
RTOS 的设计
何为实时性?
RTOS 的实时性该怎么理解呢?快速?确定性?
从中断控制器视角看实时性
我们知道一般都是 Cortex-M 跑 RTOS,Cortex-A 很少跑 RTOS,一般都是跑 Linux、Android 这些非实时系统。如果单纯从速度来看 A 核在高主频加持下一定会具有更快的速度才对呀,那 M 核的竞争力在哪里呢?实际上这就是 A 核和 M 核在设计上的两个不同方向的取舍。
首先我们看 NVIC 中断控制器的设计:
- 中断延迟波动很小:NVIC 支持中断嵌套,这样即使当前中断在处理中且非常耗时也没关系,因为可以通过高优先级的中断来响应更紧急的事件,这样中断延迟就不依赖与中断处理时间了,从设计上保证了延迟的确定性。
- 中断延迟小:NVIC 在不同的中断会跳转到不同地址运行,且可以直接在硬中断上下文中执行中断程序,这样整个 pipeline 很短,且 NVIC 还支持尾链这个概念进一步降低延迟(当高优先级的 ISR 抢占低优先级 ISR 时,处理器会跳过上下文保存和恢复,直接处理第二个 ISR,没有任何额外的开销)。通常 NVIC 中断响应时间在十几到几十 ns 之间。
NVIC 中断控制器在实时性上是满足要求的,快速和确定性都满足,但是他不适合处理大量中断,假如每秒要处理成千上万(这个中断数量对于 A 核来讲是很常见的 UAC、UVC,DSP 等一个模块每秒可能就有几千个中断)个中断,那么对 NVIC 来讲这是灾难性的,各种嵌套设计各种性能评估,除此之外对于多核系统 NVIC 也没有一套将中断分配给各个 CPU 核的机制,那么就无法充分利用多核的优势提高中断处理能力。而 A 核的 GIC 控制器就是为解决这些问题而设计的。
Cortex-A 核的 GIC 中断控制器设计很复杂,但是不支持中断嵌套,由 Distributor、CPU interface、Redistributor、ITS 组成,Distributor 具有仲裁和分发的作用,会将中断发送给 Redistributor,Redistributor 将中断发送给 CPU interface。这样第一解决了多核问题,其次 GIC 没有中断嵌套,当中断发生后跳转到一个固定地址,然后判断中断源进行下一步跳转,在 Linux 中接下来就会分为中断上半部和下半部机制,上半部在硬中断上下文快速响应然后返回,以更快处理其他中断兼顾实时性。中断下半部为了不同的应用需求设计了 softirq、tasklet、workqueue、thread 等机制来实现大量的中断任务,兼顾高性能。GIC 中断控制器解决了 NVIC 的问题但是却丢了硬实时性。
- 中断延迟比较大:中断处理的 PipeLine 比较长,中断响应延迟一般在 us 级别。
- 中断延迟波动比较大:中断不支持嵌套那么就一定要等上一个中断返回才能得到处理,这个延迟就不可控了。
从中断控制器视角看实时性是快速+确定的 latency。
从内存管理角度看实时性
如果单纯重调度器的角度看,Linux 不仅有 RT 实时调度策略,还有 DeadLine 这种强实时性调度策略,也就是说 Linux 系统在调度算法上是具备实时性(软实时)的,但实时性不仅仅取决于调度器还有其他因素的影响,其中虚拟内存机制就是极为关键的因素,下面我们做下详细说明。
我们知道 Linux 下有一套极为复杂的内存管理系统,物理内存由 Node-Zone-Section-Page 链管理,虚拟内存由 slab-buddySystem-page-pagetable 链管理,当内存不足的时候可以通过相似页合并,页面迁移、页面回收等机制回收内存使用。而 RTOS 一般只实现简单的 memory pool。虚拟内存机制有非常多的好处,但是 RTOS 为什么不实现 Linux 下这套软件机制呢,因为没有 MMU?因为资源受限?其实现在 MCU 频率也都跑到上 Ghz 了,也可以外挂 DDR,那么塞个 MMU 放进去也不是什么难事为什么都不这么做呢?其实这是跟实时性相关的,Cortex-M 相较于 A 核的一个优势在于实时性(硬实时性)。引入 MMU 后硬实时性无法保证,我们看下 Linux 下的内存管理存在的问题就知道了。
加入你在 Linux 下采用 DeadLine 调度器,设计好了调度周期核 dead line,让调度器保证在每个周期的 dead line 时间前分配给 thread 需要的时间片。但是你 thread 中使用了一块 heap 里分配的内存,Linux 下申请一块内存是直接返回成功的,这个时候只得到了虚拟地址空间,并没有实际的物理地址被分配。然后你开始写这块内存,然后系统发现并没有实际的物理内存被映射,这个时候系统通过触发缺页异常进入异常处理,一旦触发缺页异常会走页面分配器这个路径,如果申请到页面还好,如果申请不到要走慢速通道,通过回收内存、页面合并、页面迁移等操作来腾出内存,emm,这个操作的耗时情况就完全不可控了。那么这个操作在 Deadline 调度周期内就很有可能无法完成。
当然也有解决办法就是 Reserved 内存,这就相当于没有使用虚拟内存机制了。
因此何为实时性呢?从内存管理角度看确定性更为接近答案,事实上硬实时性同时需要快速核确定性来保证。
task 调度中存在的问题
优先级反转
使用实时内核,优先级反转问题是实时系统中出现得最多的问题。下图解释优先级反转是如何出现的:
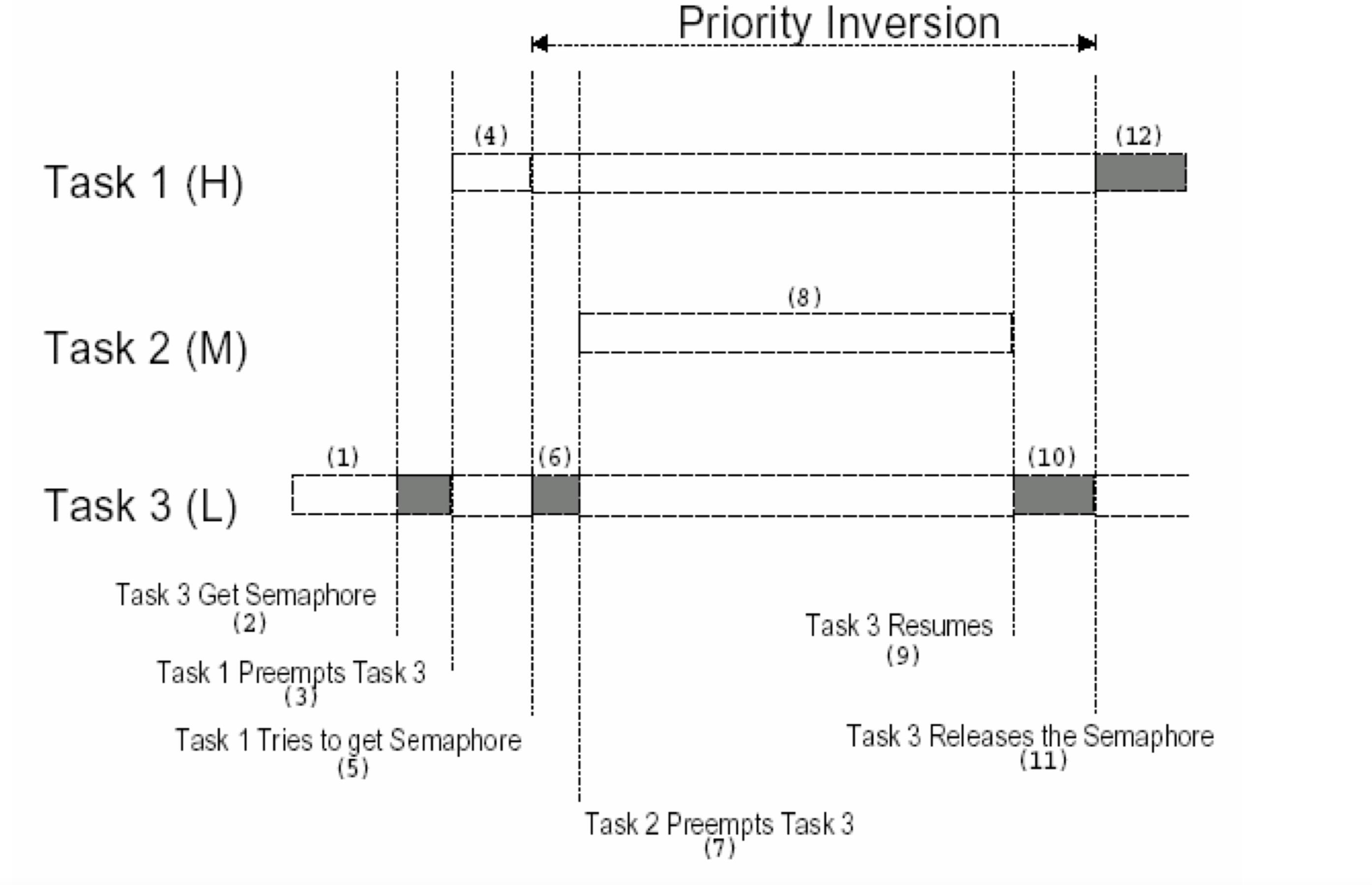
如图,task 的优先级为 task1 > task2 > task3:
- 阶段一:task1 和 task2 处于休眠态,task 申请持有锁。
- 阶段二:task1 切换到运行态,也要申请该锁,因申请不到而休眠。
- 阶段三:task2 切换到运行态,由于优先级高于 task3 而先运行。
- 阶段四:task2 运行结束,task3 运行,释放锁、然后 task1 恢复运行态开始运行。
实际 task 运行的优先级相当于 task2 > task1,发生了优先级反转。
解决措施:在 task3 使用共享资源时,提升 task3 的优先级,task 完成时予以恢复。task3 的优先级必须升至最高,高于允许使用该资源的任何 task 优先级。
然而改变 task 的优先级是很花时间的。如果 task3 并没有先被 task2 剥夺 CPU 使用权,花很多时间在共享资源使用前提升 task3 的优先级,然后又在资源使用后花时间恢复 task3 的优先级,则无形中浪费了很多 CPU 时间。真正需要的是,为防止发生优先级反转,内核能自动变换 task 的优先级,这叫做优先级继承 (Priority inheritance) 但 ucos-Ⅱ不支持优先级继承。
死锁
死锁也称作抱死,指两个 task 无限期地互相等待对方控制着的资源。设 task T1 正独享资源 R1,task T2 在独享资源 R2, 而此时 T1 又要独享 R2,T2 也要独享 R1, 于是哪个 task 都没法继续执行了,发生了死锁。最简单的防止发生死锁的方法是让每个 task 都:
- 先得到全部需要的资源再做下一步的工作。
- 用同样的顺序去申请多个资源,释放资源时使用相反的顺序。
RTOS 延时抖动
概述
对于操作系统来讲时间是颗粒性的不是连续的(物理世界也是这样的),就是操作系统有最小时间颗粒,假如操作系统的时钟滴答是 1ms 那么操作系统是没办法区分小于这个时间的,这就是操作系统延时抖动的一个重要原因。操作系统会把 999us 到 1ms 的这个 1us 当 1ms 处理,当然也会将 1us 到 1999us 这个接近 2ms 的时间当成 1ms 计算,这就造成了一定的延时误差;另一个延时误差来自 task 的运行,task 是轮询运行的也就是延时 1ms 后时间到了,但是高优先级 task 会先运行,之后再将 cpu 控制权转交给该 task,这两个延时共同构成了操作系统的延时抖动。对于精确的延时需要采用硬件定时器实现,但是对于精度要求不是那么高利用操作系统提供的延时是非常方便的,其延时误差在时钟颗粒级别非常小。
task 调度时机
假设时钟节拍是 1ms 发生一次,要求 task A 延时一个时钟节拍,下面三种情况体现了延时抖动的原因。
- 第一种情况下执行延时函数后不到 1ms 就到来时钟节拍而其他高优先级 task 又没有多少 task 可以执行很快轮到 task A 执行因此 task A 实际延时小于 1ms。
- 第二种情况当调用延时函数后高优先级 task 执行时间较长大于上一次时钟节拍到来到调用延时 task 的时间,那么延时将大于 1ms。
- 第三种情况是高优先级 task 执行时间过长超过一个时钟节拍,那么实际延时可能是 2ms。
因此,采用操作系统延时是不准确的,下图是 task 调度时机:
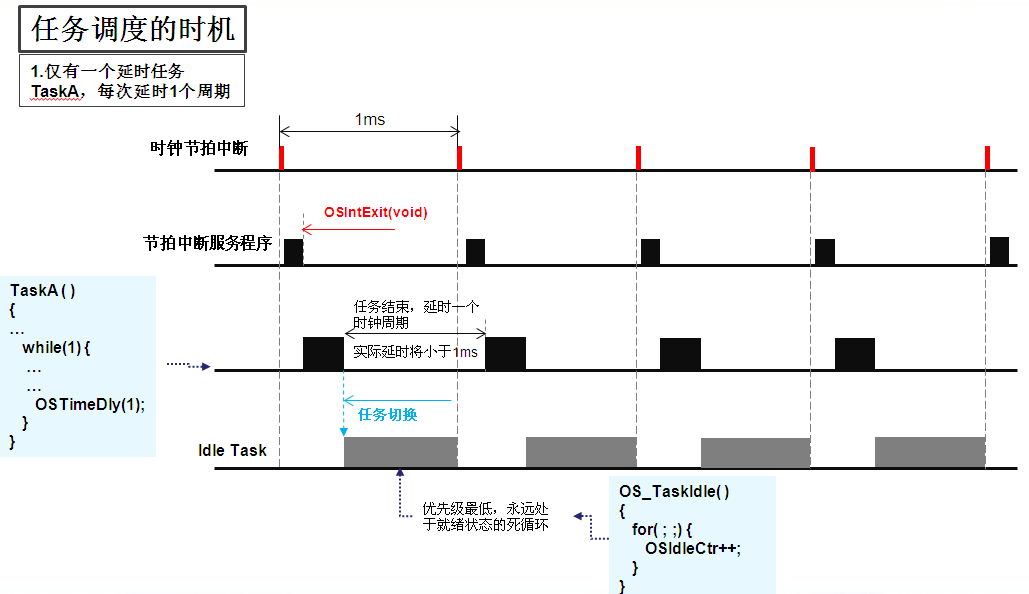
延时的实际执行过程是这样的,在每一次时钟周期到来将发生一次中断,调用节拍服务函数 OSTimeTick(),该函数主要的功能是给每个 task 控制块 OS_TCB 中的时钟延时项 OSTCBDly 减一直到等于 0,在减到 0 之前 task 是挂起的,而当 task 延时减到 0 时 task 不一定是就绪态最高优先级 task,因此 task 不一定立即得到执行,而产生延时误差。如果需要精确的延时可以采用定时器延时,定时器延时产生的中断优先级更高需要立即处理。
同步
用于行为同步的通信手段
- 二值信号量:二值信号量的使用范围是:被控制方总能够及时响应控制方发出的信号,完成相应处理 task, 并在下一次信号来到之前进入等待状态。
- 计数信号量:计数信号量的使用范围是:被控制方不能保证在下一次信号到来之前处理完本次控制方发出的信号,但总体上可以响应所有信号。
- 事件标志组:“事件标志组”可以实现多个 task(包括 ISR) 协同控制一个 task, 当各个相关 task(包括 ISR) 先后发出自己的信号后(使事件标志组的对应标志有效), 预定的逻辑运算结果有效,触发被控制的 task。
- 消息邮箱:由于“消息邮箱”里只能存放一条消息,所以在用“消息邮箱”进行同步控制时,必须满足一个前提:任何时候消息的生产速度都比消息的消费速度慢,即被控制 task 总是在等待消息。这和二值信号量的情况类似。
- 消息队列:“消息队列”可以存放多个消息,能够有效解决消息的“临时堆积”问题。与计数信号量的情况类似,“消息队列”的使用仍然需要满足一个条件:消息的平均生产时间比消息的平均消费时间长;否则,再长的“消息队列”也会“溢出”。
将以上通信手段用于 task 之间的行为同步时需要根据实际情况来选择:
- 当同步过程不需要传输具体内容时,可选择信号量类手段(二值信号量、计数信号量和事件标志组)。
- 当同步过程需要传输具体内容时,可选择消息类手段(消息邮箱和消息队列)。
- 当满足“任何时候同步信息的生产速度都比同步信息的消费速度慢”时,可选择简单的通信手段(二值信号量、事件标志组和消息邮箱)。
- 对于非周期性同步信息,当不能保证“任何时候同步信息的生产速度都比同步信息的消费速度慢”时,可选择有缓冲功能的通信手段(计数信号量和消息队列)。
- 当同步信号为多个信号的逻辑运算结果时,采用事件标志组作为同步手段。
数据通信
- 全局变量与内存数据块:在没有行为同步要求的前提下,当传输的数据量不大时,采用全局变量并配合关中断的资源同步揹施是一种经济、有效的方法。
- 消息邮箱:“消息邮箱”就是具有行为同步功能的通信手段,不具备缓存功能,消费必须及时。
- 消息队列:消息队列”是具有行为同步功能和缓冲功能的数据通信手段。
参考文献
《嵌入式实时操作系统 ucos-ii 教程》
《周慈航-基于嵌入式实时操作系统的程序设计技术》
《嵌入式实时操作系统μCOS-II 原理及应用-任哲》
[[ucosDesign]]
