
自然语言处理
自然语言处理发展综述
语言的出现是为了人与人之间的通信。英文字母或者中文的笔划实际上是信息编码的不同单位,任何一种语言都是一种编码方式,而语言的语法规则就是编码的算法。而人类研究计算机对自然语言的处理经过60多年的发展过程,大致分为两个阶段,第一个阶段(20世纪50-70年代)没有什么实质性进展,基本上是仿照人类对语言的认知,对自然语言进行句法分析和语义分析。第二个阶段转而用统计的方法才取得了实质性突破,并得到广泛应用。
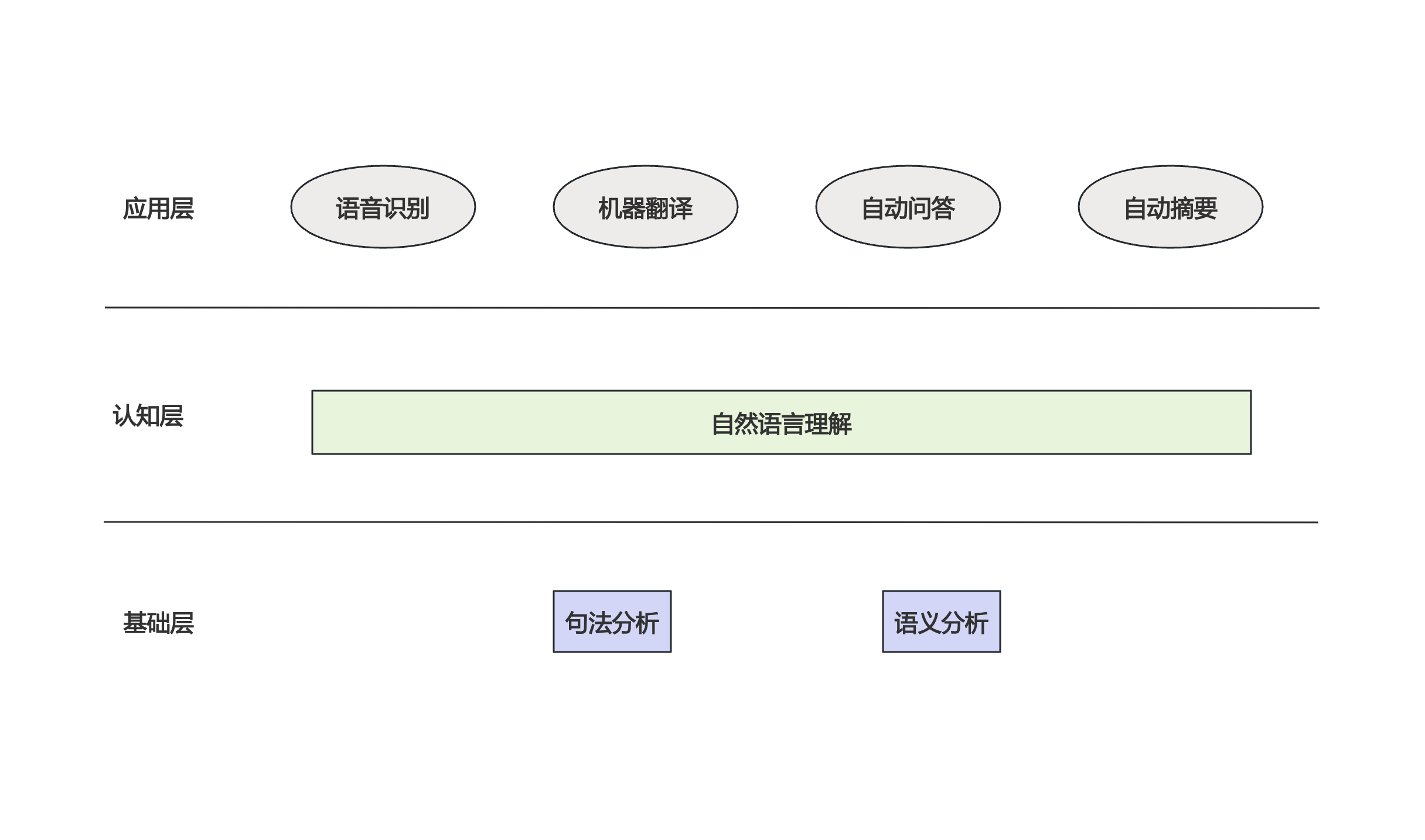
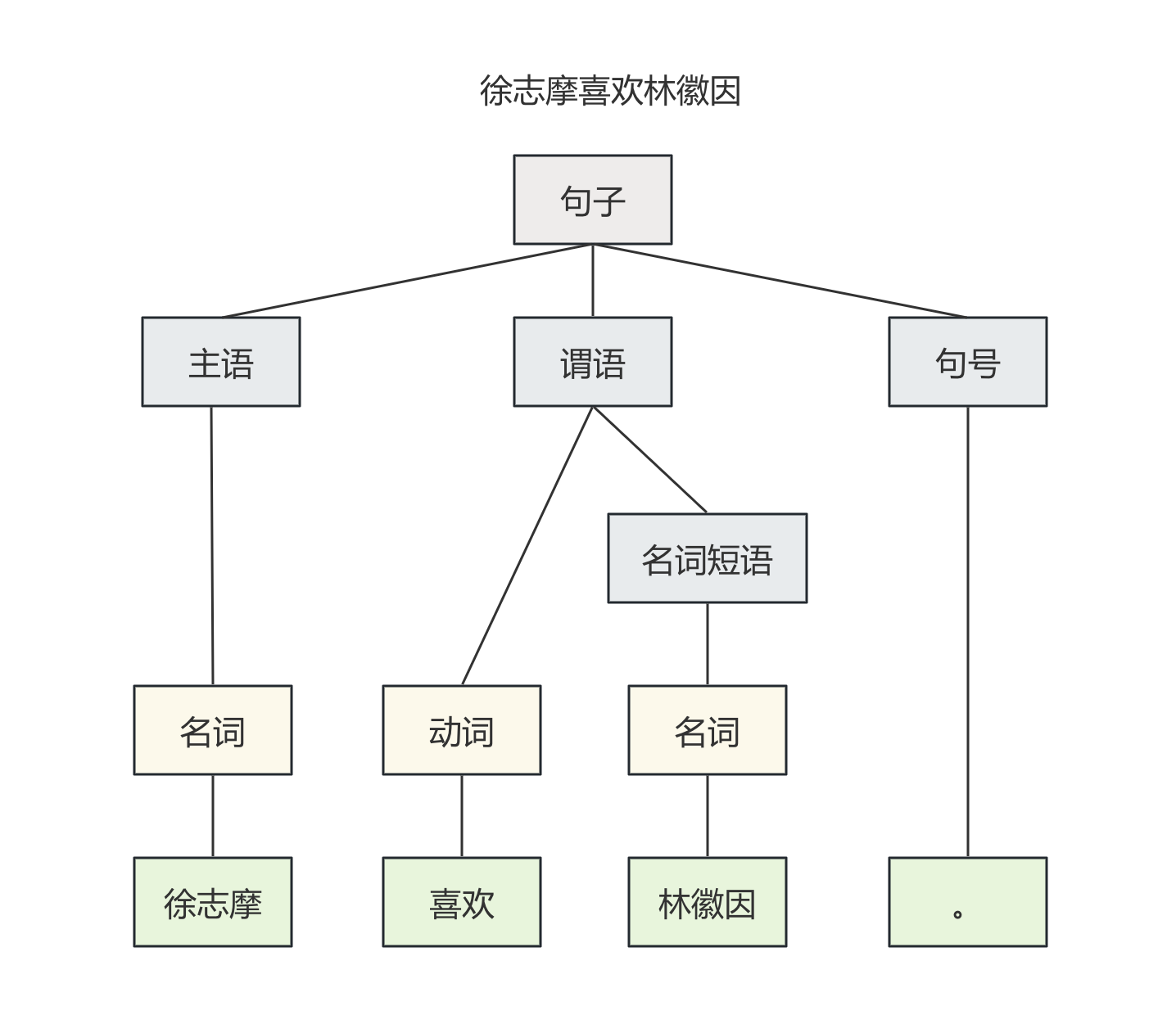
以上就是早期科学家们对自然语言处理的方法,对句子进行句法分析和语义分析,但是这么处理存在三个很严重的问题:
- 第一就是人类的语言不完全遵循语法,就好像很多人没上过学不懂语法也能与人正常沟通,很多人学习外语即使懂语法也不能完全理解外语
- 第二个就是上下文处理会非常复杂,当涉及较长的上下文语义的时候,同一句话在不同的语义下能表达完全不同的意思。此分析方法本质上是对自然语言定义规则,然后计算机按照规则来处理信息,但是自然语言不是计算机语言一开始就被设计为精确表达和有限规则的编码格式,自然语言的诞生伴随着人类的进化历程其中很多模糊、多义、非规则化的东西夹杂在其中,再加上上下文情景,想通过枚举法来解决自然语言的处理几乎是不可能的。
- 第三个是常识,某些词汇在常识下会有不同的含义。例如:“The pen(钢笔) is in the box.”和”The box is in the pen(围栏).”这里的pen的含义不是基于上下文,而是基于常识。可是到底什么是常识?
人类可以重新设计一套更为精确以及更为有效的编码方式的语言吗?
1970年以后贾里尼克和他领导的IBM华生实验室采用基于统计的方法取得了巨大的进步,并且引起业界震动。其中Google主管研究的副总裁斯伯格特敏锐的察觉到了未来自然语言的研究方向,进而转向基于统计的研究方法,并取得了巨大成就。可是基于统计的方法就能解决以上问题吗?
互信息解决词义的二义性
比如Bush这个单词可以是美国总统布什也可以是灌木丛,在机器翻译中这个词的翻译就比较麻烦,传统的语法分析不能解决问题,Bush无论怎么翻译都是名词。用传统的自然语言处理方法很难解决这个问题,而用概率论的方法+信息论相关知识就能比较好的解决该问题。比如上下文中有总统、美国、国会、华盛顿等词的出现那么翻译成布什的可能性就更高,而上下文中出现土壤、植物等词汇翻译成灌木丛的可能性更高。而在实际翻译中只需要统计上下问中出现了哪些相关信息以及这些相关信息的概率就能更准确的翻译出Bush这个单词。
统计语言模型
贾里尼克的想法很简单,一个句子是否合理就看他存在的可能性有多大,只要有一个好的语料库,那么统计一个句子在在语料库下的概率就可以了。假定S表示某一个有意义的句子,该句子由一连串特定顺序的单词排列w1,w2,w3,w4,w5,…wn组成,n代表句子的长度,现在我们想知道S的概率P(S)。把P(S)展开:
利用条件概率公式。S这个句子出现的概率等于每一个词出现的条件概率相乘,于是P(S)可展开为:
其中P(w1)表示第一个单词出现的概率;P(w2|w1)是在w1单词出现的条件下w2出现的概率,P(w3|w1,w2)是w3单词在w1,w2出现的条件下的概率,后面依此类推。可以发现如果S比较大那么需要求最后一个单词在前面n-1个单词出现的概率就比较困难了,而w1出现的概率最简单,直接在语料库下查询w1的次数除以语料库单词数量即可。20世纪初俄国有个数学家马尔可夫提出一个简化方法就是假设wi出现的概率只与w(i-1)有关,这种假设在数学上被称为马尔可夫假设,于是S出现的概率变为:
这个统计模型被称为两元模型,当前也可以假设一个单词出现的概率与前面N-1个单词有关,这种模型称为N元模型。
接下来的问题就是求条件概率公式了 ,学过概率论的都知道这个公式等于什么了:
至于 的概率就比较好求了,根据大数定理,只要统计数量足够多,相对频率就等于概率,只需要统计w(i-1),wi出现的次数除以语料库大小即可。
自此最简单的统计语言模型就出来了,一个简单的全概率公式+马尔可夫假设就解决了问题。当然在实际应用中还会存在很多其他问题需要解决,比如语料库中没有wi这个单词该怎么办?但那都是工程上的问题了,交给工程师们吧。
二元马尔可夫假设太过于简单,实际工程中常用的是三元或四元马尔可夫假设,Google使用的是4元马尔可夫假设,再多其运算量就非常大了而效果提升并没有那么大,任何事情都是有成本的对吧。而对于未出现的词汇或者概率很低的词汇处理方法一般是古得-图灵估计,为了让条件概率平滑常用的方法是卡茨退避法这里不再细速。
隐马尔可夫模型
19世纪,概率论的发展从对随机变量的研究发展到对随机变量的时间序列s1,s2,s3,…st,…即随机过程的研究。比如:
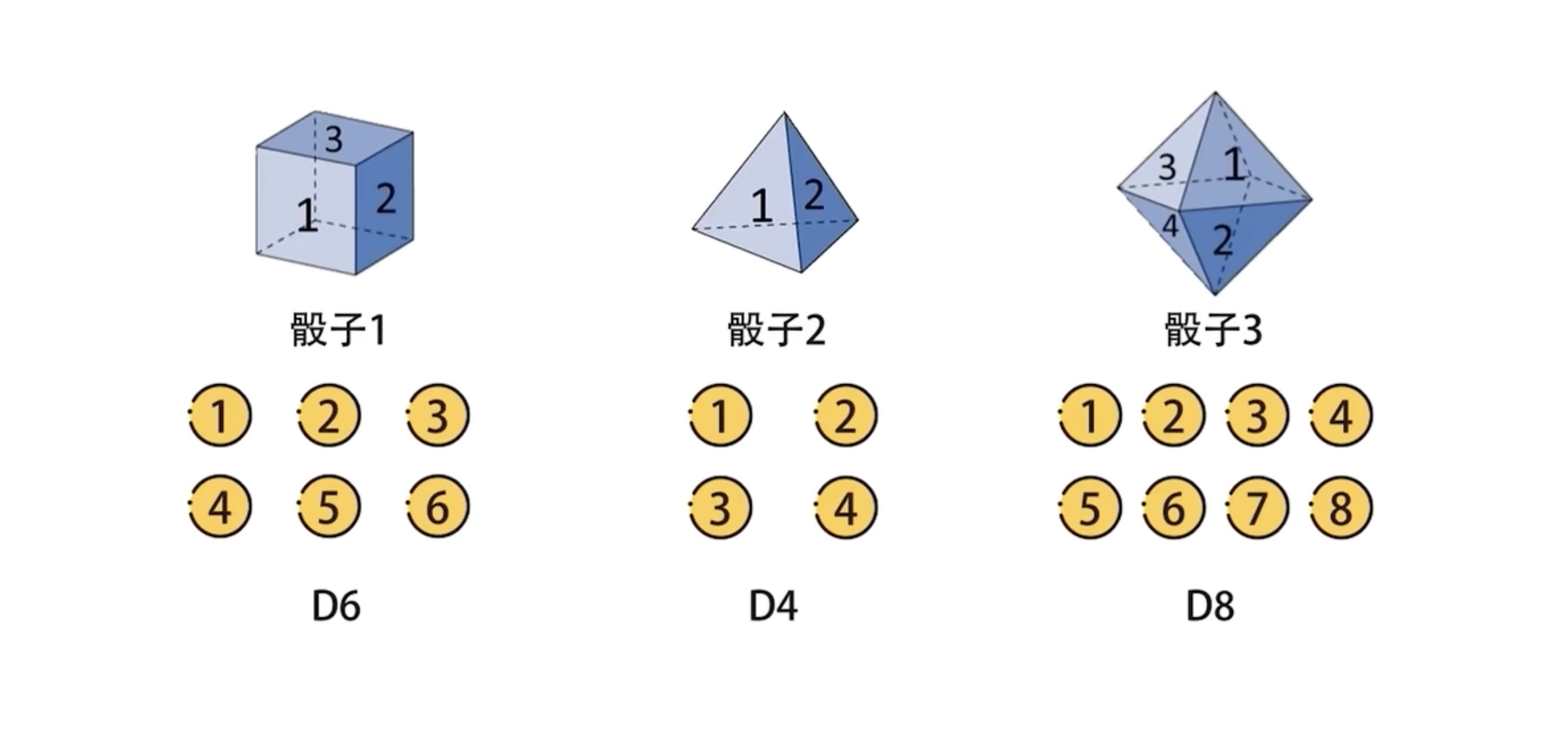
-
随机变量研究的是D6/D4/D8各骰子投出各点数的概率。随机投出D6、D4、D8中的骰子得到各点数的概率。
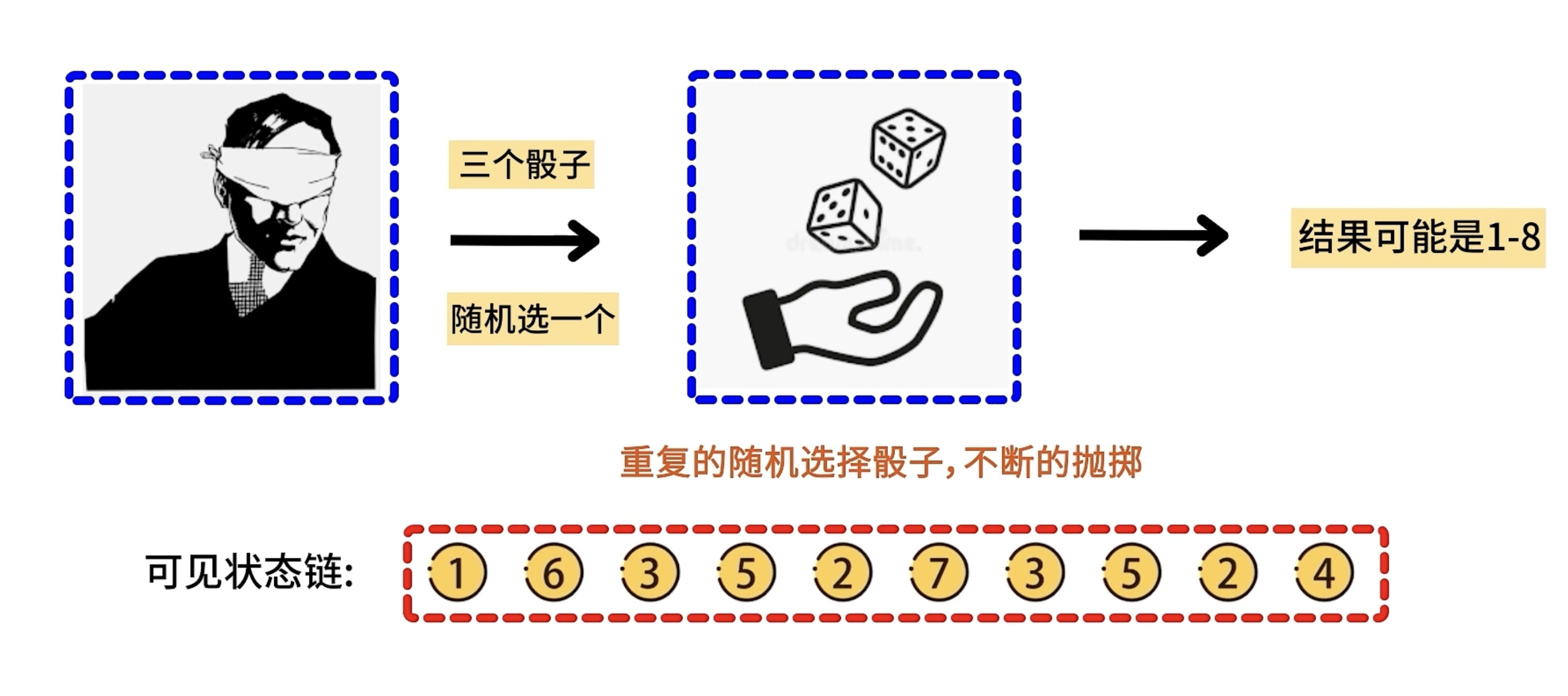
-
随机过程研究的是假设在一个大箱子有若干D6,D4,D8类型的骰子,t1时刻从箱子里随机取走一个骰子不放回(并不知道拿的是哪一种骰子)投出去得到点数,然后是t2时刻继续重复此过程得到可见状态链…。
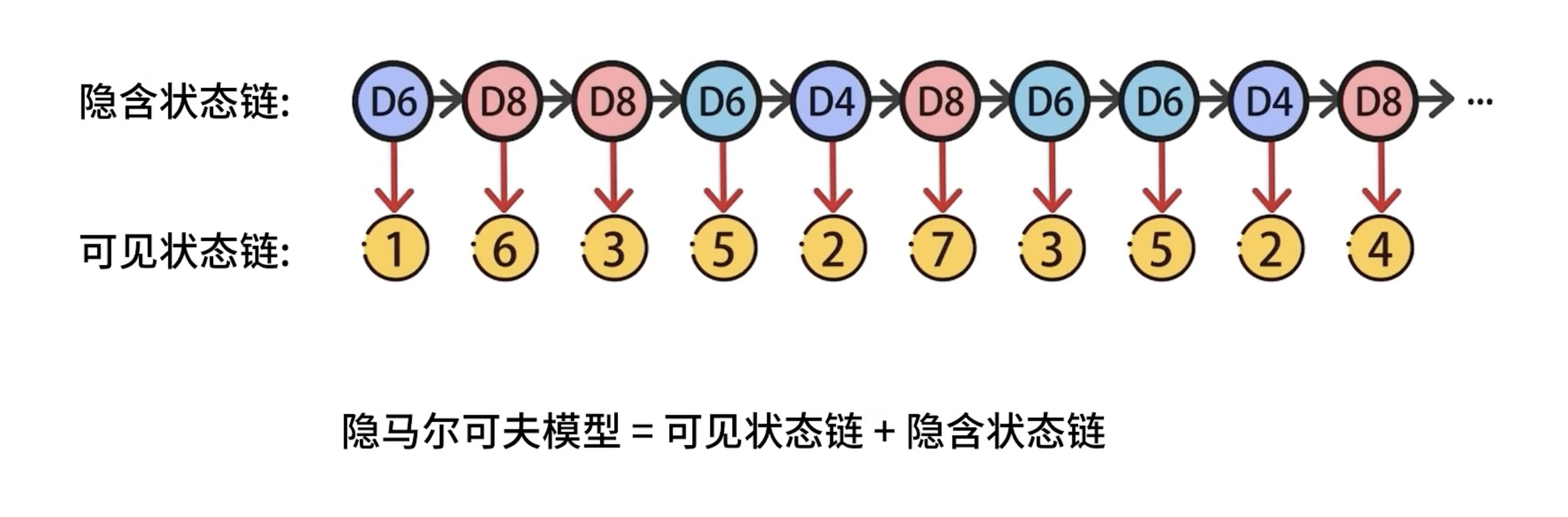
在隐马尔可夫模型中,隐含状态链是未知的,被称为状态序列用S表示在t个时刻中其状态可表示为S=(S1,S2,S3,…St),其中St状态的概率 ,St的状态与前t-1个状态有关;可见状态链是已知的被称为观测序列O,其中O=(O1,O2,O3,…Ot)其中Ot的概率为 Ot的概率与前t-1个状态有关.根据马尔可夫模型t时刻的概率只与t-1时刻有关,而与更前面的状态无关,则得到: 这是一个近似值,且通常都很有效,但并不准确。
隐马尔可夫链
如果大箱子中的D6,D4,D8的数量相同,则取出来每一种骰子的概率都是1/3,也就是隐含状态链的各状态在t1时刻彼此的转换概率是1/3.隐含状态会影响可见状态,比如隐含状态S是D6,那么输出O为7,8的概率就是0,输出1-6的概率是1/6,隐含状态S是D8,那么O为1-8的概率都是1/8.
由于箱子里的骰子会被拿走导致各种骰子的比例关系发生呢变化,但是根据马尔可夫模型t时刻拿出的骰子只与t-1时刻有关则s1,s2,s3,序列的概率为:
而观测序列O1,O2,O3,…的概率为:
这里我们知道t时刻输出的观测值Ot只与t时刻的状态St有关,这被称为独立输出假设。则有Ot的概率乘以St的概率:
而状态序列S1,S2,S3,…产生的观测量O1,O2,O3,…的概率为:
这就是隐马尔可夫模型的公式。
如何应用隐马尔可夫模型解决语音识别问题
隐马尔可夫模型最早的成功应用就是语音识别,20世纪70年代,当时IBM华生实验室的贾里尼克领导的科学家提出使用隐马尔可夫模型来识别语音,后来李开复坚持使用该模型开发了Sphinx语音识别系统。
对于语音识别应用中我们已知的观测量Ot是语音音频信息,而状态量St就是语音音频对应的文字,应用概率论来解决语音识别问题的思想是已知观测量O,求状态序列S的最大可能性,妙啊!
在已知O1,O2,O3,…的情况下求得令条件概率: 达到最大值的那组信息串S1,S2,S3,…即:
根据贝叶斯公式可得:
其中 是常数,而分子的两项可以看看上一节的推导隐马尔可夫公式都已经推导过了。
在·利用隐马尔可夫模型解决实际问题中,需要事先知道从前一个状态 进入当前状态 的概率 ,也称为转移概率;和每个状态产生输出量 的概率 ,也称为生成概率。这些概率被称为隐马尔可夫模型的参数,而计算或者估计这些参数的过程称为模型的训练。从条件概率的定义我们知道:
对于P(O_t|S_t),如果有足够的人工标记数据就可以得到:
这种训练方法被称为有监督的训练方法。对应到上面的骰子例子中就是,分别投出每种类型的骰子出去,分别统计每种骰子投出各点的概率。但是在语音识别中数据标准是很难的并不像透骰子那么简单,实际使用中更多的是仅仅通过大量的观测信号O1,O2,O3,…就能推算出 和,这类方法称为无监督的训练方法。对于语音识别中常用算法是鲍姆-韦尔奇算法。
鲍姆-韦尔奇算法的思想是这样的,仅通过观测信号O1,O2,O3,…倒推他的隐马尔可夫模型,可能会得到很多的模型,但总有一个模型 比另一个模型 更有可能产生观测信号O1,O2,O3,…,其中 和 是隐马尔可夫模型的参数,鲍姆-韦尔奇算法就是寻找最合适的模型 。如果我们有了一个初始模型 ,且计算得到 ,而且能够找到这个模型产生O的所有路径,以及这些路径的概率,其中概率最高的路径就是最有可能的模型参数。
参考文献
整理自 吴军老师的《数学之美》





