链接装载与库(三)静态链接
 原图
原图
在这一节里,我们将使用下面这两个源代码文件“a.c”和“b.c”作为例子展开分析:
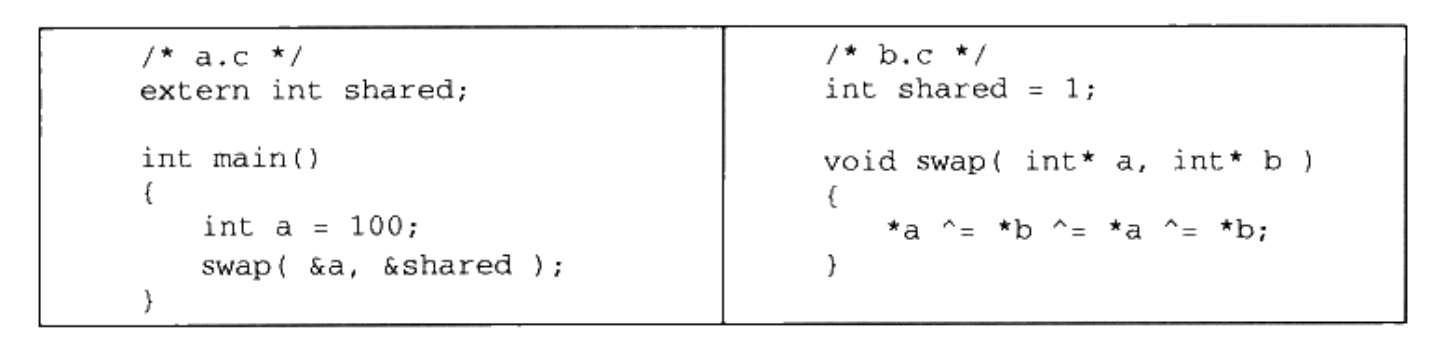
假设我们的程序只有这两个模块“a.c”和“b.c”。首先我们使用 gcc 将“a.c”和“b.c”分别编译成目标文件“a.o”和“b.o”:
1 | gcc -c a.c b.c |
从代码中可以看到,“b.c”总共定义了两个全局符号,一个是变量“shared”,另外一个是函数“swap”;“a.c”里面定义了一个全局符号就是“main”。模块“a.c”里面引用到了“b.c”里面的“swap”和“shared”。我们接下来要做的就是把“a.o”和“b.o”这两个目标文件链接在一起并最终形成一个可执行文件“ab”。
空间与地址分配
对于多个输入目标文件,链接器如何将它们的各个段合并到输出文件?
按序叠加
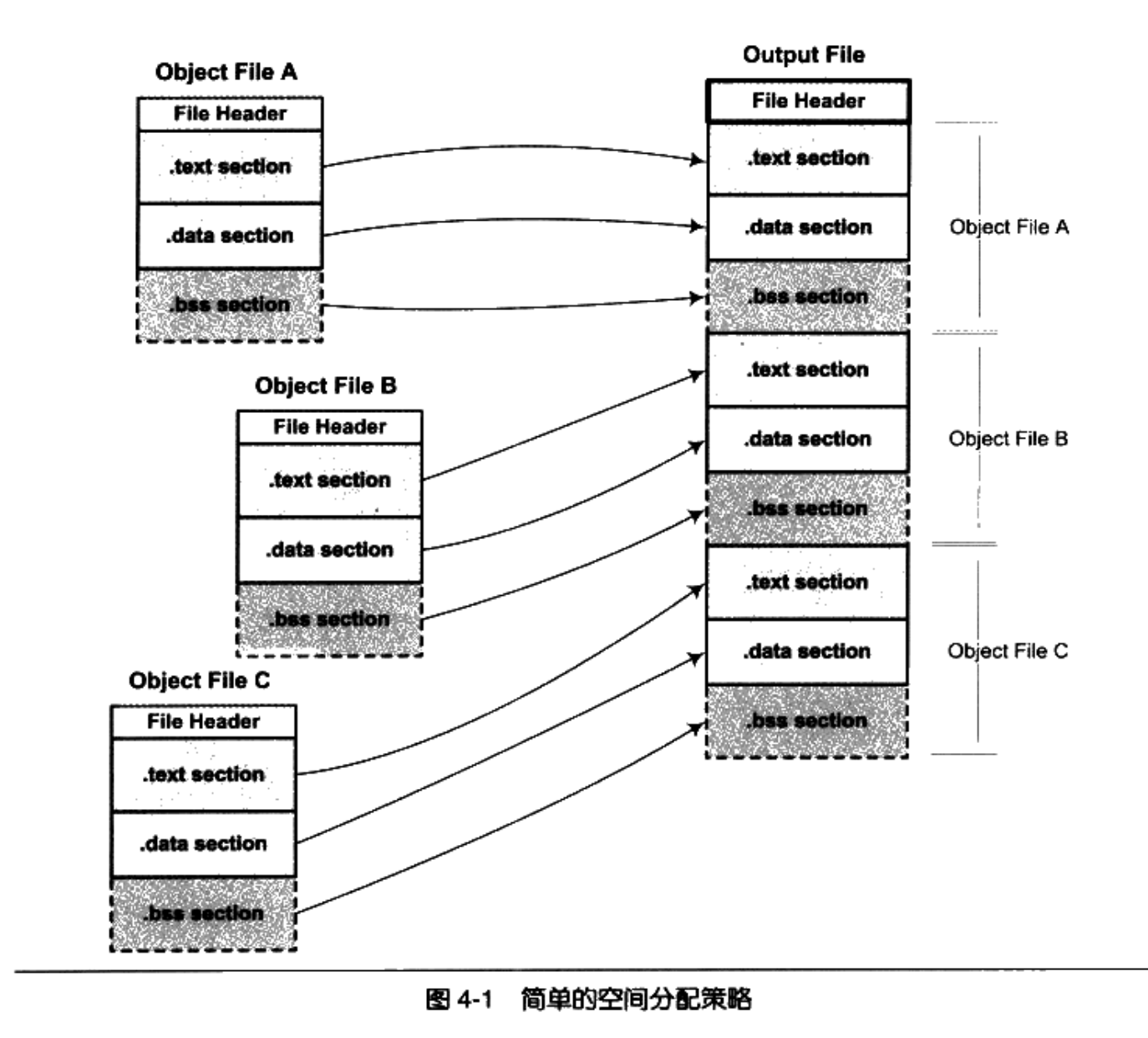 如图 4-1
所示,就是直接将各个目标文件依次合并,但是在有很多输入文件的情况下,输出文件将会有很多零散的段,这种做法非常浪费空间,因为每个段都须要有一定的地址和空间对齐要求。
如图 4-1
所示,就是直接将各个目标文件依次合并,但是在有很多输入文件的情况下,输出文件将会有很多零散的段,这种做法非常浪费空间,因为每个段都须要有一定的地址和空间对齐要求。
相似段合并
一个更实际的方法是将相同性质的段合并到一起,比如将所有输入文件的“.text”合并到输出文件的“.text”段,接着是“.data”段、“.bss”段等,如图
4-2 所示。 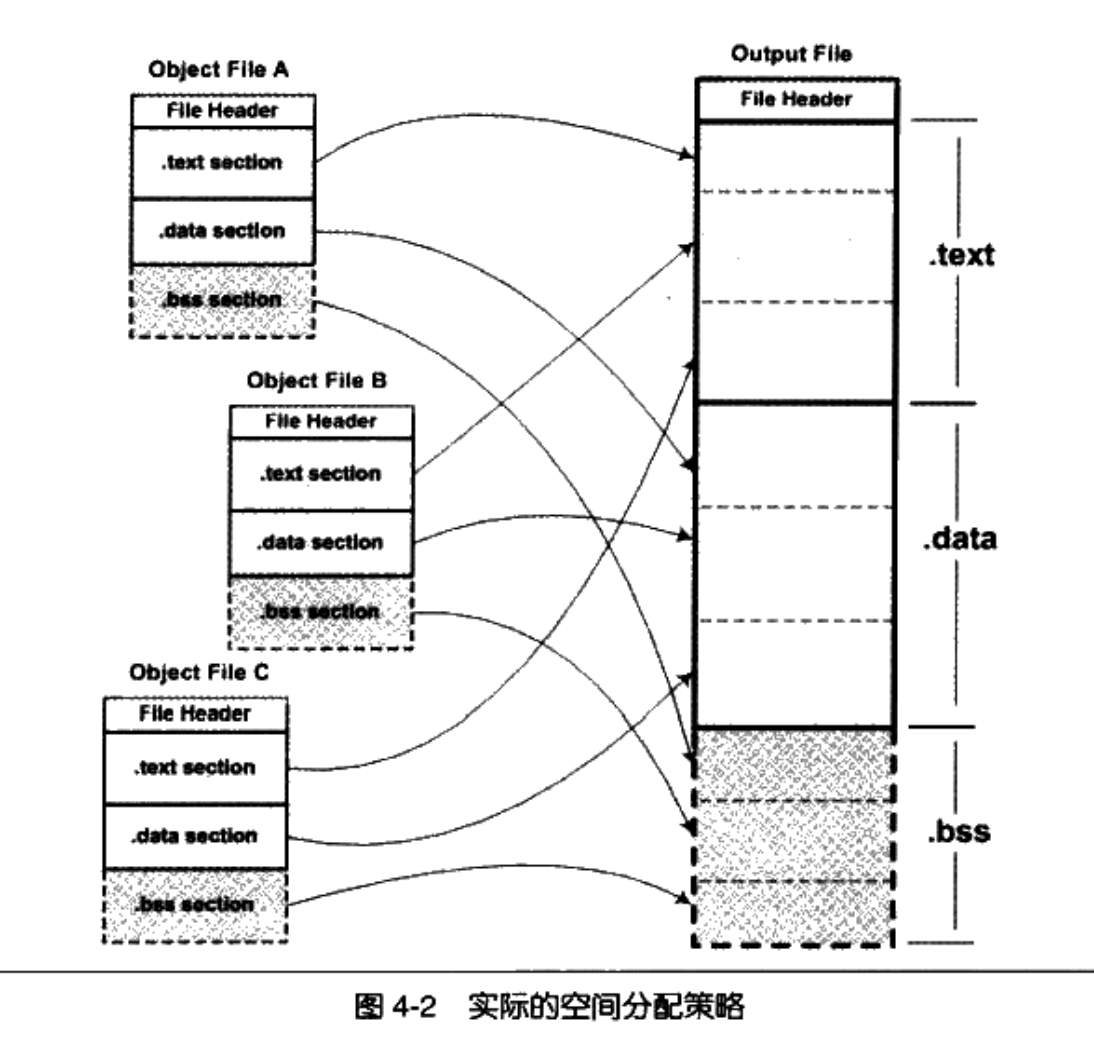
对于有实际数据的段,比如“.text”和“.data”来说,它们在文件中和虚拟地址中都要分配空间,因为它们在这两者中都存在;而对于“.bss”这样的段来说,分配空间的意义只局限于虚拟地址空间,因为它在文件中并没有内容。
使用这种方法的链接器一般都采用一种叫两步链接(Two-pass Linking)的方法,也就是说整个链接过程分两步。
- 第一步空间与地址分配扫描所有的输入目标文件,并且获得它们的各个段的长度、属性和位置,并且将输入目标文件中的符号表中所有的符号定义和符号引用收集起来,统一放到一个全局符号表。
- 第二步符号解析与重定位使用上面第一步中收集到的所有信息,读取输入文件中段的数据、重定位信息,并且进行符号解析与重定位、调整代码中的地址等(核心)。
我们使用 ld 链接器将“a.o”和“b.o”链接起来:
1 | $ld a.o b.o -e main -o ab |
- -e main 表示将 main 函数作为程序入口,ld 链接器默认的程序入口为_start。
- -o ab 表示链接输出文件名为 ab,默认为 a.out。
让我们使用 objdump 来查看链接前后地址的分配情况,代码如清单 4-1
所示。 
VMA 表示 Virtual Memory Address,即虚拟地址,LMA 表示 Load Memory Address,即加载地址。
在链接之前,目标文件中的所有段的 VMA 都是
O,因为虚拟空间还没有被分配,等到链接之后,可执行文件“b”中的各个段都被分配到了相应的虚拟地址。这里的输出程序“ab”中,“.text”段被分配到了地址
0x08048094,大小为 0x72 字节;“.data”段从地址 0x08049108 开始,大小为 4
字节。如下: 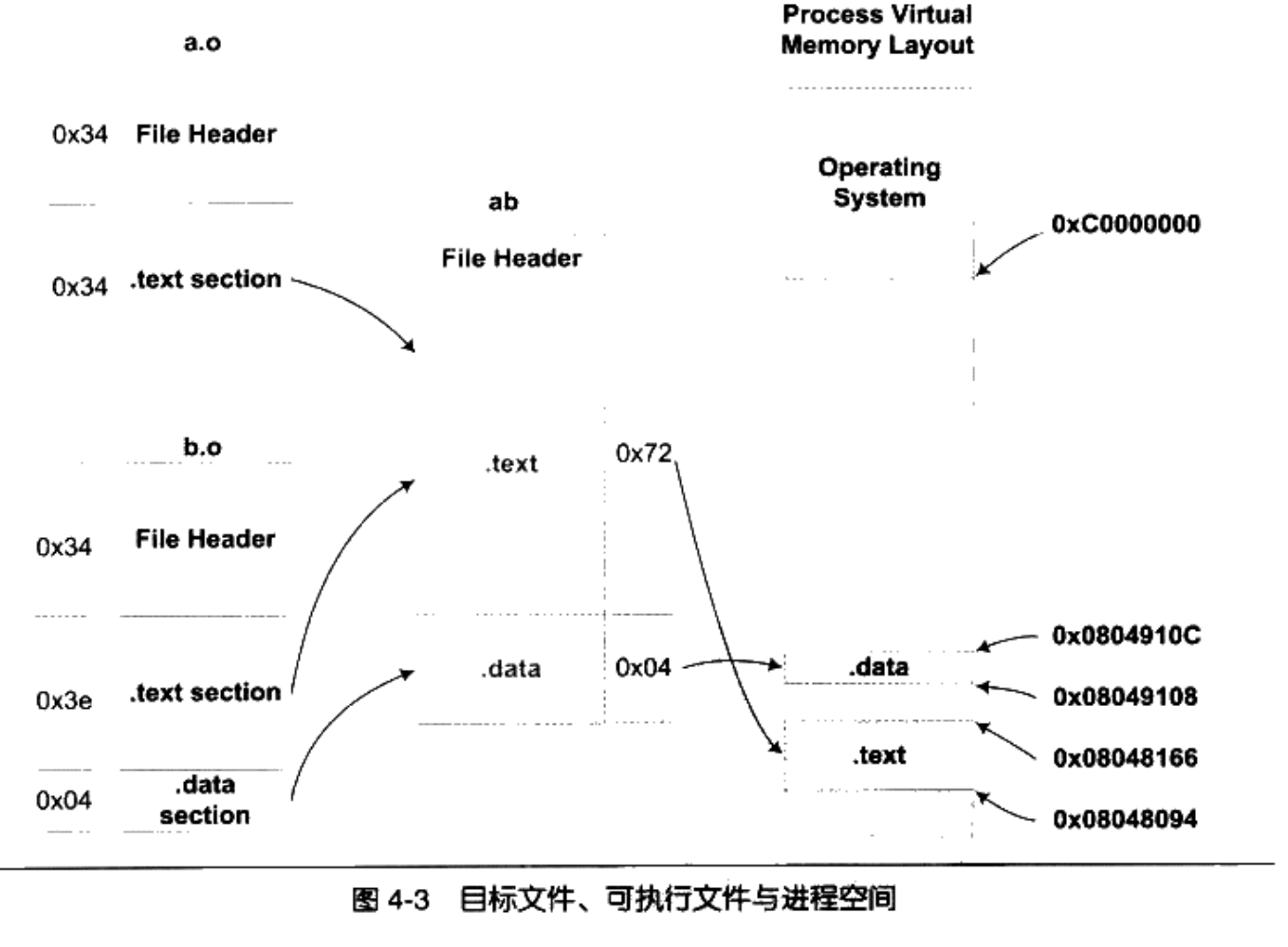
为什么链接器要将可执行文件“ab”的“.text”分配到 0x08048094、将“.data”分配 0x08049108?而不是从虚拟空间的 0 地址开始分配呢?这涉及操作系统的进程虚拟地址空间的分配规则,在 Linux 下,ELF 可执行文件默认从地址 0x08048000 开始分配。
符号地址的确定
因为各个符号在段内的相对位置是固定的,所以这时候其实“main”、“shared”和“swap”的地址也已经是确定的了,只不过链接器须要给每个符号加上一个偏移量,使它们能够调整到正确的虚拟地址。比如我们假设“a.o”中的“main”函数相对于“a.o”的“.text”段的偏移是 X,但是经过链接合并以后,“a.o”的“.text”段位于虚拟地址 0x08048094,那么“main”的地址应该是 0x08048094+X。
符号解析与重定位
重定位
使用 objdump 的“-d”参数可以看到“a.o”的代码段反汇编结果: 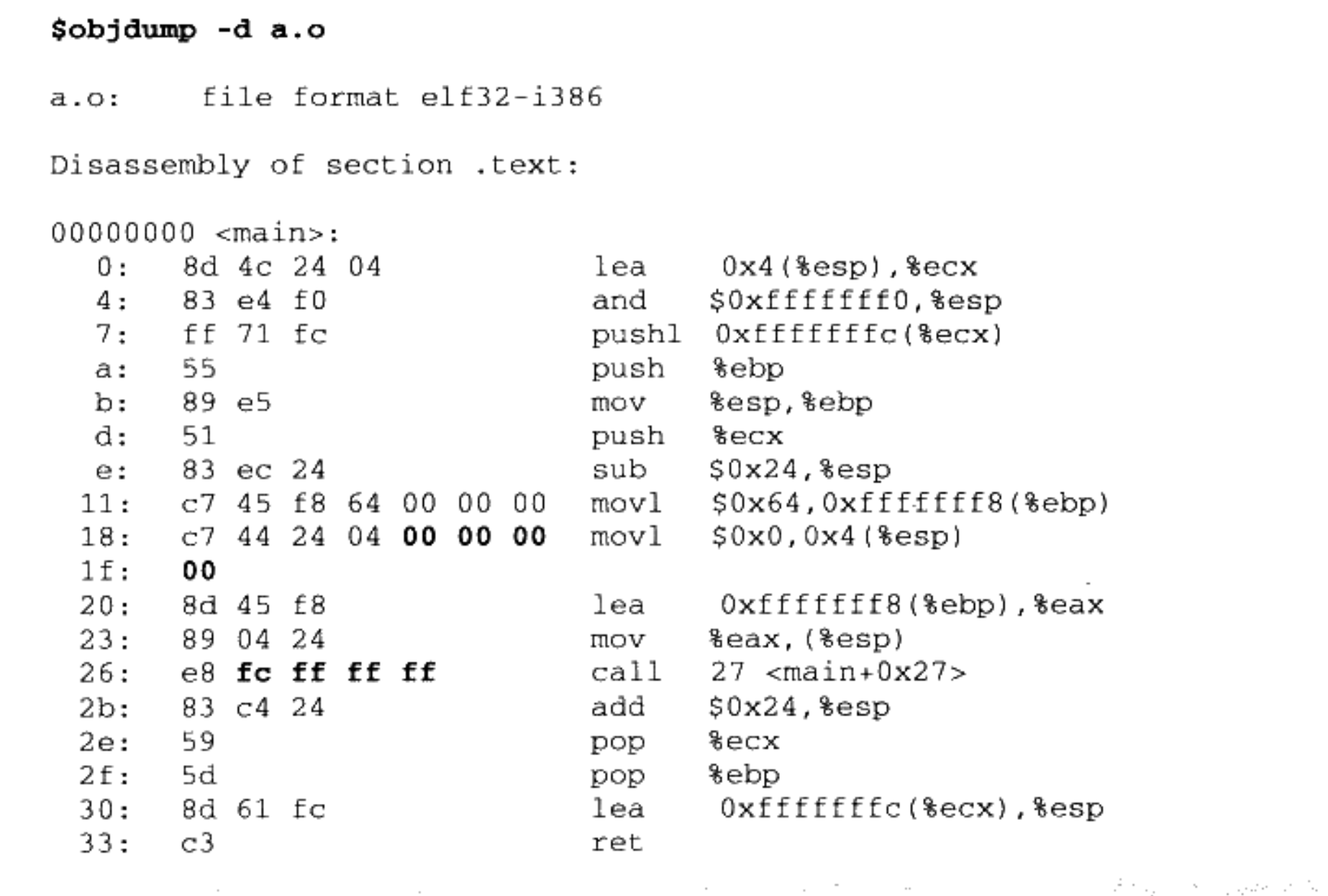
我们知道在程序的代码里面使用的都是虚拟地址,在这里也可以看到“main”的起始地址为 0×00000000,这是因为在未进行前面提到过的空间分配之前,目标文件代码段中的起始地址以 0x00000000 开始,等到空间分配完成以后,各个函数才会确定自己在虚拟地址空间中的位置。
我们可以很清楚地看到“a.o”的反汇编结果中,“a.o”共定义了一个函数
main。最左边那列是每条指令的偏移量,每一行代表一条指令,我们已经用粗体标出了两个引用“shared”和“swap”的位置,对于“shared”的引用是一条“mov”指令,这条指令总共
8 个字节,它的作用是将“shared”的地址赋值到 ESP 寄存器+4
的偏移地址中去,前面 4 个字节是指令码,后面 4
个字节是“shared”的地址,我们只关心后面的 4 个字节部分,如图 4-4 所示。
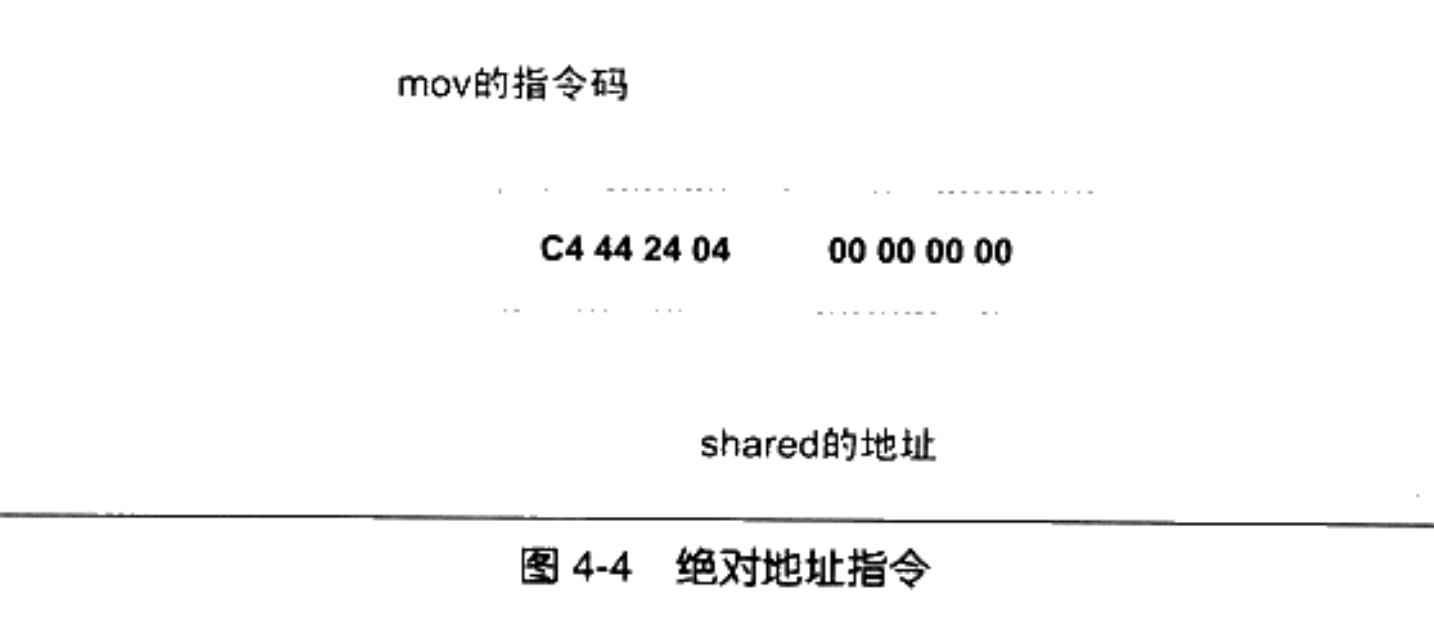
当源代码“a.c”在被编译成目标文件时,编译器并不知道“shared”和“swap”的地址。所以编译器就暂时把地址 O 看作是“shared”的地址,我们可以看到这条“mov”指令中,关于“shared”的地址部分为“0x00000000”。
另外一个是偏移为 0x26 的指令的一条调用指令,它其实就表示对 swap
函数的调用,如图 4-5 所示。 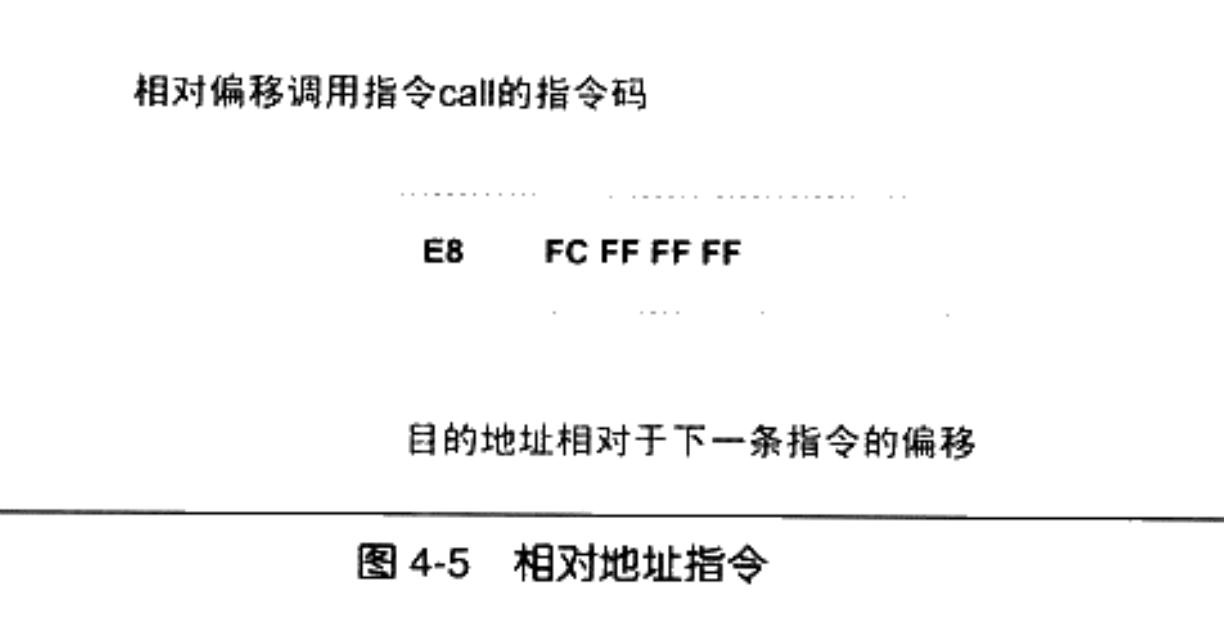
这条指令共 5 个字节,前面的 0xE8 是操作码(Operation Code),这条指令是一条近址相对位移调用指令,后面 4 个字节就是被调用函数的相对于调用指令的下一条指令的偏移量。在没有重定位之前,相对偏移被置为 0xFFFFFFFC(小端),它是常量“-4”的补码形式。
编译器把这两条指令的地址部分暂时用地址“0x00000000”和“0xFFFFFFFC”代替着,把真正的地址计算工作留给了链接器。我们用
objdump 来反汇编输出程序“ab”的代码段,可以看到 main
函数的两个重定位入口都已经被修正到止确的位置: 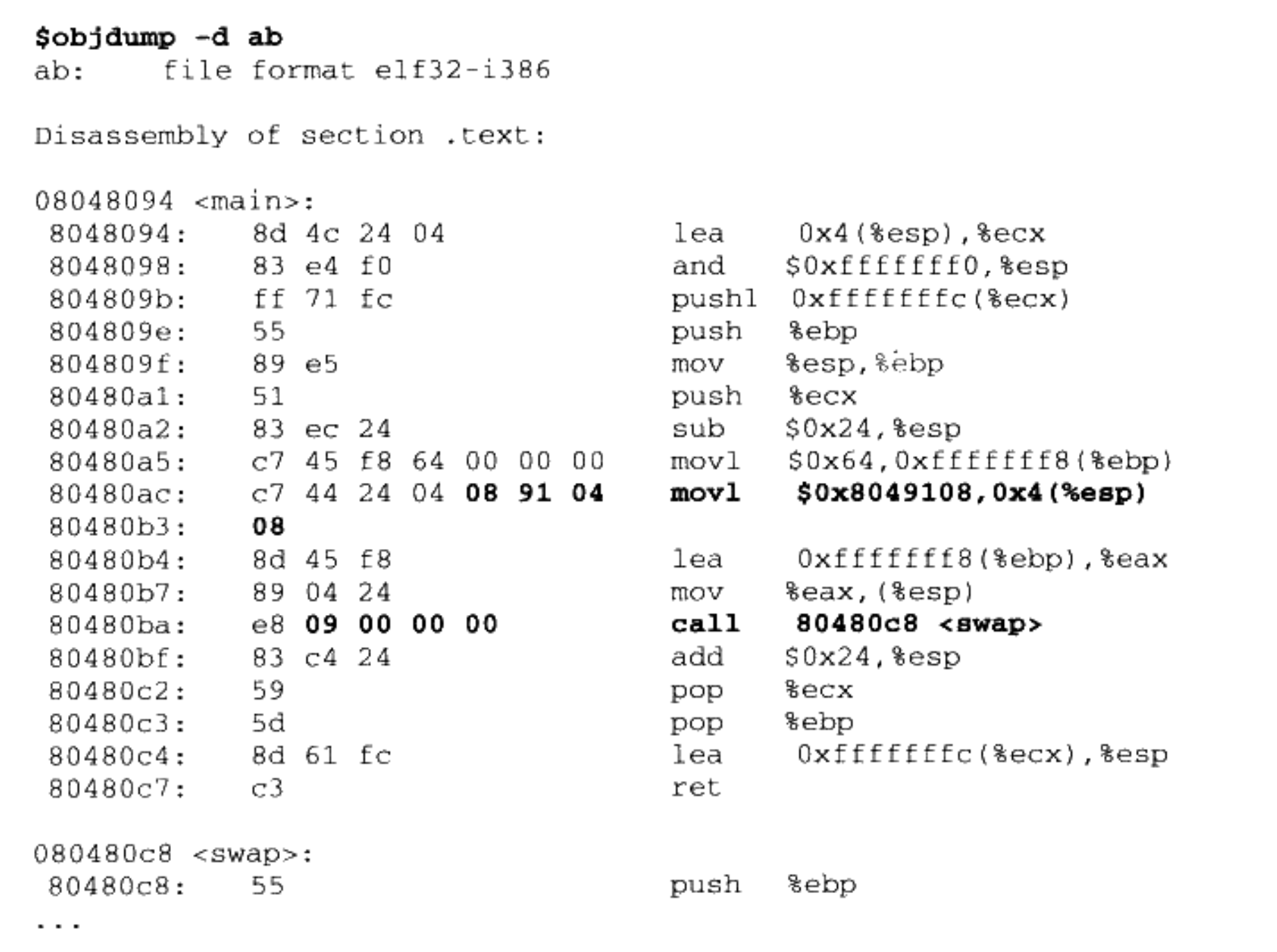
经过修正以后,“shared”和“swap”的地址分别为 0x08049108 和 0x00000009(小端字节序)。关于“shared”很好理解,因为“shared”变量的地址的确是 0x08049108。对于“swap”来说稍显晦涩。“call”指令的下一条指令是“add”,它的地址是 0x080480bf,所以“相对于 add 指令偏移量为 0x00000009”的地址为 0x080480bf+9=0x080480c8,即刚好是“swap”函数的地址。
绝对寻址修正和相对寻址修正的区别就是绝对寻址修正后的地址为该符号的实际地址;相对寻址修正后的地址为符号距离被修正位置的地址差。
重定位表
那么链接器是怎么知道哪些指令是要被调整的呢?怎么调整?事实上在 ELF 文件中,有一个叫重定位表的结构专门用来保存这些与重定位相关的信息,它在 ELF 文件中往往是一个或多个段。
我们可以使用 objdump 来查看目标文件的重定位表: 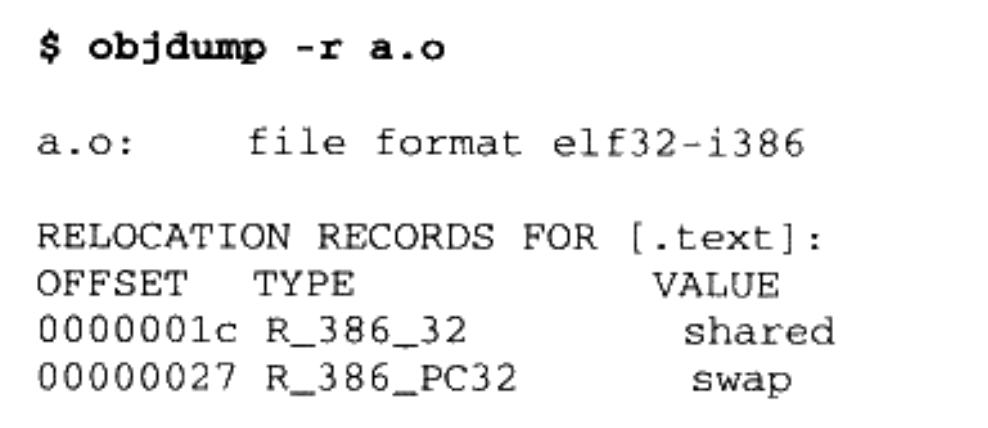
每个要被重定位的地方叫一个重定位入口(Relocation Entry),我们可以看到“a.o”里面有两个重定位入口。重定位入口的偏移(Offset)表示该入口在要被重定位的段中的位置,“RELOCATION RECORDS FOR[.text]”表示这个重定位表是代码段的重定位表,所以偏移表示代码段中须要被调整的位置。
符号解析
其实重定位过程也伴随着符号的解析过程。重定位的过程中,每个重定位的入口都是对一个符号的引用,那么当链接器须要对某个符号的引用进行重定位时,它就要确定这个符号的目标地址。这时候链接器就会去查找由所有输入目标文件的符号表组成的全局符号表,找到相应的符号后进行重定位。比如我们查看“a.o”的符号表:
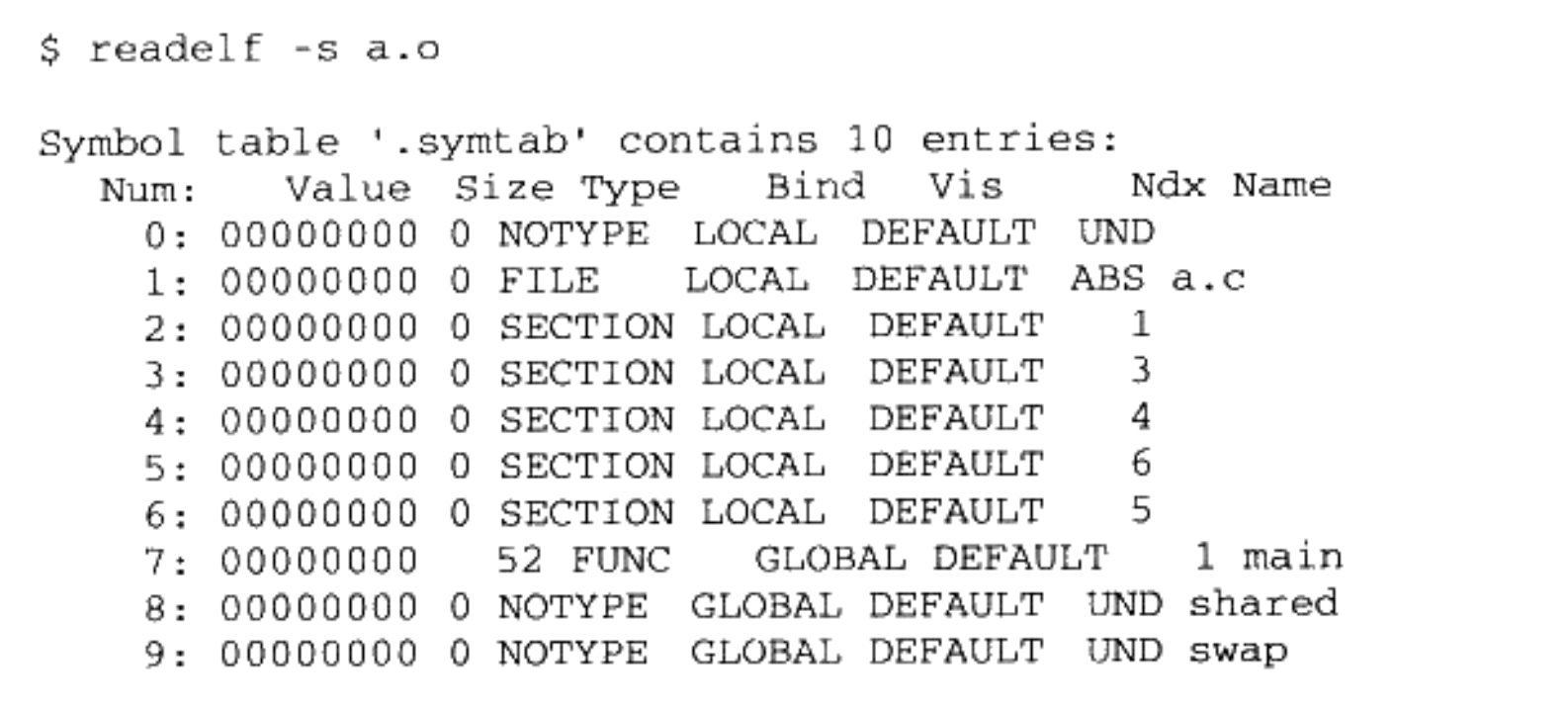
“GLOBAL”类型的符号,除了“main”函数是定义在代码段之外,其他两个“shared”和“swap”都是“UND”,所有这些未定义的符号都应该能够在全局符号表中找到,否则链接器就报符号未定义错误。
COMMON 块
目前的链接器本身并不支持符号的类型,即变量类型对于链接器来说是透明的,它只知道一个符号的名字,并不知道类型是否一致。那么当我们定义的多个符号定义类型不一致时,链接器该如何处理呢?主要分三种情况:
- 两个或两个以上强符号类型不一致,链接器会报符号多重定义错误。
- 有一个强符号,其他都是弱符号,出现类型不一致,最终输出结果中的符号所占空间与强符号相同。
- 两个或两个以上弱符号类型不一致,以占空间大的为准。
事实上,现在的编译器和链接器都支持一种叫 COMMON 块(Common Block)的机制,当不同的目标文件需要的 COMMON 块空间大小不一致时,以最大的那块为准。
现在我们再回头总结性地思考关于未初始化的全局变量的问题:在目标文件中,编译器为什么不直接把未初始化的全局变量也当作未初始化的局部静态变量一样处理,为它在 BSS 段分配空间,而是将其标记为一个 COMMON 类型的变量?
当编译器将一个编译单元编译成目标文件的时候,如果该编译单元包含了弱符号(未初始化的全局变量就是典型的弱符号),那么该弱符号最终所占空间的大小在此时是未知的,因为有可能其他编译单元中该符号所占的空间比本编译单元该符号所占的空间要大。所以编译器此时无法为该弱符号在 BSS 段分配空间,因为所须要空间的大小未知。但是链接器在链接过程中可以确定弱符号的大小,所以它可以在最终输出文件的 BSS 段为其分配空间。所以总体来看,未初始化全局变量最终还是被放在 BSS 段的。
C++相关问题
C++的一些语言特性使之必须由编译器和链接器共同支持才能完成工作。最主要的有两个方面,一个是 C++的重复代码消除,还有一个就是全局构造与析构。
重复代码消除
C++编译器在很多时候会产生重复的代码,比如模板(Templates)、外部内联函数(Extern Inline Function)和虚函数表(Virtual Function Table)都有可能在不同的编译单元里生成相同的代码。
一个比较有效的做法就是将每个模板的实例代码都单独地存放在一个段里,每个段只包含一个模板实例。比如有个模板函数是“add
函数级别链接 VISUAL C++编译器提供了一个编译选项叫函数级别链接(Functional-Level Linking),这个选项的作用就是让所有的函数都像前面模板函数一样,单独保存到一个段里面。当链接器须要用到某个函数时,它就将它合并到输出文件中,对于那些没有用的函数则将它们抛弃。这种做法可以很大程度上减小输出文件的长度,减少空间浪费。但是会增加编译时间。
GCC 编译器也提供了类似的机制,它有两个选择分别是“-ffunction-sections”和“-fdata-sections”,这两个选项的作用就是将每个函数或变量分别保持到独立的段中。
全局构造与析构
Linux 系统下一般程序的入口是“_start'”,这个函数是 Linux 系统库(Glibc)的一部分。当我们的程序与 Glibc 库链接在一起形成最终可执行文件以后,这个函数就是程序的初始化部分的入口,程序初始化部分完成一系列初始化过程之后,会调用 main 函数来执行程序的主体。在 main 函数执行完成以后,返回到初始化部分,它进行一些清理工作,然后结束进程。对于有些场合,程序的一些特定的操作必须在 main 函数之前被执行,还有一些操作必须在 main 函数之后被执行,其中很具有代表性的就是 C++的全局对象的构造和析构函数,因此 ELF 文件还定义了两种特殊的段。
- .init 该段里面保存的是可执行指令,它构成了进程的初始化代码。因此,当一个程序开始运行时,在 main 函数被调用之前,Glibc 的初始化部分安排执行这个段的中的代码。
- .fini 该段保存着进程终止代码指令。因此,当-个程序的 main 函数正常退出时,Glibc 会安排执行这个段中的代码。
利用这两个特性,C++的全局构造和析构函数就由此实现。
静态库链接
其实一个静态库可以简单地看成一组目标文件的集合,即很多目标文件经过压缩打包后形成的一个文件。通常人们使用“ar”压缩程序将这些目标文件压缩到一起,并且对其进行编号和索引,以便于查找和检索,就形成了 libc.a 这个静态库文件。我们也可以使用“ar”工具来查看这个文件包含了哪些目标文件:
1 | $ ar -t libc.a |
使用“objdump”或“readelf'”加上文本查找工具如“grep”,使用“objdump”查看 libc.a 的符号可以发现如下结果:
1 | $ objdump -t libc.a |
可以看到“printf”函数被定义在了“printf.o”这个目标文件中。这里我们似乎找到了最终的机制,那就是“Hello
World”程序编译出来的目标文件只要和 libc.a
里面的“printf.o。链接在一起,最后就可以形成一个可用的可执行文件了,printf.o
会依赖其他。o 文件例如 vfprintf.o、stdio.o
等,继续链接其他文件,最终得到如图 4-6 所示。 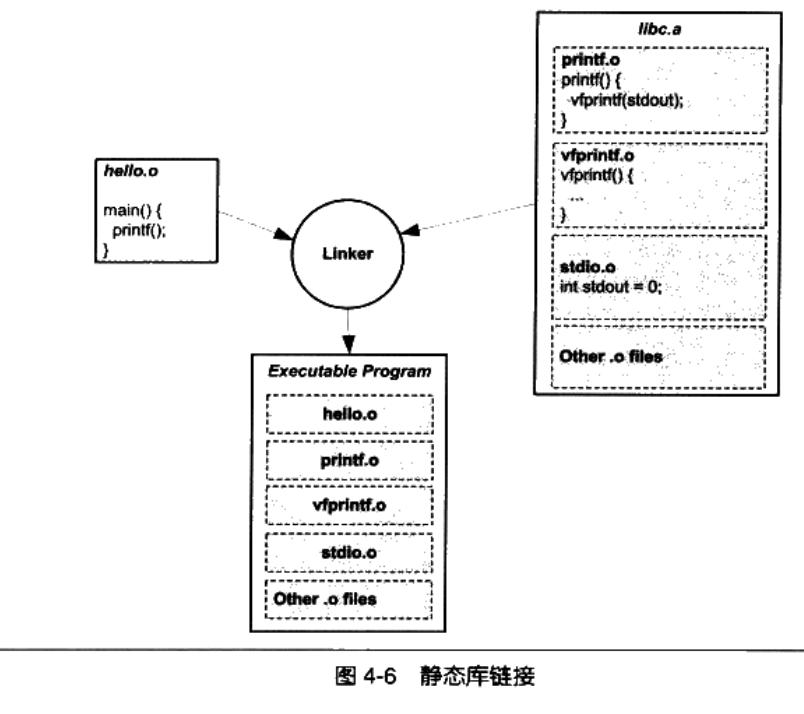
现在 Linux 系统上的库比我们想象的要复杂。当我们编译和链接一个普通 C 程序的时候,不仅要用到 C 语言库 libc.a,而且还有其他一些辅助性质的目标文件和库。我们可以使用下面的 GCC 命令编译“hello.c”,“-verbose”表示将整个编译链接过程的中间步骤打印出来:
1 | vooxle@liushuai:~$ gcc -static --verbose -fno-builtin Simplesection.c |
- 第一步是调用 cc1 程序,这个程序实际上就是 GCC 的 C 语言编译器,它将“hello.c”编译成一个临时的汇编文件“/tmp/ccUhtGSB.s”。
- 然后调用 as 程序,as 程序是 GNU 的汇编器,它将“/tmp/ccUhtGSB.s”汇编成临时目标文件“/tmp/cCQZRPL5.o”,这个“/tmp/cCQZRPL5.o”实际上就是前面的“hello.o”。
- 接着最关键的步骤是最后一步,GCC 调用 collect2 程序来完成最后的链接。
实际上 collect2 可以看作是 ld 链接器的一个包装,它会调用 ld 链接器来完成对目标文件的链接,然后再对链接结果进行一些处理,主要是收集所有与程序初始化相关的信息并且构造初始化的结构。可以看到最后一步中,至少有下列几个库和目标文件被链接入了最终可执行文件:
1 | crt1.o |
链接过程控制
链接器一般都提供多种控制整个链接过程的方法,以用来产生用户所须要的文件。一般链接器有如下三种方法。
- 使用命令行来给链接器指定参数,我们前面所使用的 ld 的-o、-e 参数就属于这类。
- 将链接指令存放在目标文件里面,编译器经常会通过这种方法向链接器传递指令。比如 VISUAL C++编译器会把链接参数放在 PE 目标文件的。drectve 段以用来传递参数。
- 使用链接控制脚本,是最为灵活、最为强大的链接控制方法。
前面我们在使用 ld 链接器的时候,没有指定链接脚本,其实 ld 在用户没有指定链接脚本的时候会使用默认链接脚本。我们可以使用下面的命令行来查看 ld 默认的链接脚本:
1 | ld --verbose |
默认的 ld 链接脚本存放在/usr/lib/ldscripts/下,不同的机器平台、输出文件格式都有相应的链接脚本。我们可以自己写一个脚本,然后指定该脚本为链接控制脚本。比如可以使用-T 参数:
1 | ld -T link.script |
参考文献
《程序员的自我修养》