Linux 并发与同步(三)互斥锁
 原图
原图
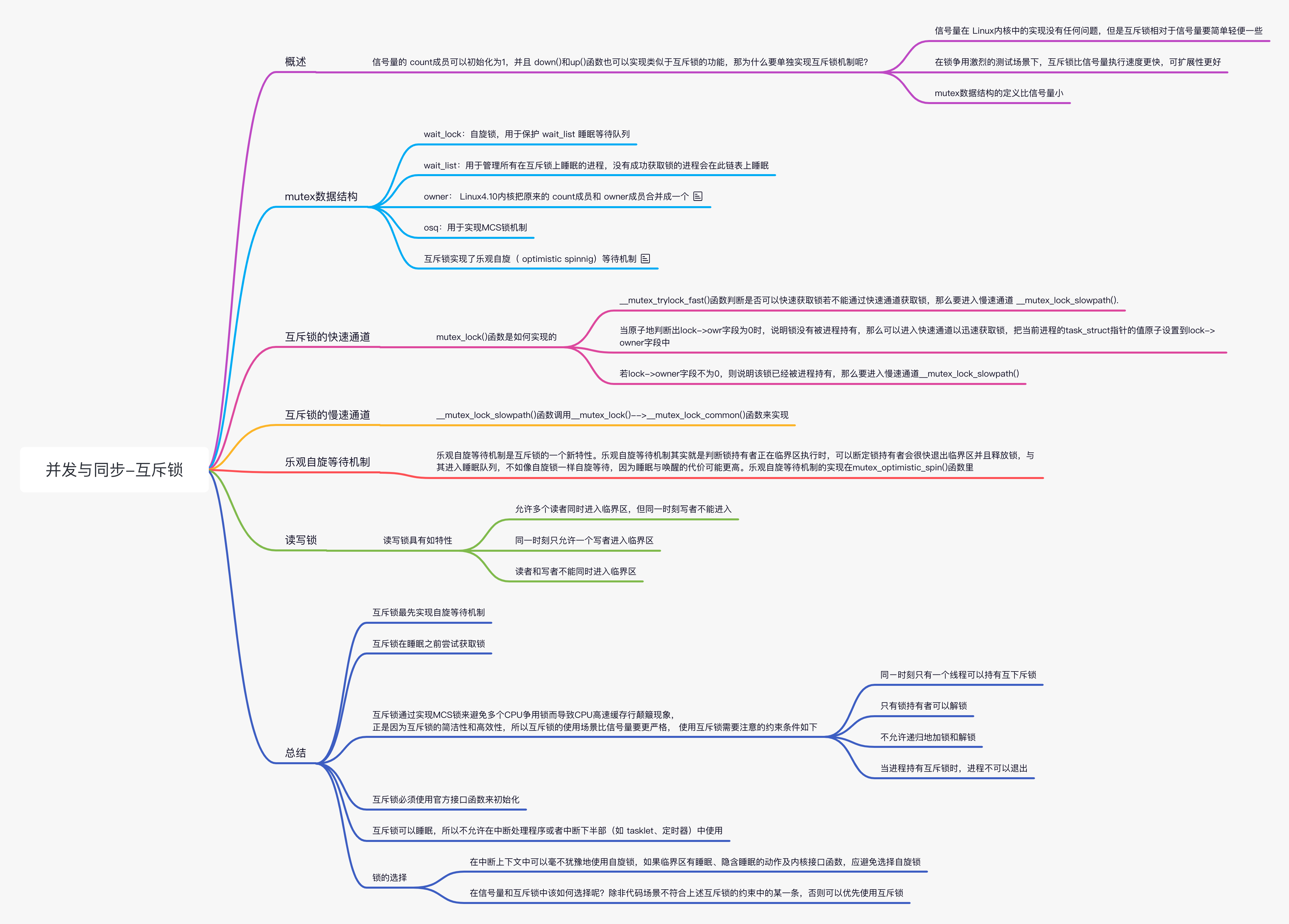
概述
互斥锁类似于 count 值等于 1 的信号量,为什么内核社区要重新开发互斥锁,mutex 有如下优点:
- mutex 数据结构的定义比信号量小
- 互斥锁相对于信号量要简单轻便一些,在锁争用激烈的测试场景下,互斥锁比信号量执行速度更快
- 可扩展性更好
mutex 数据结构
下面来看 mutex 数据结构的定义。
1 | <include/linux/mutex.h> |
- wait_lock:自旋锁,用于保护 wait_list 睡眠等待队列
- wait_list:用于管理所有在互斥锁上睡眠的进程,没有成功获取锁的进程会在此链表上睡眠
- owner: Linux4.10 内核把原来的 count 成员和 owner 成员合并成一个。原来的 count 是一个原子值,1 表示锁没有被持有,0 表示锁被持有,负数表示锁被持有且有等待者在排队。现在新版本的 owner 中,0 表示锁没有未被持有,非零值则表示锁持有者的 task_struct 指针的值。另外,最低 3 位有特殊的含义
1 |
- osq:用于实现 MCS 锁机制 MUTEX_FLAG_WAITERS:表示互斥锁的等待队列里有等待者,解锁的时候必须唤醒这些等候的进程。 MUTEX_FLAG_HANDOFF:对互斥锁的等待队列中的第一个等待者会设置这个标志位,锁持有者在解锁的时候把锁直接传递给第一个等待者。 MUTEX_FLAG_PICKUP:表示锁的传递已经完成。
互斥锁实现了乐观自旋( optimistic spinnig)等待机制。准确地说,互斥锁比读写信号量更早地实现了自旋等待机制。自旋等待机制的核心原理是当发现锁持有者正在临界区执行并且没有其它优先级高的进程要调度时,当前进程坚信锁持有者会很快离开临界区并释放锁,因此与其睡眠等待不如乐观地自旋等待,以减少陲眠唤醒的开销。在实现自旋等待机制时,内核实现了一套 MCS 锁机制来保证只有一个等待者自旋等待锁持有者释放锁。
互斥锁的快速通道
互斥锁的初化有两种方式,一种是静态使用 DEFINE_MUTE 宏,另一种是在内核代码中动态使用 mutex_init() 函数。
1 |
下面来看 mutex_lock() 函数是如何实现的。
1 | void __sched mutex_lock(struct mutex *lock) |
__mutex_trylock_fast() 函数判断是否可以快速获取锁若不能通过快速通道获取锁,那么要进入慢速通道 __mutex_lock_slowpath().
1 | static __always_inline bool __mutex_trylock_fast(struct mutex *lock) |
__mutex_trylock_fast() 函数实现的重点是 atomic_long_try_cmpxchg_acquire() 函数,如果以 cmpxchg() 函数的语义来理解,会得出错误的结论。比如,当 lock->owner 和 zero 相等时,说明 lock 这个锁没有被持有,那么可以成功获取锁,把当前进程的 task_struct->curr 的值赋给 lock->owner,然后函数返回 lock->owner 的旧值,也就是 0。这时 if 判断语句应该判断 atomic_long_try_cmpxchg_acquire() 函数是否返回 0 オ对。但是在 Linux5.0 内核的代码里和我们想的完全相反,那是怎么回事呢? 细心的读者可以通过翻阅 Linux 内核的 git 日志信息找到答案。在 Linux4.18 内核中有个优化的补丁。锁的子系统维护者 Peter Zijlstra 通过比较反汇编代码发现在 x86_64 架构下使用 try_cmpxchg() 代替 cmpxchg() 数可以少执行ー次 test 指令。try_cmpxchg() 函数的核心还是调用 cmpxchg() 函数,但是返回值发生了变化,它返回一个布尔值,表示 cmpxchg() 函数的返回值是否和第二个参数的值相等。 因此,当原子地判断出 lock->owr 字段为 0 时,说明锁没有被进程持有,那么可以进入快速通道以迅速获取锁,把当前进程的 task_struct 指针的值原子设置到 lock->owner 字段中。若 lock->owner 字段不为 0,则说明该锁已经被进程持有,那么要进入慢速通道__mutex_lock_slowpath()。
互斥锁的慢速通道
__mutex_lock_slowpath() 函数调用__mutex_lock()-->__mutex_lock_common() 函数来实现。
1 | /* |
将其绘制出一张图如下: 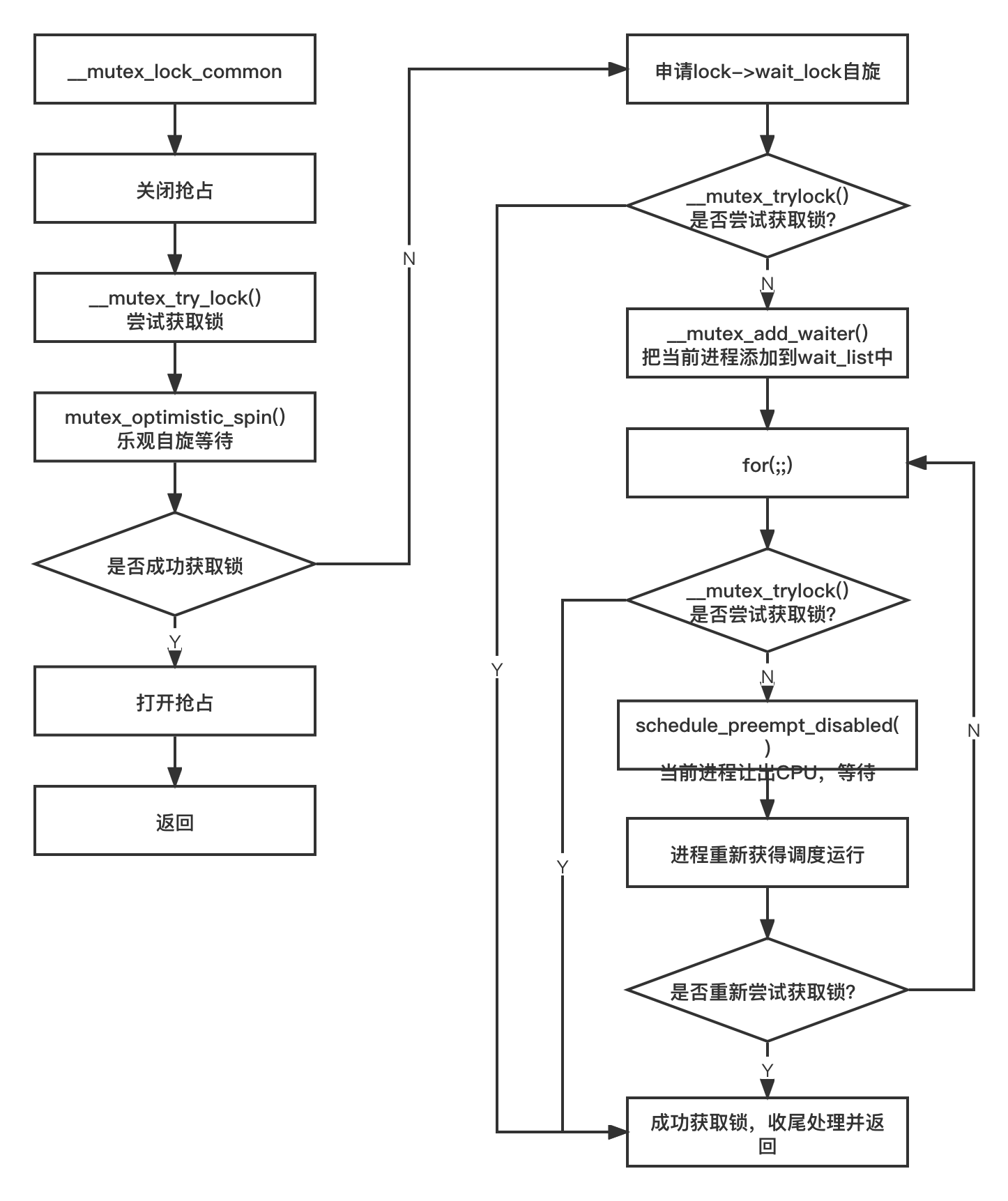
乐观自旋等待机制
乐观自旋等待机制是互斥锁的一个新特性。乐观自旋等待机制其实就是判断锁持有者正在临界区执行时,可以断定锁持有者会很快退出临界区并且释放锁,与其进入睡眠队列,不如像自旋锁一样自旋等待,因为睡眠与唤醒的代价可能更高。乐观自旋等待机制的实现在 mutex_optimistic_spin() 函数里。
1 | static __always_inline bool |
采用一张图来表示如下: 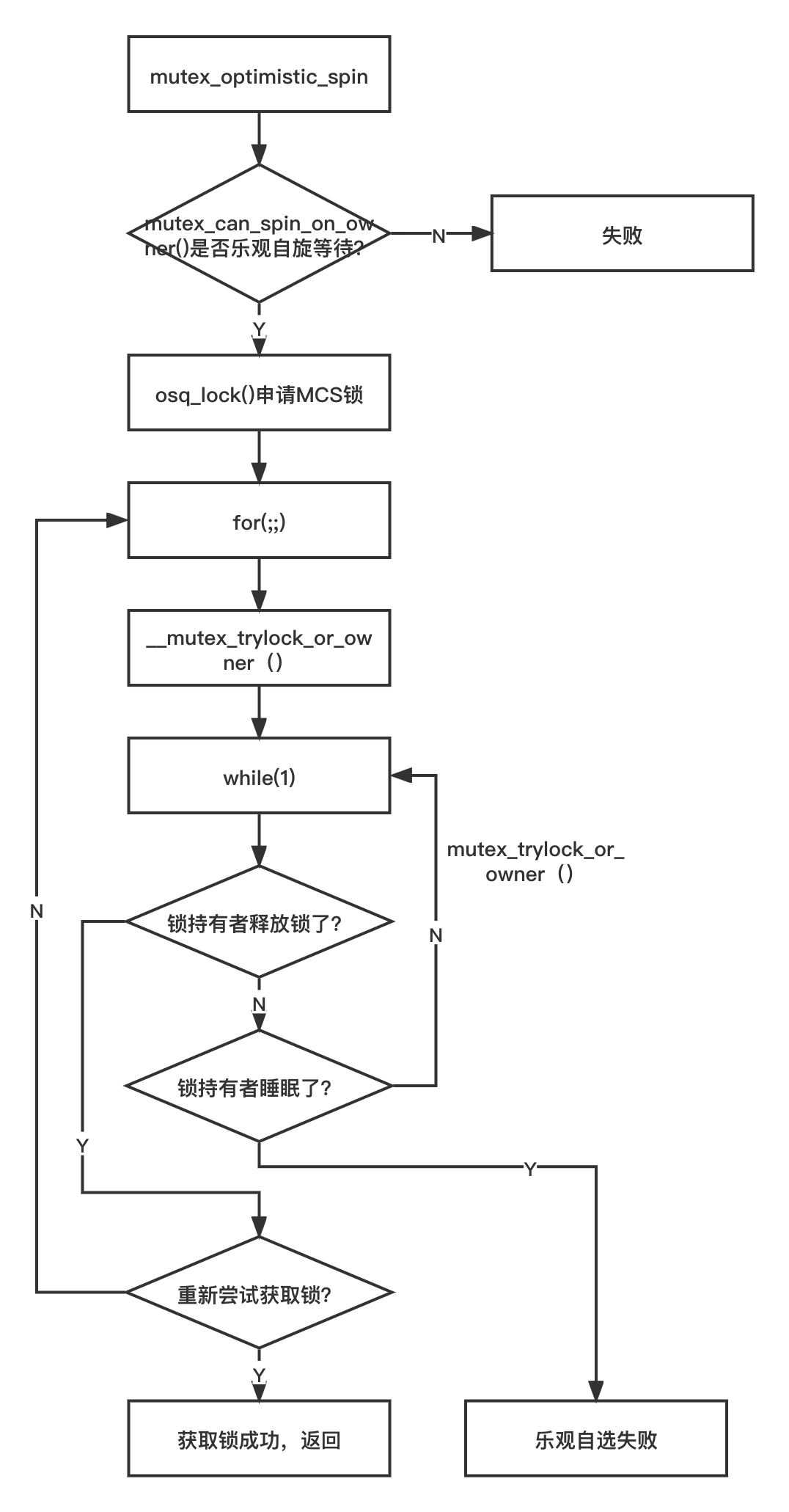
详细内容不做分析。
读写锁
上述介绍的信号量有一个明显的缺点--没有区分临界区的读写属性。读写锁通常允许多个线程并发地读访问临界区,但是写访问只限制于一个线程。读写锁能有效地提高并发性,在多处理器系统中允许有多个读者同时访问共享资源,但写者是排他性的,读写锁具有如特性。
- 允许多个读者同时进入临界区,但同一时刻写者不能进入
- 同一时刻只允许一个写者进入临界区
- 读者和写者不能同时进入临界区
读写锁有两种,分别是读者自旋锁类型和读者信号量。自旋锁类型的读写锁数据结构定义在 include/linux/rwlock_types.h 头文件中。
1 | <include/linux/rwlock_types.h> |
常用的函数如下:
- rwlock_init():初始化 rwlock
- write_lock():申请写者锁
- write_unlock():释放写者锁
- read_lock():申请读者锁
- read_unlock():释放读者锁
- read_lock_irq():关闭中断并且申请读者锁
- write_lock_irg():关闭中断并且申请写者锁
- write_unlock_irq():打开中断并且释放写者锁
和自旋锁一样,读写锁有关闭中断和下半部的版本。自旋锁类型的读写锁实现比较简单。
总结
- 互斥锁最先实现自旋等待机制
- 互斥锁在睡眠之前尝试获取锁
- 互斥锁通过实现 MCS 锁来避免多个 CPU 争用锁而导致 CPU 高速缓存行颠簸现象,正是因为互斥锁的简洁性和高效性,所以互斥锁的使用场景比信号量要更严格
使用互斥锁需要注意的约束条件如下:
- 同ー时刻只有一个线程可以持有互斥锁
- 只有锁持有者可以解锁。不能在一个进程中持有互斥锁,而在另外一个进程释放它。因此互斥锁不适合内核与用户空间复杂的同步场景,信号量和读写信号量则比较合适
- 不允许递归地加锁和解锁
- 当进程持有互斥锁时,进程不可以退出
- 互斥锁必须使用官方接口函数来初始化
- 互斥锁可以睡眠,所以不允许在中断处理程序或者中断下半部(如 tasklet、定时器)中使用
在实际项目中,该如何选择自旋锁、信号量和互斥锁呢? 在中断上下文中可以毫不犹豫地使用自旋锁,如果临界区有睡眠、隐含睡眠的动作及内核接口函数,应避免选择自旋锁。在信号量和互斥锁中该如何选择呢?除非代码场景不符合上述互斥锁的约束中的某一条,否则可以优先使用互斥锁。
参考文献
《奔跑吧 Linux 内核》