记录一次UAC 丢包问题分析过程
实验
测试发现period_size=512或者256时均不发生丢包,于是做以下实验:
| sampling rate | channel | bit depth | period_size | package size | 是否丢包 |
|---|---|---|---|---|---|
| 48k | 2 | 16bit | 1024 | 4096Byte | 丢包 |
| 48k | 1 | 16bit | 1024 | 2048Byte | 丢包 |
| 48k | 2 | 16bit | 512 | 2048Byte | 不丢包 |
| 48k | 4 | 16bit | 512 | 4096Byte | 不丢包 |
通过实验发现,丢包与period_size相关与package size无关。
通过perf top分析
通过perf top查看系统和aplay中哪些函数占比高:
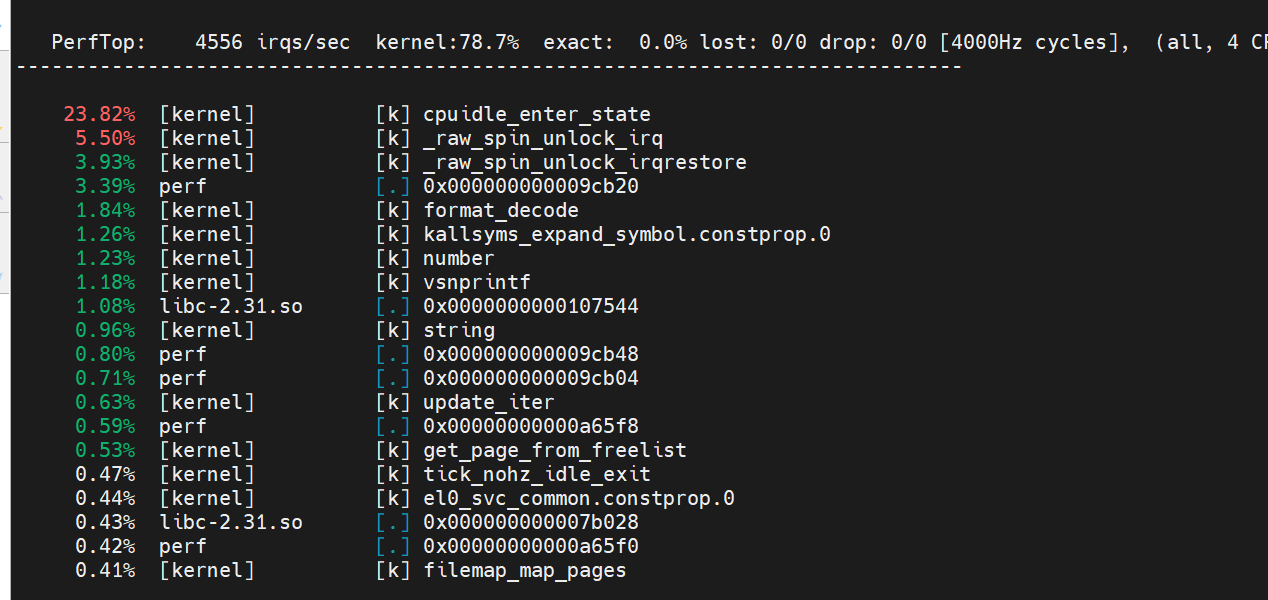
这里可以看到有大量的spin_lock函数占用比较高的cpu时间。猜测系统哪里可能有自旋锁使用不当。但是这里无法看到函数调用栈,不知道哪里调用的spinlock占用cpu资源多。
通过火焰图分析
查看ftrace
1 | mount -t debugfs none /sys/kernel/debug/ |
使用function_graph功能
需要内核开启FUNCYTION_PROFILER选项。
1 | echo 1 > ./function_profile_enabled |
使用火焰图分析
1 | perf record -F 5000 -p <pid> -g -- sleep 60 |
生成火焰图:
1 | git clone https://github.com/brendangregg/FlameGraph.git |
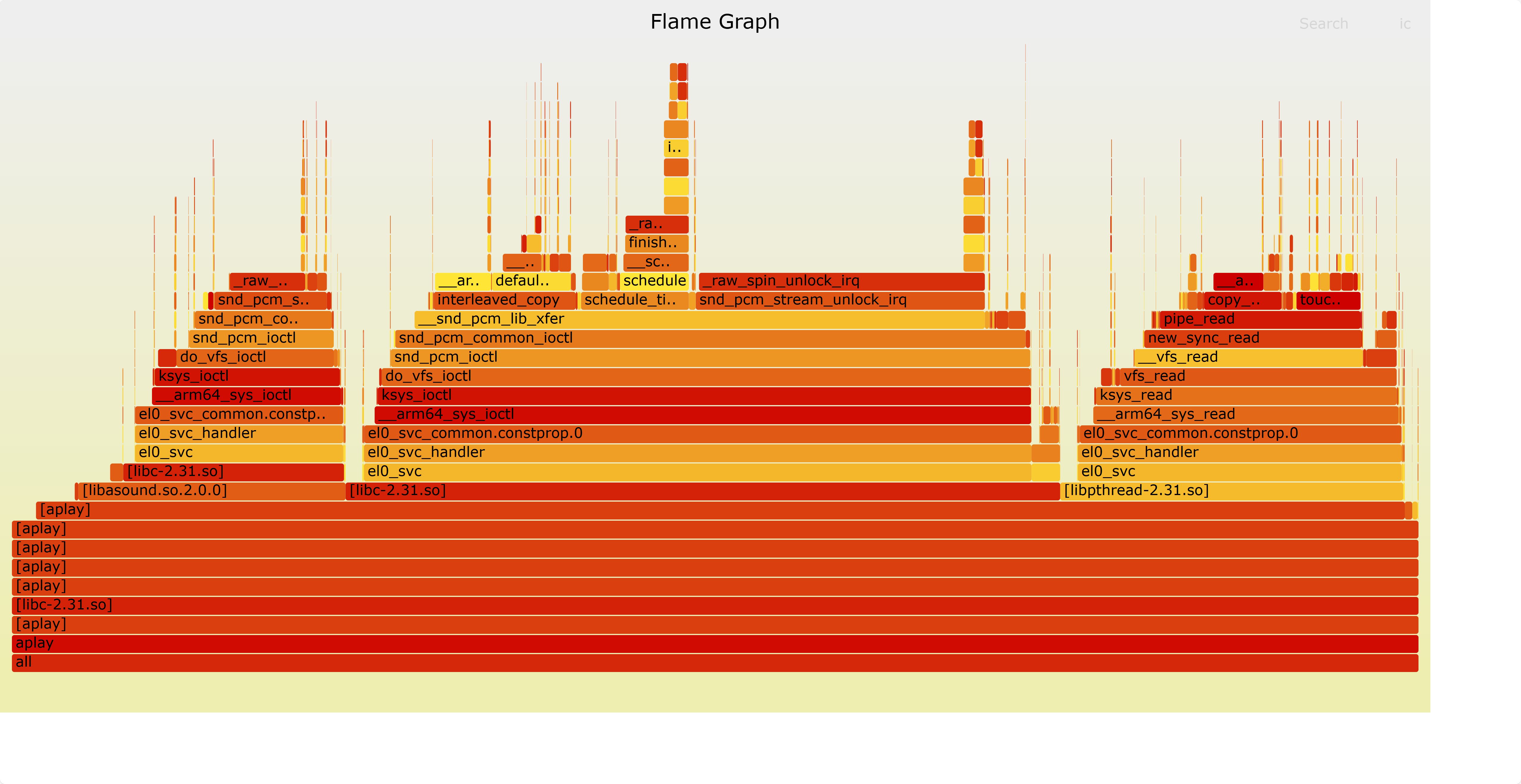
这里可以看到__snd_pcm_lib_xfer这个函数里的spinlock占用比较高的cpu资源。
通过打印时间戳分析
前面发现__snd_pcm_lib_xfer这个函数耗时很久于是打印这个函数的耗时信息:
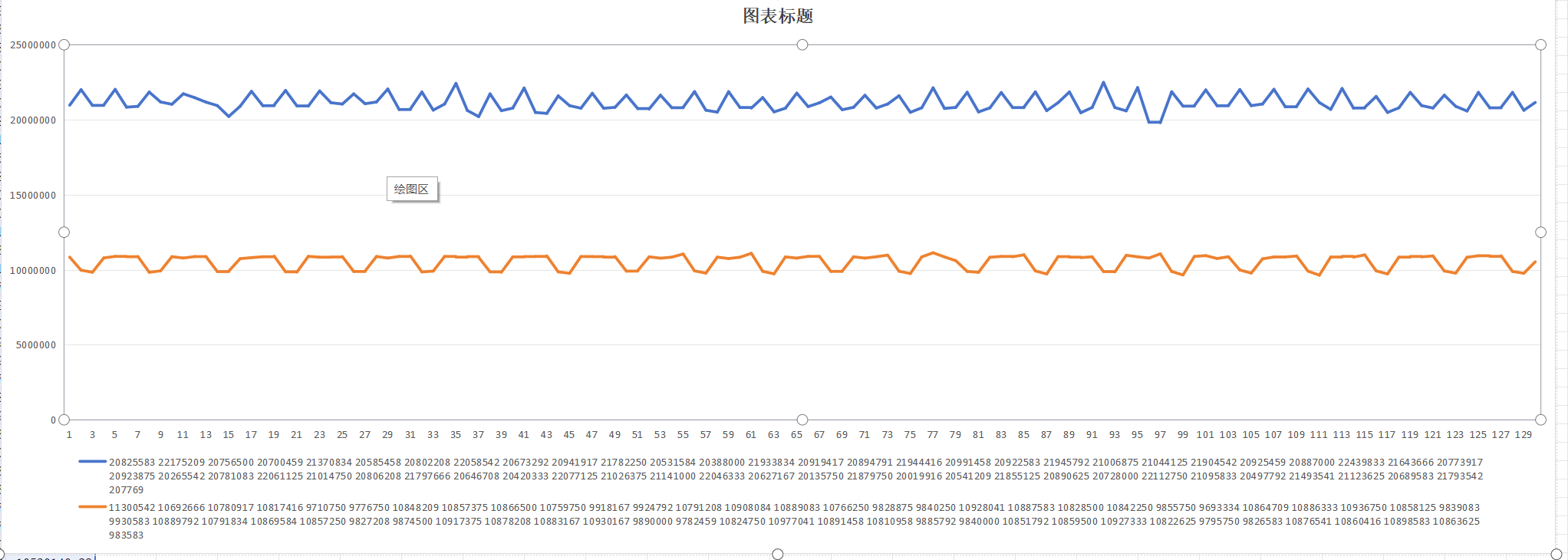
蓝色为period_size=1024时__snd_pcm_lib_xfer函数运行时间单位为ns,平均下来就是一个period_size间隔时间为1024 * 1000 / 48000 = 21ms
橙色为period_size=512时__snd_pcm_lib_xfer函数运行时间单位为ns,平均下来就是一个period_size间隔时间为512* 1000 / 48000 = 11ms
__snd_pcm_lib_xfer这个函数里有多段自旋锁,逐个打印看是否有不合理的值,最终发现大部分sleep都在schedule_timeout这个函数里,schedule_timeout的sleep的时间计算方式有问题,对比kernel6.6已经修复了sleep时间的计算方式,但是这里也不会导致丢包因为schedule_timeout函数的sleep会被各种event打断,这里代码中是sleep 10s,但是实际sleep 20ms(对于period_size=1024情况下)就被uac里的signal打断返回而提前结束。
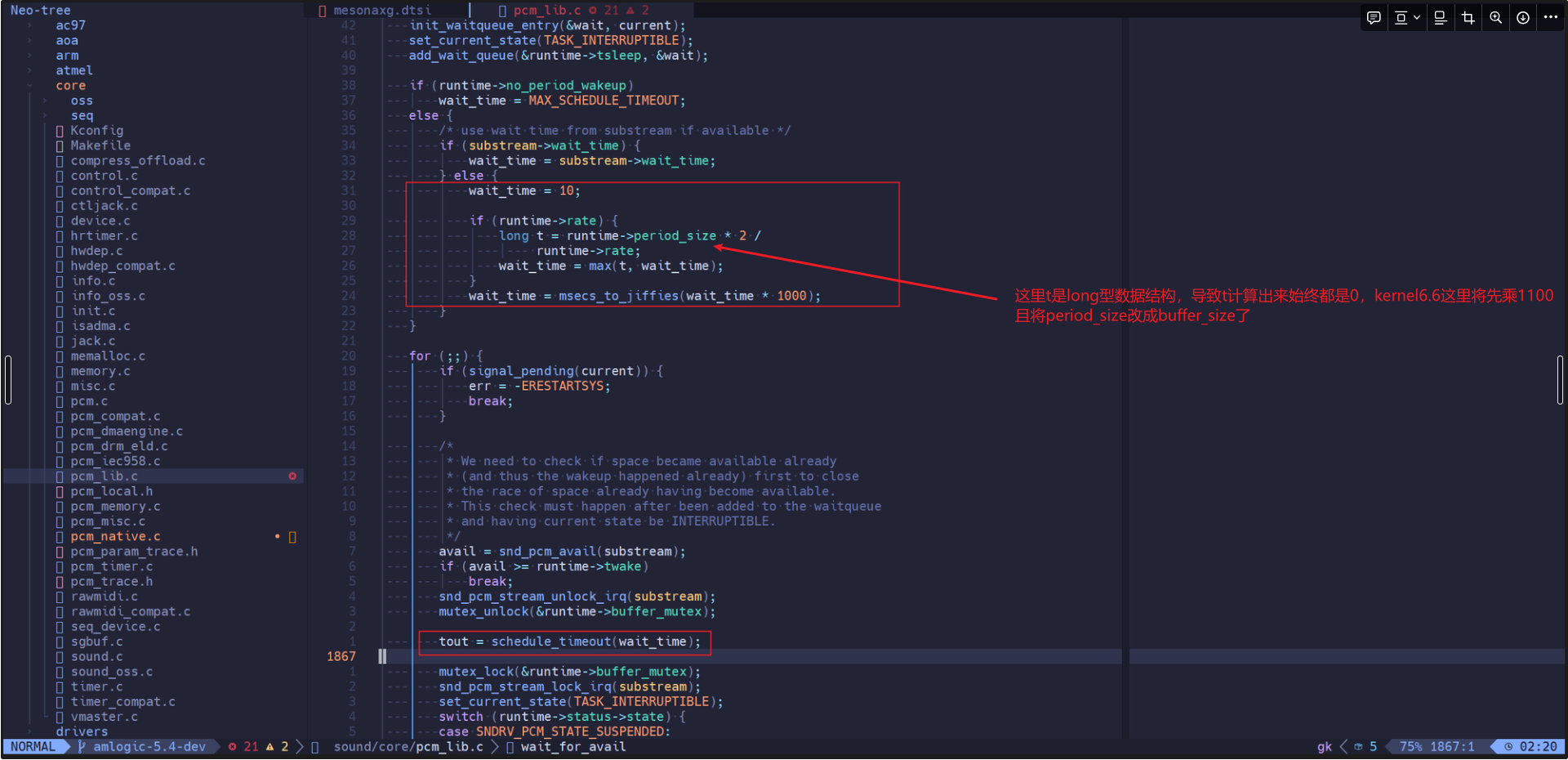
schedule_timeout函数运行时间为:
__snd_pcm_lib_xfer函数执行时间21ms其中20多ms都在schedule_timeout(没有在自旋锁内)里。到这里基本上看不出spinlock有什么问题。对比period_size=512差别只是schedule_timeout中sleep的时间长短不一致。同时根据perf top中的耗时函数看,耗时最长的是cpuidle_enter_state这个函数,怀疑是跟cpuidle相关。
cpuidle
关闭cpuidle
1 | echo 1 > /sys/devices/system/cpu/cpu0/cpuidle/state1/disable |
测试发现period_size=1024也不丢包了。
修改cpuidle参数
1 | idle-states { |
- entry-latency-us为进入cpuidle需要耗时的时间,axg上写的是5ms,这个值一看就不对,不可能耗时这么久,这个值要根据实际测试值来填写的
- exit-latency-us为退出cpuidle需要耗时的时间,同样这里也是5ms,这个值肯定不是真实的值
- min-residency-us为cpu至少要保持cpuidle状态的时间,也就是至少保持15ms,进入cpuidle才划算
我们period_size=1024的时候会sleep20多ms那么这期间就大概率会触发cpuidle进入休眠,尝试将其改成30ms,发现丢包率降低,但还是会丢包(实际查看发现cpu仍然在进入cpuidle状态)。查询cpuidle相关实现这些值是算法中的一个参数,详细的算法没去研究比较复杂,但是大致知道里面有一些权重因子,驱动不会严格按照min-residency-us来决定是否进入cpuidle而是会作用到一个权重因子,同时参考其他信息,有pm qos、以及中断、timer等相关信息来决定是否进入cpuidle状态。
这里将min-residency-us改成一个远大于period_size的值发现usb不丢包了。
反向验证下,为什么period_size=256或者512不丢包呢,查看cpuidle状态可以看到period_size=256或者512时不会进入cpuidle状态。
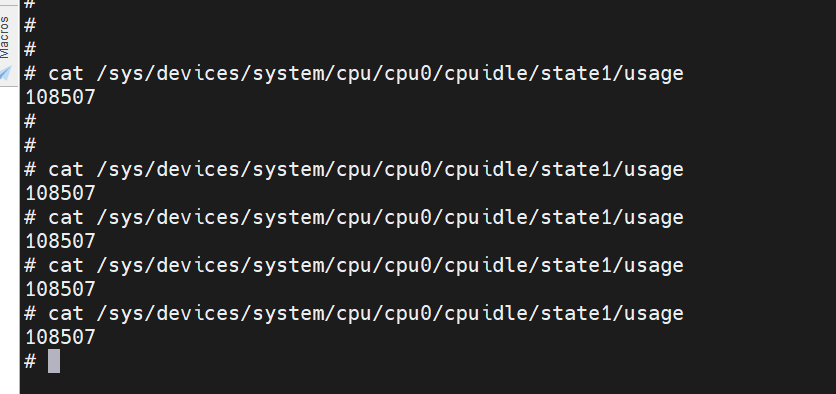
schedule_timeout这里sleep的时间短,不足以触发进入cpuidle的条件。
pm qos
前面直接通过关闭cpuidle或者修改min-residency-us都是不合理的,min-residency-us参数正确的计算方法是cpu进入cpuidle和退出cpuidle是需要额外功耗的,那么就必须保证待在cpuidle里的时间要足够久至少为min-residency-us才能保证进入cpuidle是划算的(如果进入cpuidle后立马退出那么功耗不仅不能降低还会增加,期间还disabled cpu irq)。
更合理的做法是各driver对cpuidle模块提出要求,比如这里的uac,要通过pm qos对cpuidle提出要求我的传输包间隔是period size间隔时间,期间你不能进入休眠。追查代码发现实际上我们系统里有调用pm qos接口:
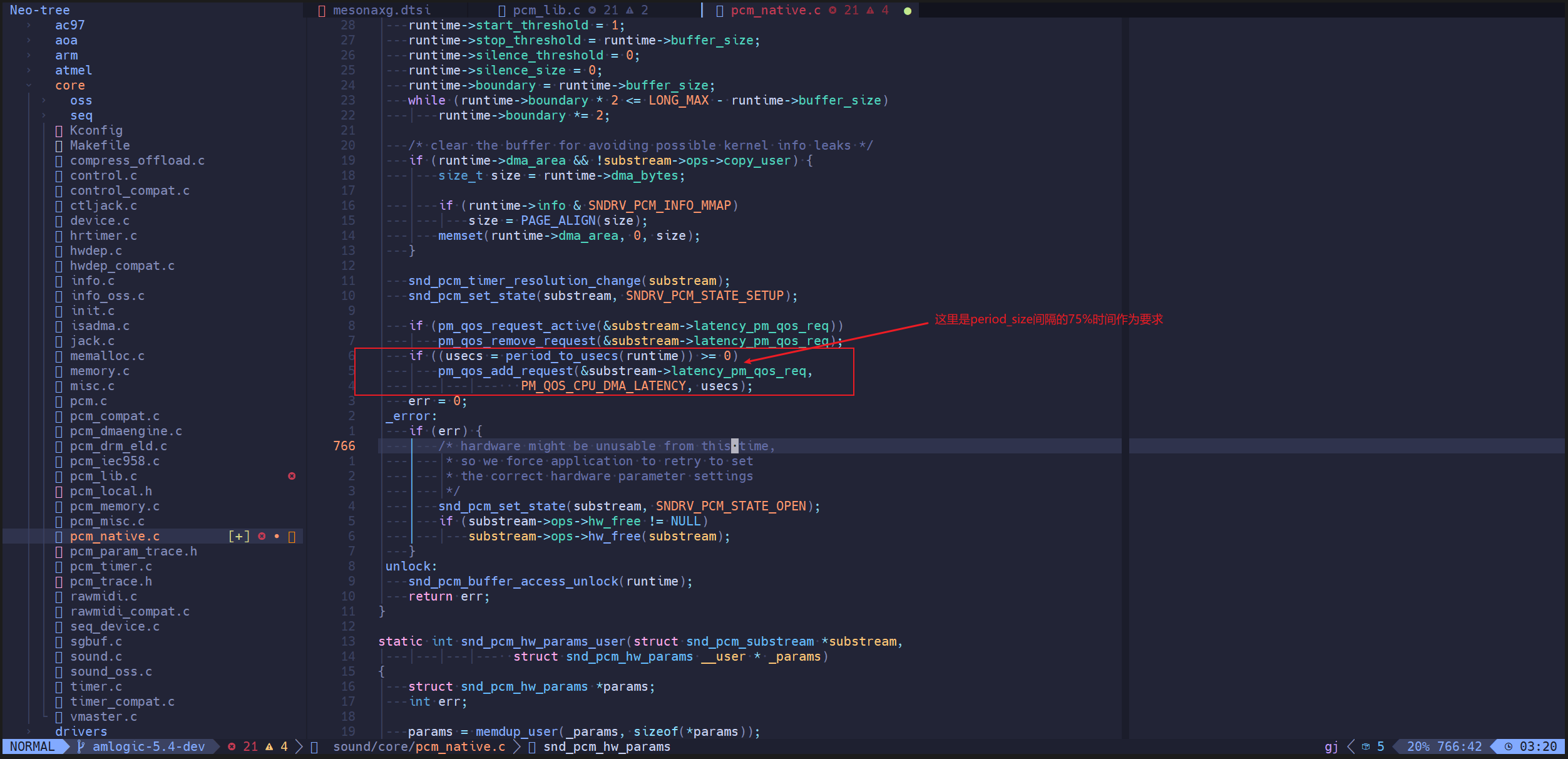
但是实际测试发现cpu仍然不停的进入cpuidle,可能是多核smp导致的,跑arecord aplay的cpu核可以满足条件,但是其他核还是可以休眠,如果关闭其他核,cpu0就不进入cpuidle了,当前也不好做验证。