/* tell the scheduler that this is a workqueue worker */ set_pf_worker(true); woke_up: raw_spin_lock_irq(&pool->lock);
/* 1. 如果工人太多,想要减少工人的数量,那么当前工人线程退出 */ /* am I supposed to die? */ if (unlikely(worker->flags & WORKER_DIE)) { raw_spin_unlock_irq(&pool->lock); WARN_ON_ONCE(!list_empty(&worker->entry)); set_pf_worker(false);
/* 2. 工人退出空闲状态 */ worker_leave_idle(worker); recheck: /* 3. 如果不需要本工人执行工作,那么本工人进入空闲状态 */ /* no more worker necessary? */ if (!need_more_worker(pool)) goto sleep;
/* 4. 如果工人池中没有空闲的工人,那么创建一些工人使用*/ /* do we need to manage? */ if (unlikely(!may_start_working(pool)) && manage_workers(worker)) goto recheck;
/* * ->scheduled list can only be filled while a worker is * preparing to process a work or actually processing it. * Make sure nobody diddled with it while I was sleeping. */ WARN_ON_ONCE(!list_empty(&worker->scheduled));
worker_set_flags(worker, WORKER_PREP); sleep: //工人进入空闲状态,睡眠 /* * pool->lock is held and there's no work to process and no need to * manage, sleep. Workers are woken up only while holding * pool->lock or from local cpu, so setting the current state * before releasing pool->lock is enough to prevent losing any * event. */ worker_enter_idle(worker); __set_current_state(TASK_IDLE); raw_spin_unlock_irq(&pool->lock); schedule(); goto woke_up; }
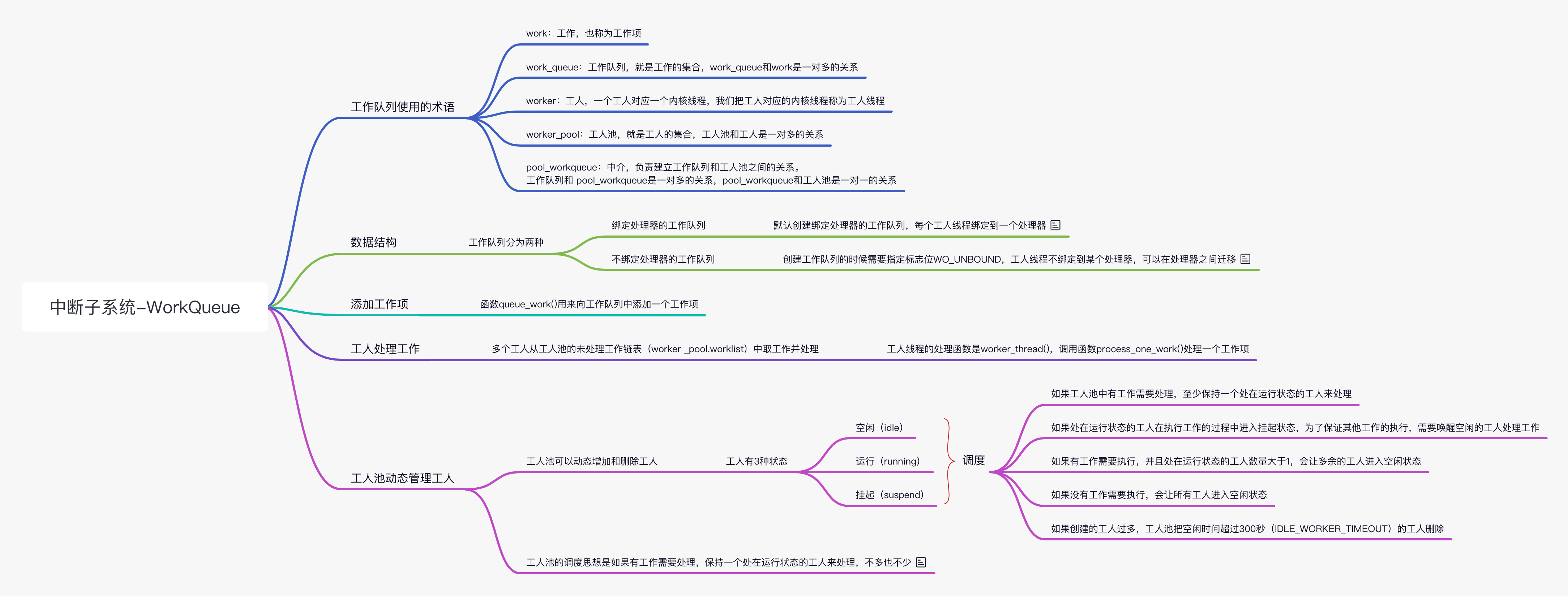
下面解释一下正常工作和特殊工作。
向工作队列中添加正常工作,是直接添加到工人池的链表 worklist 中。
调用函数 flush_work(t) 等待工作 t
执行完,实现方法是添加一个特殊工作:屏障工作,执行这个屏障工作的时候就可以确定工作
t 执行完。如果工作 t 正在被工人 p 执行,那么把屏障工作直接添加到工人 p
的链表 scheduled 中;如果工作 t
没有执行,那么把屏障工作添加到工人池的链表 worklist
中,并且给屏障工作设置标志位 WORK_STRUCT_LINKED。函数 process_one_work()
负责处理一个工作,其代码如下:
/* ensure we're on the correct CPU */ WARN_ON_ONCE(!(pool->flags & POOL_DISASSOCIATED) && raw_smp_processor_id() != pool->cpu);
/* 1. 一个工作不应该被多个工人并发执行。如果一个工作正在被工人的其他工人执行, * 那么把这个工作添加到这个工人的链表 scheduled 中延后执行 */ /* * A single work shouldn't be executed concurrently by * multiple workers on a single cpu. Check whether anyone is * already processing the work. If so, defer the work to the * currently executing one. */ collision = find_worker_executing_work(pool, work); if (unlikely(collision)) { move_linked_works(work, &collision->scheduled, NULL); return; }
/* * Record wq name for cmdline and debug reporting, may get * overridden through set_worker_desc(). */ strscpy(worker->desc, pwq->wq->name, WORKER_DESC_LEN);
list_del_init(&work->entry);
/* 3. 如果工作队列是处理器密集型的,那么给工人设置标志位 WORKER_CPU_INTENSIVE, * 工人不再被工人池动态调度。这使@worker 脱离了并发管理,下一个代码块将链接 * 执行待处理的工作项 */ /* * CPU intensive works don't participate in concurrency management. * They're the scheduler's responsibility. This takes @worker out * of concurrency management and the next code block will chain * execution of the pending work items. */ if (unlikely(cpu_intensive)) worker_set_flags(worker, WORKER_CPU_INTENSIVE);
/* 4. 对于不绑定处理器或处理器密集型的工作队列,唤醒更多空闲的工人处理工作 */ /* * Wake up another worker if necessary. The condition is always * false for normal per-cpu workers since nr_running would always * be >= 1 at this point. This is used to chain execution of the * pending work items for WORKER_NOT_RUNNING workers such as the * UNBOUND and CPU_INTENSIVE ones. */ if (need_more_worker(pool)) wake_up_worker(pool);
/* 5. 记录最后一个池并清除 PENDING,这应该是对@work 的最后一次更新。 此外, * 在@pool->lock 中执行此操作,以便在禁用 IRQ 时同时发生 PENDING 和排队状态更改 */ /* * Record the last pool and clear PENDING which should be the last * update to @work. Also, do this inside @pool->lock so that * PENDING and queued state changes happen together while IRQ is * disabled. */ set_work_pool_and_clear_pending(work, pool->id);
lockdep_invariant_state(true); trace_workqueue_execute_start(work); /* 6. 执行工作的处理函数 */ worker->current_func(work); /* * While we must be careful to not use "work" after this, the trace * point will only record its address. */ trace_workqueue_execute_end(work, worker->current_func); lock_map_release(&lockdep_map); lock_map_release(&pwq->wq->lockdep_map);
if (unlikely(in_atomic() || lockdep_depth(current) > 0)) { pr_err("BUG: workqueue leaked lock or atomic: %s/0x%08x/%d\n" " last function: %ps\n", current->comm, preempt_count(), task_pid_nr(current), worker->current_func); debug_show_held_locks(current); dump_stack(); }
/* * The following prevents a kworker from hogging CPU on !PREEMPTION * kernels, where a requeueing work item waiting for something to * happen could deadlock with stop_machine as such work item could * indefinitely requeue itself while all other CPUs are trapped in * stop_machine. At the same time, report a quiescent RCU state so * the same condition doesn't freeze RCU. */ cond_resched();
raw_spin_lock_irq(&pool->lock);
/* clear cpu intensive status */ if (unlikely(cpu_intensive)) worker_clr_flags(worker, WORKER_CPU_INTENSIVE);
/* tag the worker for identification in schedule() */ worker->last_func = worker->current_func;
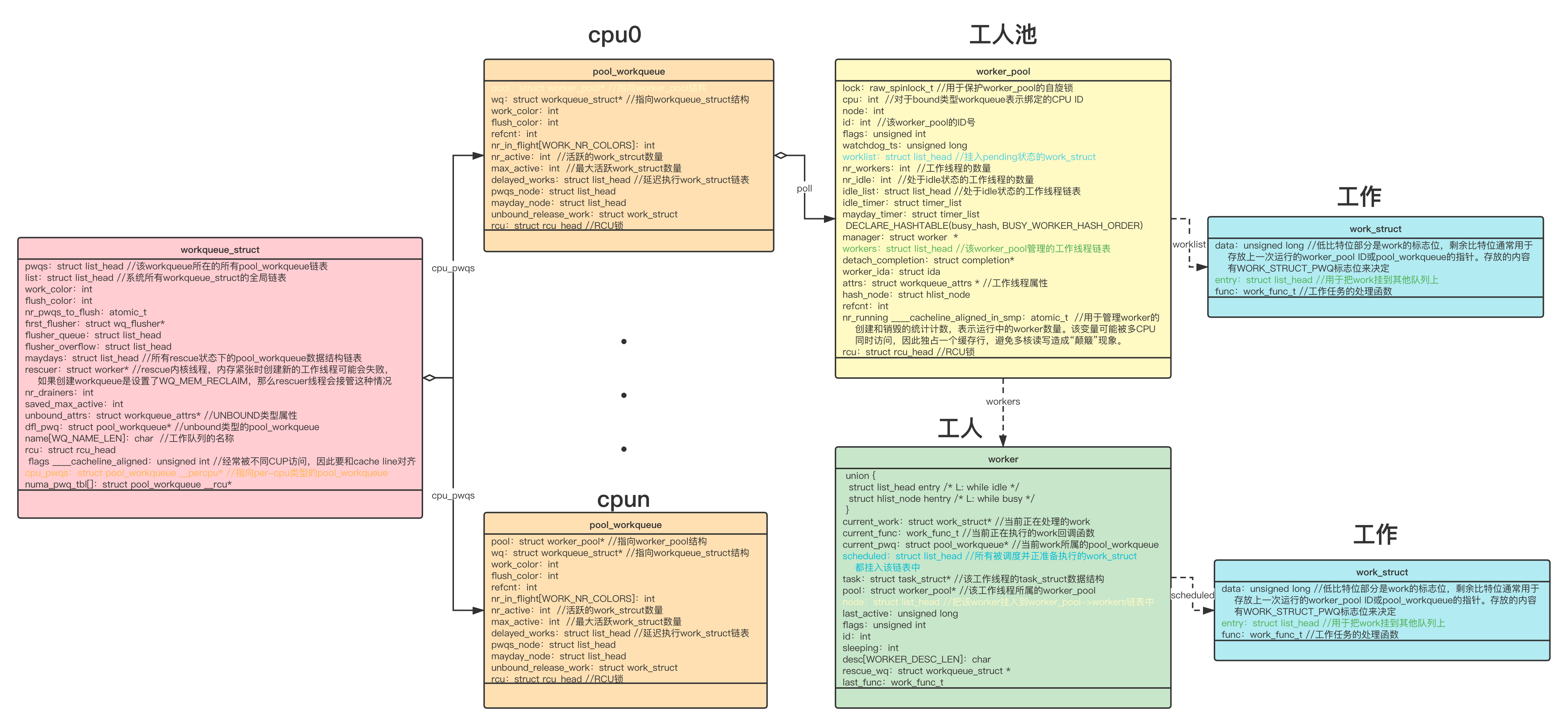 原图
原图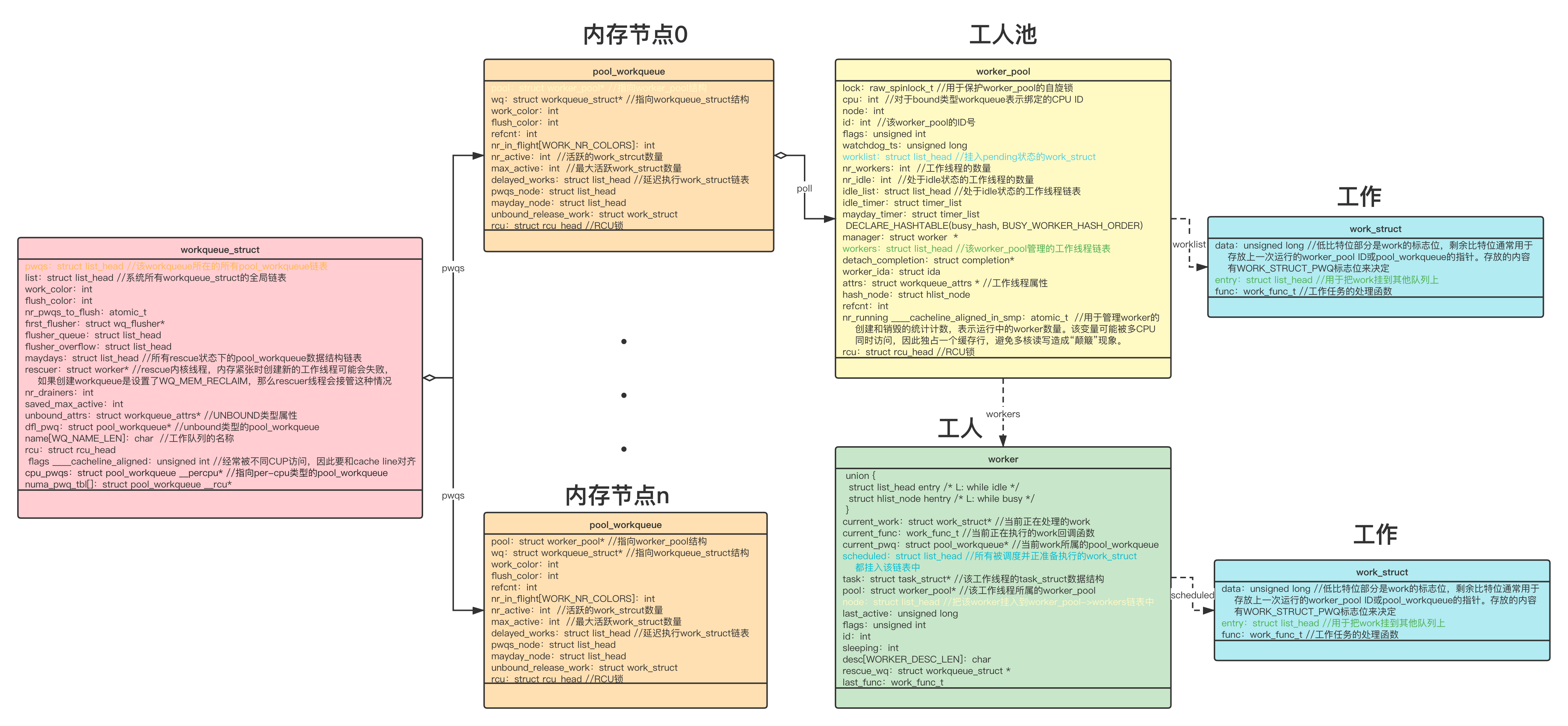 原图
原图
预览: