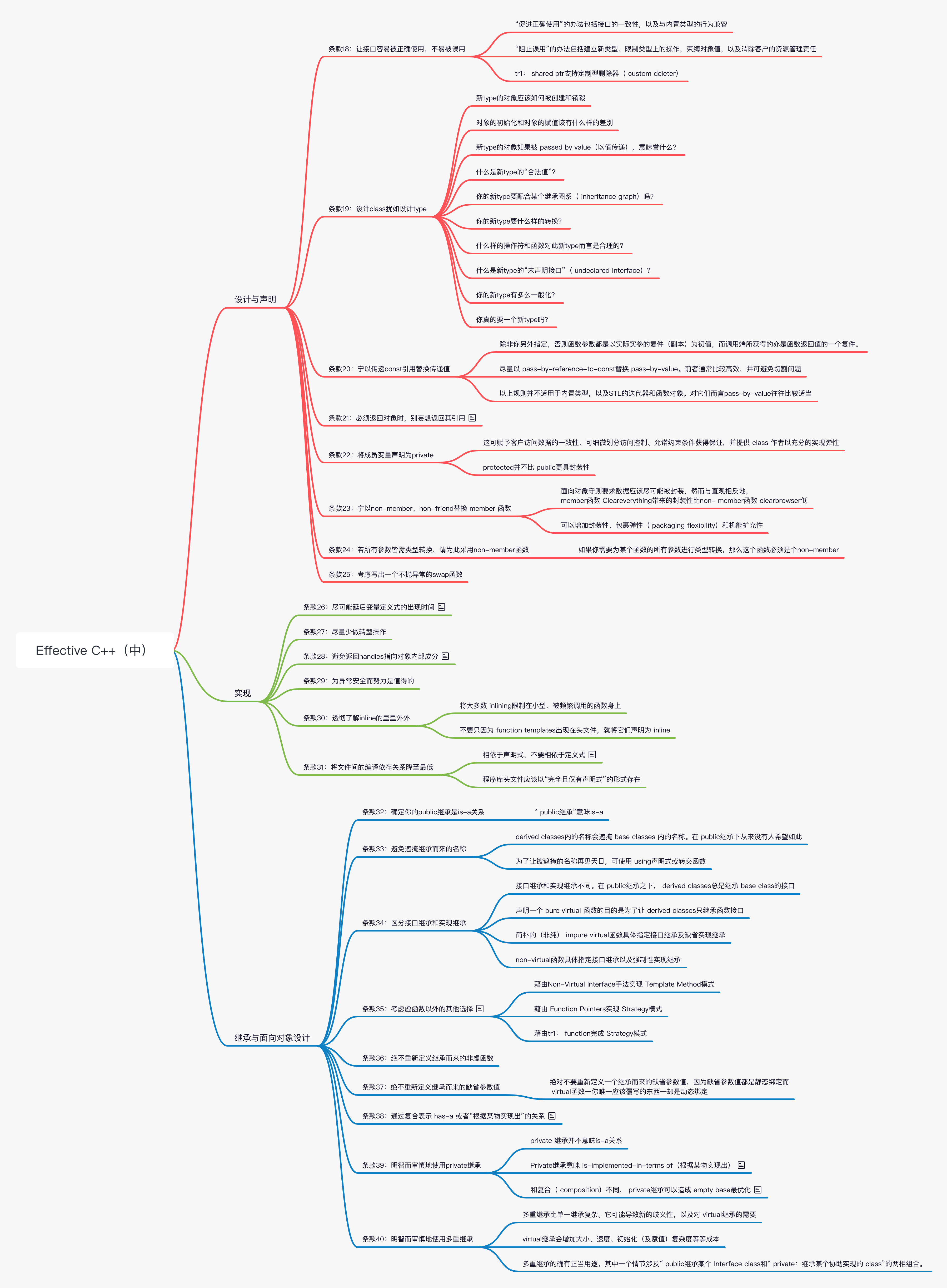
C++(三) Effective C++(中)
 原图
原图
设计与声明
条款 19:设计 class 犹如设计 type
C++就像在其他 OOP(面向对象编程)语言一样,当你定义一个新 class,也就定义了一个新 type。这意味你并不只是 class 设计者,还是 type 设计者。重载( overloading)函数和操作符、控制内存的分配和归还、定义对象的初始化和终结全都在你手上。因此你应该带着和“语言设计者当初设计语言内置类型时”一样的谨慎来研讨 class 的设计。
条款 20:宁以传递 const 引用替换传递值
缺省情况下 C++以 by value 方式传递对象至(或来自)函数。除非你另外指定,否则函数参数都是以实际实参的复件(副本)为初值,而调用端所获得的亦是函数返回值的一个复件。这些复件(副本)系由对象的 capy 构造函数产出,这可能使得 pass-by-value 成为费时的操作。
如果有什么方法可以回避所有那些构造和析构动作就太好了。有的,就是 pass by reference-to-const:这种传递方式的效率高得多:没有任何构造函数或析构函数被调用,因为没有任何新对象被创建。修订后的这个参数声明中的 const 是重要的。
以 by reference 方式传递参数也可以避免 slicing(对象切割)问题。当一个 derived class 对象以 by value 方式传递并被视为一个 base class 对象, base class 的 copy 构造函数会被调用,而“造成此对象的行为像个 derived class 对象”的那些特化性质全被切割掉了,仅仅留下一个 base class 对象。这实在不怎么让人惊讶,因为正是 base class 构造函数建立了它,但这几乎绝不会是你想要的。
请记住
- 尽量以 pass-by-reference-to-const 替换 pass-by-value。前者通常比较高效,并可避免切割问题( slicing problem)
- 以上规则并不适用于内置类型,以及 STL 的迭代器和函数对象。对它们而言 pass-by-value 往往比较适当
条款 21:必须返回对象时,别妄想返回其引用
1 | const Rational& operator* (const Rational& lhs |
就像所有用上 static 对象的设计一样,这一个也立刻造成我们对多线程安全性的疑虑。不过那还只是它显而易见的弱点。如果想看看更深层的瑕疵,考虑以下面这些完全合理的客户代码
1 | bool operator==(const Rational& lhs //ー个针对 Rationals |
猜想怎么着?表达式(a * b)==(c * d))总是被核算为 true,不论 a,b,c 和 d 的值是什么! 一旦将代码重新写为等价的函数形式,很容易就可以了解出了什么意外:
1 | if (operator==(operator*(a, b), operator*(c, d))) |
注意,在 operator==被调用前,已有两个 operator* 调用式起作用,每一个都返回 reference 指向 operator 的内部定义的 static Rational 对象。因此 operator=被要求将“ operator* 内的 static Rational 对象值”拿来和“ operator* 内的 static Rational 对象值”比较,如果比较结果不相等,那オ奇怪呢。(译注:这里我补充说明:两次 operator *调用的确各自改变了 static Rational 对象值,但由于它们返回的都是 reference,因此调用端看到的永远是 static Rational 对象的“现值”。)
请记住
绝不要返回 pointer 或 reference 指向一个 local stack 对象,或返回 reference 指向个 heap allocated 对象,或返回 pointer 或 reference 指向一个 local static 对象而有可能同时需要多个这样的对象。
条款 22:将成员变量声明为 private
对于 private 变量,如果你通过函数访问成员变量,日后可改以某个计算替换这个成员变量,而 class 客户一点也不会知道 class 的内部实现已经起了变化,完全具备封装性。
假设我们有一个 public 成员变量,而我们最终取消了它,多少代码可能会被破坏呢?唔,所有使用它的客户码都会被破坏,而那是一个不可知的大量,因此 public 成员变量完全没有封装性。
假设我们有一个 protected 成员变量,而我们最终取消了它,有多少代码被破坏?唔,所有使用它的 derived classes 都会被破坏,那往往也是个不可知的大量。因此, protected 成员变量完全没有封装性。
条款 23:宁以 non-member、non-friend 替换 member 函数
让我们从封装开始讨论。如果某些东西被封装,它就不再可见。愈多东西被封装,愈少人可以看到它,我们就有愈大的弹性去变化它。因此,愈多东西被封装,我们改变那些东西的能力也就愈大。
现在考虑对象内的数据。愈少代码可以看到数据,愈多的数据可被封装,而我们也就愈能自由地改变对象数据,愈多函数可访问它,数据的封装性就愈低。
条款 22 曾说过,成员变量应该是 private,能够访问 private 成员变量的函数只有 class 的 member 函数加上 friend 函数而已。如果要你在一个 member 函数和一个 non-member,non-friend 函数之间做抉择,而且两者提供相同机能,那么,导致较大封装性的是 non-member non-friend 函数,因为它并不增加“能够访问 class 内之 private,成分”的函数数量。
将所有便利函数放在多个头文件内但隶属同一个命名空间,意味客户可以轻松扩展这一组便利函数。他们需要做的就是添加更多 non-member non-friend 函数到此命名空间内。
条款 24:若所有参数皆需类型转换,请为此采用 non-member 函数
假设你这样开始你的 Rational class:
1 | class Rational |
你想支持算术运算诸如加法、乘法等等,但你不确定是否该由 member 函数、non-member 函数,或可能的话由 non-member friend 函数来实现它们,先研究一下将 operator *写成 Rational 成员函数的写法:
1 | class Rational |
这个设计使你能够将两个有理数以最轻松自在的方式相乘:
1 | Rational oneEighth(1, 8); |
但你还不满足。你希望支持混合式运算,也就是拿 Rationals 和……嗯例如 int 相乘。毕竟很少有什么东西会比两个数值相乘更自然的了一即使是两个不同类型的数值。然而当你尝试混合式算术,你发现只有一半行得通:
1 | result = oneHalf * 2; //很好 |
这不是好兆头。乘法应该满足交换律,不是吗?当你以对应的函数形式重写上述两个式子,问题所在便一目了然了:
1 | result= oneHalf.operator*(2); //很好 |
是的, oneHalf 是一个内涵 operator* 函数的 class 的对象,所以编译器调用该函数。然而整数 2 并没有相应的 class,也就没有 operator* 成员函数。
结论是,只有当参数被列于参数列( parameter list)内,这个参数才是隐式类型转换的合格参与者。这就是为什么上述第一次调用可通过编译,第二次调用则否,因为第一次调用伴随一个放在参数列内的参数,第二次调用则否。 然而你一定也会想要支持混合式算术运算。可行之道终于拨云见日:让 operator 成为一个 non-member 函数,俾允许编译器在每一个实参身上执行隐式类型转换:
1 | class Rational |
实现
条款 26:尽可能延后变量定义式的出现时间
尽可能延后变量定义式的出现,既包括延后构造它,保证只有真正使用才构造;也包括只有到赋值时才构造它,避免默认构造函数无谓调用。 对于循环操作,在循环前还是中进行构造,取决于赋值操作与构造+析构操作的成本对比。
- 循环前:1 个构造函数+1 个析构函数+n 个赋值操作。
- 循环后:n 个构造函数+n 个析构函数。
条款 30:透彻了解 inline 的里里外外
在一台内存有限的机器上,过度热衷 inline 会造成程序体积太大。即使拥有虚拟内存, inline 造成的代码膨胀亦会导致额外的换页行为( paging),降低指令高速缓存装置的击中率( instruction cache hit rate),以及伴随这些而来的效率损失。
换个角度说,如果 inline 函数的本体很小,编译器针对“函数本体”所产出的码可能比针对“函数调用”所产出的码更小。果真如此,将函数 inline 确实可能导致较小的目标码( object code)和较高的指令高速缓存装置击中率!
程序库设计者必须评估“将函数声明为 inline”的冲击: inline 函数无法随着程序库的升级而升级。换句话说如果 f 是程序库内的一个 inline 函数,客户将“f 函数本体”编进其程序中,一旦程序库设计者决定改变 f,所有用到 f 的客户端程序都必须重新编译。这往往是大家不愿意见到的。
记住, inline 只是对编译器的一个申请,不是强制命令。这项申请可以隐喻提出,也可以明确提出。隐喻方式是将函数定义于 class 定义式内。
条款 31:将文件间的编译依存关系降至最低
针对 Person 我们可以这样做:把 Person 分割为两个 classes,一个只提供接口,另一个负责实现该接口。如果负责实现的那个所谓 implementation class 取名为 PersonImpl, Person 将定义如下:
1 |
|
这样就不必 include Date、Address 等头文件而只是声明该 class(定义式改声明式)。
pimp 方式
在这里, class Person 只内含一个指针成员,指向其实现类( PersonImpl)。这般设计常被称为 pimpl idiom(pimp 是" pointer to implementation"的缩写)。
这样的设计之下, Person 的客户就完全与 Dates, Addresses 以及 Persons 的实现细目分离了。那些 classes 的任何实现修改都不需要 Person 客户端重新编译。此外由于客户无法看到 Person 的实现细目,也就不可能写出什么“取决于那些细目”的代码。这真正是“接口与实现分离。
这个分离的关键在于以“声明的依存性”替换“定义的依存性”,那正是编译依存性最小化的本质:现实中让头文件尽可能自我满足,万一做不到,则让它与其他文件内的声明式(而非定义式)相依。其他每一件事都源自于这个简单的设计策略。
- 如果使用 object references 或 object pointers 可以完成任务,就不要使用 objects。你可以只靠一个类型声明式就定义出指向该类型的 references 和 pointers;但如果定义某类型的 objects,就需要用到该类型的定义式。
- 如果能够,尽量以 class 声明式替换 class 定义式。
abstract baseclass 方式
另一个制作 Handle class 的办法是,令 Person 成为一种特殊的 abstract baseclass(抽象基类),称为 Interface class。这种 class 的目的是详细一描述 derived classes 的接口,因此它通常不带成员变量,也没有构造函数,只有个 virtual 析构函数以及一组 pure virtual 函数,用来叙述整个接口。
继承与面向对象设计
条款 32:确定你的 public 继承是 is-a 关系
“ public 继承”意味 is-a。适用于 base classes 身上的每一件事情一定也适用于 derived classes 身上,因为每一个 derived class 对象也都是一个 base class 对象。
条款 33:避免遮掩继承而来的名称
- derived classes 内的名称会遮掩 base classes 内的名称。在 public 继承下从来没有人希望如此。
- 为了让被遮掩的名称再见天日,可使用 using 声明式或转交函数( forwarding functions)。
条款 34:区分接口继承和实现继承
1 | class Shape |
shape class 声明了三个函数。draw 是个 pure virtual 函数; error 是个简朴的(非纯) impure virtual 函数; objectid 是个 non-virtual 函数。这些不同的声明带来什么样的暗示呢?
- 声明一个 pure virtual 函数的目的是为了让 derived classes 只继承函数接口。
- 声明简朴的(非纯) impure virtual 函数的目的,是让 derived classes 继承该函数的接口和缺省实现。
- 声明 non-virtual 函数的目的是为了令 derived classes 继承函数的接口及一份强制性实现。
条款 35:考虑虚函数以外的其他选择
假设你正在写一个视频游戏软件,你打算为游戏内的人物设计一个继承体系。你的游戏属于暴力砍杀类型,剧中人物被伤害或因其他因素而降低健康状态的情况并不罕见。你因此决定提供一个成员函数 healthvalue,它会返回一个整数,表示人物的健康程度。由于不同的人物可能以不同的方式计算他们的健康指数,将 healthvalue 声明为 virtual 似乎是再明白不过的做法:
1 | class GameCharacter |
healthvalue 并未被声明为 pure virtual,这暗示我们将会有个计算健康指数的缺省算法。这的确是再明白不过的设计,但是从某个角度说却反而成了它的弱点。由于这个设计如此明显,你可能因此没有认真考虑其他替代方案。为了帮助你跳脱面向对象设计路上的常轨,让我们考虑其他一些解法。
藉由 Non-Virtual Interface 手法实现 Template Method 模式
我们将从一个有趣的思想流派开始,这个流派主张 virtual 函数应该几乎总是 private。这个流派的拥护者建议,较好的设计是保留 healthvalue 为 public 成员函数,但让它成为 non-virtual,并调用一个 private virtual 函数(例如 dohealthvalue)进行实际工作:
1 | class GameCharacter |
令客户通过 public non-virtual 成员函数间接调用 private virtual 函数,称为 mom-virtual interface(NVI)手法。它是所谓 Template Method 设计模式(与 C++ templates 并无关联)的一个独特表现形式。
NVI 手法的一个优点隐身在上述代码注释“做一些事前工作”和“做一些事后工作”之中。那些注释用来告诉你当时的代码保证在“ virtual 函数进行真正工作之前和之后”被调用。
藉由 Function Pointers 实现 Strategy 模式
另一个更戏剧性的设计主张“人物健康指数的计算与人物类型无关”,这样的计算完全不需要“人物”这个成分。例如我们可能会要求每个人物的构造函数接受一个指针,指向一个健康计算函数,而我们可以调用该函数进行实际计算:
1 | class Gamecharacter; //前置声明( forward declaration) |
这个做法是常见的 Strategy 设计模式的简单应用。拿它和“植基于 GameCharacter 继承体系内之 virtual 函数”的做法比较,它提供了某些有趣弹性:
- 同一人物类型之不同实体可以有不同的健康计算函数。
- 某已知人物之健康指数计算函数可在运行期变更。
藉由 tr1: function 完成 Strategy 模式
一旦习惯了 templates 以及它们对隐式接口的使用,基于函数指针的做法看起来便过分苛刻而死板了。为什么要求“健康指数之计算”必须是个函数,而不能是某种“像函数的东西”(例如函数对象)呢?如果一定得是函数,为什么不能够是个成员函数?为什么一定得返回 int 而不是任何可被转换为 int 的类型呢?
如果我们不再使用函数指针(如前例的 healtheunc),而是改用一个类型为 tr1::function 的对象,这些约束就全都挥发不见了。就像条款 54 所说,这样的对象可持有(保存)任何可调用物( callable entity,也就是函数指针、函数对象、或成员函数指针),只要其签名式兼容于需求端。以下将刚才的设计改为使用:
1 | tr1::function |
现在我们靠近一点瞧瞧 HealthCalceunc 是个什么样的 typedef std::tr1::function<int (const Gamecharacter&)> 这里我把 tr1::function 具现体( instantiation)的目标签名式( target signature),那个签名代表的函数是“接受一个 reference 指向 const Gamecharacter,并返回 int”。
和前一个设计(其 GameCharacter 持有的是函数指针)比较,这个设计几乎相同。唯一不同的是如今 Gamecharacter 持有一个 tr1::function 对象,相当于个指向函数的泛化指针。这个改变如此细小,我总说它没有什么外显影响,除非客户在“指定健康计算函数”这件事上需要更惊人的弹性:
本条款的根本忠告是,当你为解决问题而寻找某个设计方法时,不妨考虑 virtual 函数的替代方案:
- 使用 non-virtual interface(NVI)手法,那是 Template Method 设计模式的一种特殊形式。它以 public non-virtual 成员函数包裹较低访问性( private 或 protected)的 virtual 函数。
- 将 virtual 函数替换为“函数指针成员变量”,这是 Strategy 设计模式的一种分解表现形式。
- 以 tr1::function 成员变量替换 virtual 函数,因而允许使用任何可调用物( callable entity)搭配一个兼容于需求的签名式。这也是 Strategy 设计模式的某种形式。
- 将继承体系内的 virtual 函数替换为另一个继承体系内的 virtual 函数。这是 Strategy 设计模式的传统实现手法。
条款 36:绝不重新定义继承而来的非虚函数
non-virtual 函数是静态绑定。这意思是,由于 pb 被声明为一个 pointer-to-B,通过 pb 调用的 non-virtual 函数永远是 B 所定义的版本,即使 pb 指向一个类型为“B 派生之 class”的对象。
但另一方面, virtual 函数却是动态绑定。如果 mf 是个 virtual 函数,不论是通过 pB(指向 D)或 pD(指向 D)调用 mf,都会导致调用 D::mf,因为 pB 和 pD 真正指的都是一个类型为 D 的对象。
条款 37:绝不重新定义继承而来的缺省参数值(缺省参数值都是静态绑定而)
这种情况下,本条款成立的理由就非常直接而明确了: virtual 函数系动态绑定( dynamically bound),而缺省参数值却是静态绑定( statically bound)。静态绑定又叫前期绑定,earbinding:动态绑定又名后期绑定, late binding。
1 | //ー个用以描述几何形状的 cass |
这个继承体系图示如下 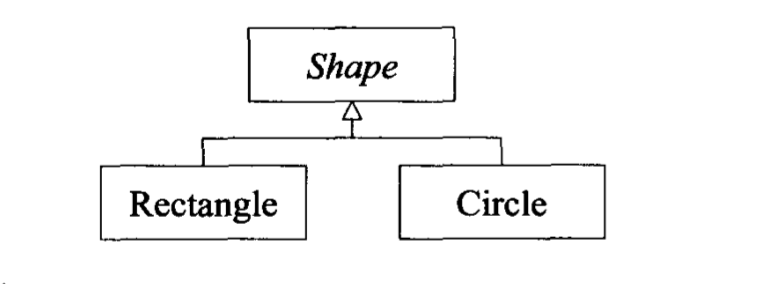
现在考虑这些指针:
1 | Shape* pr =new Rectangle; //静态类型为 Shape* |
此例之中,pr 的动态类型是 Rectangle,所以调用的是 Rectangle 的 virtual 函数,一如你所预期。 Rectangle::draw 函数的缺省参数值应该是 GREN,但由于 pr 的静态类型是 Shape,所以此一调用的缺省参数值来自 shape class 而非 Rectangle class!结局是这个函数调用有着奇怪并且几乎绝对没人预料得到的组合,由 Shape class 和 Rectangle class 的 draw 声明式各出一半力。
请记住
绝对不要重新定义一个继承而来的缺省参数值,因为缺省参数值都是静态绑定而 virtual 函数一你唯一应该覆写的东西一却是动态绑定
条款 38:通过复合表示 has-a 或者“根据某物实现出”的关系
复合( composition)的意义和 public 继承完全不同。 在应用域( application domain),复合意味 has a(有一个)。在实现域( implementation domain),复合意味 is-implemented-in-terms-of(根据某物实现出)。
条款 39:明智而审慎地使用 private 继承
其中 class Student 以 public 形式继承 class Person,于是编译器在必要时刻(为了让函数调用成功)将 Students 暗自转换为 Persons。现在我以 private 继承替换 public 继承:
1 | class Person {...}; |
如果 classes 之间的继承关系是 private,编译器不会自动将一个 derived class 对象(例如 Student)转换为一个 base class 对象(例如 Person)。这和 public 继承的情况不同。这也就是为什么通过 s 调用 eat 会失败的原因。第二条规则是,由 private base class 继承而来的所有成员,在 derived class 中都会变成 private 属性,纵使它们在 base class 中原本是 protected 或 public 属性。
Private 继承意味 implemented-in-terms-of(根据某物实现出), private 继承意味只有实现部分被继承,接口部分应略去。
请记住
- Private 继承意味 is-implemented-in-terms of(根据某物实现出)。它通常比复合( composition)的级别低。但是当 derived class 需要访问 protected base class 的成员,或需要重新定义继承而来的 virtual 函数时,这么设计是合理的。
- 和复合( composition)不同, private 继承可以造成 empty base 最优化。这对致力于“对象尺寸最小化”的程序库开发者而言,可能很重要。
条款 40:明智而审慎地使用多重继承

使用 virtual 继承的那些 classes 所产生的对象往往比使用 non-virtual 继承的兄弟们体积大,访问 virtual base classes 的成员变量时,也比访问 non-virtual base classes 的成员变量速度慢。
virtual 继承的成本还包括其他方面。支配“ virtual base classes 初始化”的规则比起 non-virtual bases 的情况远为复杂且不直观。 virtual base 的初始化责任是由继承体系中的最低层( most derived) class 负责,这暗示:
- classes 若派生自 virtual bases 而需要初始化,必须认知其 virtual bases 一不论那些 bases 距离多远。
- 当一个新的 derived class 加入继承体系中,它必须承担其 virtual bases(不论直接或间接)的初始化责任。
我对 virtual base classes(亦相当于对 virtual 继承)的忠告很简单。第一,非必要不使用ⅵrtual bases。平常请使用 non-virtual 继承。第二,如果你必须使用 virtual base classes,尽可能避免在其中放置数据。这么一来你就不需担心这些 classes 身上的初始化(和赋值)所带来的诡异事情了。
参考文献
《Effective C++》