Ward Cunningham 所说,通过重构,我就把脑子里的理解转移到了代码本身。随后我运行这个软件,看它是否正常工作,来检查这些理解是否正确。如果把对代码的理解植入代码中,这份知识会保存得更久,并且我的同事也能看到。
捡垃圾式重构
帮助理解的重构还有一个变体:我已经理解代码在做什么,但发现它做得不好,例如逻辑不必要地迂回复杂,或者两个函数几乎完全相同,可以用一个参数化的函数取而代之,我会马上重构它;如果重构需要花一些精力,我可能会拿一张便笺纸把它记下来,完成当下的任务再回来重构它。
有计划的重构和见机行事的重构
上面的例子——预备性重构、帮助理解的重构、捡垃圾式重构——都是见机行事的:我并不专门安排一段时间来重构,而是在添加功能或修复 bug 的同时顺便重构,这是我自然的编程流的一部分。
Tip
还有一种常见的误解认为,重构就是人们弥补过去的错误或者清理肮脏的代码。当然,如果遇上了肮脏的代码,你必须重构,但漂亮的代码也需要很多重构。
如果团队过去忽视了重构,那么常常会需要专门花一些时间来优化代码库,以便更容易添加新功能。在重构上花一个星期的时间,会在未来几个月里发挥价值。有时,即便团队做了日常的重构,还是会有问题在某个区域逐渐累积长大,最终需要专门花些时间来解决。但这种有计划的重构应该很少,大部分重构应该是不起眼的、见机行事的。
何时不应该重构
如果我看见一块凌乱的代码,但并不需要修改它,那么我就不需要重构它。如果丑陋的代码能被隐藏在一个 API 之下,我就可以容忍它继续保持丑陋。只有当我需要理解其工作原理时,对其进行重构才有价值。
另一种情况是,如果重写比重构还容易,就别重构了。
重构、架构和 YAGNI
与其猜测未来需要哪些灵活性、需要什么机制来提供灵活性,我更愿意只根据当前的需求来构造软件,同时把软件的设计质量做得很高。随着对用户需求的理解加深,我会对架构进行重构,使其能够应对新的需要。如果一种灵活性机制不会增加复杂度,我可以很开心地引入它;但如果一种灵活性会增加软件复杂度,就必须先证明自己值得被引入。如果不同的调用者不会传入不同的参数值,那么就不要添加这个参数。当真的需要添加这个参数时,运用函数参数化也很容易。要判断是否应该为未来的变化添加灵活性,我会评估“如果以后再重构有多困难”,只有当未来重构会很困难时,我才考虑现在就添加灵活性机制。我发现这是一个很有用的决策方法。
这种设计方法有很多名字:简单设计、增量式设计或者 YAGNI——“你不会需要它”(you arenʼt going to need it)的缩写。YAGNI 并不是“不做架构性思考”的意思,不过确实有人以这种欠考虑的方式做事。我把 YAGNI 视为将架构、设计与开发过程融合的一种工作方式,这种工作方式必须有重构作为基础才可靠。
重构与软件开发过程
重构的第一块基石是自测试代码。我应该有一套自动化的测试,我可以频繁地运行它们,并且我有信心:如果我在编程过程中犯了任何错误,会有测试失败。
如果一支团队想要重构,那么每个团队成员都需要掌握重构技能,能在需要时开展重构,而不会干扰其他人的工作。这也是我鼓励持续集成的原因:有了 CI,每个成员的重构都能快速分享给其他同事,不会发生这边在调用一个接口那边却已把这个接口删掉的情况;如果一次重构会影响别人的工作,我们很快就会知道。自测试的代码也是持续集成的关键环节,所以这三大实践——自测试代码、持续集成、重构——彼此之间有着很强的协同效应。
有这三大实践在手,我们就能运用前一节介绍的 YAGNI 设计方法。重构和 YAGNI 交相呼应、彼此增效,重构(及其前置实践)是 YAGNI 的基础,YAGNI 又让重构更易于开展:比起一个塞满了想当然的灵活性的系统,当然是修改一个简单的系统要容易得多。在这些实践之间找到合适的平衡点,你就能进入良性循环,你的代码既牢固可靠又能快速响应变化的需求。
有这三大核心实践打下的基础,才谈得上运用敏捷思想的其他部分。持续交付确保软件始终处于可发布的状态,很多互联网团队能做到一天多次发布,靠的正是持续交付的威力。即便我们不需要如此频繁的发布,持续集成也能帮我们降低风险,并使我们做到根据业务需要随时安排发布,而不受技术的局限。有了可靠的技术根基,我们能够极大地压缩“从好点子到生产代码”的周期时间,从而更好地服务客户。这些技术实践也会增加软件的可靠性,减少耗费在 bug 上的时间。
参考文献
《重构 改善既有代码的设计》
https://book-refactoring2.ifmicro.com/docs/ch2.html
[[RefactorPart3]]
[[RefactorPart2]]
[[RefactorPart1]]





