IMU 误差模型及校准
传感器误差模型
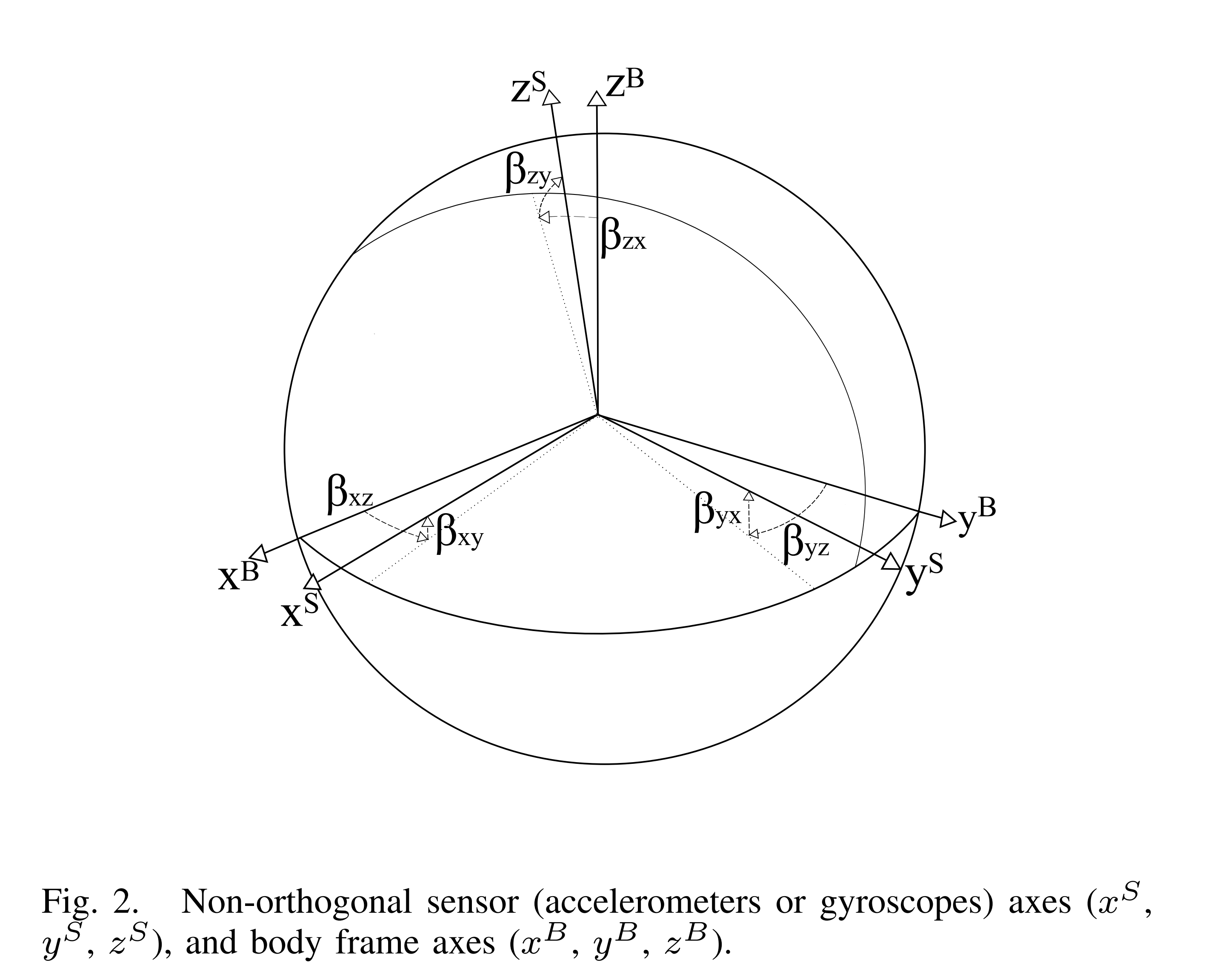
对于理想的 IMU 三轴加速度计两两正交,构成一个正交的三轴直角坐标系,加速度计每一轴单独测量该轴的加速度,而陀螺仪则测量该轴的角速度。在实际的真实 IMU 中由于制造工艺的误差,三个坐标轴不可能完全两两正交,加速度计与陀螺仪的坐标系也不会完全重合,并且单个传感器也不是完全精确的。在实际器件中将数字输出量转化为实际物理量的 scale 参数在不同轴上是不同的,但是设备生产商都会提供一个默认的 scale 参数用于转换所有轴的数据,而且数字量的输出还会受到零偏(传感器在静止情况下也会有微小量的输出)的影响,这些就是造成 IMU 传感器的系统误差。
我们取实际器件的加速度计坐标系为 AF, 陀螺仪坐标系为 GF,根据 AF 和 GF 分别建立对应的正交坐标系 AOF 和 GOF,其建立约束为
- AOF 的 x 轴与 AF 的 x 轴重合。
- AOF 的 y 轴位于 AF 的 x 与 y 轴的平面中。
对于 GOF 的建立约束与 AOF
的约束类比建立。最后再建立一个正交机体坐标系 BF,BF 通常与 AF 和 GF
之间有一个小角度的偏差。在非正交坐标系(AF 或
GF)中测量得到的物理量
另外 BF 与 AOF 以及 BF 与 GOF 坐标系之间只有纯粹的旋转关系,我们假设
BF 的 x 轴恰巧与 AOF 的 x 轴重合在这种情况下
这里
注意到目前为止要重点区分 5 个坐标系,首先是加速度计坐标系 AF 和陀螺仪坐标系 GF 由于制造工艺的原因这两个坐标系都不是正交的,且这两个坐标系也不重合,然后根据 AF 和 GF 分创建了两个正交坐标系 AOF 和 GOF,建立的约束就是上文中提到的,最后又建立了一个机体坐标系。后面我们假设机体坐标系的 x 轴与加速度正交坐标系 AOF 的 x 轴重合于是建立了加速计方程(1)和(2)最后 BF 与 GOF 的 x 轴不重合因此只有第一步公式(3)没有后续的推导。
综上加速度计和陀螺仪的误差都是包含两部分比例误差 scale 和 0 偏误差 bias,比例偏差 scale 用如下表示:
两个 bias 向量用如下表示:
完整的加速度误差模型如下:
完整的角速度误差模型如下:
其中
校准框架
为了校准加速度计我们需要估计如下未知参数:
我们定义如下函数:
实际上是忽略了测量噪声。像传统的多位置方案中,我们移动 IMU 到 M
个不同的临时稳定状态,可以提取加速度向量
为了校准陀螺仪我们可以在 IMU
初始的静止阶段读取陀螺仪数据并取均值,作为陀螺仪 bias。 我们定义
我们需要估计的未知陀螺仪参数如下:
在这种情况下我们定义代价函数:
M 是静态状态读取数据的数量
校准过程
静态检测
如前面校准框架所述,校准 IMU 需要收集加速度计和陀螺仪的原始数据,采集的数据应该包含 IMU 在各个稳定状态及其间隔状态下的数据。为了减小 bias 噪声对上面两个代价函数的影响需要先对 0 偏进行校准,初始阶段需要一段时间的静止用于校准陀螺仪的 bias 以及用于静态检测参考。
校准精度取决于对静止状态判断的准确性,校准加速度计需要在几个静态状态下进行运算,校准陀螺仪需要静态以及各个不同状态的静态之间的运动数据。根据经验对实际的数据集采用基于滤波的算子效果会较差,例如准静态检测器,检测静止状态通常会包含一些小的运动。而且基于滤波器的算法通常依赖滤波参数,需要对滤波参数进行调整。
我们建议采用基于方差的静态检测器运算,他利用上面的静态检测间隔。我们的检测器基于
其中
龙格库塔法积分
在上面的 11 式中,通过 k-1 时刻的加速度计得到的重力向量与 k-1 到 k 时刻的加速度进行运算得到 k 时刻的重力向量,这里 k-1 和 k 是两个稳定状态,因此 k-1 和 k 之间有一段时间的运动,需要对陀螺仪数据进行积分到加速度计的重力向量中去,在我们的实验中采用 4 阶龙格库塔积分法(RK4n)比标准线性积分精度要高,下式 15 用微分方程来描述四元数运动方程:
这里 q 是 t-1 时刻的重力向量的四元数表示,而
RK4n 算法如下:
所有需要的系数
最后对于每一步我们需要归一化四元数 q:
阿伦方差
我们使用艾伦方差来表示陀螺仪的随机漂移误差,这里用
其中
完成校准
为了得到较好的校准结果至少需要 9 种不同姿态的数据,实验表明姿态数越多校准结果越好。
附录
Levenberg-Marquardt 算法
牛顿法
牛顿法(英语:Newton's
method)又称为牛顿-拉弗森方法(英语:Newton-Raphson
method),它是一种在实数域和复数域上近似求解方程的方法。方法使用函数
我们求解 x,过程如下:
我们将新求得的点
对于多维的情况,对
这里
可以写为如下:
这就是牛顿法的多维公式,其中
高斯-牛顿法
给定 m 个方程
从给定初始值
这里
其中符号
这就是一维牛顿法的直接推广。 在数据拟合中,目标是找到最佳参数
高斯-牛顿法可以用函数
这里
高斯-牛顿算法将通过近似从牛顿方法优化函数中推导而来。牛顿方法最小化参数函数
海塞矩阵
高斯-牛顿法忽略二阶小项,海塞矩阵
这里
将这些表达式代入上述递归关系中以获得运算方程式就得到:
注意并非在所有情况下都保证高斯-牛顿法的收敛性,下式要能够得到保证才可以:
二阶导数足够小可以被忽略,在如下两种情况下都会收敛:
1.
Levenberg-Marquardt 算法
莱文贝格-马夸特方法(Levenberg–Marquardt
algorithm)能提供数非线性最小化(局部最小)的数值解。、
和其他最小化算法一样,LM
算法也是采用迭代过程,首先也是要提供一个参数
其中:
是函数
或者用向量符号表示:
这里暂时先不做理论推导了,目前没找到好的推导方法,直接上结论吧,
就是莱文贝格-马夸特方法。如此一来
- 如果发现
- 发现
- 到达了迭代的上限设定就结束。
参考文献
《A Robust and Easy to Implement Method for IMU Calibration without External Equipments》
预览: