Linux 内存管理(六)伙伴系统和 slab 分配器
 原图
原图
声明本文转载自知乎 兰新宇 内存相关文章
内存池
空闲链表(free list)
将内存中所有的空闲内存块通过链表的形式组织起来,就形成了最基础的 free list。内存分配时,扫描 free list 的各个空闲内存块,从中找到一个大小满足要求的内存块,并将该内存块从 free list 中移除。内存释放时,释放的内存块被重新插入到 free list 中。
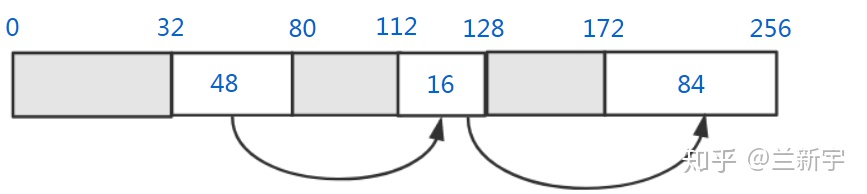
假设现在内存的使用情况是这样的: 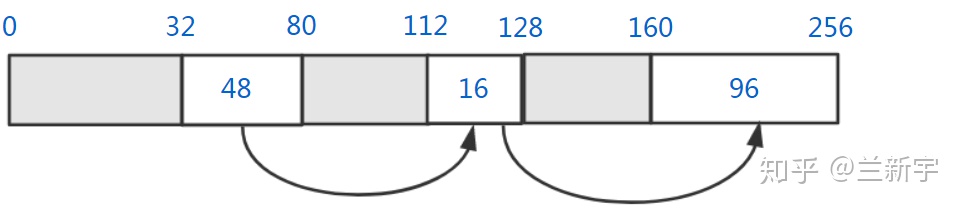
灰色部分代表已经被分配的内存块,白色部分代表空闲的内存块,大小分别是 48 字节,16 字节和 96 字节。如果此时内存分配的申请是 12 个字节,那么将有以下三种策略可以选择:
First fit(最先适配),就是从 free list 头部开始扫描,直到遇到第一个满足大小的空闲内存块,这里第一个 48 字节的内存块就可以满足要求。这种方法的优点是相对快一些,尤其是满足要求的空闲内存块位于链表前部的时候,但是在控制碎片数量上不是最优的。
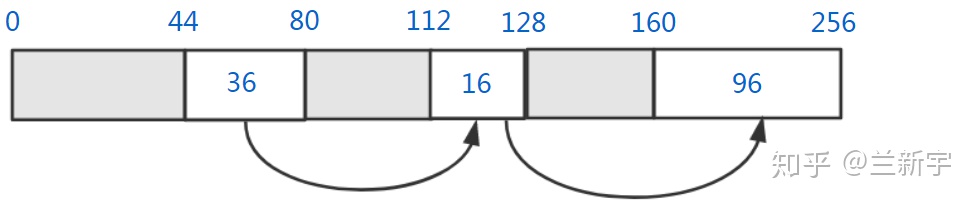
Best fit(最佳适配),就是遍历 free list 的所有空闲内存块,从中找到和所申请的内存大小最接近的空闲内存块,这里第二个 16 字节的内存块是最接近 12 字节的。
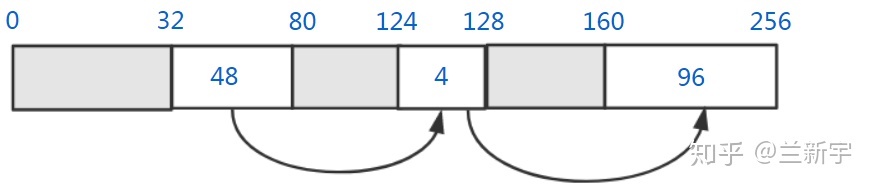
Worst fit(最差适配),也是遍历 free list 的所有空闲内存块,如果找不到大小刚好匹配的,就从最大的空闲内存块中分配。初看起来很反直觉是不是?但假设接下来的内存申请是 64 个字节,那只有 worst fit 的这种方法才能满足需求,所以其价值体现在:分配之后剩下的空闲内存块很可能仍然足够大。
以上讨论的是内存分配的情况,接下来看看内存释放的操作是怎样的。假设从第
80 字节到第 100 字节中间的 20
字节内存被释放了,那么它将和前面相邻的空闲内存块合并: 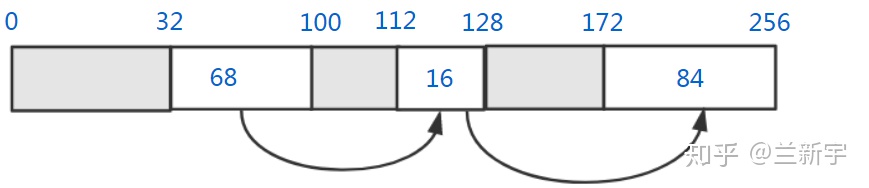
接下来从第 100 字节到第 112 字节中间的 12
字节内存也被释放了,那么它将同时和前后相邻的空闲内存块合并: 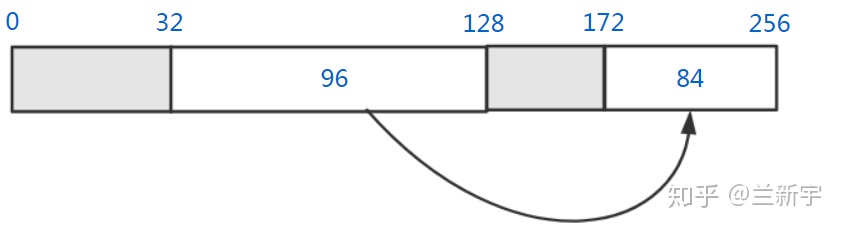
不过,既然用到了链表,那就需要指针,而指针本身也是要占用内存空间的。而且在内存释放时,要判断被释放的内存块前后的内存块是不是也是空闲的,这就需要每个内存块有一个空闲状态的标志位。可以采用的一种方式是
bitmap,假设以 4 个字节为最小分配单位,那么每 4 字节需要一个
bit,因此额外消耗的内存为 1/32。 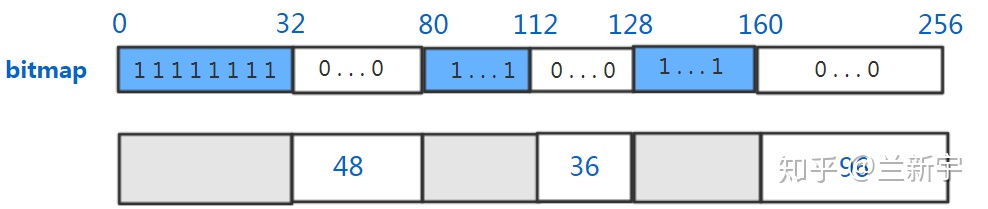
内存池(memory pool)
空闲链表的分配方式简单,但分配效率不高,运行一段时间后容易产生大量的内存碎片,从而恶化了内存利用率。
如果能将一大块内存分成多个小内存(称为内存池),不同的内存池又按照不同的「尺寸」分成大小相同的内存块(比如分别按照 32, 64, 128……字节),同一内存池中的空闲内存块按照 free list 的方式连接。
每次分配的时候,选择和申请的的内存在「尺寸」上最接近的内存池,比如申请
60 字节的内存,就直接从单个内存块大小为 64 字节的内存池的 free list
上分配。 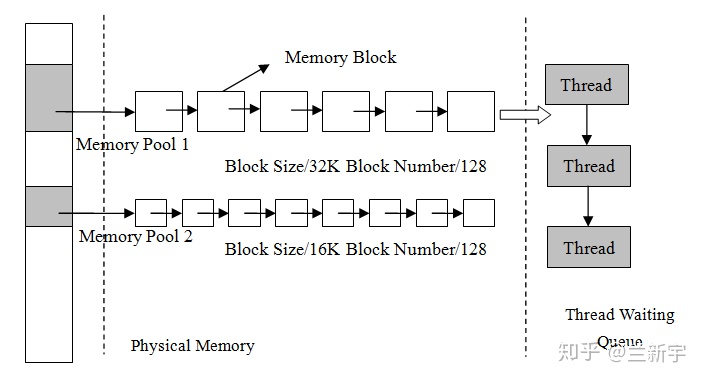
这样减少了 free list 链表的长度,能够缩短每次内存分配所需的线性搜索的时间,特别适合对实时性要求比较高的系统(比如 RTOS)。但要想取得好的效果,需要结合系统实际的内存分配需求,对内存池的大小进行合理的划分。比如一个系统常用的是 256 字节以下的内存申请,那设置过多的 256 字节以上的内存池,就会造成内存资源的闲置和浪费。
似乎不是很好把控到底怎样划分内存池最为合适?下文将要介绍的 Linux 中的 buddy 分配系统,将基于普通的内存池进行优化,以更贴合大型操作系统对内存管理的需求。
Buddy 分配算法
上文介绍了内存池,它的分配快速,但这种“事先就划分好”的方法对系统的适应性较差,不同「尺寸」的内存池之间不能“互通有无”。而 buddy 分配系统在普通内存池的基础上,允许两个大小相同且相邻的内存块合并,合并之后的内存块的「尺寸」增大,因而将被移动到另一个内存池的 free list 上。
来看下面这个例子,内存共有 1024 字节,由 32, 64, 128, 256, 512
字节为「尺寸」的 5 个 free list 组织起来,最小分配单位为 32
字节(对应位图中的 1 个 bit)。假设现在 0 到 448 字节的内存已使用,448
到 1024 字节的内存为空闲(字母编号从 A 开始,表示分配顺序)。 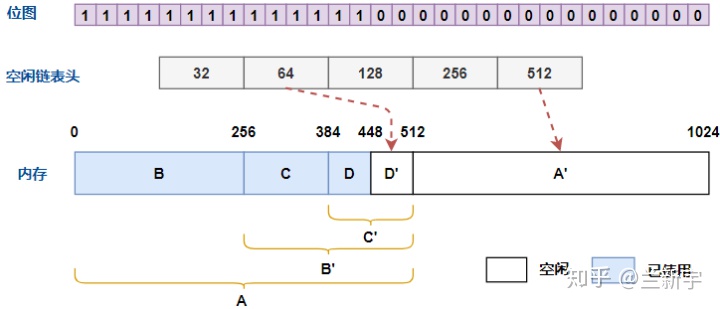
现在我们要申请 128 字节的内存,那么首先应该查看「尺寸」为 128 字节的 free list,但很可惜没有,那再看看 256 字节的 free list,还是没有,只能再往上找,到 512 字节的 free list 这儿,终于有了一个空闲的内存块 A'。
那么将 A'划分为 256 字节的 E 和 E',再将内存块 E 划分成 128 字节的 F
和 F',内存块 F 即是我们需要的内存。之后,在此过程中产生的 E'和
F'将分别被挂接到「尺寸」为 256 字节和 128 字节的 free list 上,位图中
bits 的值也会相应变化。 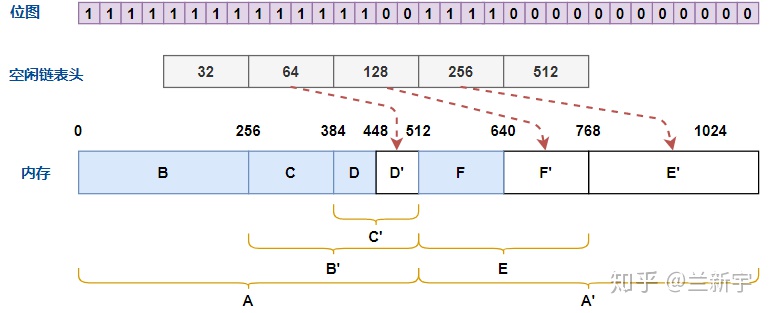
接下来释放 128 字节的内存块 C,由于 C
相邻的两个内存块都不是空闲状态,因此不能合并,之后 C
也将被挂接到「尺寸」为 128 字节的 free list 上。 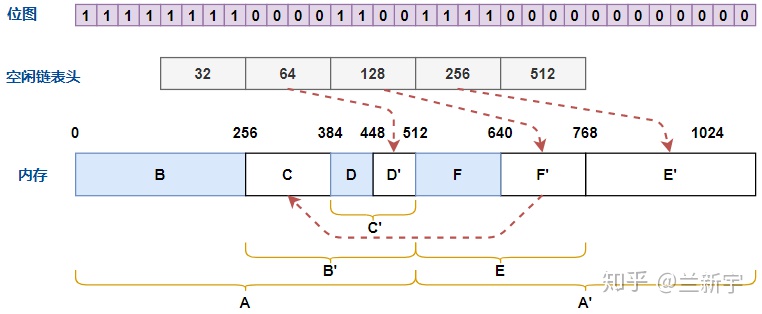
然后释放 64 字节的内存块 D,分配器根据位图可知,右侧的
D'也是空闲的,且 D 和 D'的大小相同,因此 D 和
D'将合并。按理合并后的空闲内存块 C'为 128 字节,应该被添加到「尺寸」为
128 字节的 free list 上,但因为左侧的 C 也是空闲的,且 C 和
C'的大小相同,因此 C 和 C'还将合并形成
B',合并后的空闲内存块将被挂接到「尺寸」为 256 字节的 free list 上。
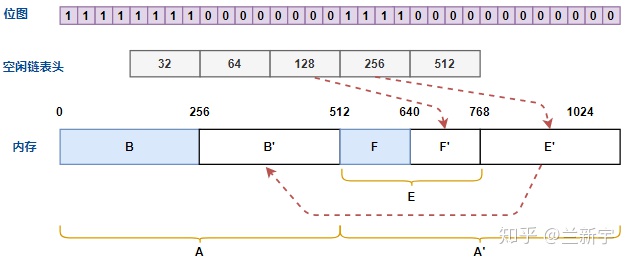
在 buddy 分配系统中,从物理上,内存块按地址从小到大排列;从逻辑上,内存块通过 free list 组织。通过对相邻内存块的合并,增加了内存使用的灵活性,减少了内存碎片。
但是实现合并有一个前提,就是内存块的尺寸必须是 2 的幂次方(称为"order"),这也是 buddy 系统划分内存块的依据。此外,每次内存释放都要查找左右的 buddy 是否可以合并,还可能需要在 free list 之间移动,也是一笔不小的开销。
Slab
Linux 中的 buddy 分配器是以 page frame 为最小粒度的,而现实的应用多是以内核 objects(比如描述文件的"struct inode")的大小来申请和释放内存的,这些内核 objects 的大小通常从几十字节到几百字节不等,远远小于一个 page 的大小。
那可不可以把一个 page frame 再按照 buddy 的原理,以更小的尺寸(比如 128 字节,256 字节)组织起来,形成一个二级分配系统呢?这就是 slab 分配器。
cache 和 slab
在 slab 分配器中,每一类 objects 拥有一个"cache"(比如 inode_cache,
dentry_cache)。之所以叫做"cache",是因为每分配一个
object,都从包含若干空闲的同类 objects
的区域获取,释放时也直接回到这个区域,这样可以缓存和复用相同的
objects,加快分配和释放的速度。 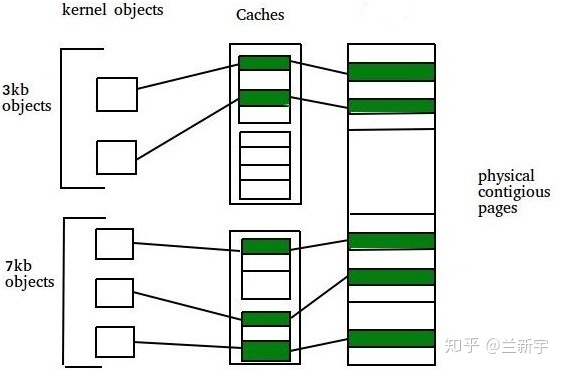
object 从"cache"获取内存,那"cache"的内存又是从哪里来的呢?还是得从
buddy 分配器来。slab 层直接面向程序的分配需求,相当于是前端,而 buddy
系统则成为 slab 分配器的后端。 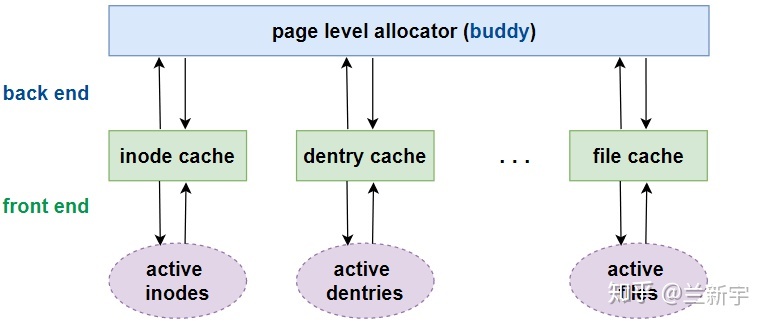
由于"cache"的内存是从 buddy
系统获得的,因此在物理上是连续的。如果一个"cache"中 objects
的数目较多,那么"cache"的体积较大,需要占用的连续物理内存较多。当 object
的数量增加或减少时,也不利于动态调整。因此,一个"cache"分成了若干个
slabs。 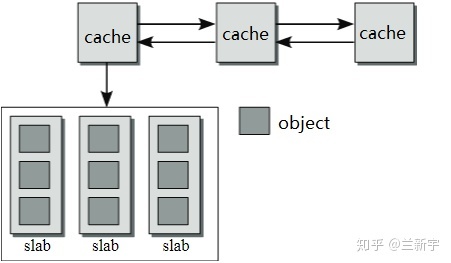
数据结构
一个"cache"在 Linux 中由"struct kmem_cache"结构体描述:
1 | struct kmem_cache { |
一个 slab 由一个或多个 page frame 组成(通常为一个),根据 buddy 系统的限制,在数量上必须是 2 的幂次方,"gfporder"实际就定义了一个"cache"中每个 slab 的大小。
既然涉及到 page frame 的分配,那自然离不开 GFP flags,比如要求从 DMA 中分配,就需要指定"GFP_DMA"。
s,数量由"num"表示,每个 object 的大小由"object_size"给出。一个 object 可能跨越 2 个 page frames。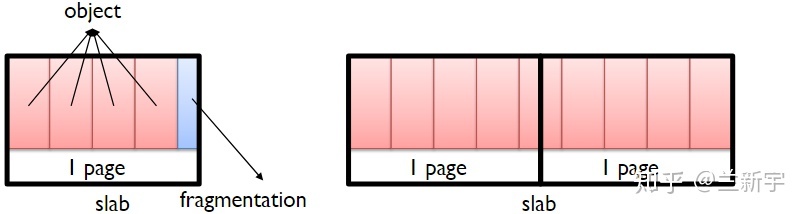
如果 object 的内存地址能按一定字节数(比如总线宽度)或者按硬件 cache
line 的大小对齐,将可以提高读写性能。此外,不同 slabs 中具有相同偏移的
objects,大概率会落在同一 cache line 上,造成 cache line
的争用,所以最好加上不同的填充,以错开对 cache line
的使用。这些偏移和填充,共同构成了 slab 的 coloring 机制。 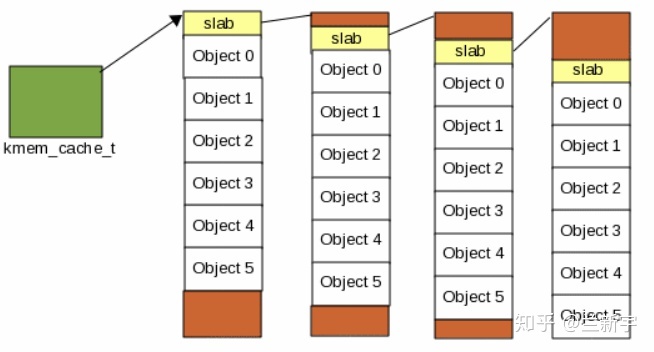
可见啊,slab cache 除了和硬件 cache 一样都使用了“缓存”的思想,它还在实现中充分利用了硬件 cache 提供的特性,以进一步提高运行效率。但付出的代价就是,不管对齐还是填充,都需要额外的字节,这对内存资源也会造成一定的消耗。
统计信息
可通过"slabtop"命令查看当前系统的 slab 分配情况: 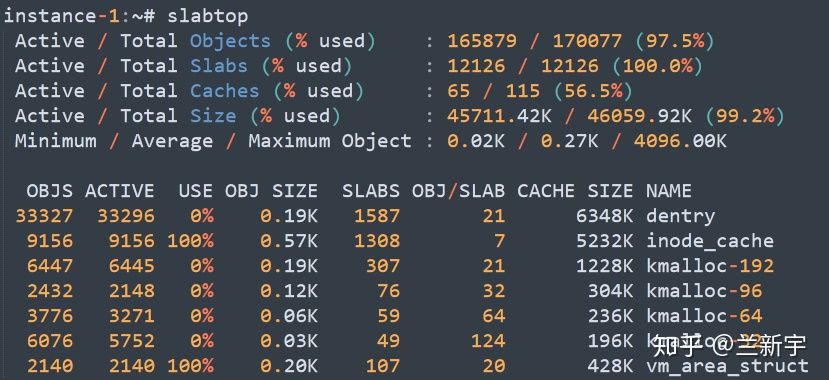
如上图所示,系统中 slab 分配器一共占据了 46059.92KB 内存,包括 115 个"caches",12126 个"slabs"(平均每个 cache 拥有 105 个 slabs),170077 个"objects"(平均每个 slabs 拥有 14 个 objects)。在所有的 objects 中,最小的为 0.02KB,最大的为 4096KB,平均值是 0.27KB。
此外,还有细分的每类 objects 的信息,比如从"inode cache"可以得知打开了 9150 个文件,从"vm_area_struct"可以得知所有进程一共使用了 2140 个 VMA。并且,还能大致知道每类 object 的控制结构的大小,比如一个"struct dentry"大约占据 0.19KB 的内存空间。
虽然没有 per-slab 包含的 pages 数目信息,不过完全可以通过"OBJ/SLAB"乘以"SIZE"计算出来。比如通过这种方法算出来"dentry"的就是大约 4KB,说明每个"dentry"的 slab 包含一个 page frame。
其更重要的意义是体现在调试的时候:当你发现当前内存资源比较紧张,通过"/proc/meminfo"查到是"Slab"占据了较大内存,根据"slabtop"就可以快速知道是哪一类 object 消耗的最多(比如建立了过多的 socket)。
"slabtop"其实和可以显示 CPU 和内存占用率的"top"命令是类似的,都是动态地显示目前资源占用率最高的,只不过"top"针对的是进程,而"slabtop"针对的是"caches"。如果要获取全部"caches"的信息,应查看"/proc/slabinfo"文件。
创建和初始化
创建一个新的"cache"的函数接口是 kmem_cache_create(),主要就是为"kmem_cache"的控制结构分配内存空间并初始化。而这个控制结构本身也是一个内核 object,按理也应该从 slab cache 中获取,那第一个"kmem_cache"从哪里来?这就形成了一个“先有鸡还是先有蛋”的问题,解决的办法是在 slab 子系统生效之前的启动阶段,用一段特殊的 boot cache 来分配。
"cache"创建后,一开始不含有任何的 slab,也就没有任何空闲的
objects,只有当产生分配一个新的 object 的需求时,才开始创建
slab。创建一个 slab 除了需要分配容纳 objects 的内存(相当于 user
data),还需要生成管理这个 slab 的控制信息(相当于 meta data,这里称为
slab descriptor)。 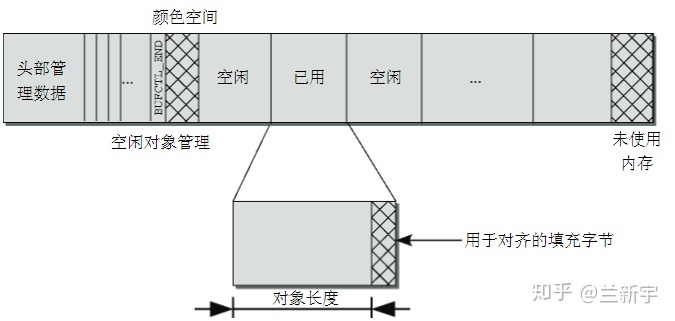
一个 slab 区域包括若干个大小相同的 objects,以及它们的 coloring 消耗的字节。一个"cache"的多个 slabs 通过双向链表连接,因而需要存储链表指针的空间。
根据 object 的大小不同,slab descriptor 本身占据的内存可以位于其管理的 slab 内存区域内部,也可以位于外部(off-slab) 。当位于内部时,链表指针存储在一个 slab 区域的末尾。
1 | if (OFF_SLAB(cachep)) { |
分配 object
内核编程中如果需要申请在物理上连续的内存,最常用的函数就是 kmalloc() 了,而它的底层实现依靠的正是 slab cache。
1 | static __always_inline void *__do_kmalloc(size_t size, gfp_t flags, ...) |
如果传入的参数是"sizeof(struct inode)"这样的,可能刚好有 object 大小完全匹配的 cache。如果参数是一个普通的整数(比如 100),那就需要遍历 cache,并进行一定的计算,以寻找最合适的。
第一级分配(fast path)
每个"kmem_cache"除了包含多个 slabs 外,还包含一组"cpu_cache",这是一种 per-CPU 的 cache,是 slab 的 cache。这么说可能有点绕口,其实就是一个软件层面的二级 cache。拿硬件 cache 来类比,"cpu_cache"就是 L1 cache,slab 就是 L2 cache。
1 | struct array_cache __percpu *cpu_cache; |
"entry[]"表示了一个遵循 LIFO 顺序的数组(Last In, First
Out),"avail"和"limit"分别指定了当前可用 objects
的数目和允许容纳的最大数目。 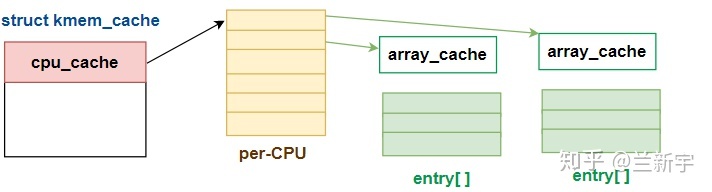
每当 object 试图从 slab 中分配内存时,都先从所在 CPU 对应的"entry[]"数组中获取。per-CPU 的设计可以减少 SMP 系统对全局 slab 的锁的竞争,一些 CPU bound 的线程尤其适合使用 CPU bound 的内存分配。
1 | void *____cache_alloc(struct kmem_cache *cachep, gfp_t flags) |
第二级分配(slow path)
如果在申请时数组为空,那么就需要从全局的 slab 中 refill,那选择哪个 slab 呢?为了减少内存碎片,一个 cache 的 slabs 在每个内存 node 中(per-node),根据使用状态被分成了三类:
- 全部分配完,没有空闲 objects 的 full slabs。
- 分配了一部分,尚有部分空闲的 partial slabs。
- 完全空闲可用的 free slabs。
1 | struct kmem_cache_node *node[MAX_NUMNODES]; |
应首先从 partial slabs 中选择,等 partial slabs 都满了,成为了 full
slab,这时再从 free slabs 中选择。 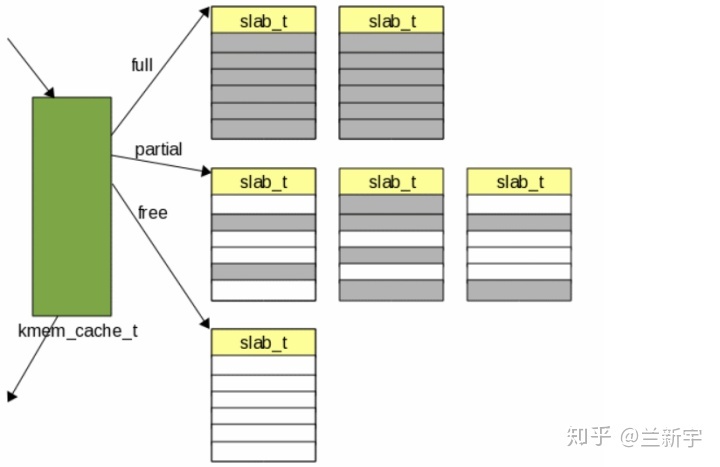
又是 per CPU,又是 per node,在大型系统中,这是一笔不小的开销。
第三级分配(very slow path)
如果一个 cache 连 free slab 都没有了,那就需要新增一个 slab
来“扩容”了。新增 slab 的方法在上文已经介绍过了,最终是向 buddy
系统申请,回到这篇文章描述的 page level 分配器的代码路径。 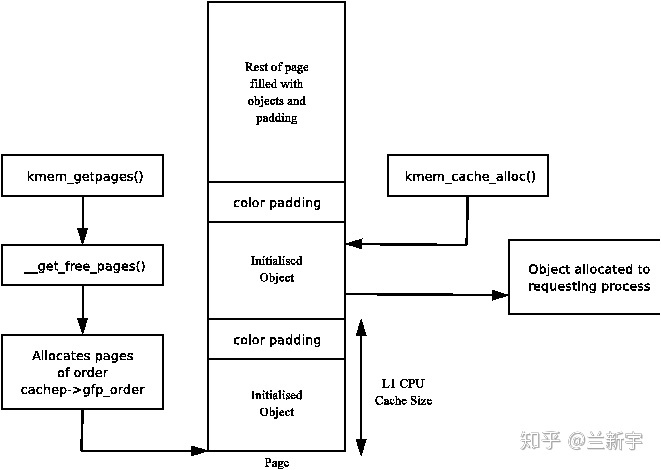
释放 object
释放时也归还到所在 CPU 的"cpu_cache"数组,如果释放导致数组溢出,则数组中的一部分 entries 将被返还到全局的 slab 中。
1 | void ___cache_free(struct kmem_cache *cachep, void *objp, ..) |
我们平时常调用的接口是 kfree(),只有一个表示地址的参数,那如何知道应该归还到哪个 slab 中?寻找的方法是首先根据 object 的虚拟地址找到 object 所在的 page frame,进而找到这个 page frame 所在 compound page 的中的 head page,而 head page 中的"slab_cache"指针就指向了这个 object 所属的 slab。
1 | void kfree(const void *objp) |
借助这条路径,进而还可以知道一个 object 的大小。
1 | size_t __ksize(const void *objp) |
小结
至此,slab 分配器的原理和在 Linux
中的实现就粗略的介绍完了,可以借助下面这张图来一览它的构成,包括 kernel
object, page frame 和 slab cache 的关系,物理内存的组织和分配等。 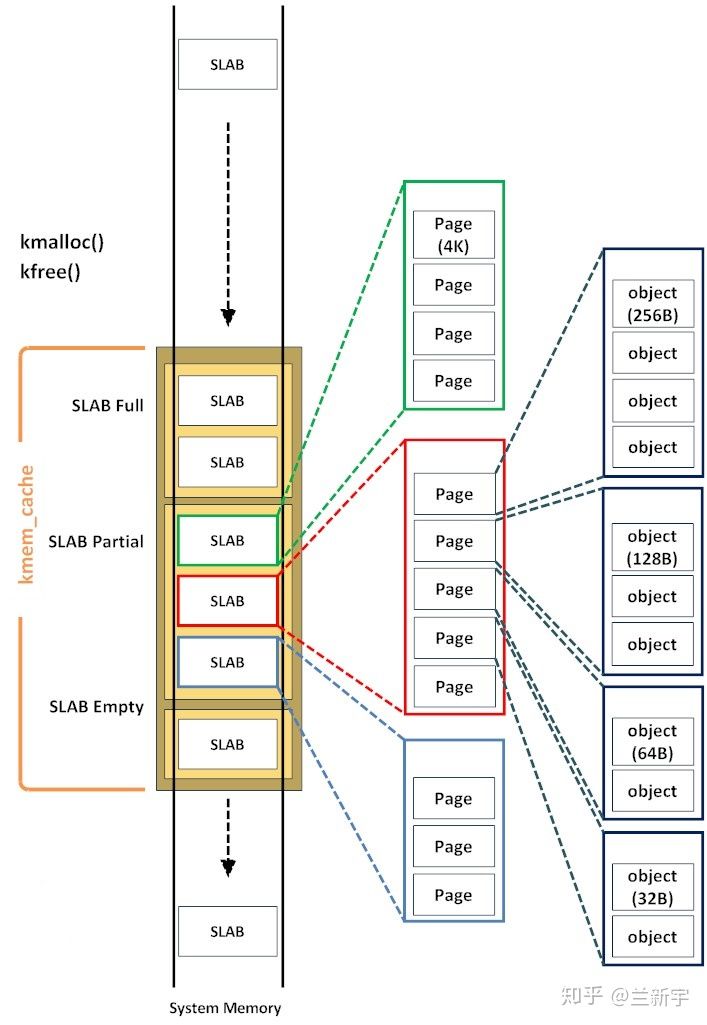
slab 分配器对内存的利用率是比较高的,因为充分借助了各种缓存机制,分配和释放的速度也比较理想。存在的缺点就是要为内核中众多的 objects 维护独立的 cache,这会带来相当的管理上的开销。
kmalloc
内核中常用的 kmalloc() 函数的核心实现是 slab 机制。类似于伙伴系统机制,在内存块中按照$ 2^{order} $字节来创建多个 slab 描述符,如 16 字节、32 字节、64 字节、128 字节等大小,系统会分别创建 kmalloc-16、kmalloc-32、kmalloc-64 等 slab 描述符,在系统启动时这在 create_kmalloc_caches() 函数中完成。例如,要分配 30 字节的一个小内存块,可以用“kmalloc(30,GFP_KERNEL) 实现,之后系统会从 kmalloc-32 slab 描述符中分配一个对象。
1 | static __always_inline void *kmalloc(size_t size, gfp_t flags) |
kmalloc_index 可以用于查找使用的是哪个 slab 缓冲区,这很形象的展示了 kmalloc 的设计思想。
1 |
1 | static __always_inline unsigned int __kmalloc_index(size_t size, |
与 vmalloc 区别(都是分配内核空间内存):
- kmalloc 分配物理连续的地址,而 vmalloc 分配虚拟地址连续的空间。
- kmalloc 可以通过 gfp_mask 标志控制分配内存时不能休眠,因此可以用于中断上下文(softirq 和 tasklet 也处于中断上下文),而 vmalloc 的调用可能引起睡眠不能用于中断上下文。
- kmalloc 性能更好(内核空间更多实用这个函数),而 vmalloc 为了把物理上不连续的页转换为虚拟地址空间上连续的页,需要建立专门的页表项,会导致 TLB 抖动等问题,性能不佳(主要用于用户空间分配内存)。
参考文献
https://zhuanlan.zhihu.com/p/106106008