Linux 进程管理(番外篇)调度算法的演变
 原图
原图
O(n)调度器
如何组织 task
调度器模块定义了一个 runqueue_head 的链表头变量,无论进程是普通进程还是实时进程,只要进程状态变成可运行状态的时候,它会被挂入这个全局 runqueue 链表中。由于整个系统中的所有 CPU 共享一个 runqueue,为了解决同步问题,调度器模块定义了一个自旋锁来保护对这个全局 runqueue 的并发访问。
除了这个 runqueue 队列,系统还有一个囊括所有 task(不管其进程状态为何)的链表,链表头定义为 init_task,在一个调度周期结束后,重新为 task 赋初始时间片值的时候会用到该链表。
动态优先级
对于普通进程,计算动态优先级的策略如下:
- 如果该进程的时间片已经耗尽,那么动态优先级是 0,这也意味着在本次调度周期中该进程已经再也没有机会获取 CPU 资源了。
- 如果该进程的时间片还有剩余,那么其动态优先级等于该进程剩余的时间片和静态优先级之和。之所以用(20-nice value)表示静态优先级,主要是为了让静态优先级变成单调上升。之所以要考虑剩余时间片是为了奖励睡眠的进程,因为睡眠的进程剩余的时间片较多,因此动态优先级也就会高一些,更容易被调度器调度执行。
在计算普通进程的动态优先级的时候,除了考虑进程剩余时间片信息和静态优先级,调度器也会酌情考虑 cache 和 TLB 的性能问题。例如 A 和 B 进程优先级相同,剩余的时间片都是 3 个 tick,但是 A 进程上一次就是运行在本 CPU 上,如果选择 A,可能会有更好的 cache 和 TLB 的命中率,从而提高性能。在这种情况下,调度器会提升 A 进程的动态优先级。此外,如果备选进程和当前进程共享同一个地址空间,那么在计算调度指数的时候也会做小小的倾斜。
主调度器算法
主调度器(schedule 函数)核心代码如下:
1 | list_for_each(tmp, &runqueue_head) { |
list_for_each 用来遍历 runqueue_head 链表上的所有的进程,临时变量 p 就是本次需要检查的进程描述符。如何判断哪一个进程是最适合调度执行的进程呢?我们需要计算进程的动态优先级(对应上面程序中的变量 weight),它是通过 goodness 函数实现的。动态优先级最大的那个进程就是当前最适合调度到 CPU 执行的进程。一旦选中,调度器会启动进程切换,运行该进程以替换之前的那个进程。
时间片处理
普通进程的时间片处理思路是这样:
- 每个进程根据其静态优先级可以固定分配一个缺省的时间片,静态优先级越大,分配的时间片就越大。
- 一旦 Runqueue 中的进程被调度执行,那么其时间片就会在 tick 到来的时候递减,如果进程时间片耗尽,那么该进程将失去分配 CPU 资源的资格。
- Runqueue 中的进程的时间片全部被用完之后,我们称一个调度周期结束,这时候需要为 runqueue 中的进程重新设定其缺省时间片,这样,一个新的调度周期又开始了。
O(1)调度器
Why O(1)调度器
让我们一起来控诉 O(n)调度器的“七宗罪”,同时这也是 Ingo Molnar 发起 O(1)调度器项目背后的原因。
算法复杂度问题: 让人最不爽的就是对 runqueue 队列的遍历,随着系统中 runnable 状态的进程数目增多,那么调度器 select next 的运算量也随之呈线性的增长,这也是我们为什么叫它 O(n)调度器的原因。此外,调度周期结束后,调度器会为所有进程的时间片进行“充值“的动作,为每一个进程计算其时间片的过程太耗费时间。
SMP 扩展性问题,2.4 内核的 O(n)调度器有非常差的 SMP 扩展性。
CPU 空转问题: 每当 runqueue 链表中的所有进程耗尽了其时间片,这时候就需要启动对系统中所有进程时间片重新计算的过程。这个计算过程异常丑陋,需要遍历系统中的所有进程,为进程描述符的 counter 成员赋一个新值。而这个操作足以把该 CPU 上的 L1 cache 全部干掉,这时候 L1 cache 的命中率急剧下降在只剩最后一个线程的时候多个 cpu 中就会有 cpu 处于 idle 状态,出现 cpu 空转问题
task bouncing issue: 一般而言,一个进程最好是从一而终,运行在一个 cpu 上,在 O(n)调度器下很多人都反映有进程在 CPU 之间跳来跳去的现象导致 cache 命中率下降
RT 进程调度性能问题: 实时进程和普通进程挂在一个链表中。当调度实时进程的时候,我们需要遍历整个 runqueue 列表,扫描并计算所有进程的调度指数,从而选择出心仪的那个实时进程
当然,上面的这些还不是关键,最重要的是整个 linux 内核不是抢占式内核,在整个内核态都不能被抢占。除了内核抢占性之外,优先级翻转问题也需要引起调度器的重视,否则即便一个 rt 进程变成 runnable 状态了,但是也只能眼睁睁的看着比它优先级低的进程运行,直到该 rt 进程等待的资源被释放。
交互式普通进程的调度延迟问题: O(n)并不区分交互式进程和批处理进程,它只是奖励经常睡眠的那些进程
时间片粒度问题: 随着 runnable 进程增大,调度周期也变大。当一个进程耗尽其时间片之后,只能等待下一个调度周期到来。因此随着调度周期变大,系统响应也会变的较差
虽然 O(n)调度器存在不少的 issue,但是社区的人还是基本认可这套算法的,O(1)基于 O(n)调度器进行改进。鉴于 O(1)调度器和 O(n)调度器没有本质区别,因此我们只是描述它们之间不同的地方。
O(1)调度器的软件功能划分
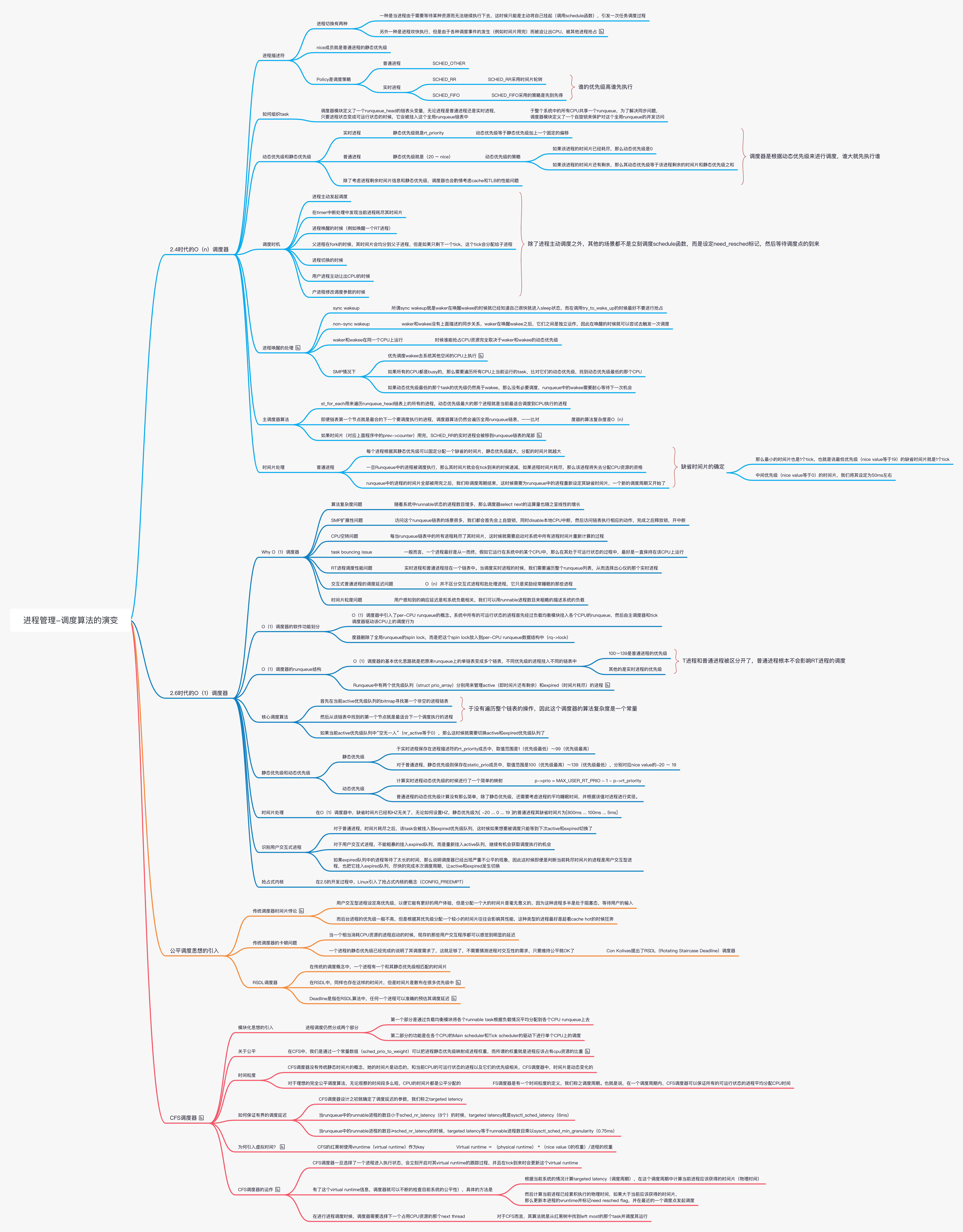
下图是一个 O(1)调度器的软件框架: 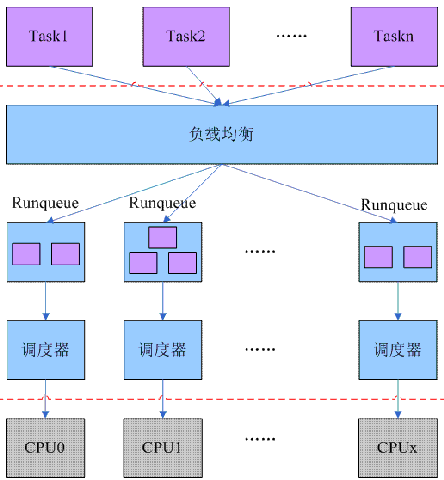
O(n)调度器中只有一个全局的 runqueue,严重影响了扩展性,因此在 O(1)调度器中引入了 per-CPU runqueue 的概念。系统中所有的可运行状态的进程首先经过负载均衡模块挂入各个 CPU 的 runqueue,然后由主调度器和 tick 调度器驱动该 CPU 上的调度行为。
由于引入了 per-CPU runqueue,O(1)调度器删除了全局 runqueue 的 spin lock,而是把这个 spin lock 放入到 per-CPU runqueue 数据结构中(rq->lock),通过把一个大锁细分成小锁,可以大大降低调度延迟,提升系统响应时间。这种方法在内核中经常使用,是一个比较通用的性能优化方法。
通过上面的软件结构划分可以解决 O(n)调度的 SMP 扩展性问题和 CPU 空转问题。此外,好的复杂均衡算法也可以解决 O(n)调度器的 task bouncing 问题。
O(1)调度器的 runqueue 结构
O(1)调度器的基本优化思路就是把原来 runqueue
上的单链表变成多个链表,即每一个优先级的进程被挂入不同链表中。相关的软件结构可以参考下面的图片:
在调度器中,runqueue 是一个很重要的数据结构,它最重要的作用是管理那些处于可运行状态的进程。O(1)调度器引入了优先级队列的概念来管理 task,具体由 struct prio_array 抽象:
1 | struct prio_array { |
由于支持 140 个优先级,因此 queue 成员中有 140 个分别表示各个优先级的链表头,不同优先级的进程挂入不同的链表中。bitmap 是表示各个优先级进程链表是空还是非空。 nr_active 表示这个队列中有多少个 task。在这些队列中,100~139 是普通进程的优先级,其他的是实时进程的优先级。因此,在 O(1)调度器中,RT 进程和普通进程被区分开了,普通进程根本不会影响 RT 进程的调度。 Runqueue 中有两个优先级队列(struct prio_array)分别用来管理 active(即时间片还有剩余)和 expired(时间片耗尽)的进程。Runqueue 中有两个优先级队列的指针,分别指向这两个优先级队列。随着系统的运行,active 队列的 task 一个个的耗尽其时间片,挂入到 expired 队列。当 active 队列的 task 为空的时候,切换 active 和 expired 队列,开始一轮新的调度过程。
虽然在 O(1)调度器中 task 组织的形式发生了变化,但是其核心思想仍然和 O(n)调度器一致的。
核心调度算法
主调度器(就是 schedule 函数)的主要功能是从该 CPU 的 runqueue 找到一个最合适的进程调度执行。其基本的思路就是从 active 优先级队列中寻找,代码如下:
1 | idx = sched_find_first_bit(array->bitmap); |
首先在当前 active 优先级队列的 bitmap 寻找第一个非空的进程链表,然后从该链表中找到的第一个节点就是最适合下一个调度执行的进程。由于没有遍历整个链表的操作,因此这个调度器的算法复杂度是一个常量,从而解决了 O(n)算法复杂度的 issue。
如果当前 active 优先级队列中“空无一人”(nr_active 等于 0),那么这时候就需要切换 active 和 expired 优先级队列了:
1 | if (unlikely(!array->nr_active)) { |
- 切换很快,并没有一个遍历所有进程重新赋 default 时间片的操作(大大缩减了 runqueue 临界区的 size)。这些都避免了 O(n)调度器带来的种种问题,从而提高了调度器的性能。
- 对于 O(1)调度器,时间片的重新赋值是分散处理的,在各个 task 耗尽其时间片之后立刻进行的。这样的改动也修正了 O(n)调度器一次性的遍历系统所有进程,重新为时间片赋值的过程。
- O(1)调度器使用非常复杂的算法来判断进程的用户交互指数以及进程是否是交互式进程,它总是比仅仅考虑睡眠时间的 O(n)调度器性能要好。
- Linux 引入了抢占式内核的概念(CONFIG_PREEMPT),如果没有配置该选项,那么一切和 2.4 内核保持一致。
番外之番外-多级反馈队列算法
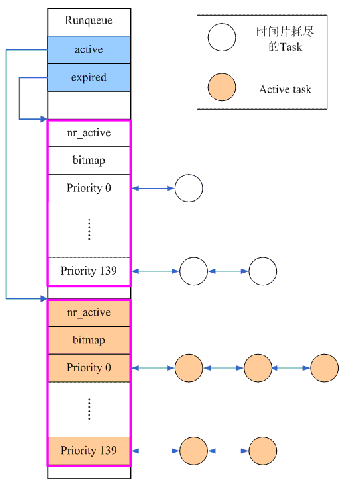
多级反馈队列算法的核心思想是把进程按照优先级分成多个队列,相同优先级的进程在同一个队列中。如图所示,系统中有
5 个优先级,每个优先级有一个队列,队列 5 的优先级最高,队列 1
的优先级最低。 
多级反馈队列算法有如下几条基本规则。
- 规则 1:如果进程 A 的优先级大于进程 B 的优先级,那么调度器选择进程 A。
- 规则 2:如果进程 A 和进程 B 的优先级一样,那么它们同属一个队列,可使用轮转调度算法来选择。
- 规则 3:当一个新进程进入调度器时,把它放入优先级最高的队列里。
- 规则 4a:当一个进程吃满时间片时,说明这是一个 CPU 消耗型的进程,需要把优先级降一级,从高优先级队列中迁移到低一级的队列里。
- 规则 4b:当一个进程在时间片还没有结束之前放弃 CPU 时,说明这是一个 I/O 消耗型的进程,优先级保持不变,维持原来的高优先级。
其实多级反馈队列算法的精髓在于“反馈”二字,也就是说,调度器可以动态地修改进程的优先级。进程可以大致分成两类,一类是 I/O 消耗型这类进程很少会完全占用时间片,通常情况下在发送 I/O 请求或者在等待 I/O 请求,比如等待鼠标操作、等待键盘输入等,这里进程和系统的用户体验很相关:另一类是 CPU 消耗型这类进程会完全占用时间片,比如计算密集型的应用程序、批处理应用程序等。多级反馈队列算法需要区分进程属于哪种类型,然后做出不同的反馈。
多级反馈队列算法看起来很不错,可是在实际应用过程中还是有不少问题的。
- 第一个问题就是产生饥饿,当系统中有大量的 I/O 消耗型的进程时,这些 I/O 消耗型的进程会完全占用 CPU,它们的优先级最高,那些 CPU 消耗型的进程就得不到 CPU 时间片,产生饥饿。
- 第二个问题是有些进程会欺骗调度器。比如,有的进程在时间片快要结束时突然发起一个 I/O 请求并且放弃 CPU。
- 第三个问题是,一个进程在生命周期里,有可能一会儿是 I/O 消耗型的,一会儿是 CPU 消耗型的,所以很难判断一个进程究竟是哪种类型。
针对第一个问题,多级反馈队列算法提出了一种改良方案,也就是在一定的时间周期后,把系统中的全部进程都提升到最高优先级,相当于系统中的进程过了一段时间又重新开始一样。
- 规则 5:每隔时间周期 S 之后,把系统中所有进程的优先级都提到最高级别。规则 5 可以解决进程饥饿的问题,然而,将时间周期 S 设置为多少合适呢?如果 S 太长,那么 CPU 消耗型的进程会饥饿;如果 S 太短,那么会影响系统的交互性。
针对第二个问题,需要对规则 4 做一些改进:
- 新的规则 4:当一个进程使用完时间片后,不管它是否在时间片的最末尾发生 I/O 请求从而放弃 CPU,都把它的优先级降一级。经过改进后的规则 4 可以有效地避免进程的欺骗行为。
在介绍完多级反馈队列算法的核心实现后,在实际工程应用中还有很多问题需要思考和解决,其中一个最难的问题是参数如何确定和优化。比如,系统需要设计多少个优先级队列?时间片应该设置成多少?规则 5 中的时间间隔 S 又应该设置成多少,才能实现既不会让进程饥饿,也不会降低系统的交互性?这些问题很难回答。
参考文献
http://www.wowotech.net/process_management/scheduler-history.html