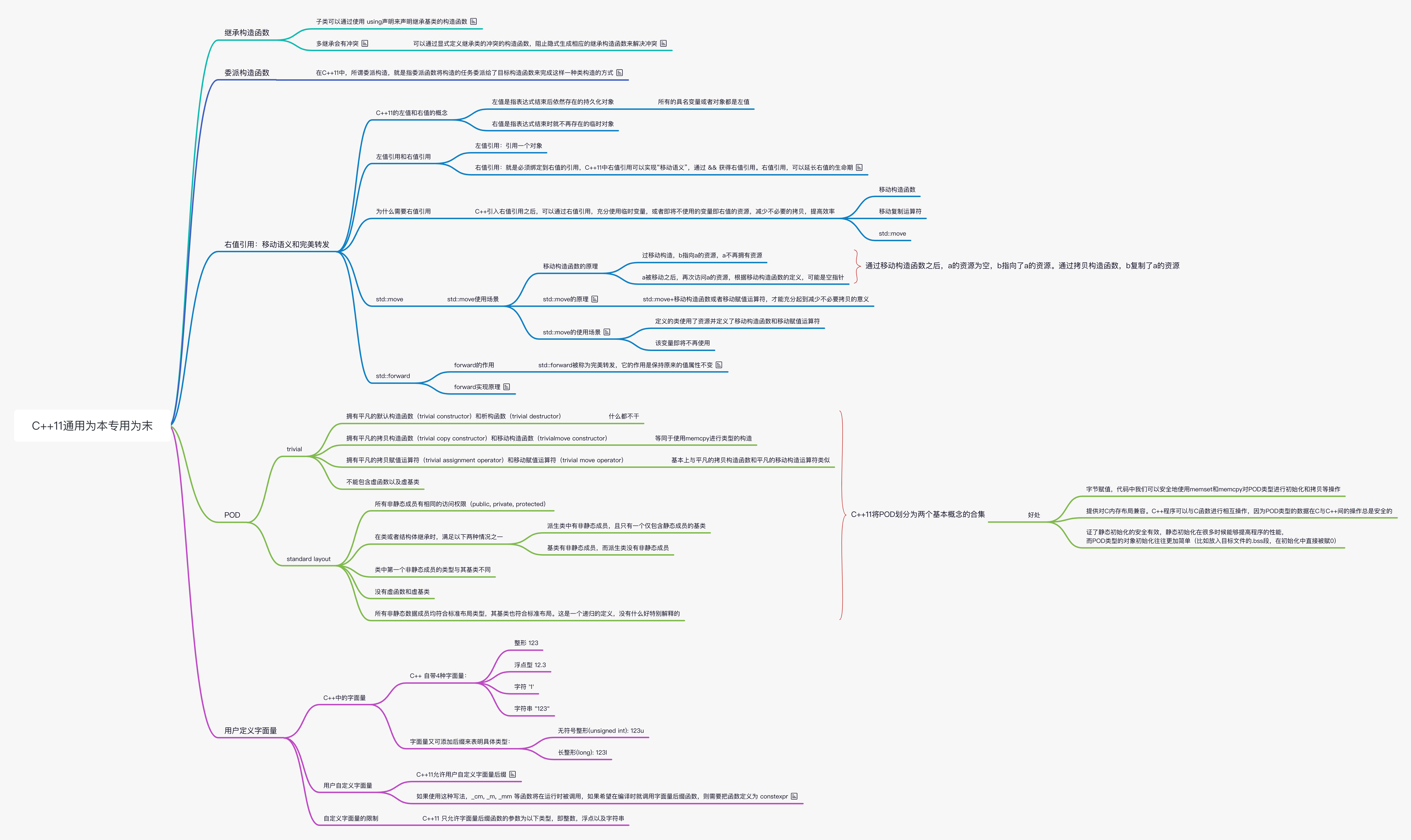
C++11(二)右值引用与 POD
 原图
原图
继承构造函数
1 | struct A |
继承于 A 的派生类 B 实际上只是添加了一个接口 Extralnterface,那么如果我们在构造 B 的时候想要拥有 A 这样多的构造方法的话,就必须一“透传”各个接口。这无疑是相当不方便的。事实上,在 C++中已经有了一个好用的规则,子类可以通过使用 using 声明来声明继承基类的构造函数。
1 | struct A |
而有的时候,我们还会遇到继承构造函数“冲突”的情况。这通常发生在派生类拥有多个基类的时候。多个基类中的部分构造函数可能导致派生类中的继承构造函数的函数名、参数(有的时候,我们也称其为函数签名)都相同,那么继承类中的冲突的继承构造函数将导致不合法的派生类代码。
1 | struct A {A(int){}}; |
A 和 B 的构造函数会导致 C 中重复定义相同类型的继承构造函数。这种情况下,可以通过显式定义继承类的冲突的构造函数,阻止隐式生成相应的继承构造函数来解决冲突。比如:
1 | struct C: A, B { |
其中的构造函数 C(int) 就很好地解决了继承构造函数的冲突问题。
委派构造函数
与继承构造函数类似的,委派构造函数也是 C++11 中对 C++的构造函数的一项改进其目的也是为了减少程序员书写构造函数的时间。通过委派其他构造函数,多构造函数的类编写将更加容易。
1 | class Info { |
在上述代码中,我们声明了一个 Info 的自定义类型。该类型拥有 2 个成员变量以及 3 个构造函数。这里的 3 个构造函数都声明了初始化列表来初始化成员 type 和 name,并且都调用了相同的函数 Initrest。可以看到,除了初始化列表有的不同,而其他的部分,3 个构造函数基本上是相似的,因此其代码存在着很多重复。
在 C++11 中,我们可以使用委派构造函数来达到期望的效果。更具体的,C++11 中的委派构造函数是在构造函数的初始化列表位置进行构造的、委派的。我们可以看看
1 | class Info { |
可以看到,在上述代码中,我们在 Info(int)和 Info(char)的初始化列表的位置,调用了“基准版本”的构造函数 Info。这里我们为了区分被调用者和调用者,称在初始化列表中调用“基准版本”的构造函数为委派构造函数( delegating constructor),而被调用的基准版本”则为目标构造函数( target constructor)。在 C++11 中,所谓委派构造,就是指委派函数将构造的任务委派给了目标构造函数来完成这样一种类构造的方式。
右值引用:移动语义和完美转发
C++11 的左值和右值的概念
在 c++中,一个值要么是右值,要么是左值,左值是指表达式结束后依然存在的持久化对象,右值是指表达式结束时就不再存在的临时对象。所有的具名变量或者对象都是左值,而右值不具名。
1 | int lvalue = 1; // lvalue 为左值, 1 为右值 |
左值引用和右值引用
- 左值引用:引用一个对象
- 右值引用:就是必须绑定到右值的引用,C++11 中右值引用可以实现“移动语义”,通过 && 获得右值引用。右值引用,可以延长右值的生命期,比如:
1 | int&& i = 123; |
可以通过下面的代码,更深入的体会左值引用和右值引用的区别:
1 | int i; |
为什么需要右值引用
C++引入右值引用之后,可以通过右值引用,充分使用临时变量,或者即将不使用的变量即右值的资源,减少不必要的拷贝,提高效率。如下代码,均会产生临时变量:
1 | class RValue { |
为了充分利用右值的资源,减少不必要的拷贝,C++11 引入了右值引用 (&&),移动构造函数,移动复制运算符以及 std::move。
std::move
右值引用 (&&),移动构造函数,移动复制运算符以及 std::move
1 |
|
不过,当运行的时候却发现没有任何输出
1 | g++ move.cpp -std=c++11 -o move |
这是因为,编译器做了优化,编译的时候加上-fno-elide-constructors,去掉优化
1 | g++ move.cpp -std=c++11 -fno-elide-constructors -o move |
通过上面的代码,可以看出,在没有加-fno-elide-constructors 选项时,编译器做了优化,没有临时变量的生成。在加了-fno-elide-constructors 选项时,get 产生了两次临时变量,put 生成了一次临时变量。
将 get 函数稍微修改一下:
1 | RValue get() { |
只是简单的修改了一下,std::move(a),在编译器做了优化的情况下,用了 std::move,反而多做了一次拷贝。
其实,RValue 如果在没有定义移动构造函数,重复上面的操作,生成临时变量的次数还是一样的,只不过,调用的时拷贝构造函数了而已。
通过 get 函数可以知道,乱用 std::move 在编译器开启构造函数优化的场景下反而增加了不必要的拷贝。那么,std::move 应该在什么场景下使用?
std::move 使用场景
移动构造函数的原理
通过移动构造,b 指向 a 的资源,a 不再拥有资源,这里的资源,可以是动态申请的内存,网络链接,打开的文件,也可以是本例中的 string。这时候访问 a 的行为时未定义的,比如,如果资源是动态内存,a 被移动之后,再次访问 a 的资源,根据移动构造函数的定义,可能是空指针,如果是资源上文的 string,移动之后,a 的资源为空字符串(string 被移动之后,为空字符串)。 可以通过下面代码验证,修改 main 函数:
1 | int main() { |
通过移动构造函数之后,a 的资源为空,b 指向了 a 的资源。通过拷贝构造函数,b 复制了 a 的资源。
std::move 的原理
std::move 的定义:
1 |
|
这里,T&&是通用引用,需要注意和右值引用(比如 int&&)区分。通过 move 定义可以看出,move 并没有”移动“什么内容,只是将传入的值转换为右值,此外没有其他动作。std::move+移动构造函数或者移动赋值运算符,才能充分起到减少不必要拷贝的意义。
std::move 的使用场景
在之前的项目中看到有的同事到处使用 std::move,好像觉得使用了 std::move 就能移动资源,提升性能一样,在我看来,std::move 主要使用在以下场景:
- 使用前提:
- 定义的类使用了资源并定义了移动构造函数和移动赋值运算符
- 该变量即将不再使用
- 使用场景
1 | RValue a, b; |
- 在没有右值引用之前,为了使用临时变量,通常定义 const 的左值引用,比如 const string&,在有了右值引用之后,为了使用右值语义,不要把参数定义为常量左值引用,否则,传递右值时调用的是拷贝构造函数。
1 | void put(const RValue& c){ |
不使用左值常量引用:
1 | void put(RValue c){ |
这是因为,根据通用引用的定义,std::move(c) 过程中,模板参数被推倒为 const RValue&,因此,调用拷贝构造函数。
总结
通过简绍右值和右值引用以及 std::move 和移动构造函数,总结右值引用,移动构造函数和移动赋值运算符和 std::move 的用法和注意事项。
std::forward
forward 的作用
std::forward 被称为完美转发,它的作用是保持原来的值属性不变。啥意思呢?通俗的讲就是,如果原来的值是左值,经 std::forward 处理后该值还是左值;如果原来的值是右值,经 std::forward 处理后它还是右值。
看看下面的例子,你应该就清楚上面这句话的含义了:
1 |
|
上面代码执行结果如下:
1 | 左值 |
从上面第一组的结果我们可以看到,传入的 1 虽然是右值,但经过函数传参之后它变成了左值(在内存中分配了空间);而第二行由于使用了 std::forward 函数,所以不会改变它的右值属性,因此会调用参数为右值引用的 print 模板函数;第三行,因为 std::move 会将传入的参数强制转成右值,所以结果一定是右值。
再来看看第二组结果。因为 x 变量是左值,所以第一行一定是左值;第二行使用 forward 处理,它依然会让其保持左值,所以第二也是左值;最后一行使用 move 函数,因此一定是右值。
通过上面的例子我想你应该已经清楚 forward 的作用是什么了吧?
forward 实现原理
要分析 forward 实现原理,我们首先来看一下 forward 代码实现。由于我们之前已经有了分析 std::move 的基础,所以再来看 forward 代码应该不会太困难。
1 | template <typename T> |
forward 实现了两个模板函数,一个接收左值,另一个接收右值。
POD
POD 是英文中 Plain Old Data 的缩写。POD 在 C++中是非常重要的一个概念,通常用于说明一个类型的属性,尤其是用户自定义类型的属性。具体地,C++11 将 POD 划分为两个基本概念的合集,即:平凡的(trivial)和标准布局的(standard layout)。
trivial
我们先来看一下平凡的定义。通常情况下,一个平凡的类或结构体应该符合以下定义:
- 拥有平凡的默认构造函数(trivial constructor)和析构函数(trivial destructor)。平凡的默认构造函数就是说构造函数“什么都不干”。使用=default 关键字来显式地声明缺省版本的构造函数,使得类型恢复“平凡化”。
- 拥有平凡的拷贝构造函数(trivial copy constructor)和移动构造函数(trivialmove constructor)。平凡的拷贝构造函数基本上等同于使用 memcpy 进行类型的构造。同平凡的默认构造函数一样,不声明拷贝构造函数的。话,编译器会帮程序员自动地生成。同样地,可以显式地使用=default 声明默认拷贝构造函数。
- 拥有平凡的拷贝赋值运算符(trivial assignment operator)和移动赋值运算符(trivial move operator)。这基本上与平凡的拷贝构造函数和平凡的移动构造运算符类似。
- 不能包含虚函数以及虚基类
standard layout
标准布局的类或结构体应该符合以下定义:
- 所有非静态成员有相同的访问权限(public, private, protected)
- 在类或者结构体继承时,满足以下两种情况之一:
- 派生类中有非静态成员,且只有一个仅包含静态成员的基类
- 基类有非静态成员,而派生类没有非静态成员
- 类中第一个非静态成员的类型与其基类不同
- 没有虚函数和虚基类
- 所有非静态数据成员均符合标准布局类型,其基类也符合标准布局。这是一个递归的定义,没有什么好特别解释的
POD
对于 POD 而言,在 C++11
中的定义就是平凡的和标准布局的两个方面。同样地,要判定某一类型是否是
POD,标准库中的
1 | /// is_pod |
使用 POD 我们看得到的大概有如下 3 点:
- 字节赋值,代码中我们可以安全地使用 memset 和 memcpy 对 POD 类型进行初始化和拷贝等操作。
- 提供对 C 内存布局兼容。C++程序可以与 C 函数进行相互操作,因为 POD 类型的数据在 C 与 C++间的操作总是安全的。
- 保证了静态初始化的安全有效。静态初始化在很多时候能够提高程序的性能,而 POD 类型的对象初始化往往更加简单(比如放入目标文件的。bss 段,在初始化中直接被赋 0)。
用户定义字面量
C++中的字面量
C++ 自带 4 种字面量:
- 整形 123
- 浮点型 12.3
- 字符 '1'
- 字符串 "123"
字面量又可添加后缀来表明具体类型:
- 无符号整形 (unsigned int): 123u
- 长整形 (long): 123l
在 C++03 中,我们可以定义一个浮点数 height
1 | double height = 3.4; |
那么,痛点来了,此处的 height 的单位是什么呢?米?厘米?又或是英尺?在面对此类问题时,如果我们能编写如下代码,事情就会简单许多:
1 | height = 3cm; |
用户自定义字面量
C++11 允许用户自定义字面量后缀
1 | long double |
如果使用这种写法,_cm, _m, _mm 等函数将在运行时被调用,如果希望在编译时就调用字面量后缀函数,则需要把函数定义为 constexpr,例如
1 | constexpr long double |
更进一步,我们甚至可以
1 | // 注意,如果这里要定义函数为 constexpr |
自定义字面量的限制
C++11 只允许字面量后缀函数的参数为以下类型,即整数,浮点以及字符串:
- unsigned long long
- long double
- char const*
- char const*, std::size_t
- wchar_t const*, std::size_t
- char16_t const*, std::size_t
- char32_t const*, std::size_t
返回值则无类型限制
参考文献
https://zhuanlan.zhihu.com/p/94588204
https://www.jianshu.com/p/97fdd852974f
https://zhuanlan.zhihu.com/p/111369693
《深入理解 C++11:C++11 新特性解析与应用》