C++11(五)constexpr、原子与线程存储
 原图
原图
常量表达式(constexpr)
常量表达式机制是为了:
- 提供一种更加通用的常量表达式。
- 允许用户自定义的类型成为常量表达式。
- 提供了一种保证在编译期完成初始化的方法(可以在编译时期执行某些函数调用)。
考虑下面这段代码:
1 | enum Flags { good=0, fail=1, bad=2, eof=4 }; |
虽然“bad|eof”是一个表达式,但是因为这两个参数都是常量,在编译时期,就可以计算出它的结果,因而可以作为常量对待,可以在编译时期被动地计算表达式的值。
constexpr 并不是 const 的通用版,反之亦然:
- const 主要用于表达“对接口的写权限控制”,即“对于被 const 修饰的量名(例如 const 指针变量),不得通过它对所指对象作任何修改”。(但是可以通过其他接口修改该对象)。
- constexpr 的主要功能则是让更多的运算可以在编译期完成,并能保证表达式在语义上是类型安全的。(译注:相比之下,C 语言中#define 只能提供简单的文本替换,而不具任何类型检查能力)。
constexpr 修饰普通变量
使用 constexpr 修改普通变量时,变量必须经过初始化且初始值必须是一个常量表达式。
constexpr 修饰函数
constexpr 还可以用于修饰函数的返回值,这样的函数又称为“常量表达式函数”。
注意,constexpr 并非可以修改任意函数的返回值。换句话说,一个函数要想成为常量表达式函数,必须满足如下 4 个条件:
- 整个函数的函数体中,除了可以包含 using 指令、typedef 语句以及 static_assert 断言外,只能包含一条 return 返回语句。
- 该函数必须有返回值,即函数的返回值类型不能是 void。
- 函数在使用之前,必须有对应的定义语句。
- return 返回的表达式必须是常量表达式。
常量表达式函数的返回值必须是常量表达式的原因很简单,如果想在程序编译阶段获得某个函数返回的常量,则该函数的 return 语句中就不能包含程序运行阶段才能确定值的变量。
constexpr 修饰类的构造函数
对于 C++ 内置类型的数据,可以直接用 constexpr 修饰,但如果是自定义的数据类型(用 struct 或者 class 实现),直接用 constexpr 修饰是不行的。
1 | //此程序是无法通过编译的,编译器会抛出“constexpr 不能修饰自定义类型”的异常。 |
当我们想自定义一个可产生常量的类型时,正确的做法是在该类型的内部添加一个常量构造函数。例如,修改上面的错误示例如下:
1 |
|
可以看到,在 myType 结构体中自定义有一个构造函数,借助此函数,用 constexpr 修饰的 myType 类型的 my 常量即可通过编译。
constexpr 修饰模板函数
C++11 语法中,constexpr 可以修饰模板函数,但由于模板中类型的不确定性,因此模板函数实例化后的函数是否符合常量表达式函数的要求也是不确定的。针对这种情况下,C++11 标准规定,如果 constexpr 修饰的模板函数实例化结果不满足常量表达式函数的要求,则 constexpr 会被自动忽略,即该函数就等同于一个普通函数。
变长模板
变长函数和变长的模板参数
printf 则使用了 C 语言的函数变长参数特性,通过使用变长函数( variadic funciton), printf 的实现能够接受任何长度的参数列表。不过无论是宏,还是变长参数,整个机制的设计上,没有任何一个对于传递参数的类型是了解的。我们可以看看变长函数的例子。通常情况下,一个变长函数可以如下代码所示。
1 |
|
在上述代码中,我们声明了一个名为 Sumoffloat
变长函数。变长函数的第一个参数 count 表示的是变长参数的个数,这必须由
Sumoffloat 的调用者传递进来。而在被调用者中,则需要通过一个类型为
va_list 的数据结构 ap 来辅助地获得参数。可以看到,这里代码首先使用
va_star 函数对 ap 进行初始化,使得 ap 成为被传递的变长参数的一个“句柄”(
handler)。而后代码再使用 va_arg 函数从 ap
中将参数一取出用于运算。由于这里是计算浮点数的和,所以每次总是给 va_arg
传递一个 double
类型作为参数。下图显示了一种变长函数的可能的实现方式,即以句柄 ap
为指向各个变长参数的指针,而 va_arg 则通过改变指针的方式(每次增加
sizeof( double)字节)来返回下一个指针所指向的对象。 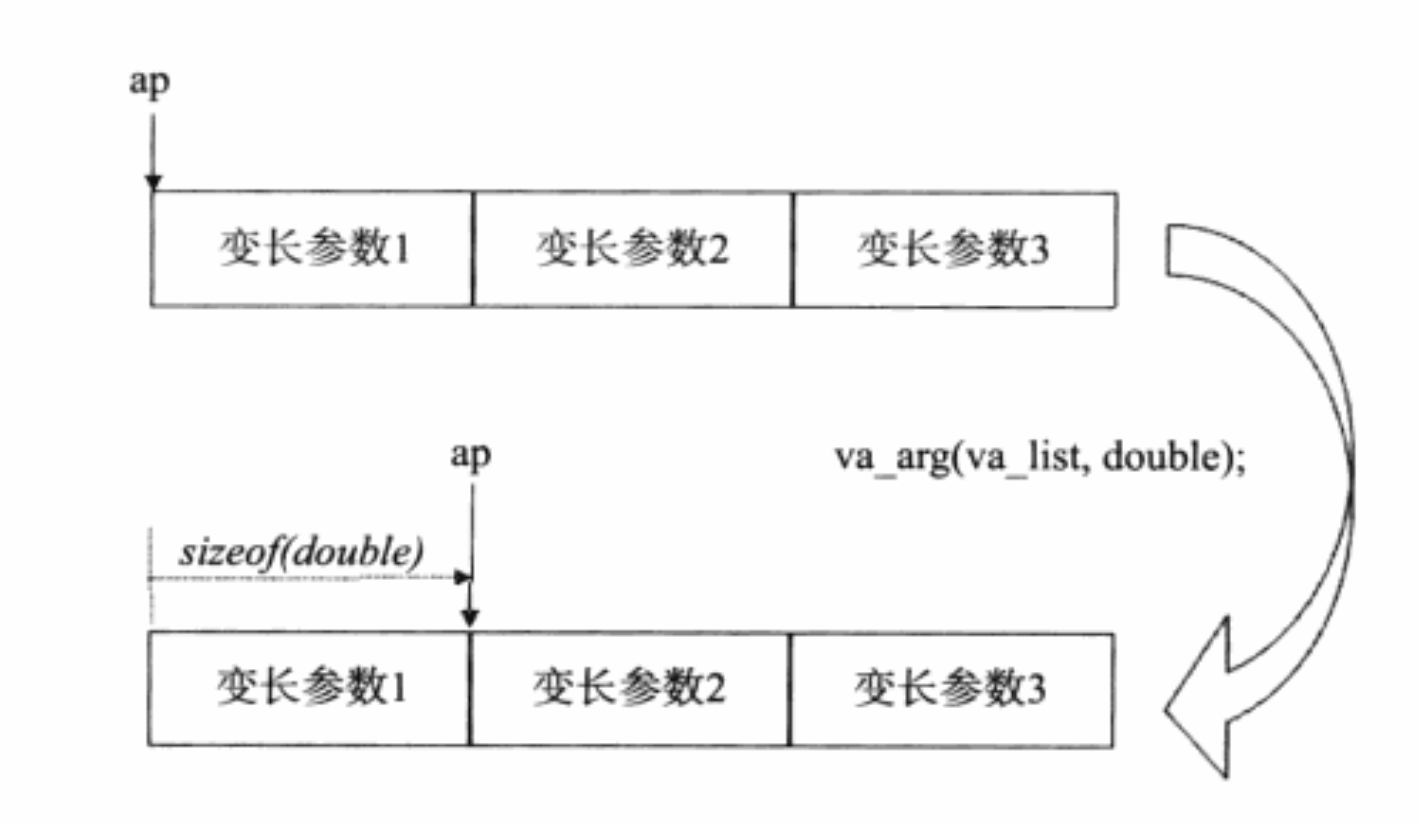
可以看到,在本例中,只有使用表达式 va_arg(ap,double)的时候,我们才按照类型(实际是按类型长度)去变长参数列表中获得指定参数。而如何打印则得益于传递在字符串中的形如“s% d%”这样的转义字,以及传递的 count 参数。事实上,函数“本身”完全无法知道参数数量或者参数类型。因此,对于一些没有定义转义字的非 POD 的数据来说,使用变长函数就会导致未定义的程序行为。比如:
1 | const char *msg = "hello %s"; |
这样的代码就会导致 printf 出错。 从另一个角度讲,变长函数这种实现方式,对于 C++这种强调类型的语言来说相当于开了一个“不规范”的后门。这是 C++标准中所不愿意看到的(即使它能够工作)。因此,客观上,C++需要引入一种更为“现代化”的变长参数的实现方式,即类型和变量同时能够传递给变长参数的函数。一个好的方式就是使用 C++的函数模板
此外在一些情况下,类也需要不定长度的模板参数。最为典型的就是 C++11 标准库中的 tuple 类模板。如果读者熟悉 C++98 中的 pair 类模板的话,那么理解 tuple 也就不困难了。具体来讲,pair 是两个不同类型的数据的集合。比如 pair<int,double>就能够容纳 int 类型和 double 类型的两种数据。一些如 std::map 的标准库容器,其成员就需要是类模板 pair 的。在 C++11 中, tuple 是 pair 类的一种更为泛化的表现形式。比起 pair, tuple 是可以接受任意多个不同类型的元素的集合。比如我们可以通过:
1 | std::tuple<double, char, std::string> collections; |
来声明一个 tuple 模板类。该 collections 变量可以容纳 double、char、std::string 三种类型的数据。当然,读者还可以用更多的参数来声明 collection,因为 tuple 可以接受任意多的参数。此外,和 pair 类似地,我们也可以更为简单地使用 C++11 的模板函数 make_tuple 来创造一个 tuple 模板类型。
1 | std: make_tuple(9.8, 'g', "gravity"); |
由于 tuple 包含的类型数量可以任意地多,那么在客观上,就需要类模板能够接受变长的参数。因此,在 C++11 中我们就看到了所谓的变长模板( variadic template)的实现。
变长模板:模板参数包和函数参数包
我们先看看变长模板的语法,还是以前面提到的 tuple 为例,我们需要以下代码来声明 tuple 是一个变长类模板
1 | template<typename ... Elements> class tuple; |
可以看到,我们在标示符 Elements 之前的使用了省略号(三个“点”)来表示该参数是变长的。在 C++11 中, Elements 被称作是一个“模板参数包"( template parameter pack)这是一种新的模板参数类型。有了这样的参数包,类模板 tuple 就可以接受任意多个参数作为模板参数。对于以下实例化的 tuple 模板类:
1 | tuple<int, char, double> |
编译器则可以将多个模板参数打包成为“单个的”模板参数包 Elements,即 Element 在进行模板推导的时候,就是一个包含 int、char 和 double 三种类型类型集合。
与普通的模板参数类似,模板参数包也可以是非类型的,比如:
1 | template<int...A> class Nontypevariadictemplate(); |
就定义了接受非类型参数的变长模板 Nontypevariadictemplate。这里,我们实例化一个三参数(1,0,2)的模板实例 ntvt。该声明方式相当于:
1 | template<int, int, int> class Nontypevariadictemplate: |
这样的类模板定义和实例化。 除了类型的模板参数包和非类型的模板参数包,模板参数包实际上还是模板类型的,不过这样的声明会比较复杂,我们在后面再讨论一个模板参数包在模板推导时会被认为是模板的单个参数(虽然实际上它将会打包任意数量的实参)。为了使用模板参数包,我们总是需要将其解包( unpack)。在 C++11 中,这通常是通过一个名为包扩展( pack expansion)的表达式来完成。比如:
1 | template<typename...A> class Template: private B<A...>{}; |
这里的表达式 A...(即参数包 A 加上三个“点”)就是一个包扩展。直观地看,参数包会在包扩展的位置展开为多个参数。比如:
1 | template<typename T1, typename T2> class B{}; |
这里我们为类模板声明了一个参数包 A,而使用参数包 A... 则是在 Template 的私有基类 B<A...>中,那么最后一个表达式就声明了一个基类为 B<X,Y>的模板类 Template<X,Y>的对象 xy。其中 X、Y 两个模板参数先是被打包为参数包 A,而后又在包扩展表达式 A... 中被还原。读者可以体会一下这样的使用方式。
不过上面对象 xy 的例子是基于类模板 B 总是接受两个参数的前提下的。倘若我们在这里声明了一个 Template<X,Y,Z>,就必然会发生模板推导的错误。这跟我们之前提到的“变长”似乎没有任何关系。那么如何才能利用模板参数包及包扩展,使得模板能够接受任意多的模板参数,且均能实例化出有效的对象呢?
事实上,在 C++11 中,实现 tuple 模板的方式给出了一种使用模板参数包的答案。这个思路是使用数学的归纳法,转换为计算机能够实现的手段则是递归。通过定义递归的模板偏特化定义,我们可以使得模板参数包在实例化时能够层层展开,直到参数包中的参数逐渐耗尽或到达某个数量的边界为止。下面的例子是一个用变长模板实现 tuple(简化的 tuple 实现)的代码,如下代码所示。
1 | template<typename...Elements> class tuple; //变长模板的声明 |
在代码中,我们声明了变长模板类 tuple,其只包含一个模板参数,即
Elements 模板参数包。此外,我们又偏特化地定义了一个双参数的 tuple
的版本。该偏特化版本的 tuple 包含了两个参数,一个是类型模板参数
Head,另一个则是模板参数包 Tail 在代码的实现中,我们将 Head 型的数据作为
tuple<Head,Tail...>的第一个成员,而将使用了包扩展表达式的模板类
tuple<Tail...>作为
tuple<Head,Tail...>的私有基类。这样来,当程序员实例化一个形如
tuple <double,int,char,
float>的类型时,则会引起基类的递归构造,这样的递归在 tuple 的参数包为
0 个的时候会结束。这是由于我们定义了边界条件或者说初始条件,即
tuples<>这样不包含参数的偏特化版本而造成的。在代码中,
tuples<>偏特化版本是一个没有成员的空类型。这样一来,编译器将从
tuples 建造出 tuple<float...>,继而造出 tuple<char,foat>、
tuple<int,char,foat>,最后就建造出了
tuple<double,int,char,foa>类型。 下图是
tuple<double,in,char,nioa>实例化后的继承结构示意图。我们用方框表示类型,而方框内的方框则表示类型由其内部的方框所代表的类型私有派生而来。
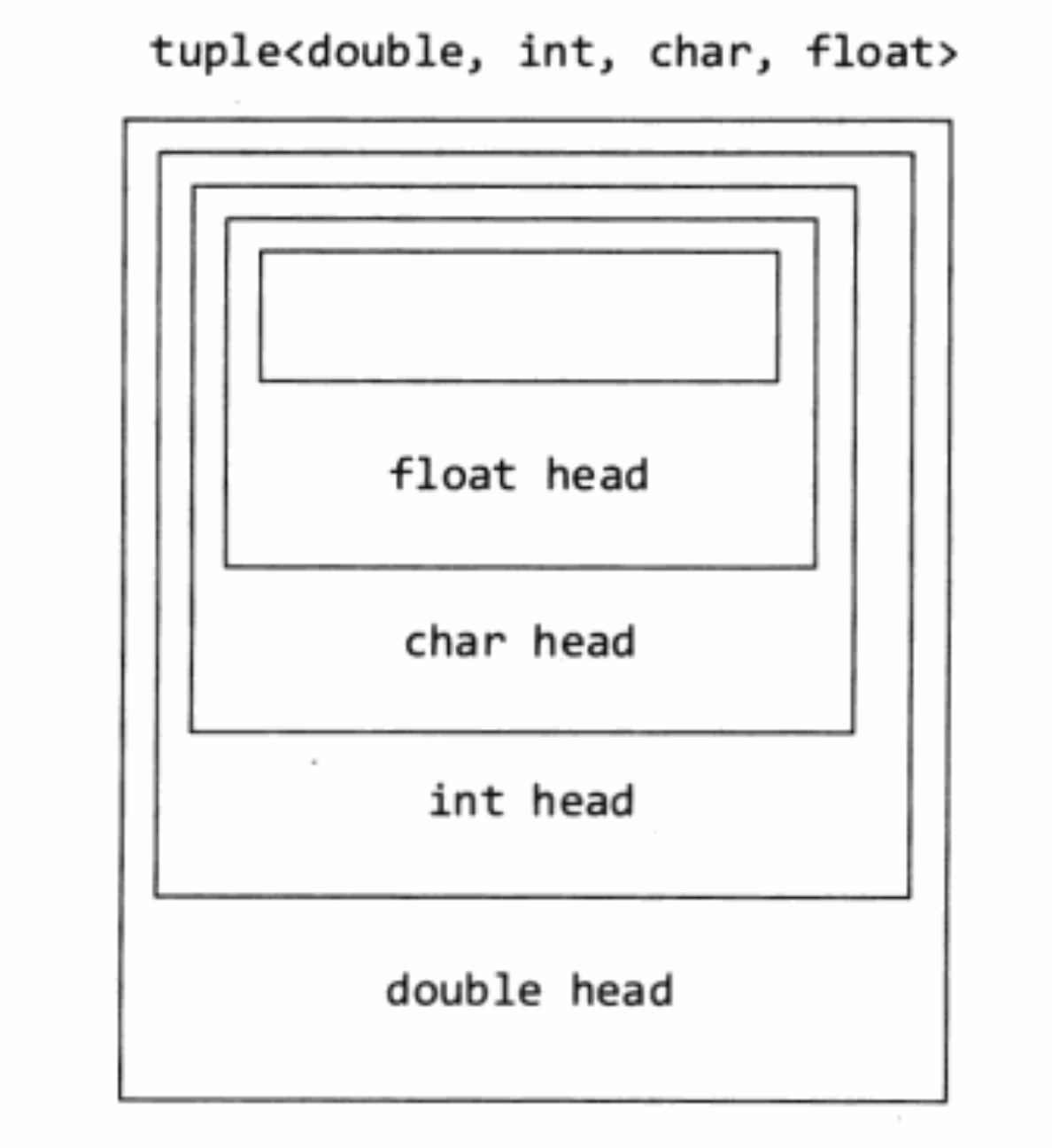
这种变长模板的定义方式稍显复杂,不过却有效地解决了模板参数个数这样的向题。当然,这样做的前提是模板类/函数的定义要具有能够递推的结构。
除了变长的模板类,在 C++11 中,我们还可以声明变长模板的函数。对于变长模板函数而言,除了声明可以容纳变长个模板参数的模板参数包之外,相应地,变长的函数参数也可以声明成函数参数包( function parameter pack)。比如:
1 | template<typename...T> void f(T...args); |
这个例子中,由于 T 是个变长模板参数(类型),因此 args 则是对应于这些变长类型的数据,即函数参数包。值得注意的是,在 C++11 中,标准要求函数参数包必须唯一,且是函数的最后一个参数(模板参数包没有这样的要求)。 有了模板参数包和函数参数包两个概念,我们就可以实现 C 中变长函数的功能了。
原子类型与原子操作
并行编程、多线程与 C++11
在 C++11 之前,在 C/C++中程序中使用线程却并非鲜见。这样的代码主要使用 POSIX 线程( pthread)和 OpenMP 编译器指令两种编程模型来完成程序的线程化。而在 C++11 中,标准的一个相当大的变化就是引入了多线程的支持,这使得 C/C++语言在进行线程编程时,不必依赖第三方库和标准。而 C++对线程的支持,一个最为重要的部分,就是在原子操作中引入了原子类型的概念。
原子操作与 C++11 原子类型
通常情况下,原子操作都是通过“互斥”( mutual exclusive)的访问来保证的。借助 POSIX 标准的 pthread 库中的互斥锁( mutex)也可以做到。不过显而易见地,基于 pthread 的方法虽然可行,但代码编写却很麻烦。程序员需要为共享变量创建互斥锁,并在进入临界区前后进行加锁和解锁的操作。不过在 C++11 中,通过对并行编程更为良好的抽象,要实现同样的功能就简单了很多。我们可以看看下面的例子。
1 | std::atomic_llong total = 0; // atomic_llong 相当于 long long,但是本身就拥有原子性 |
可以看到,使用了原子类型 atomic_llong
之后,不需要使用额外的互斥接口来保证 total 的同步。除了 atomic_llong
类型,C++11 还提供了其他的原子类型。 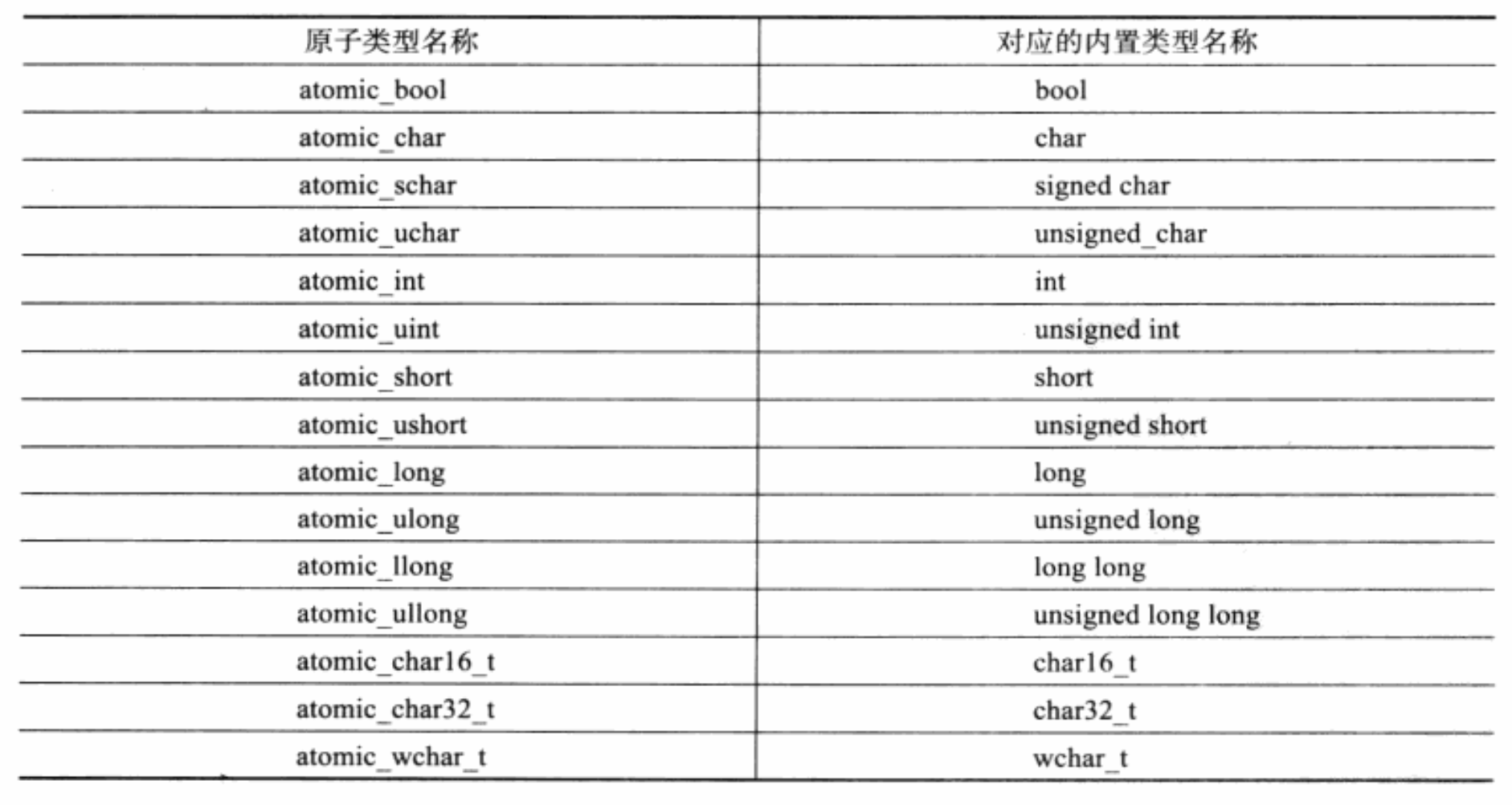
当我们去看这些类型的定义时会发现,起始它们都是用
atomic
C++11 中将原子操作定义为 atomic
模板类的成员函数,包括了大多数类型的操作,比如读写、交换等。对于内置类型,主要通过重载全局操作符来实现。下面列出所有
atomic 类型及其支持的相关操作列表: 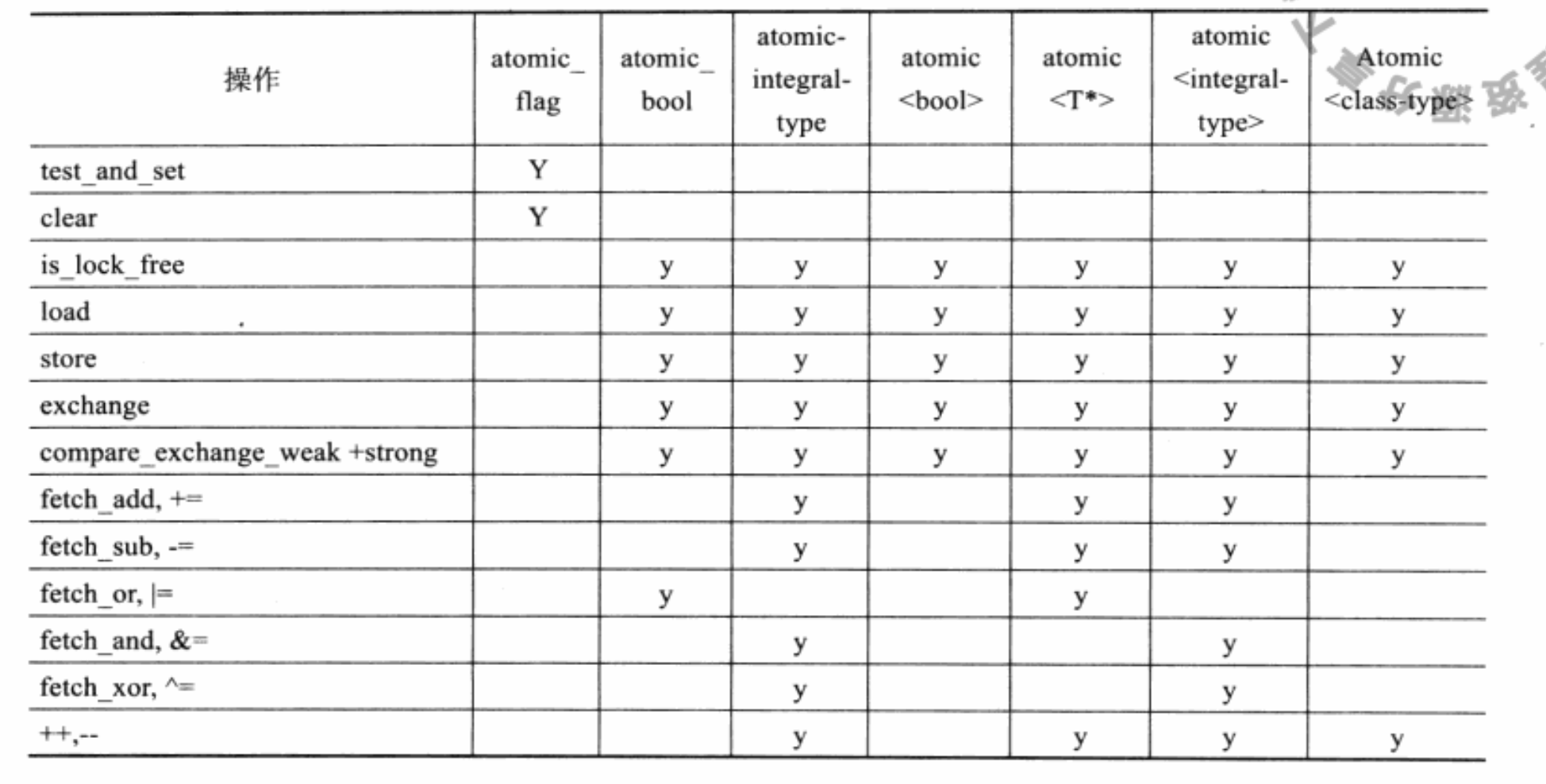
列表中的 atomic-intergral-type 以及
atomic
内存模型、顺序一致性和 memory_order
了解这一小节的内容之前,先看一段代码:
1 | void func1() |
以上的代码,在主线程中打印 a 和 b 结果必定是 1,2,而在线程 func2 中打印结果就不一定了,可能是 0,0 或者 1,2 或者 1,0。因为线程的执行并不能保证先创建的一定先运行,两者运行顺序存在多种可能。但是对于原子类型来说,func2 中的打印不可能出现 0,2 的情况,因为原子类型的变量在线程中总是保持顺序执行的特性(顺序一致性)。
不过在 C++11 中顺序一致性只是多种内存模型中的一种,代码并非必须按照顺序执行,因为顺序往往意味着最低效的同步方式。在了解其他内存模型之前,我们需要先了解一些处理器和编译器相关的知识。现代的处理器并不是逐条处理机器指令的:
1 | 1: Load reg3, 1; // 将立即数 1 放入寄存器 reg3 |
以上的伪汇编代码代表了 temp = 1; a = temp; b = 2,通常情况下指令都是按照 1~5 的顺序执行,这种内存模型称为强顺序 (strong ordered)。不过可以看到,指令 1、2、3 和指令 4、5 的运行顺序不影响结果,有一些处理器可能会将指令的顺序打乱,例如按照 1-4-2-5-3 的顺序执行,这种内存模型称为弱顺序 (weak ordered)。
介绍了硬件内存模型后,再来说说 C++11 中定义的内存模型和顺序一致性和硬件中的关系。高级语言和机器指令是通过编译器来进行转换的,而编译器处于代码优化的考虑,会将指令进行移动。对于 C++11 的内存模型而言,要保证代码的顺序一致性,需要同时做到以下几点:
- 编译器保证原子操作的指令间顺序不变,即产生的读写原子类型变量的机器指令和代码编写顺序是一样的。
- 处理器对原子操作的汇编指令的执行顺序不变。这对于 x86 这样的强顺序的体系结构而言没有任何问题,而对于一些弱顺序的平台则需要每个原子操作之后要加入内存栅栏。
对于上文打印 a,b 的代码来说,如果只需要在主线程中打印结果,那么代码的执行顺序并不重要。但是 atomic 原子类型默认的顺序一致性会要求编译器禁用优化,这无疑增加了性能开销。于是 C++11 中,设计了能够对原子类型指定内存顺序 memory_order。我们把上文打印 a,b 的代码中的 func1 做一下修改:
1 | void func1() |
上面的代码使用了 store 函数进行赋值,store
函数接受两个参数,第一个是要写入的值,第二个是名为 memory_order
的枚举值。这里使用了
std::memory_order_relaxed,表示松散内存顺序,该枚举值代表编译器可以任由编译器重新排序或则由处理器乱序处理。这样
a 和 b 的赋值执行顺序性就被解除了,对于 func2 中的打印语句,打印出 0,2
的结果也就是合理的了。在 C++11 中一共有 7 种 memory_order
枚举值,默认按照 memory_order_seq_cst 执行: 
需要注意的是,不是所有的 memory_order 都能被 atomic 成员使用:
- store 函数可以使用 memory_order_seq_cst、memory_order_release、memory_order_relaxed。
- load 函数可以使用 memory_order_seq_cst、memory_order_acquire、memory_order_consume、memory_order_relaxed。
- 需要同时读写的操作,例如 test_and_flag、exchange 等操作。可以使用 memory_order_seq_cst、memory_order_rel、memory_order_release、memory_order_acquire、memory_order_consume、memory_order_relaxed。
- 原子类型提供的一些操作符都是 memory_order_seq_cst 的封装,所以他们都是顺序一致性的。
最后说明一下,在除非必要的情况下,不用使用 std::memory_order,std::atmoic 默认用的是最强限制。
线程局部存储
线程局部存储(TLS, thread local storage)是一个已有的概念。简单地说,所谓线程局部存储变量,就是拥有线程生命期及线程可见性的变量。线程局部存储实际上是由单线程程序中的全局/静态变量被应用到多线程程序中被线程共享而来。我们可以简单地回顾一下所谓的线程模型。通常情况下,线程会拥有自己的栈空间,但是堆空间、静态数据区则是共享的。这样一来,全局、静态变量在这种多线程模型下就总是在线程间共享的。 C++11 声明一个 TLS 变量的语法很简单,即通过 thread_local 修饰符声明变量即可:
1 | int thread_local errcode; |
一旦声明一个变量为 thread_local,其值将在线程开始时被初始化,而在线程结束时,该值也将不再有效。对于 thread_local 变量地址取值(&),也只可以获得当前线程中的 TLS 变量的地址值。
参考文献
https://blog.csdn.net/WizardtoH/article/details/81111549
《深入理解 C++11:C++11 新特性解析与应用》