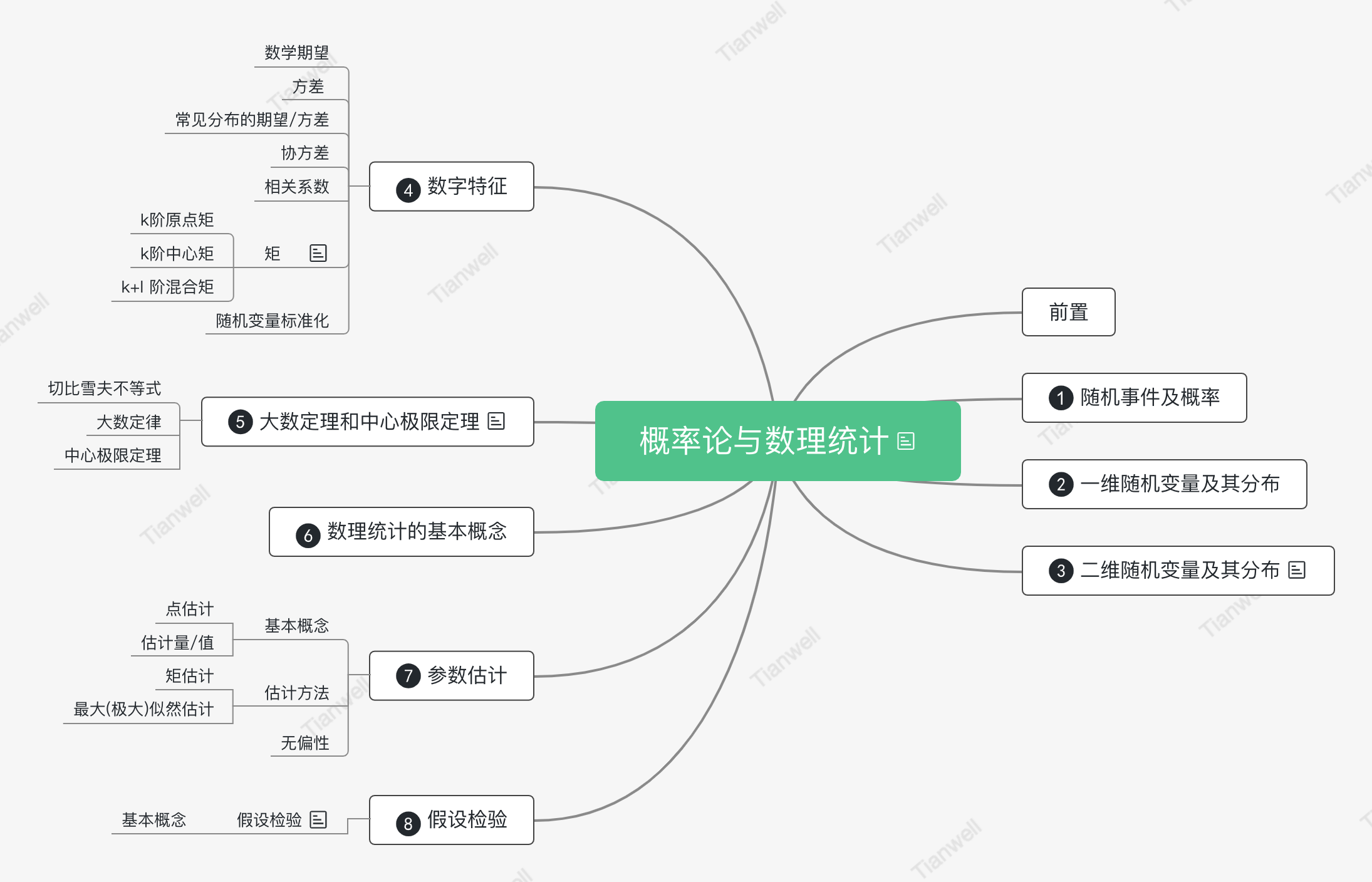
原图
概率论基本概念
概率的派别
对于概率的定义有几个主流的派别:
-
频率派:
频率派认为如果频率存在稳定性,即当n→∞时下面极限存在(下面这个写法只是示意,后面介绍大数定律的时候会给出严格的定义),就得到了概率(用 Probability 的首字母 P 来表示):
P(正面)=n→∞limPn(正面)
-
古典派:
如果因为无知,使得我们没有办法判断哪一个结果会比另外一个结果更容易出现,那么应该给予它们相同的概率,此称为不充分理由原则(Insufficient Reason Principle)。以不充分理由原则为基础,经由拉普拉斯:之手,确立了古典概率的定义,即:
未知的概率都为等概率
-
主观派:
最后介绍下主观派,主观派认为概率是信念强度(degree of belief)。比如说,我个人相信 20 年后人类从网络时代进入人工智能时代的概率为 70%.
三个流派大概有以下的区别:
理论基础概率定义频率派过往事实的归纳总结、quad频率稳定性、quad古典派不充分理由原则、quad等概率、quad主观派知识和直觉、quad信念强度、quad
概率公理化
已知某样本空间Ω,对于其中任一事件A,定义函数P,满足以下三大公理:
-
非负性公理:
P(A)≥0
-
规范性公理:
P(Ω)=1
-
可加性公理:
设A1、A2、⋯为两两不相容的事件,即Ai∩Aj=∅(i=j),有:
P(A1∪A2∪⋯)=P(A1)+P(A2)+⋯
则P称为概率函数,P(A)称为事件 A 的概率。
事件之间的运算和关系
-
并运算:
对于事件A、B,并运算定义为(≡表示定义):
A∪B≡{x∣x∈A 或 x∈B}
-
交运算:
对于事件A、B,交运算定义为:
A∩B≡{x∣x∈A 且 x∈B}
-
差运算:
对于事件A、B,定义差运算为:
A−B≡{x∣x∈A且、quadx∈/B}
-
补运算:
对于事件 A、B,如果:
A=Ω−B
则称 B 为 A 的补,记作(其中 c 代表 Complement):
B=A或、quadB=Ac
-
基本运算的性质:
并交差类比、quad+×−改写A∪B=A+BA∩B=ABA−B
并交差补定义、quadA∪B={x∣x∈A 或 x∈B}A∩B={x∣x∈A 且 x∈B}A−B={x∣x∈A 且、x∈/B}A=B⟺B=Ω−A类比、quad+×−
事件之间的关系=
\begin{cases}
包含、\
相等、\
不相容、\
对立
\end{cases}
条件概率
设 A 和 B 是样本空间Ω中的两事件,若P(B)>0,则称:
P(A∣B)=P(B)P(A∩B)
为“假设条件为 B 时的 A 的概率”,简称条件概率。也常写作:
P(A∣B)=P(B)P(AB)
乘法公式
-
若P(B)>0,则:
P(AB)=P(B)P(A∣B)
-
若P(A)>0,则:
P(AB)=P(A)P(B∣A)
-
若P(A1⋯An)>0,则:
P(A1⋯An)=P(A1)P(A2∣A1)P(A3∣A1A2)⋯P(An∣A1⋯An−1)
63 4、 贝叶斯与全概率
对于同一样本空间Ω中的随机事件A、B,若P(B)=0,有:
P(A∣B)=P(B)P(A)P(B∣A)
设A1、A2、⋯、An满足:
Ai∩Aj=∅,(i=j)且、quadP(i=1⋃nAi)=1
若P(Ai)>0,i=1,2,⋯,n,则对任意事件B有:
P(B)=i=1∑nP(Ai)P(B∣Ai)
有了全概率公式后,可以得到贝叶斯定理真正的样子:
设A1、A2、⋯、An为样本空间Ω的一个分割,则有:
P(Ai∣B)=P(B)P(BAi)=P(B)P(B∣Ai)P(Ai)=i=1∑nP(Ai)P(B∣Ai)P(B∣Ai)P(Ai)
也就是把P(B)分解到分割A1、A2、⋯、An上去了。
独立事件
对于两个随机事件A、B,如果满足:
P(AB)=P(A)P(B)
则称 A 与 B 相互独立,或简称 A 与 B 独立,否则称 A 与 B 不独立或相依。
设A1、A2、⋯为有限个或者无限个事件,从中任取两个Ai1、Ai2,若满足:
P(Ai1Ai2)=P(Ai1)P(Ai2)
则称A1、A2、⋯是两两独立。
若从中任取有限个Aj1、Aj2、⋯、Ajm,若满足:
P(Aj1Aj2⋯Ajm)=P(Aj1)P(Aj2)⋯P(Ajm)
则称A1、A2、⋯是相互独立。
随机变量及其分布
随机变量
定义在样本空间Ω上的实值函数:
X=X(ω),ω∈Ω
称为随机变量。随机变量是一个函数,所以都用大写字母来表示,以示和自变量 x 的区别。
二项分布
概率质量函数
如果p(x)满足(x∈{xi},i=1,2,⋯):
则称其为概率质量函数(PMF)。
伯努利分布
某样本空间只包含两个元素,Ω={ω1,ω2},在其上定义随机变量X:
X=X(ω)={1,0,ω=ω1ω=ω2
若0≤p≤1时,有:
p(1)=P(X=1)=p
p(0)=P(X=0)=1−p
或写作:
P(X=x)=p(x)={p,1−p,x=1x=0
则此概率分布称作 0-1 分布,也称作伯努利分布。
在数学中,类似于扔一次硬币这样的“是非题”称为一次伯努利试验,像上面这样独立地重复扔 n 次硬币(做同样的“是非题”n 次),就称为 n 重伯努利试验。
二项分布
对于 n 重伯努利实验,如果每次得到“是”的概率为 p,设随机变量:
X=得到“是”的次数
则称:
p(k)=P(X=k)=(kn)pk(1−p)n−k,k=0,1,⋯,n
为随机变量 X 的二项分布,也可以记作:
X∼b(n,p)
当 n=1 的时候,对应的就是伯努利分布,所以伯努利分布也可以记作b(1,p)。
离散的累积分布函数
设X是一个随机变量,x是任意实数,函数:
F(x)=P(X≤x)=a≤x∑p(a)
因为是把概率质量函数累加起来,所以称为累积分布函数(Cumulative Distribution Function,或者缩写为 CDF),也简称为分布函数。
离散的数学期望
设离散随机变量X的概率质量函数为:
p(xi)=P(X=xi),i=1,2,⋯,n,⋯
如果:
i=1∑∞∣xi∣p(xi)<∞
则称:
E(X)=i=1∑∞xip(xi)
为随机变量 X 的数学期望(expected value,或,expectation),简称期望或均值(mean),也有很多文档会用μX来表示(如果不强调随机变量的话,也可以直接用μ来表示):
μX=μ=i=1∑∞xip(xi)
若级数∑i=1∞∣xi∣p(xi)不收敛,则称X的数学期望不存在。
学期望也称作矩。更准确点说,由于数学期望:
E(X)=i=1∑∞xip(xi)
中xi是一次项,所以又称作一阶矩。这个称呼经常在统计的书上会遇到,特在此说明。
数学期望的性质
-
复合:
假设g(X)为随机变量X的某一函数,则:
E[g(X)]=i∑g(xi)p(xi)
-
常数:
若 c 为常数,则:
E(c)=c
-
线性组合:
数学期望满足:
E(aX)=aE(X)
- 可加性,对于随机变量的函数g1(X)、g2(X)有:
E[g1(X)+g2(X)]=E[g1(X)]+E[g2(X)]
-
伯努利分布和二项分布的期望分别如下:
PMF μ伯努利分布、qquadp(x)={p,1−p,x=1x=0p二项分布、qquadp(x)=(xn)px(1−p)n−xnp
方差与标准差
方差
代数式:
Var(X)=E[(X−E(X))2]
称为随机变量 X 的方差(Variance),也可记作σ2或者σX2。
方差的性质
-
化简:
可以通过下式来化简运算:
Var(X)=E(X2)−μ2
-
常数:
若 c 为常数,则:
Var(c)=0
-
相加与数乘:
若 a、b 为常数,则:
Var(aX+b)=a2Var(X)
标准差
假如随机变量X的方差为Var(X),则称:
σ(X)=Var(X)
为标准差,也可以记作σ或者σX。
二项分布的方差
PMF μVar(X)伯努利分布、qquadp(x)={p,1−p,x=1x=0pp(1−p)二项分布、qquadp(x)=(xn)px(1−p)n−xnpnp(1−p)
马尔可夫不等式
设X为取非负值的随机变量,则对于任何a>0,有:
P(X≥a)≤aE(X)
切比雪夫不等式
设X是一随机变量,均值μ和方差σ2有限,则对任何k>0有:
P(∣X−μ∣≥k)≤k2σ2
泊松分布
对于随机变量X的概率质量函数:
P(X=k)=k!λke−λ,k=0,1,2,⋯
称为随机变量X的泊松分布,也可以记为:
X∼P(λ)
其数学期望和方差为:
E(X)=λ,Var(X)=λ
条件
更一般地,在某一段时间 T 内发生特定事件的次数,如果满足以下假设,都可以看作泊松分布:
- 平稳性:在此时间段 T 内,此事件发生的概率相同(在实际应用中大致相同就可以了)。
- 独立性:事件的发生彼此之间独立(或者说,关联性很弱)。
- 普通性:把 T 切分成足够小的区间、Delta T,在、Delta T 内恰好发生两个、或多个事件的可能性为 0(或者说,几乎为 0)。
泊松分布是二项分布的极限:
n→∞lim(kn)(nμ)k(1−nμ)n−k=k!μke−μ
所以在泊松分布的λ固定的情况,二项分布的 n 越大(对应的p=nλ越小),此时两者会非常接近。
重要的离散分部
几何分布
对于 n 重伯努利实验,如果每次得到“是”的概率为 p,设随机变量:
X=首次得到“是”时进行的试验次数
则称:
p(k)=P(X=k)=(1−p)k−1p,k=1,2,⋯
为随机变量 X 的几何分布,也可以记作:
X∼Ge(p)
其数学期望和方差为:
E(X)=p1,Var(X)=p21−p
负二项分布
对于 n 重伯努利实验,如果每次得到“是”的概率为 p,设随机变量:
X=第r次“是”发生时的实验次数
则称:
p(k)=P(X=k)=(r−1k−1)pr(1−p)k−r,k=r,r+1,⋯
为随机变量 X 的负二项分布,也称为帕斯卡分布,也可以记作:
X∼Nb(r,p)
其数学期望为:
E(X)=pr,Var(X)=p2r(1−p)
负二项分布与几何分布
-
几何是负二项的特例 :
负二项分布是这样的:
p(k)=P(X=k)=(r−1k−1)pr(1−p)k−r,k=r,r+1,⋯
r=1 的时候,就得到了几何分布:
p(k)=P(X=k)=(1−p)k−1p,k=1,2,⋯
-
负二项是几何的和:
参数为 r、p 的负二项分布可以表示为如下事件序列:

图中所示的每一段X1、X2、⋯、Xr都是几何分布,所以有:
X=X1+X2+⋯+Xr∼Nb(r,p)
所以负二项分布的期望为:
E(X)=E(X1)+E(X2)+⋯+E(Xr)=pr
超几何分布
设有 N 件产品,其中有 M 件不合格品,随机抽取 n 件产品,则其中含有 m 件不合格产品的概率为多少?
假设随机变量:
X=随机抽取的n件中有m件不合格品
这个随机变量的概率可以用古典概率来求,首先,样本空间就是从 N 件中随便抽取 n 件,所以:
∣Ω∣=(nN)
然后有 m 件从不合格品中抽取,剩下的在合格品中抽取,则有:
∣X∣=(mM)(n−mN−M)
所求概率即为:
P(X=m)=(Nn)(Mm)(N−Mn−m),m=0,1,⋯,r
其中r=min(M,n)。此时称 X 服从超几何分布,可以记作:
X∼h(n,N,M)
其数学期望和方差为:
E(X)=nNM,Var(X)=nNM(1−NM)(1−N−1n−1)
超几何分布与二项分布
超几何分布与二项分布类似,都是求抽取 n 次其中有 m 次“是”的概率,只是:
- 二项分布:相当于抽取之后放回。
- 超几何分布:抽取之后不放回。
所以在超几何分布中,如果被抽取的总数 N 特别大,那么放回不放回区别也就不大了,此时,那么超几何分布可以近似看作二项分布。
这点从两者的期望、方差也可以看出来:
μσ2二项分布、qquadnpnp(1−p)超几何分布、qquadnNMnNM(1−NM)(1−N−1n−1)
令p=NM,超几何分布的期望和方差可以写作:
μ=nNM=np
\sigma^2=n\frac{M}{N}\left(1-\frac{M}{N}\right)\left(1-\frac{n-1}{N-1}\right)=np(1-p)\left(1-\frac{n-1}{N-1}\right)
对超几何分布而言,当 N 足够大的时候,$\frac{M}{N}$可看作取出不合格产品的概率,那此时超几何分布可看作二项分布。
### 总结
\begin{array}{c|c}
\hline
\
\quad 伯努利分布、quad&\quad 抛硬币,二选一 \quad\
\quad 二项分布、quad&\quad n 重伯努利,出现 k 次“是” \quad\
\quad 泊松分布、quad&\quad 二项分布的极限 \quad\
\quad 几何分布、quad&\quad n 重伯努利,第 k 次首次出现“是” \quad\
\quad 负二项分布、quad&\quad 几何分布的和 \quad\
\quad 超几何分布、quad&\quad 不放回抽样的二项分布 \quad\
\
\hline
\end{array}
## 概率密度函数
### 概率密度函数
如果函数$p(x)$满足下列两个条件(对应了概率的三大公理):
- 非负性:
p(x) \ge 0
$$
则称其为概率密度函数(Probability Density Function,简写为 PDF)。
期望
离散随机变量的期望定义为:
E(X)=i=1∑∞xip(xi)
可以用类似的方法定义连续随机变量的期望,当然期望的意义是没有改变的:
E(X)=∫−∞+∞xp(x)dx
关于期望的几个性质也是成立的:
-
复合:
假设g(X)为连续随机变量X的某一函数,则:
E[g(X)]=∫−∞+∞g(x)p(x)dx
-
常数:
若 c 为常数,则:
E(c)=c
-
线性:
数学期望满足:
E(aX)=aE(X)
- 可加性,对于任意两个函数g1(X)、g2(X)有:
E[g1(X)+g2(X)]=E[g1(X)]+E[g2(X)]
方差
方差的定义依然是:
Var(X)=E[(X−E(X))2]
相关的性质也是成立的:
-
化简:
可以通过下式来化简运算:
Var(X)=E(X2)−μ2
-
常数:
若 c 为常数,则:
Var(c)=0
-
相加与数乘:
若 a、b 为常数,则:
Var(aX+b)=a2Var(X)
累积分布函数
连续随机变量X的概率密度函数为p(x),则:
F(x)=P(X≤x)=∫−∞xp(t)dt
称为X的累积分布函数。
正态分布
正态分布
如果连续随机变量X的概率密度函数为:
p(x)=σ2π1e−2σ2(x−μ)2,−∞<x<+∞
则称X服从正态分布(normal distribution),也称作高斯分布(Gaussian distribution),记作X∼N(μ,σ2),其累积分布函数为:
F(x)=σ2π1∫−∞xe−2σ2(t−μ)2dt
我们称μ=0、σ=1时的正态分布N(0,1)为标准正态分布。
期望与方差
正态分布X∼N(μ,σ2)的期望和方差为:
E(X)=μ,Var(X)=σ2
指数分布
若随机变量X的概率密度函数为:
p(x)={λe−λx,0,x≥0x<0
其中λ>0,称X服从指数分布,也可以记为:
X∼Exp(λ)
累积分布函数为:
F(x)={1−e−λx,0,x≥0x<0
指数分布X∼Exp(λ)的期望和方差为:
E(X)=λ1,Var(X)=λ21
总结
首先是一维离散随机变量的概率分布:
伯努利分布、quad二项分布、quad泊松分布、quad几何分布、quad负二项分布、quad超几何分布、quad抛硬币,二选一n重伯努利,出现k次“是”二项分布的极限n重伯努利,第k次首次出现“是”几何分布的和不放回抽样的二项分布
然后是一维连续随机变量的概率分布:
均匀分布、quad正态分布、quad指数分布、quad古典派中的几何概型二项分布的另外一种极限泊松分布的间隔,连续的几何分布
多维随机变量及其分布
多维随机变量及其分布
联合概率质量函数
如果二维随机向量(X,Y)所有可能的取值为(xi,yj),i,j=1,2,⋯,这两个随机变量同时发生的概率可以用函数表示如下:
pij=P(X=xi,Y=yj)=P(X=xi 且 Y=yj),i,j=1,2,⋯
且此函数满足如下性质(即概率的三大公理):
则称此函数为(X,Y)的联合概率质量函数(Joint Probability Mass Function),或者称为联合分布列,此定义可以推广到多维离散随机变量上去。
联合概率密度函数
对于某二维随机变量(X,Y)存在二元函数p(x,y)满足:
-
非负性:
p(x,y)≥0
-
规范性和可加性(连续的都通过积分来相加):
∫−∞+∞∫−∞+∞p(x,y)dxdy=1
则称此函数为(X,Y)的联合概率密度函数(Joint Probability Density Function),此定义可以推广到多维连续随机变量上去。
联合累积分布函数
设(X,Y)是二维随机变量,对于任意实数x、y,可以定义一个二元函数来表示两个事件同时发生的概率:
F(x,y)=P({X≤x} 且 {Y≤y})=P(X≤x,Y≤y)
称为二维随机变量(X,Y)的联合累积分布函数(Joint Cumulative Distribution Function),如果混合偏导存在的话,那么:
∂x∂y∂F(x,y)=p(x,y)
得到p(x,y)就是此分布的概率密度函数。此定义和性质可以推广到多维随机变量。
多维均匀分布
设D为Rn中的一个有界区域,其度量(直线为长度,平面为面积,空间为体积等)为SD,如果多维随机变量(X1,X2,⋯,Xn)的联合概率密度函数为:
p(x1,x2,⋯,xn)={SD1,0,(x1,x2,⋯,xn)∈D其它
则称(X1,X2,⋯,Xn)服从D上的多维均匀分布,记作:
(X1,X2,⋯,Xn)∼U(D)
边缘分布与随机变量的独立性
边缘概率质量函数
如果二维离散随机变量(X,Y)的联合概率质量函数为:
P(X=xi,Y=yj),i,j=1,2,⋯
对j求和所得的函数:
j=1∑∞P(X=xi,Y=yj)=P(X=xi)
称为X的边缘概率质量函数(Marginal Probability Mass Function),或者称为边缘分布列。类似的对 i 求和所得的函数:
i=1∑∞P(X=xi,Y=yj)=P(Y=yj)
称为Y的边缘概率质量函数。
边缘概率密度函数
如果二维连续随机变量(X,Y)的联合概率密度函数为p(x,y),则:
pX(x)=∫−∞+∞p(x,y)dy
称为X的边缘概率密度函数(Marginal Probability Density Function)。类似的:
pY(y)=∫−∞+∞p(x,y)dx
称为 Y 的边缘概率密度函数。
边缘累积分布函数
如果二维连续随机变量(X,Y)的联合累积分布函数为F(x,y),如下可以得到X的累积分布函数:
FX(x)=y→+∞limF(x,y)=P(X≤x,Y<+∞)=P(X≤x)
称为X的边缘累积分布函数(Marginal Cumulative Distribution Function)。可记作:
FX(x)=F(x,+∞)
同理可以得到 Y 的边缘累积分布函数:
FY(y)=F(+∞,y)
条件分布
离散的条件分布
设(X,Y)是二维离散型随机变量,对于固定的j,若P(Y=yj)≥0,则称:
P(X=xi∣Y=yj)=P(Y=yj)P(X=xi,Y=yj),i=1,2,⋯
为Y=yj条件下的随机变量X的条件概率质量函数。同样的对于固定的i,若P(X=xi)≥0,则称:
P(Y=yj∣X=xi)=P(X=xi)P(X=xi,Y=yj),j=1,2,⋯
为X=xi条件下的随机变量Y的条件概率质量函数。
条件分布和条件概率没有什么区别,一样可以用于全概率公式、贝叶斯公式。
连续的条件分布
设二维连续型随机变量(X,Y)的概率密度函数为p(x,y),若对于固定的y有边缘概率密度函数pY(y)>0,则:
pX∣Y(x ∣ y)=pY(y)p(x,y)
为Y=y条件下的随机变量X的条件概率密度函数。对应的条件累积分布函数为:
FX∣Y(x ∣ y)=∫−∞xpY(y)p(u,y)du
同样的道理,以X=x为条件有:
pY∣X(y ∣ x)=pX(x)p(x,y)
F_{Y|X}(y\ |\ x)=\int_{-\infty}^{y}\frac{p(x,u)}{p_X(x)}\mathrm{d}u
### 连续的全概率和贝叶斯
- 全概率:
p_{Y}(y)=\int_{-\infty}^{+\infty} p(y | x) p_{X}(x) \mathrm{d} x
$$
p_{X}(x)=\int_{-\infty}^{+\infty} p(x | y) p_{Y}(y) \mathrm{d} y
$$
p(x∣y)=pY(y)p(y∣x)pX(x)=∫−∞+∞p(y∣x)pX(x)dxp(y∣x)pX(x)
多维随机变量函数的分布
随机变量的和
-
离散:
设 X、Y 为两个相互独立的离散随机变量,取值范围为0,1,2,⋯,则其和的概率质量函数为:
P(X+Y=k)=i=0∑kP(X=i)P(Y=k−i)
这个概率等式称为离散场合下的卷积公式。
-
连续:
设(X,Y)为二维连续型随机变量,概率密度函数为p(x,y),则Z=X+Y仍为连续型随机变量,其概率密度为:
pX+Y(z)=∫−∞+∞p(z−y,y)dy=∫−∞+∞p(x,z−x)dx
若X、Y为相互独立,其边缘密度函数分别为pX(x)和pY(y),则其和Z=X+Y的概率密度函数为:
pZ(z)=∫−∞+∞pX(z−y)pY(y)dy=∫−∞+∞pX(x)pY(z−x)dx
上面两个概率等式称为连续场合下的卷积公式。
随机变量的数字特征
数学期望
数学期望的定义
离散随机变量的数学期望定义为:
E(X)=i=1∑∞xip(xi)
连续随机变量的数学期望定义为:
E(X)=∫−∞+∞xp(x)dx
函数的数学期望
-
一维随机变量:
设Y是随机变量X的函数Y=g(X)(g 是连续函数)。
- 若X为离散随机变量,则(设下式中的级数绝对收敛):
E(Y)=E[g(X)]=i∑g(xi)p(xi)
- 若X为连续随机变量,则(设下式中的积分绝对收敛):
E(Y)=E[g(X)]=∫−∞+∞g(x)p(x)dx
-
多维随机变量:
设Z是随机变量(X,Y)的函数Z=g(X,Y)(g 是连续函数)。
- 若(X,Y)为离散随机变量,则(设下式中的级数绝对收敛):
E(Z)=E[g(X,Y)]=j∑i∑g(xi,yj)p(xi,yj)
- 若(X,Y)为连续随机变量,则(设下式中的积分绝对收敛):
E(Z)=E[g(X,Y)]=∫−∞+∞∫−∞+∞g(x,y)p(x,y)dxdy
线性的数学期望
数学期望满足:
-
齐次性,对于任意常数 a 有:
E(aX)=aE(X)
-
可加性,对于任意两个函数g1(X)、g2(X)有:
E[g1(X)+g2(X)]=E[g1(X)]+E[g2(X)]
对于多维也成立:
E(X+Y)=E(X)+E(Y)
E(X_1+X_2+\cdots+X_n)=E(X_1)+E(X_2)+\cdots+E(X_n)
### 施瓦茨不等式
对任意随机变量$X$与$Y$都有:
\Big[E(XY)\Big]^2 \le E(X2)E(Y2)
### 独立的数学期望
设$(X,Y)$为二维独立随机变量,则有:
E(XY)=E(X)E(Y)
这个结论可以推广到n维独立随机变量:
E\left(X_{1} X_{2} \cdots X_{n}\right)=E\left(X_{1}\right) E\left(X_{2}\right) \cdots E\left(X_{n}\right)
## 方差与标准差
### 方差与标准差的定义
方差定义为(因为直接通过数学期望定义的,所以没有区分离散和连续):
Var(X)=E\left[\Big(X-E(X)\Big)^2\right]
为了写的简单一点,也常常令$E(X)=\mu$,那么上式可以改写为:
Var(X)=E\left[(X-\mu)^2\right]
之前也介绍过,由于方差里面含有平方,在实际应用中需要开平方才能保持单位一致,这就是标准差:
\sigma(X)=\sqrt{Var(X)}
### 线性的方差
若$a、b$为常数,则:
Var(aX+b)=a^2Var(X)
### 独立的方差
设$(X,Y)$为二维独立随机变量,则有:
Var(X\pm Y)=Var(X)+Var(Y)
这个结论可以推广到n维独立随机变量:
Var\left(X_{1}\pm X_{2}\pm \cdots\pm X_{n}\right)=Var\left(X_{1}\right) +Var\left(X_{2}\right)+\cdots+Var\left(X_{n}\right)
## 协方差
### 协方差的定义
设$(X,Y)$是一个二维随机变量,若$E\Big[(X-\mu_X)(Y-\mu_Y)\Big]$存在,则称此数学期望为$X$与$Y$的协方差(Covariance),记作:
Cov(X,Y)=E\Big[(X-\mu_X)(Y-\mu_Y)\Big]
特别地有$Cov(X,X)=Var(X)$。
很显然会有:
- $Cov(X,Y) > 0$时,$X、Y$正相关,即两者有同时增加或者减少的倾向。
- $Cov(X,Y) < 0$时,$X、Y$负相关,即两者有反向增加或者减少的倾向。
- $Cov(X,Y) = 0$时,$X、Y$不相关,不过和独立还是有区别的,这点我们后面再论述。
### 协方差的性质
- 化简:
可以通过下式来化简运算:
Cov(X,Y)=E(XY)-E(X)E(Y)
$$
据此马上可以得到一个推论:
$$
Cov(X,Y)=Cov(Y,X)
$$
-
方差:
对于任意的二维随机变量(X,Y)有:
Var(X+Y)=Var(X)+Var(Y)+2Cov(X,Y)
Var(X-Y)=Var(X)+Var(Y)-2Cov(X,Y)
所以当$(X,Y)$为二维不相关随机变量时,有:
Var(X\pm Y)=Var(X)+Var(Y)
Cov(X1+X2,Y)=Cov(X1,Y)+Cov(X2,Y)
-
数乘:
Cov(aX+c,bY+d)=abCov(X,Y)
独立与不相关
-
独立必不相关:
根据刚才的性质:
Cov(X,Y)=E(XY)−E(X)E(Y)
如果 X、Y 独立,则有:
E(XY)=E(X)E(Y)⟹Cov(X,Y)=0
所以:
独立、implies不相关
-
不相关不能推出独立:
不相关只能说明 X、Y 之间没有正相关规律,也没有负相关规律,但可能还有很多别的规律,所以:
不相关、/⟹ 独立
相关系数
对于二维随机变量(X,Y),各自的方差为:
Var(X)=σX2,Var(Y)=σY2
则:
ρXY=σXσYCov(X,Y)
称为随机变量X和Y的相关系数。
对于任意的二维随机变量(X,Y),若相关系数存在,则:
−1≤ρXY≤1
有界性让比较有了一个范围,我们可以得到如下结论:
- ρ>0:正相关,且ρ=1的时候,正相关性最大,称为完全正相关。
- ρ<0:负相关,且ρ=−1的时候,负相关性最大,称为完全负相关。
- ρ=0:不相关。
二维正态分布
如果二维随机变量(X,Y)的联合概率密度函数为:
p(x,y)=2πσ1σ21−ρ21exp{−2(1−ρ2)1[σ12(x−μ1)2−σ1σ22ρ(x−μ1)(y−μ2)+σ22(y−μ2)2]}
则称(X,Y)服从二维正态分布,记作:
(X,Y)∼N(μ1,μ2,σ12,σ22,ρ)
它含有五个参数μ1,μ2,σ12,σ22和ρ,取值范围分别为:
−∞<μ1<∞,−∞<μ2<∞,σ1>0,σ2>0,−1⩽ρ⩽1
并且μ1,μ2分别是X、Y的期望;σ12,σ22分别是X、Y的方差;ρ是X、Y的相关系数。
大数定律及中心极限定理
大数定律
伯努利大数定律
整个概率论的得以存在的基础是,其所研究的随机现象虽然结果不确定,但又有规律可循。这个基础在概率论中被称为大数定律(Law of large numbers)。大数定律是一系列的定律,先来介绍伯努利大数定律:
设nA是n次重复独立实验中事件A发生的次数,p是事件A在每次实验中发生的概率,则对于任意正数ϵ>0,有:
n→∞limP(∣∣∣∣nnA−p∣∣∣∣<ϵ)=1
或:
n→∞limP(∣∣∣∣nnA−p∣∣∣∣≥ϵ)=0
这里需要注意不能直接用:
n→∞limnnH=p
而必须在外面套上一个概率函数,nnH并不是一个数列,而是随机变量。因此它不具备进行极限运算的前提。
依概率收敛
因为nnH是随机变量,所以要表示它和p接近,只能表示为事件:
“频率Pn越来越接近概率p”={∣∣∣∣nnH−p∣∣∣∣<ϵ}
然后套上概率函数P,对该函数求n趋于无穷时的极限:
n→∞limP(∣∣∣∣nnH−p∣∣∣∣<ϵ)=1
这个极限同样表达了“随着n的增大,频率Pn会越来越接近概率p”的意思,但是因为套上了概率函数,所以也称为Pn依概率收敛于p,记作:
nnHPp,n→∞
辛钦大数定律
伯努利大数定律局限于伯努利分布,下面介绍辛钦大数定律就没有这个限制,只是要求遵循相同的分布:
设有随机变量:
X1,X2,⋯,Xn
这些随机变量相互独立,服从同一分布,且具有相同的数学期望:
E(Xi)=μ,i=1,2,⋯,n
令:
X=nX1+X2+⋯+Xn
则对于任意ϵ>0有:
n→∞limP(∣∣∣X−μ∣∣∣<ϵ)=1
或:
n→∞limP(∣∣∣X−μ∣∣∣≥ϵ)=0
也可以表述为:
XPμ,n→∞
切比雪夫大数定律
相同的分布也算比较严格的限制,下面介绍切比雪夫大数定律对于分布就更加宽松,只要各自的方差有共同上界即可:
设有随机变量:
X1,X2,⋯,Xn
这些随机变量两两不相关,若每个随机变量Xi的方差存在,且有共同的上界,即:
Var(Xi)≤c,i=1,2,⋯,n
令:
X=nX1+X2+⋯+Xn,μ=E(X)
则对于任意ϵ>0有:
n→∞limP(∣∣∣X−μ∣∣∣<ϵ)=1
或:
n→∞limP(∣∣∣X−μ∣∣∣≥ϵ)=0
也可以表述为:
XPμ,n→∞
总结
这里总共介绍了三个大数定律,主要区别如下:
\begin{array}{c|c}
\hline
\quad \quad &\quad 分布、quad&\quad 独立性、quad&\quad 方差、quad\\
\hline
\\
\quad 伯努利大数、quad & \quad 伯努利分布、quad & \quad 独立、quad & \quad 无要求、quad\\
辛钦大数 & 同分布 & 独立 & 无要求 \\
切比雪夫大数 & 无要求 & 不相关 & 同上界、\
\\
\hline
\end{array}
强大数定律
前面介绍的大数定律又称为弱大数定律(Weak Law of large numbers),有弱就自然就有强,下面就来介绍强大数定律(Strong Law of large numbers):
设有随机变量:
X1,X2,⋯,Xn
这些随机变量相互独立,服从同一分布,且具有相同的数学期望:
E(Xi)=μ,i=1,2,⋯,n
令:
X=nX1+X2+⋯+Xn
则对于任意ϵ>0有:
P(n→∞lim∣∣∣X−μ∣∣∣<ϵ)=1
或:
P(n→∞lim∣∣∣X−μ∣∣∣≥ϵ)=0
这个强大数定律和之前的辛钦大数定律非常接近:
- 弱大数定律(辛钦大数定律),极限符号在 P 函数外面:
n→∞limP(∣∣∣X−μ∣∣∣<ϵ)=1
P(n→∞lim∣∣∣X−μ∣∣∣<ϵ)=1
仔细体会这两则之间的区别^ _ ^。
中心极限定理
棣莫弗-拉普拉斯定理
设随机变量X∼b(n,p),则对任意 x 有:
n→∞limP(np(1−p)X−np≤x)=Φ(x)=2π1∫−∞xe−2t2dt
林德伯格-莱维定理
设随机变量:
Xi,i=1,2,⋯,n
相互独立,服从同一分布,且有相同的数学期望和方差:
E(Xi)=μ,Var(Xi)=σ2
则随机变量:
Y=σnX1+X2+⋯+Xn−nμ
对于任意实数y有:
n→∞limFY(y)=n→∞limP(Y≤y)=Φ(y)=2π1∫−∞ye−2t2dt
参考文献
《马同学的概率论与数理统计》
感兴趣的可以购买他的课程,写的很好(强烈推荐)!!!
[[ANovelCameraPathPlanningAlgorithmForRealTimeVideoStabilization]]
[[DigitalVideoStabilizationAndRollingShutterCorrectionUsingGyroscope]]
[[GyroscopeBasedNonlinearFilterForVideoStabilization]]
[[HybridMotionEstimationForVideoStabilizationBasedOnIMUSensor]]
[[NonlinearAnalysisAndControlOf3DInvertedPendulumBasedOnCounterwheelAction]]
[[ProbabilityTheoryandMathematicalStatistics]]






