CPUIdle
cpu idle实现原理
通过wfi或wfe指令进入low-power-state。在low-power-state下cpu core保持上电状态,但其大部分时钟停止或者进入时钟门限。这意味着core的绝大部分都处于static state,唯一消耗的功率是用于寻找中断唤醒条件的泄漏电流和少量逻辑时钟。进入low-power-state后将暂停当前的工作直到某个中断或event事件发生会退出low-power-state进入正常运行state。


其唤醒wfi或wfe的interrupt或者event请参考《The AArch64 System Level Programmers’ Model 》D1.6 Mechanisms for entering a low-power state

cpu idle代价
cpu的状态被称为C状态,不同的C状态功耗不同,其中C0是normal state,正常运行状态就是C0状态,其他各state退出到C0状态所需的时间也不同,以下是一个笔记本的CPU各C状态的功耗和退出latency。
| C1 | C2 | C3 | |
|---|---|---|---|
| Exit latency (µs) | 1 | 1 | 57 |
| Power consumption (mW) | 1000 | 500 | 100 |
cpu idle的设计目的是降低功耗,但是进入cpu idle是有代价的,这里面会涉及entry_latency以及对应的能量消耗,退出low-power-state也需要时间exit_latency以及对应的能量消耗,如果cpu待在low_power_state的时间很短那么可能进入和退出的能量消耗比cpu空转都高,而且这期间还导致cpu无法处理其他事情,导致系统性能下降。
这里的代价主要是两个指标:
- 功耗
- latency
要求功耗越低那么就需要idle深度越深(关闭的额模块越多)那么从low_power_state到nomal state所花的时间就越久,也就是功耗和latency是互相矛盾的。
在Linux系统中,cpuidle 子系统提供了多种策略来平衡功耗和延迟的选择,我们在使用中只要关注这些策略的倾向以及参数设计即可。
Linux cpuidle子系统
框架
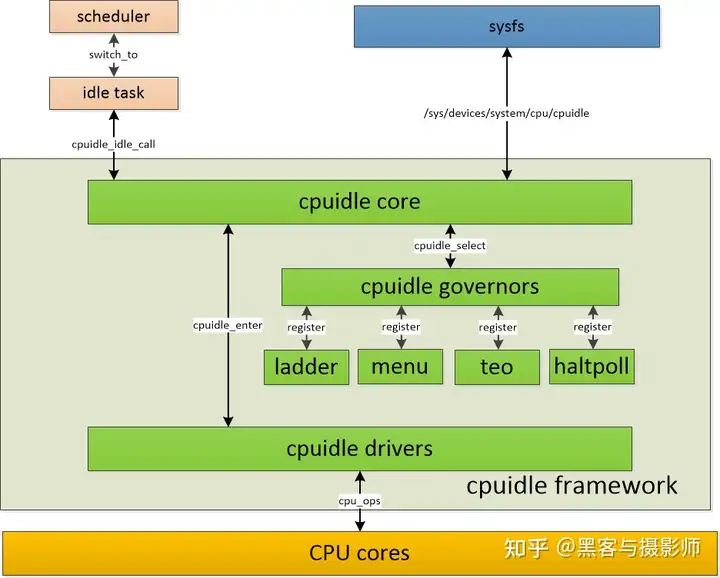
- scheduler模块:位于kernel.c中,负责实现idle状态的选择、idle的进入等等
- cpuidle core模块:cpuidle core抽象出cpuidle device、cpuidle
driver、cpuidle governor三个实体
- 以函数调用的形式,向上层sched模块提供接口
- 以sysfs的形式,向用户空间提供接口
- 向下层的cpuidle drivers模块,提供统一的driver注册和管理接口
- 向下层的cpuidle governors模块,提供统一的governor注册和管理接口
- puidle governors模块:提供多种idle的策略,比如menu/ladder/teo/haltpoll。位于governors/目录下
- cpuidle drivers模块:负责idle机制的实现,即:如何进入idle状态,什么条件下会退出
CPU Idle策略
其实idle策略的基本原则很简单就是在系统容忍的最大latency内选择休眠最深的即可,但是实际上这是很难准确评估的,系统中大量的中断、event、timer各种不确定的事件随时可能到来,接下来cpu要进入idle状态多长时间很难评估出来。
governors模块提供了四种策略,分别是menu、ladder、teo和haltpoll。
menu
任务1,menu governor从如下几个方面去达成:
menu governor用于tickless system,简化处理,menu将“距离下一个tick来临的时间(由next timer event测量,简称next_timer_us)”作为基础的predicted_us。
当然,这个基础的predicted_us是不准确的,因为在这段时间内,随时都可能产生除next timer event之外的其它wakeup event。为了使预测更准确,有必要加入一个校正因子(correction factor),该校正因子基于过去的实际predicted_us和next_timer_us之间的比率,例如,如果wakeup event都是在预测的next timer event时间的一半时产生,则factor为0.5。另外,为了更精确,menu使用动态平均的factor。
另外,对不同范围的next_timer_us,correction factor的影响程度是不一样的。例如期望50ms和500ms的next timer event时,都是在10ms时产生了wakeup event,显然对500ms的影响比较大。如果计算平均值时将它们混在一起,就会对预测的准确性产生影响,所以计算correction factor的数据时,需要区分不同级别的next_timer_us。同时,系统是否存在io wait,对factor的敏感度也不同。基于这些考虑,menu使用了一组factor(12个),分别用于不同next_timer_us、不同io wait的场景下的的校正。
最后,在有些场合下,next_timer_us的预测是完全不正确的,如存在固定周期的中断时(音频等)。这时menu采用另一种不同的预测方式:统计过去8次停留时间的标准差(stand deviation),如果小于一定的门限值,则使用这8个停留时间的平均值,作为预测值。
任务2,延迟容忍度(latency_req)的估算,menu综合考虑了两种因素,如下:
由pm qos获得的,系统期望的CPU和DMA的延迟需求。这是一个硬性指标。
基于这样一个经验法则:越忙的系统,对系统延迟的要求越高,结合任务1中预测到的停留时间(predicted_us),以及当前系统的CPU平均负荷和iowaiters的个数(get_iowait_load函数获得),算出另一个延迟容忍度,计算公式(这是一个经验公式)为: predicted_us / (1 + 2 * loadavg +10 * iowaiters) 这个公式反映的是退出延迟和预期停留时间之间的比例,loadavg和iowaiters越大,对退出延迟的要求就越高奥。
最后,latency_req的值取上面两个估值的最小值。
TEO(Timer Events Oriented)
面向计时器事件 (TEO) 的governor 是tickless systems的替代governor ,它遵循与menu调度器相同的基本策略:始终尝试找到适合当前条件的最深空闲状态。然而,它采用了一种不同的方法来解决这个问题。
首先,它不使用睡眠时间修正因子,而是尝试将观察到的空闲持续时间值与可用的空闲状态进行关联,并利用这些信息选择最有可能“匹配”即将到来的CPU空闲间隔的空闲状态。其次,它完全不考虑过去在给定CPU上运行的任务,这些任务现在正在等待一些I/O操作完成(没有保证它们在重新变为可运行状态时会在同一CPU上运行),而且其中的模式检测代码避免了计时器唤醒的影响。它还仅使用小于当前时间与最近计时器(不包括调度器滴答)之间的时间间隔的空闲持续时间值。
具体算法比较复杂请参考《https://docs.kernel.org/admin-guide/pm/cpuidle.html》,,,略
haltpoll
适用于虚拟机系统,略
ladder
是一种更为简单的调度策略,它通过一个类似阶梯的机制来选择 CPU 的空闲状态。CPU 会按顺序尝试不同的空闲状态,从最浅的状态到最深的状态。
PM QoS
PM QoS有哪些指标
针对这个指标PM QoS有一个专门的名词:constraint(约束),其实也比较好理解,可以看做其他模块对PM的诉求和限制,目前PM QoS针对这些指标分为两类:一类是系统级的,包括:cpu&dma latency、network latency、network throughput和memory bandwidth,定义在kernel/power/qos.c中(在最新的kernel-5.4版本中,这一类constraint从4个缩减到只有cpu&dma latency这一个,同时增加了一类cpufreq的constraint)
这些指标该如何去满足呢
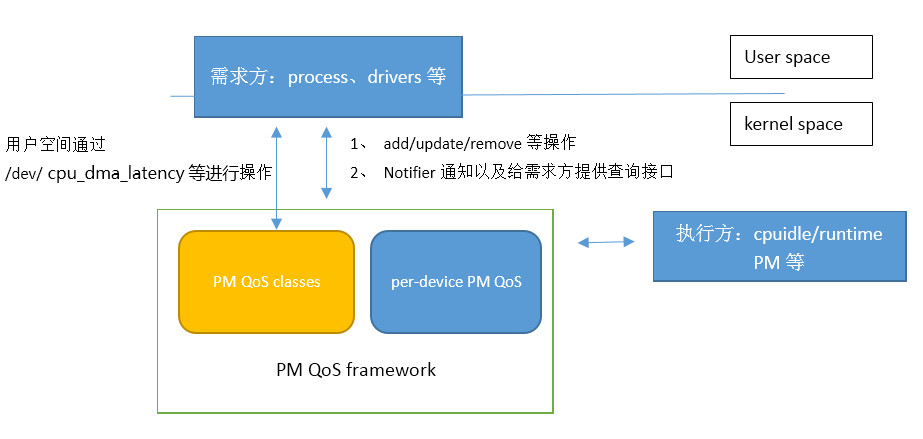
- 需求方:如进程、drivers等,它们根据自身的特性提出一系列需求(如cpu&dma latency等)
- 框架层:PM QoS framework对这些需求进行汇总,根据实际情况,计算出来极值(比如cpu&dma的latency不能小于xx等)
- 执行方:执行方需要确保自身的行为可以满足这些需求,这里的执行方很容易想到都是电源管理相关的,比如cpuidle,需要确保cpuidle等级满足cpu&dma latency的最低要求等等,可以参考下第三章的实例
相关参数说明
先确认当前系统采用的governors:
1 | cd /sys/devices/system/cpu |
当前采用的governors是menu调度。
dts里的参数
1 | idle-states { |
- entry-latency-us是进入cpuidle需要的时间
- exit-latency-us是离开cpuidle所需的时间
- min-residency-us:这个是idle指定cpu进入idle的最小时间,当小于这个时间则不划算,linux cpuidle子系统的menu、teo等算法要参考此参数来决定cpu要不要进入idle状态的。
- local-timer-stop:指示在进入cpuidle时是否关闭本地timer
- psci-suspend-param:PSCI传递参数,存储了power_state信息,对于cpuidle来说bit24用于区分哪种掉电方式
cpu进入idle后需要不定期通过tick进行唤醒,但是如果在idle-state节点中定义了local-timer-stop属性就会导致cpu本地的timer被关闭,出现没有外部中断来临就无法退出中断的情况,这种情况下就需要将一个timer变为broadcast-timer,用来一段时间后让cpu退出idle状态。
sysfs文件节点
1 | # cat sys/devices/system/cpu/cpu0/cpuidle/ |
- above, below :cpuidle未满足期望休眠的次数,如提前唤醒
- desc, name:cpuidle的名称
- latency : 进入和退出idle的总时间,由DTS中 entry-latency-us和exit-latency-us相加得来
- residency :最小驻留时间, 由DTS中的min-residency-us解析而来
- time:停留cpuidle state中的累计时间
- usage:停留在cpuidle state中的累计次数
参考文献
http://www.wowotech.net/pm_subsystem/cpuidle_overview.html
http://www.wowotech.net/pm_subsystem/cpuidle_core.html
http://www.wowotech.net/pm_subsystem/cpuidle_arm64.html
http://www.wowotech.net/pm_subsystem/cpuidle_menu_governor.html