Linux 进程管理(四)多核调度
 原图
原图
概述
SMP(Symmetrical MultiProcessing)的全称是“对称多处理”技术,是指在一台计算机上汇集了一组处理器,这些处理器都是对等的,它们之间共享内存子系统和系统总线。
下图所示为 4 核的 SMP 处理器架构,在 4 核处理器中,每个物理 CPU
核心拥有独立的 L1 缓存且不支持超线程技术,分成两个簇(cluster)簇 0 和簇
1,每个簇包含两个物理 CPU 核,簇中的 CPU 核共享 L2 缓存。 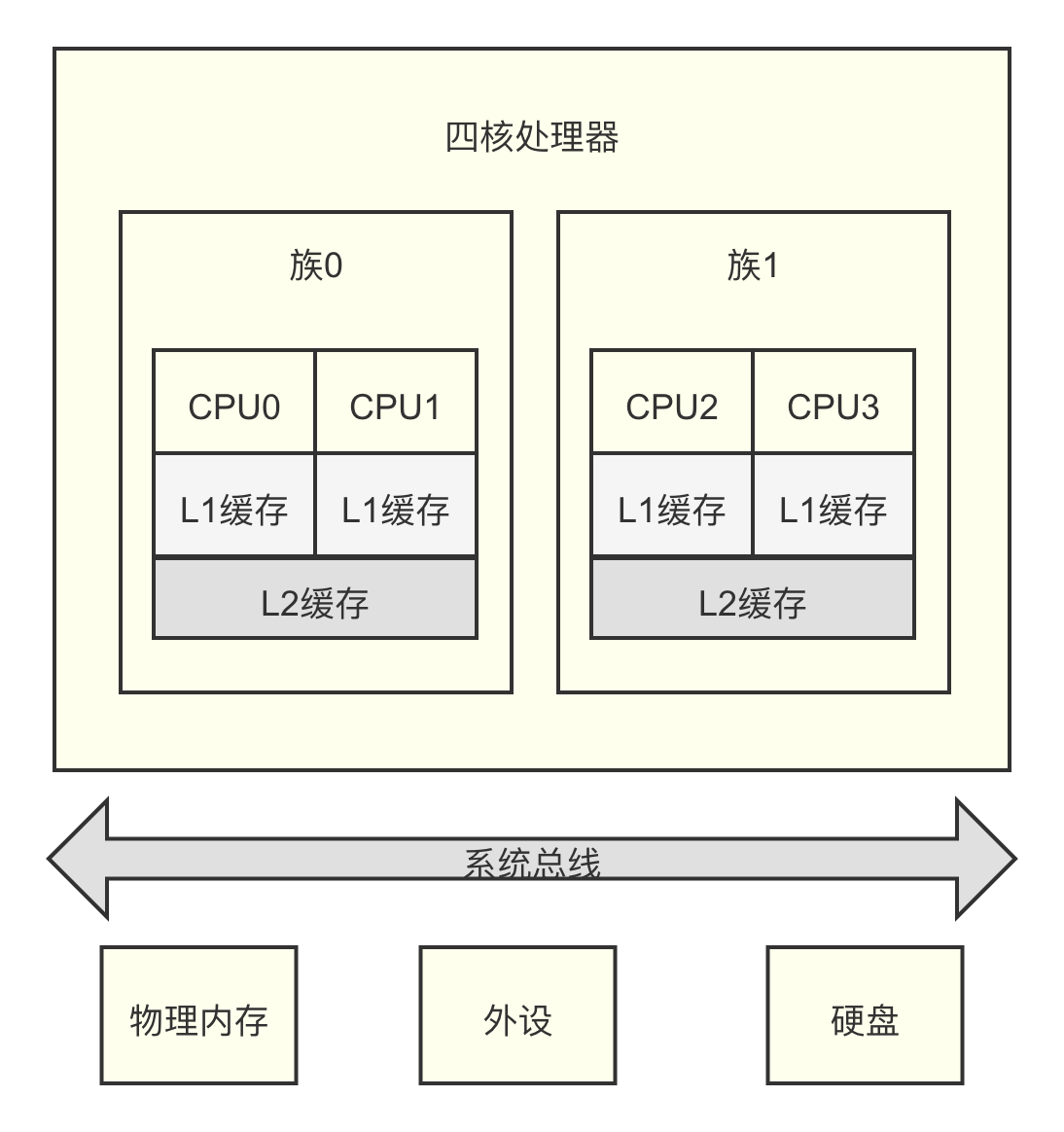
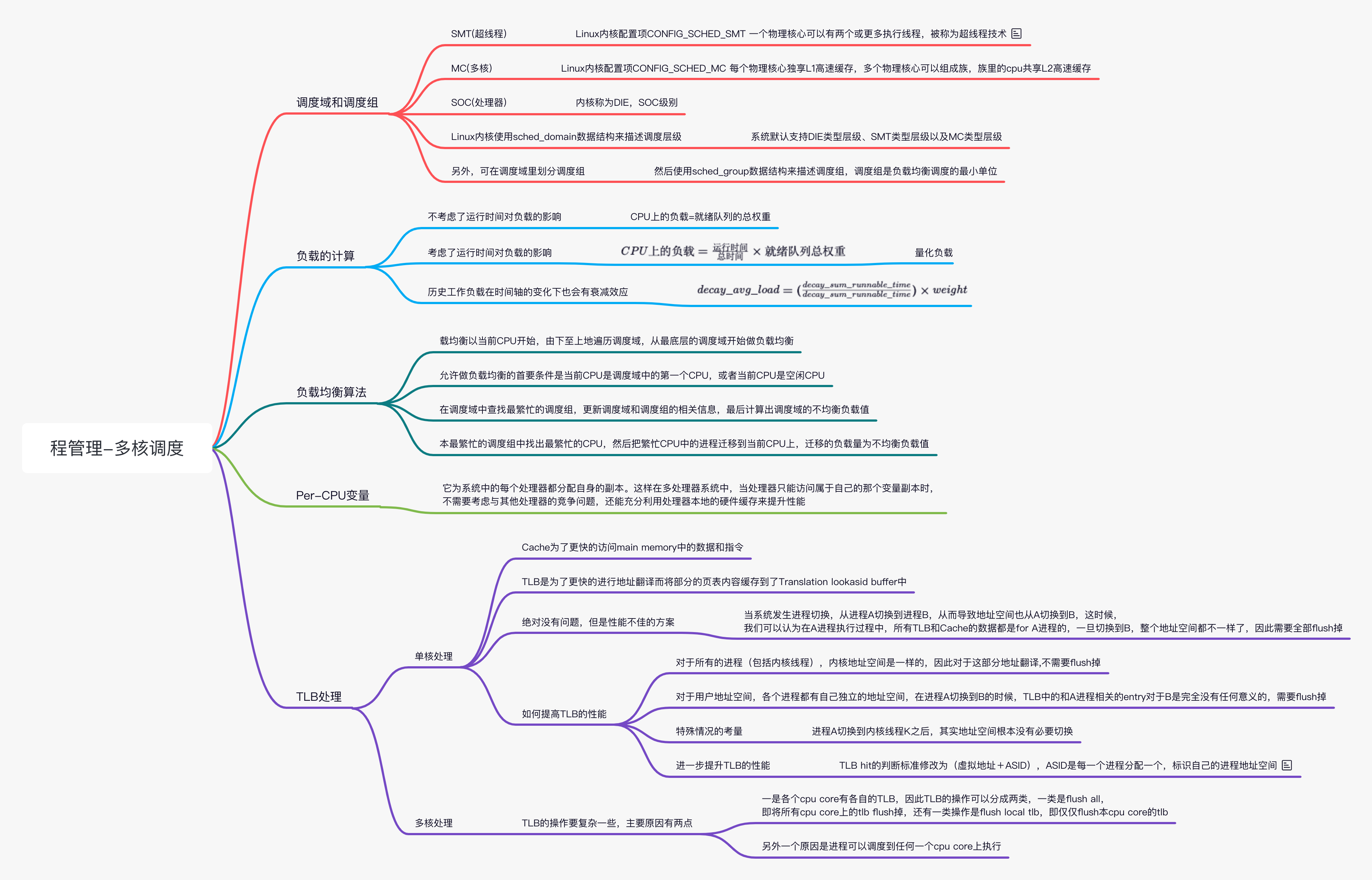
调度域和调度组
根据处理器的实际物理属性,CPU 和 Linux 内核的分类如下所示。
SMT(超线程): Linux 内核配置项 CONFIG_SCHED_SMT 一个物理核心可以有两个或更多执行线程,被称为超线程技术。超线程使用相同的 cpu 资源且共享 L1 缓存,迁移进程不会影响高速缓存的利用率
MC(多核): Linux 内核配置项 CONFIG_SCHED_MC 每个物理核心独享 L1 高速缓存,多个物理核心可以组成族,族里的 cpu 共享 L2 高速缓存
SOC(处理器): 内核称为 DIE SOC 级别
Linux 内核使用数据结构 sched_domain_topology_level 来描述 CPU 的层次关系,本节中简称为 SDTL。
1 | <include/linux/sched/topology.h> |
另外,Linux 内核默认定义了数组 default_topology[] 来概括 CPU 物理域的层次结构。
1 | <kernel/sched/topology.c> |
Linux 内核使用 sched_domain 数据结构来描述调度层级,从
defaul_topology[] 数组可知,系统默认支持 DIE 类型层级、SMT 类型层级以及
MC 类型层级。另外,可在调度域里划分调度组,然后使用 sched_group
数据结构来描述调度组,调度组是负载均衡调度的最小单位。在最低层级的调度域中,通常用调度组描述
CPU 核心。 在支持 NUMA 架构的处理器中,假设支持 SMT
技术,那么整个系统的调度域和调度组的关系如图所示,可在默认的调度层级中新增
NUMA
层级的调度域。在超大系统中,系统会频繁访问调度域数据结构。为了提升系统的性能和可扩展性,调度域数据结构
sched_domain 采用 Per-CPU 变量来构建 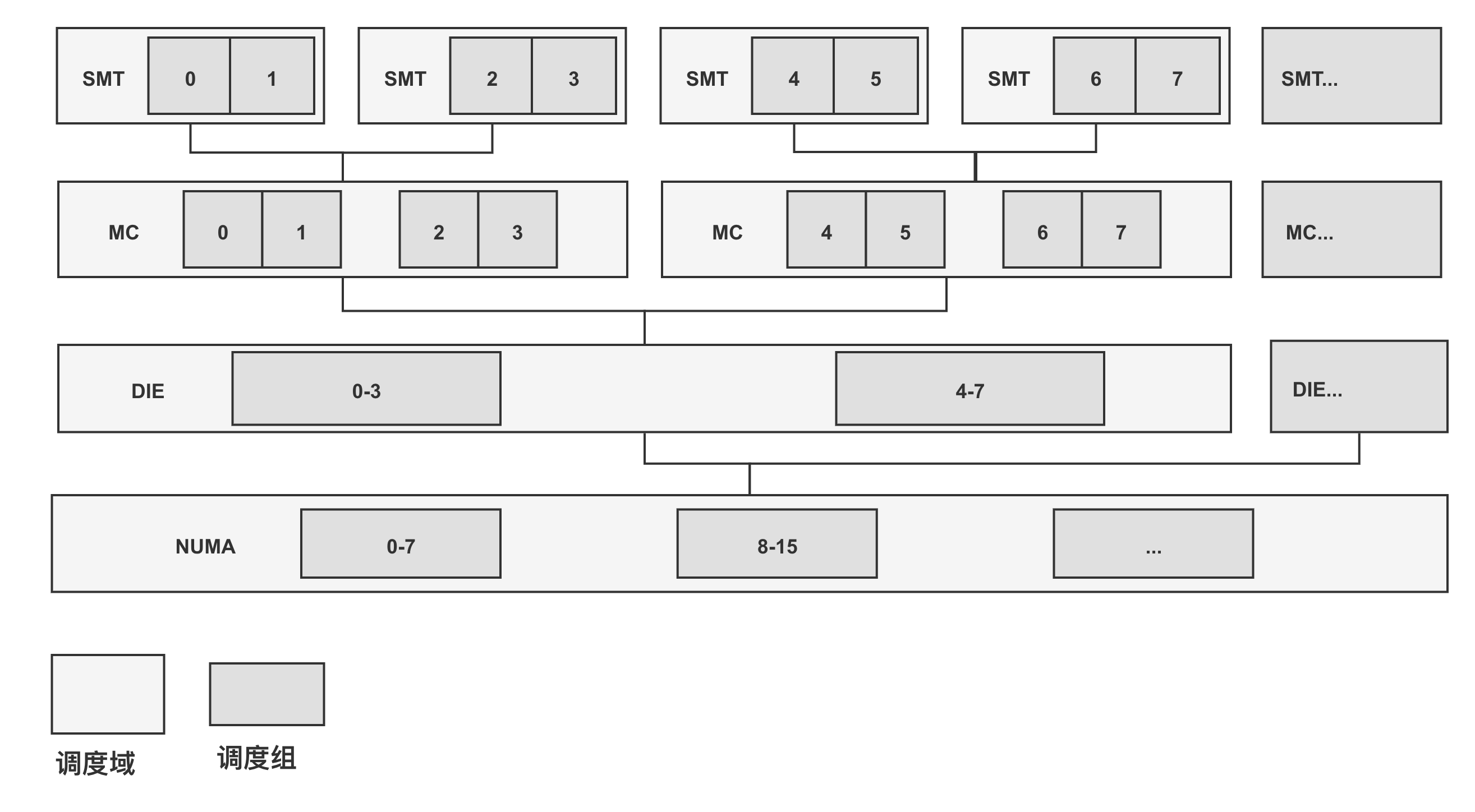
负载的计算
例 1
假设在如图所示的双核处理器里,CPU0 的就绪队列里有 4 个进程,CPU1
的就绪队列里有两个进程,那么究竟哪个 CPU 上的负载重呢? 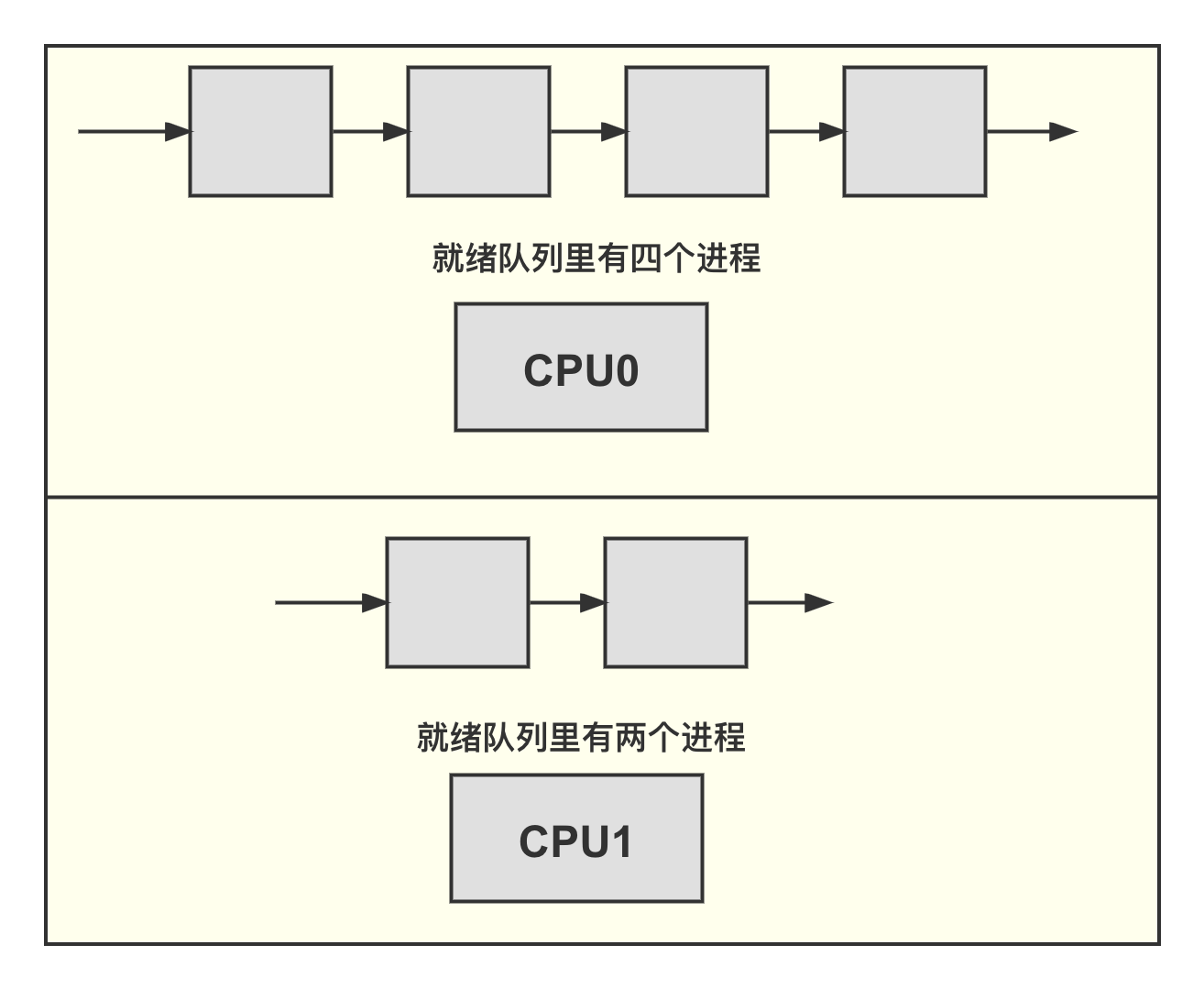
假设上述 6 个进程的 nice 值是相同的,也就是优先级和权重都相同,那么明显可以看出 CPU0 的就绪队列里有 4 个进程,相比 CPU1 的就绪队列里的进程数目要多,从而得出 CPU0 上的负载相比 CPU1 更重的结论。
CPU 上的负载=就绪队列的总权重为了计算 CPU 上的负载,最简单的方法是计算 CPU 的就绪队列中所有进程的权重。
但是,仅考虑优先级和权重是有问题的,有的是 CPU 密集型的,也有的是 I/O 密集型的。如果延伸到多 CPU 之间的负载均衡,结果就显得不准确了。
例 2
在如图所示的双核处理器里,CPU0 和 CPU1
的就绪队列里都只有一个进程在运行,而且进程的优先级和权重相同。但是,CPUO
上的进程一直在占用 CPU,而 CPU1 上的进程走走停停,那么究竟 CPU0 和 CPU1
上的负载是不是相同呢? 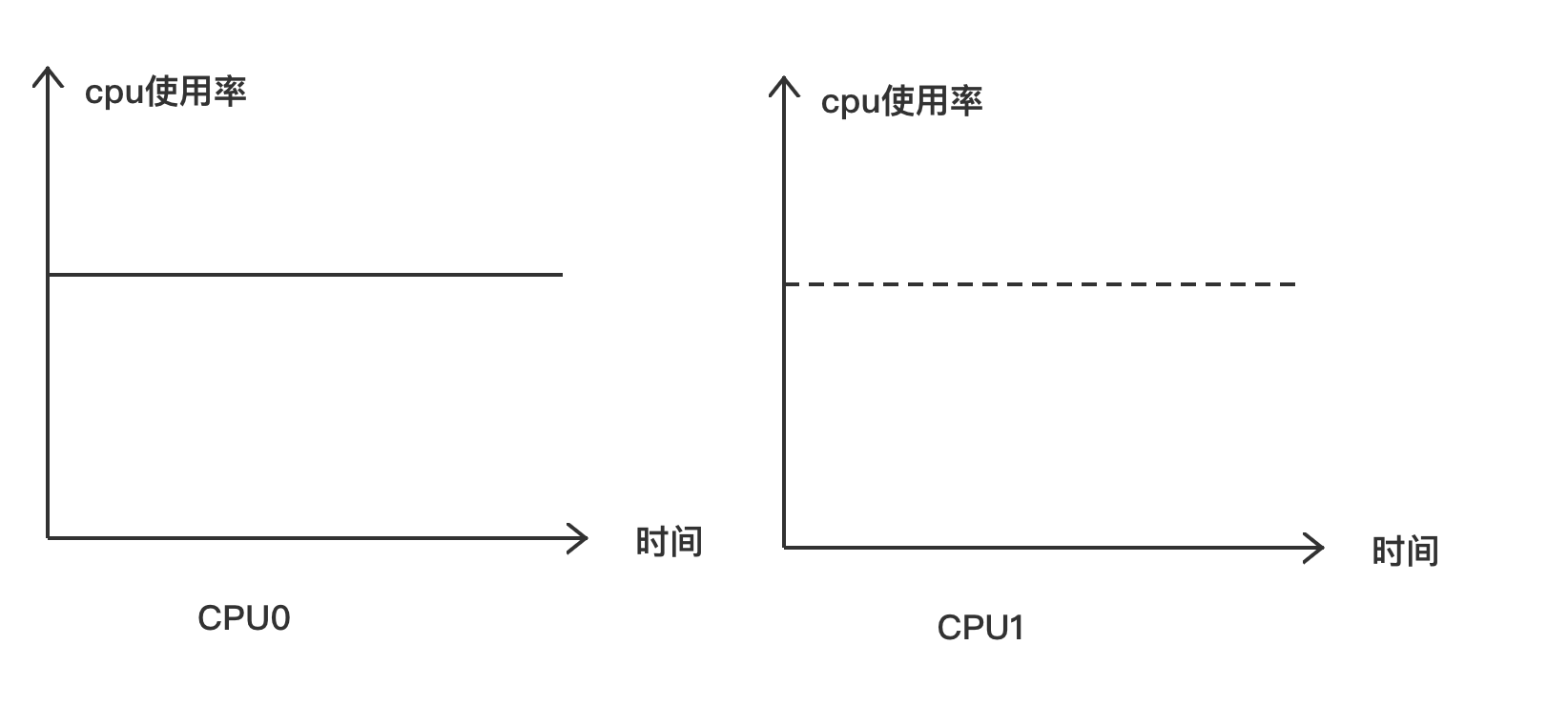
从例 1 中的判断条件看,两个 CPU 上的负载是一样的。但是,从我们的直观感受看,CPU0 上的进程一直占用 CPU,CPU0 是一直满负荷运行的,而 CPU1 上的进程走走停停,CPU 使用率不高。为什么会得出不一样的结论呢? 这是因为例 1 使用的计算方法没有考虑进程在时间因素下的作用,也就是没有考虑历史负载对当前负载的影响。那么该如何计算历史负载对 CPU 上的负载的影响呢?
CPU 上的负载的计算公式如下。 \[ CPU 上的负载 = \frac{运行时间}{总时间} \times 就绪队列总权重 \tag{2} \] 其中,运行时间是指就绪队列占用 CPU 的总时间;总时间是指采样的总时间,包括 CPU 处于空闲的时间以及 CPU 正在运行的时间;就绪队列总权重是指就绪队列里所有进程的总权重。
式 2 把负载这个概念量化到了权重,这样不同运行行为的进程就有了量化的标准来衡量负载,本书把这种用运行时间与总时间的比值来计算的权重,称为量化负载。另外,我们把时间与权重的乘积称为工作负载。
式 2 并不完美,因为它把历史工作负载和当前工作负载平等对待了。
因此,自 Linux3.8 内核以后,进程的负载计算不仅要考虑权重,而且要跟踪每个调度实体的历史负载情况,因而称为 PELT (Per-Entitv Load Tracking)。PELT 算法引入了 "accumulation of an infinite geometric series”这个概念,英文字面意思是无穷几何级数的累加,本书把这个概念简单称为历史累计计算。
Linux 内核使用量化负载这个概念来计算和比较进程以及就绪队列的负载。 根据量化负载的定义,量化负载的计算如式 3 所示。 \[ decay\_avg\_load = (\frac{decay\_sum\_runnable\_time}{decay\_sum\_runnable\_time}) \times weight \tag{3} \]
其中,decay_avg_load 表示量化负载;decay_sum_runnable_time 指的是就绪队列或调度实体在可运行状态下的所有历史累计衰减时间;decay_sum_period_time 指的是就绪队列或调度实体在所有的采样周期里全部时间的累加衰减时间。通常从进程开始执行时就计算和累计这些值。weight 表示调度实体或就绪队列的权重。 计算进程的量化负载的意义在于能够把负载量化到权重里。当一个进程的 decay_sumrunnable_time 无限接近 decay_sum_period_time 时,它的量化负载就无限接近权重值,说明这个进程一直在占用 CPU,满负荷工作,CPU 占用率很高。一个进程的 decay_sum_runnable_time 越小,它的量化负载就越小,说明这个进程的工作负荷很小,占用的 CPU 资源很少,CPU 占用率很低。这样,我们就对负载实现了统一和标准化的量化计算,不同行为的进程就可以进行标准化的负载计算和比较了。
负载均衡算法
SMP 负载均衡机制从注册软中断开始,系统每次调度 tick 中断时,都会检查当前是否需要处理 SMP 负载均衡。rebalance_domains() 函数是负载均衡的核心入口。load_balance() 函数中的主要流程如下。
- 负载均衡以当前 CPU 开始,由下至上地遍历调度域,从最底层的调度域开始做负载均衡
- 允许做负载均衡的首要条件是当前 CPU 是调度域中的第一个 CPU,或者当前 CPU 是空闲 CPU。详见 should_we_balance() 函数
- 在调度域中查找最繁忙的调度组,更新调度域和调度组的相关信息,最后计算出调度域的不均衡负载值
- 最繁忙的调度组中找出最繁忙的 CPU,然后把繁忙 CPU 中的进程迁移到当前 CPU 上,迁移的负载量为不均衡负载值
Per-CPU 变量
Per-CPU 变量是 Linux 内核中同步机制的一种。当系统中的所有 CPU 都访问共享的一个变量 v 时,如果 CPU0 修改了变量 v 的值,而 CPU1 也在同时修改变量 v 的值,就会导致变量 v 的值不正确。一种可行的办法就是在 CPU0 访问变量 v 时使用原子加锁指令,这样 CPU1 访问变量 v 时就只能等待了,但这样做有两个比较明显的缺点。
- 原子操作是比较耗时的
- 在现代处理器中,每个 CPU 都有 L1 缓存,因而多个 CPU 同时访问同一个变量就会导致缓存一致性问题。当某个 CPU 对共享的数据变量 v 进行修改后,其他 CPU 上对应的缓存行需要做无效操作,这对性能是有损耗的
Per-CPU 变量是为了解决上述问题而出现的一种有趣的特性,它为系统中的每个处理器都分配自身的副本。这样在多处理器系统中,当处理器只能访问属于自己的那个变量副本时,不需要考虑与其他处理器的竞争问题,还能充分利用处理器本地的硬件缓存来提升性能。
Per-CPU 变量的定义和声明
Per-CPU 变量的定义和声明有两种方式。一种是静态声明,另一种是动态分配。静态的 Per-CPU 变量可通过 DEFINE_PER_CPU 和 DECLARE_PER_CPU 宏来定义和声明。这类变量与普通变量的主要区别在于它们存放在一个特殊的段中。
1 | /* |
用于动态分配和释放 per-cpu 变量的 API 函数如下。
1 |
|
使用 Per-CPU 变量
对于静态定义的 Per-CPU 变量,可以通过 get_cpu_var() 和 put_cpu_var() 函数来访问和修改,这两个函数内置了关闭和打开内核抢占的功能。另外需要注意的是,这两个函数需要配对使用。
1 |
对于动态分配的 Per-CPU 变量,需要通过以下接口来访问:
1 |
TLB 处理
单核处理
在进程切换的时候,需要有 tlb 的操作,以便清除旧进程的影响,具体怎样做呢?我们下面一一讨论。
绝对没有问题,但是性能不佳的方案: 所有 TLB 和 Cache 的数据都全部 flush 掉。当然,稍微有一点遗憾的就是在 B 进程开始执行的时候,TLB 和 Cache 都是冰冷的
如何提高 TLB 的性能: 对于所有的进程(包括内核线程),内核地址空间是一样的,因此对于这部分地址翻译,无论进程如何切换,内核地址空间转换到物理地址的关系是永远不变的,不需要 flush TLB。对于用户地址空间,各个进程都有自己独立的地址空间,在进程 A 切换到 B 的时候,TLB 中的和 A 进程相关的 entry(上图中,青色的 block)需要 flush 掉 我们其实需要区分 global 和 local 这两种类型的地址翻译,因此,在页表描述符中往往有一个 bit 来标识该地址翻译是 global 还是 local 的,同样的,在 TLB 中,这个标识 global 还是 local 的 flag 也会被缓存起来。有了这样的设计之后,我们可以根据不同的场景而 flush all 或者只是 flush local tlb entry
特殊情况的考量: 对于多线程环境,切换可能发生在一个进程中的两个线程,这时候,线程在同样的地址空间,也根本不需要 flush tlb
进一步提升 TLB 的性能: 这里有一个术语叫做 ASID(address space ID)。原来 TLB 查找是通过虚拟地址 VA 来判断是否 TLB hit。有了 ASID 的支持后,TLB hit 的判断标准修改为(虚拟地址+ASID),ASID 是每一个进程分配一个,标识自己的进程地址空间。TLB block 如何知道一个 tlb entry 的 ASID 呢?一般会来自 CPU 的系统寄存器(对于 ARM64 平台,它来自 TTBRx_EL1 寄存器),这样在 TLB block 在缓存(VA-PA-Global flag)的同时,也就把当前的 ASID 缓存在了对应的 TLB entry 中,这样一个 TLB entry 中包括了(VA-PA-Global flag-ASID)
多核处理
在多核系统中,进程切换的时候,TLB 的操作要复杂一些,原因是进程可以调度到任何一个 cpu core 上执行。
根据上一节的描述,我们了解到地址翻译有 global(各个进程共享)和 local(进程特定的)的概念,因而 tlb entry 也有 global 和 local 的区分。如果区分 global 和 local,那么 tlb 操作也基本类似,只不过进程切换的时候,不是 flush 该 cpu 上的所有 tlb entry,而是 flush 所有的 tlb local entry 就 OK 了。
对 local tlb entry 还可以进一步细分,那就是 ASID(address space ID)或者 PCID(process context ID)的概念了(global tlb entry 不区分 ASID)。如果支持 ASID(或者 PCID)的话,tlb 操作变得简单一些,或者说我们没有必要执行 tlb 操作了,因为在 TLB 搜索的时候已经可以区分各个 task 上下文了,这样,各个 cpu 中残留的 tlb 不会影响其他任务的执行。
不过,对于多核系统,这种情况有一点点的麻烦,其实也就是传说中的 TLB shootdown 带来的性能问题。在多核系统中,如果 cpu 支持 PCID 并且在进程切换的时候不 flush tlb,那么系统中各个 cpu 中的 tlb entry 则保留各种 task 的 tlb entry,当在某个 cpu 上,一个进程被销毁,或者修改了自己的页表(也就是修改了 VA PA 映射关系)的时候,我们必须将该 task 的相关 tlb entry 从系统中清除出去。这时候,你不仅仅需要 flush 本 cpu 上对应的 TLB entry,还需要 shootdown 其他 cpu 上的和该 task 相关的 tlb 残余。而这个动作一般是通过 IPI 实现(例如 X86),从而引入了开销。此外 PCID 的分配和管理也会带来额外的开销,因此,OS 是否支持 PCID(或者 ASID)是由各个 arch 代码自己决定。
参考文献
《奔跑吧 Linux 内核》
《Linux 内核设计与实现》
http://www.wowotech.net/process_management/context-switch-tlb.html